INT102 算法笔记
PDF版本下载
文章目录
- week1 伪代码与时间复杂度
-
- 伪代码(Pseudo Code)
- 时间复杂度(Time complexity)
- week2 评估基础查找与排序算法
-
- 线性查找(Linear Search)
- 二分法查找(Binary Search)
- 寻找连续子串出现位置 (Search for a pattern)
- 选择排序 (Selection Sort)
- 冒泡排序(Bubble Sort)
- 插入排序 (Insertion Sort Algorithm)选读
- week3 分治思想和基础图论
-
- 分而治之(Divide and Conquer)
-
- 归并排序(Merge Sort)(O(nlogn))
- 基础图论
-
- 图(Graphs)
- 树(Tree)
-
- 树的遍历
- 欧拉回路(Euler circuit)
- 哈密顿图(Hamiltonian circuit / path)
- week4 深度优先与广度优先
-
- 深度优先(Deep First Search)
- 广度优先(Breadth First Search)
- week5 贪心算法及最小生成树
-
- 贪心算法(Greedy Algorithms)
- 贪心背包问题(Knapsack Problem)
- 最小生成树(Minimum Spanning Tree)
-
- Prim's algorithm( O(|E|*log|V|) )
- Kruskal's algorithm ( O(|E|*log|V|) )
- Dijkstra’s algorithm ( O(|E|*log|V|) )
- week6 动态规划
-
- 斐波拉契(Fibonacci numbers)(O(n) )
- 流水线调度(Assembly line scheduling)(O(nm^2^) )
- week8 时空转换相关算法和图的最短路径
-
- 时空转换 (Space-for-time tradeoffs)
- 计数排序(Counting Sort)(O(n+k))
- 确认连续子串出现位置Horspool's Algorithm
- 图的最短路径
-
- 单起点最短路径(Single-source shortest paths)
-
- Bellman-Ford Algorithm
- 多源最短路径
-
- Floyd Algorithom(All-pairs shortest paths)(O(n^3^))
- 构建传递闭包
-
- Warshall’s Algorithm(O(n^3^))
- week9 查找最长相同子序列
-
- 最长相同子序列问题(LCS Intuitive Solution)
-
- 爆算
- dp
- 双序列比对问题(Pairwise Sequence Alignment Problem)
-
- 全局比对dp
- 局部比对(Local alignment)
- 回溯dp的table
- week 10 NP问题
-
-
- Circuit-SAT问题
-
- 范式(Normal form (NF))
-
- 合取范式 (Conjunctive Normal Form)
- 析取范式 (Disjunctive Normal Form)
- 判断问题和最优化问题
-
- 判断问题(Decision problems)
- 最优化问题(Optimisation problems)
- 解决(solving)问题和判别(verifying)待定解
- P和NP复杂类
-
- P复杂类(Complexity Classes P )
- NP复杂类(Complexity Classes NP )
- 多项式规约(Polynomial-time reduction)
-
- NP-hard
- NP-complete
- NP=P?
-
- week11 回溯剪枝DFS算法设计
-
- 精确解策略(Exact Solution Strategies)
- 算法设计(Algorithm Design Techniques)
-
- [n皇后问题(n-Queens Problem)](https://leetcode-cn.com/problems/n-queens/)
- 哈密顿电路(Hamiltonian Circuit )
- [N数之和问题(Subset-Sum Problem)](https://leetcode-cn.com/problems/4sum/)
- 指派问题(Assignment Problem)
- 旅行商问题(Traveling Salesman Problem)
- week12 更多动态规划dp
-
- 一维动态规划问题 1-dimensional DP
-
- 目标和的加法式数量
- 贴砖 Troll Tiling
- 二维动态规划问题 2-dimensional DP
-
- LCS Problem
- 间隔DP Interval DP
- Tree DP
- dp背包问题 Knapsack 0-1 Example
- week13 近似求解
-
- 爆算 Brute-force algorithms
- 启发法 Heuristics
- 近似算法 Approximation algorithms
-
- 准确率Accuracy Ratio
- c-approximation algorithm
- 近似解顶点覆盖问题VERTEX-COVER
- 近似解TSP问题
-
- Nearest-neighbor
- Euclidean instances
- Multifragment-heuristic
- Twice-Around-the-Tree Algorithm
week1 伪代码与时间复杂度
伪代码(Pseudo Code)
这部分略过
时间复杂度(Time complexity)
要注意的是f(n)和大O(g(n)), f(n)=O(g(n))
- 算法频度f(n):该算法基本操作需要执行的次数
- 辅助函数g(n): n取无穷时可近似f(n) (n趋近无穷时,lim f(n)/g(n) 等于一个常数)
- 时间渐进复杂度O(g(n)): 时间复杂度,通常用O(n)表示运行算法的规模,在代码分析中主要取决于循环语句执行次数。
下图展示了时间复杂度之间的大小比较关系
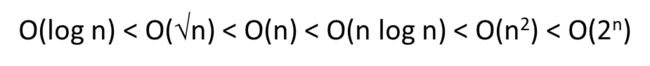
部分题型:
给定一式子,要求求解时间复杂度—》证明各项在某个n值时恒小于某一项
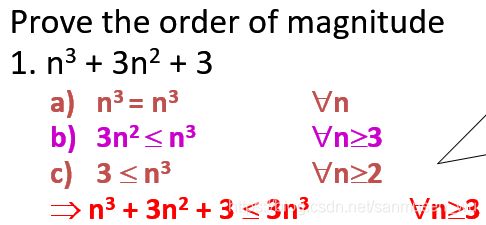
week2 评估基础查找与排序算法
线性查找(Linear Search)
从头到尾查,O(n)
二分法查找(Binary Search)
原数组已排序时可用该算法,确定数组的左界和右界,每次查找查两界中间的数,如果想找的数比中间的数大,把中间+1更新为左界;反之,如果想找的数比中间的数小,把中间-1更新为右界,O(log n)
寻找连续子串出现位置 (Search for a pattern)
从子串第一个字符位置依次向后比较,出现不相同的字符就把整体子串往后移一位继续从子串第一个字符开始向后比,O(nm)
选择排序 (Selection Sort)
每次从原始数组中选择最小数,append到新数组中,O(n^2)
冒泡排序(Bubble Sort)
从前到后,将原数组的相邻两数进行比较换位,直到数组末尾,此时末尾的数字已确定,下次(第2次)循环只需比较0到n-1个数字,以此类推,在第i次循环只需比较至n-i+1个数,直到i等于n结束循环,O(n^2)
插入排序 (Insertion Sort Algorithm)选读
顺序遍历原始数组中的数,插入新数组中,将其放置于新数组里小于该数的数字与大于该数的数字之间,O(n^2)
week3 分治思想和基础图论
分而治之(Divide and Conquer)
将大问题转化为小问题去解决,有时需要舍弃部分子问题。一般来说小问题与大问题之间是类似而不是完全相同,求解一个大问题下的小问题不代表这个解一定对于其他包含该小问题的大问题有用。
一个例子是二分法查找,将在全数组中查找转化为在半个数组中查找,舍弃另半个数组,往下依次类推…四分之一个数组…八分之一个数组…直到最终只有一个数字。
关于递归的时间复杂度
大问题的计算次数=子问题的计算次数+计算子问题结果之间的过程所需次数

三种T(n)对应的大O:
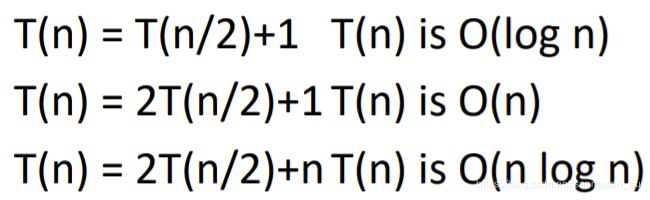
归并排序(Merge Sort)(O(nlogn))
将数组二分至几个数字单元,然后有序合并单元化后的数组。
重点在于合并时的操作,新数组依次append(两个单元数组间最小的第一个数.pop())
总时间复杂度O(nlogn),(上图,T(n)= 2T(n/2)+ n , 2T(n/2)代表两个子问题的运行次数,加的那个n是归并两子问题所需的遍历数组的次数)
基础图论
图(Graphs)
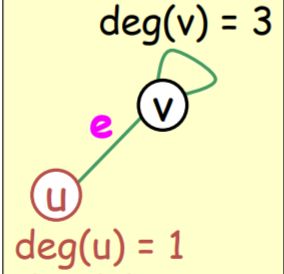
- 无向图(undirected graph) 没箭头
节点的度(degree of a vertex v):等于这个节点相连的边的量
- 有向图(directed graph) 有箭头
出度与入度(out-degree and in-degree):出去的边和进来的边的数量 - 邻接矩阵(Adjacency matrix):表示节点间连结与否或距离的矩阵
- 关联矩阵(Incidence matrix):表示节点与边的关联与否或距离的矩阵
- 关联列表Incidence list,表示最左边的一列与哪些点相连,如a与b,c相连
左图邻接矩阵,右图关联矩阵

关联列表Incidence list,如a与b,c相连,b与a,c,f相连

树(Tree)
无向图无环且连续可构造树
相关术语:
| 根节点 | 孩子节点 | 父母节点 | 度 | 叶子节点 | 内部节点 | 左子树 |
|---|---|---|---|---|---|---|
| root | children | parent | degree | leaf | internal vertices | left subtree |
树的遍历
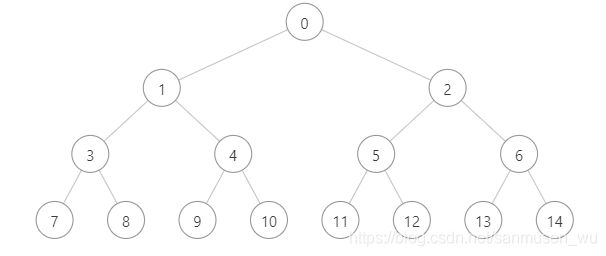
L代表遍历左子树,R代表遍历右子树,v代表当前节点值
- 前序遍历 v,L,R----[0,1,3,7,8,4,9,10,2,5,11,12,6,13,14]
- 中序遍历 L,v,R----[7,3,8,1,9,4,10,0,11,5,12,2,13,6,14]
- 后序遍历 L,R,v----[7,8,3,9,10,4,1,11,12,5,13,14,6,2,0]
欧拉回路(Euler circuit)
既一笔画问题
能一笔画的条件:
- G为连通图,并且G仅有两个奇度结点(度数为奇数的顶点)或者无奇度结点。
- 或D为有向图,D的基图连通,并且所有顶点的出度与入度都相等;
或者除两个顶点外,D的其余顶点的出度与入度都相等,而这两个顶点中一个顶点的出度与入度之差为1,另一个顶点的出度与入度之差为-1。
哈密顿图(Hamiltonian circuit / path)
给定一个图,存在有一种一笔画能够走完这个图的所有节点(走过的边不可再走,不必经过所有边),也就是这个图的节点可以一笔画走完,则称这个图为哈密顿图。
**部分题型:
-
给定一个递推公式,证明其O(n)为某值—》以某值为基础假设T(n)恒等式,证明T(n)有上界为O(n)乘一常数

-
给定一棵树,按照前序中序后序对其遍历
week4 深度优先与广度优先
深度优先(Deep First Search)
深度优先专注于先找到一个叶子节点,找到一个叶子再依次返回上级继续往下找与之相近的叶子节点
广度优先(Breadth First Search)
广度优先专注于先找里层节点,找完一层再依次往外找外层节点
部分例题:
给定一无向图,按DFS或BFS按照字母顺序对其进行遍历
week5 贪心算法及最小生成树
贪心算法(Greedy Algorithms)
每步都选择最优情况,贪就完事了
在按步进行贪心时,往往会错过全局最优解,
但是通过合理的贪心策略也可以求得全局最优解或近似解。
贪心背包问题(Knapsack Problem)
给定各个物品的重量和价值,要求在一个限重的背包里面塞入尽可能多值钱的东西。
这时用贪心基本上会错过最优解。贪值钱/贪轻量/贪价质比这三种策略都有可能错过最优解。
最小生成树(Minimum Spanning Tree)
给定一图,选择使该图所有点连通且总权值最小的边的集合
E边,V点
最小生成树有两种算法:
prim和kruskal
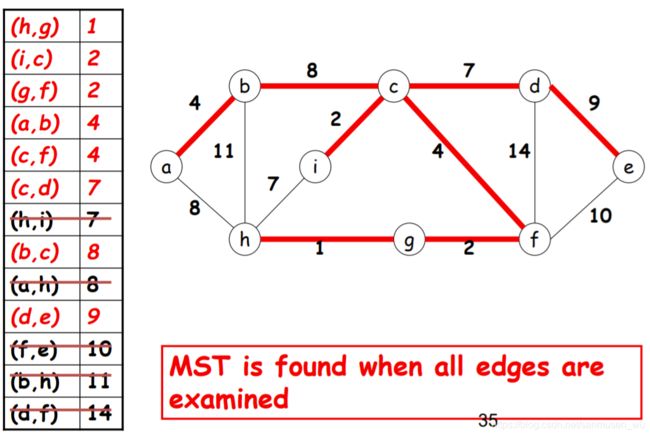
Prim’s algorithm( O(|E|*log|V|) )
这个算法需要维护点的初始集合S和点的最终集合T
初始时T为空,S为所有节点,将任意一节点从S移入T
- 计算初始集合S上的所有节点到最终集合T上的所有节点的边的距离
- 在所有上述边中选择距离最小的,将这条边的节点从初始集合S移到最终集合T,
- 重复上述步骤直到结果图中包含了所有节点
以下是例题,一行一行来看,每行选取前一行距离最终集合最小的点,然后更新两集合间线的距离

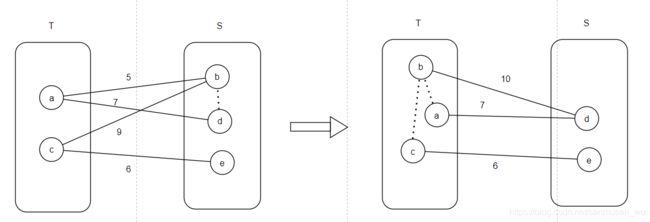
Kruskal’s algorithm ( O(|E|*log|V|) )
这个算法维护一个已确定的边的集合T,
起始时图上所有边初始化为未确定状态,集合T为空
- 选择未选择状态中最短的边w
- 如果边w加入集合T,集合T中不会形成回路,则将边w加入集合T
- 否则,在图中删除边w
- 重复上述步骤直到集合T中包含所有节点
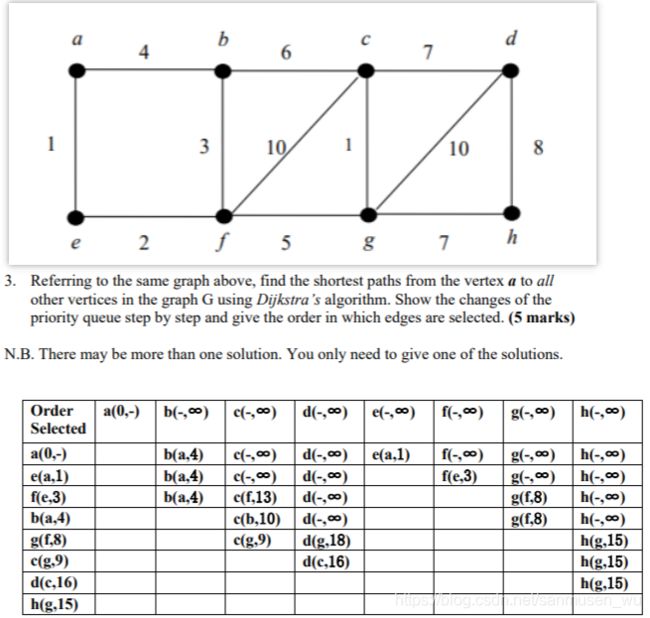
Dijkstra’s algorithm ( O(|E|*log|V|) )
针对于边权值非负的图,寻求从起点开始到其他各个节点的最短距离。
PPT里有详细过程
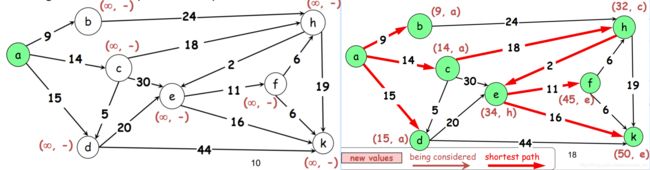
这个算法中每个点都有距离值,初始化为无穷,代表从起点到该点的最短距离。
算法需要维护已确定的点的集合True和一个已探明的集合Light,其余点均未探明。集合T中的点已经确定最小距离值,集合L中的点已被探知但未确定最小距离值。(可以想象为这是一个矿工在探索漆黑矿洞的过程,有些矿洞已走进去过,有些矿洞没进去过但是在路牌上见过,有些矿洞见都还没见着)
起始时只有起点在确定集合T中,与起点直接相连的点在探知集合L中,这些点的距离值为它们到起点的边长。
- 在集合L中挑选距离值最少的点m,移入集合T
- 在图中检查所有从点m出发相连的点p,
- 点p的距离值=m的距离值加上m和p它俩间的距离
如果点p在已探明集合L中,再检查p的新距离值是否小于原来记录的距离值,如果小于就更新距离值,同时记录下是从点m这儿发现更短的路的。
如果点p未探明,恭喜,你在黑暗中解锁了一个新矿洞,将p和其距离值加入集合L,同时记录下是从点m这儿探知到的。
如果点p在已确定集合T中,则其新距离值一定大于已记录的距离值。因为这个算法会将当前L中距离值最小的点加入T,又因为边权值非负,意味着加入T的时间越靠前,其距离值必定越小。 - 重复上述步骤直到集合T包含所有节点
以下是例题,按行来看,每行选取前一行的最小值,然后重新计算更新各个点的距离值。
week6 动态规划
动规属于分治的一种,但是分出来的小问题和原先大问题互相是等价的,求解小问题相当于求解大问题,因此动规多了种自下而上求解的方式,减少了时间复杂度。
不妨与分治的例子----二分法查找作比较:
求解大问题【1,2,3,4,5,6】中是否有6,二分法会继续找【4,5,6】中是否有6。二分法必须要先知道大问题,将他拆解成小问题,无法忽略大问题直接对小问题求解——它不先解决大问题它甚至不知道小问题是啥(是【1,2,3】还是【4,5,6】?还是【7,8,9】?)
一个动规的例子是数字的幂次方,要求算2的8次方,可以通过小问题2乘自己,2的2次方乘自己,2的4次方乘自己这样自下而上的求解。可以看出,动规可以在求解小问题后,逐步递推至解决大问题。
斐波拉契(Fibonacci numbers)(O(n) )
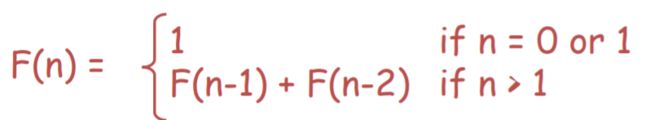
自左到右,维护当前F(n)
| F(0) | –>F(1) | –>F(2) | –>F(3) | –>F(4) | –>F(5) | –>F(6) |
|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 5 | 8 | 13 |
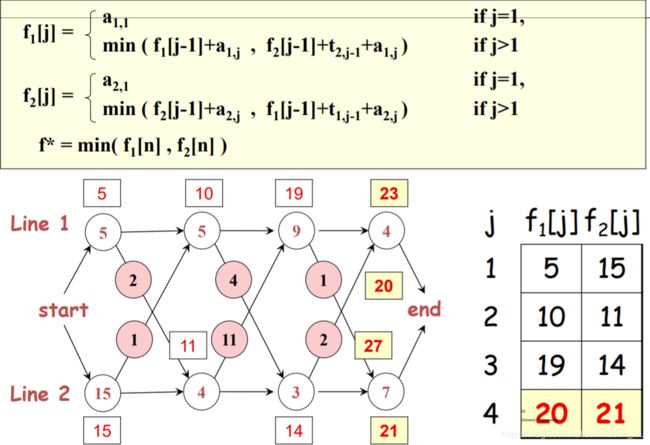
流水线调度(Assembly line scheduling)(O(nm2) )
给定点和边的权值
自左到右,维护 到当前步为止,从上到下m个站点最短路径的距离
一共走n步,每前进一步,更新该步的m个站点最短路径。更新方程:
该步第i个站点的最短路径=min(上一步第1个站点的距离值+上一步第1个站点走到这个站点i的距离,上一步第2个站点的距离值+上一步第2个站点走到这个站点i的距离…上一步第m个站点的距离值+上一步第m个站点走到这个站点i的距离)。
右下角的表: j 代表当前步,fm[j]代表第 j 步的从上到下第m个站点
week8 时空转换相关算法和图的最短路径
时空转换 (Space-for-time tradeoffs)
空间换时间,时间换空间
空间换时间的例子:
- 输入强化(Input-enhancement)
预处理输入存储一些信息,以待后续使用 - 预构造(Pre-structuring)
使用一个数据结构处理输入,以便更简单地处理问题
计数排序(Counting Sort)(O(n+k))
比较排序依靠值比较进行排序,其算法时间复杂度下限O(nlog(n))
而计数排序依靠已排序的桶进行计数排序,不需要进行值比较
其算法时间复杂度O(n+k) ,其中k为原始数列中数的范围,也就是桶的数量。
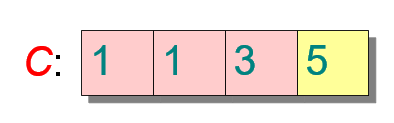
该算法维护一个计数数组(就是许多桶)
-
首先,根据数列的范围设置多个桶,数列元素的范围为多少就设置几个桶。例如,待排序数列中只包含个位数,那么就设置从0~9十个桶。初始时桶内计数都为0。
-
遍历原始数列,将遍历到的数对应的桶内计数自增1。

-
遍历桶,更新每个桶的计数=这个桶的计数+前一个桶的计数。遍历结束后各个桶内计数既代表该桶对应元素在排序后数组中最后处于的位置。
-
从后向前遍历原始数列,将遍历的元素按照对应桶内的计数作为地址依次放在新数组中,然后该桶计数减1。遍历结束新数组就是排序后的数组

确认连续子串出现位置Horspool’s Algorithm
寻找一字符串的某一连续子串出现位置
算法需要连续子串的shift table来确认按位匹配出错时,子串需要往右移动多少位,基本思想是“需要将子串往右移多少,才能使当前子串末尾对应的字符串元素再次与子串中最靠右的同名元素匹配”。
创建shift table,初始化shift table中元素为字符串中元素范围的所有元素。
遍历shift table:
- 如果遍历的元素不在子串前n-1个中,将shift table中该元素的偏移值记为子串长度
- 如果遍历的元素在子串前n-1个中,将shift table中该元素的偏移值记为子串前n-1个中最右方的相同元素到子串结尾的距离。
使用shift table找子串位置:
- 将从后向前对比子串与对应字符串的元素,如果某个位置上的元素不相等就将子串往后挪动。
- 具体挪多少得看子串最后一位对应的字符串元素,按照该元素在shift table中的偏移值挪动子串。
- 重复以上操作直到所有子串元素都能对应字符串
例题:给一子串求shift table,BAOBAB, 去掉最后一位→BAOBA_,下面以这个去掉最后一位的残缺串讨论
范围为26个字母,所以table长为26
残缺串的_往左数1位到A,A对应1
残缺串的_往左数两位到B,B对应2
残缺串的_左边没有C,C对应子串长度6
…
图的最短路径
单起点最短路径(Single-source shortest paths)
从一个起点到别的点的最短路径
边权值非负: Dijkstra’s Algorithm
边权值可负:Bellman-Ford Algorithm
Bellman-Ford Algorithm
该算法允许出现负权有向边,但是不允许出现负权回路
算法维护一个记录点的走法和距离值的集合T:
算法定义一个操作 松弛(a,b):
- 对于边(a,b),遍历所有点集,检查是否有点f可使 a的距离值+(a,f)+(f,b)
算法:
- 对所有在边集里的边(j,k),进行一次松弛(j,k),如果出现更小的k的距离值,更新k的距离值,否则代表没有从j之外的地方到k可以使k距离值变少。
- 由于松弛过后出现了新的距离值,需要重复以上操作直到某次对边集的松弛没有使点的距离值减少。如果上述操作进行了超过V-1次,怎么循环都能更新距离值,则图中存在负权回路。
例题,按行看,红线隔开的行代表从之前行中选择了节点
红线区域之内的两行代表将该点作为松弛时的b点,其他所有点作为a点进行松弛
多源最短路径
Floyd Algorithom(All-pairs shortest paths)(O(n3))
各个点到各个点的最短路径,不能有负权回路
维护记录了点到点距离值的邻接矩阵。
假设一共有n个城市,对于邻接矩阵e,依次假设将第k个城市作为中转,看是否有两城市 i,j 通过这个中转城市走路更近些
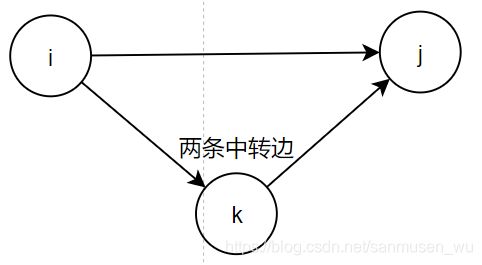
for(k=1;k<=n;k++)
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(e[i][j]>e[i][k]+e[k][j]):
e[i][j]=e[i][k]+e[k][j];
例题
看每个矩阵,十字型排列既是讨论十字里面的有向边作为两条中转边去更新其他边距离值(不包括交叉处的0)

如:
第一幅矩阵D(0)中的十字作为坐标轴,计算轴间值之和,发现可以更新出来个5和9,比目前的无穷小,于是把无穷变成5和9
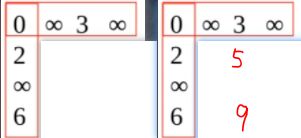
类推即可
构建传递闭包
传递闭包内点a若能中转到达点b,则有(a连b)这条线。
Warshall’s Algorithm(O(n3))
算法维护一个状态矩阵,1表示a点可达b点,0表示不能达到。
- 对矩阵所有点,检查上个矩阵中该点状态是否为1,或者是否存在中转点,使两点间可连通,存在则更新为1。其他情况该点状态为0。
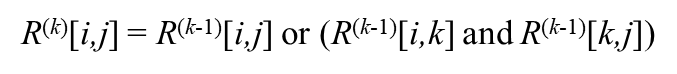
- 重复上述操作直到没有进行更新任何点的状态
for(k=1;k<=n;k++)
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
transitiveClosureMatrix[i,j] = transitiveClosureMatrix[i,j] or transitiveClosureMatrix[i,k] and transitiveClosureMatrix[k,j]
例题:

依旧是红十字,
比如R0中,把十字看成坐标轴,坐标轴间进行并计算,发现二行三列出来个1,于是R1中二行三列更新为1
week9 查找最长相同子序列
最长相同子序列问题(LCS Intuitive Solution)
Leetcode:最长公共子序列
给定两字符串,可以在保留他们顺序的前提下提取部分元素组成子序列,也就是子序列可以不连续取,要求求解最长且相同的子序列,下面是两种解决方法:
爆算
字符串构造2n个子序列,看是否也是另一个字符串的子序列,直到找到最大且符合条件的子序列,O(2n)
dp
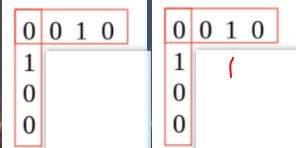
维护一个当前的最长子序列数值c[i,j],依次从1迭代到总长度(或者用递归从总长度递归到1)。
迭代方程,
第一行表示有一序列为空,
第二行表示当前两序列最后一位相同,直接引用上一个dp的结构,
第三行表示当前两序列最后一位不同,试图gap其中一个从以往dp中找最大值:
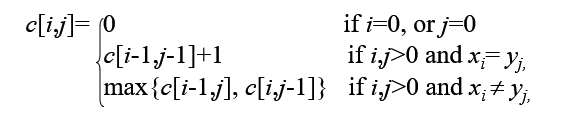
例题,寻找ABCBDAB与BDCABA的最长子序列
算出dp后,右下角的值就是最长子序列长度
从右下角向左上回溯可以得出子序列,深色斜着的箭头代表取当前x轴和y轴元素
也就是BCBA和BCBA

双序列比对问题(Pairwise Sequence Alignment Problem)
给定两个序列,遍历并比对序列元素,根据元素比对结果按照打分表上对应的score值累加score。求解比对到末尾为止,最大的总的score(两串序列的相似度)
全局比对dp
维护一个当前最大score的二维矩阵,依次从1,1迭代到各自的总长度(或者从各自的总长度递归至1,1)。
举个例子,现在比对字符串abc和abh,求现在最大的score,在以下三种中选最大
- 取ab和ab的socre加上c,h的打分表值
- 取ab和abh的score加上一个gap的值(因为ab短于abh),暂时忽略c
- 取abc和ab的score加上一个gap的值(因为ab短于abc),暂时忽略h
迭代方程:
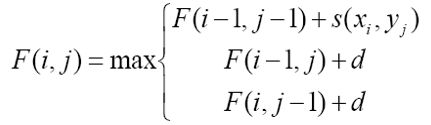

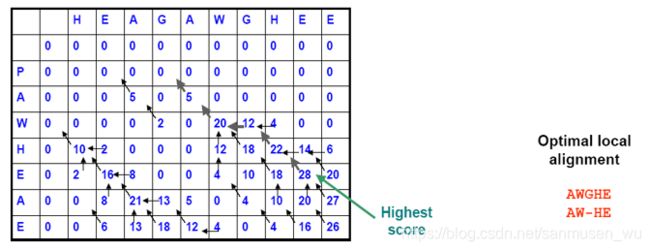
局部比对(Local alignment)
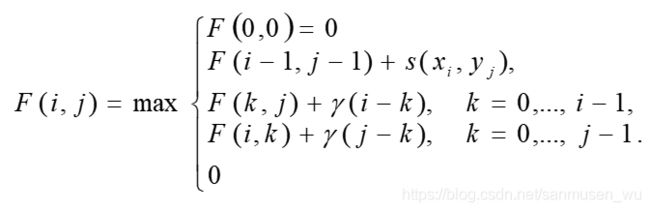
可以得到有较高相似度的子序列,部分比对的dp与全局比对的dp差不多,但是每次迭代时当前score最小为0,意味着迭代时max函数中多了一个常数0。
回溯dp的table
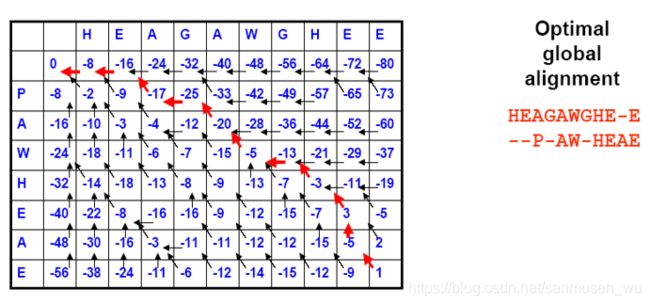
· 通过从全局比对的最终值(最右下角)回溯可以得出使两序列相似度最大的排列方式
· 通过从部分比对得出来的最大值位置回溯就能得出较高相似度的子序列的排列方式
其中垂直于当前序列方向的箭头表示那个轴当前位置的一个gap(空格),斜着的箭头没影响
如:
global:
对于横轴而言,竖着的箭头代表一个_
对于纵轴而言,横着的箭头代表一个_
local:
与global相似,不过是从最大值开始取
week 10 NP问题
P指Polynomial Time,多项式时间(指数不含n),P问题表示可以在多项式时间内求出解的问题(哈密顿图Hamiltonian Circuit(一笔画问题),背包问题Knapsack Problem,Circuit-SAT问题)
Circuit-SAT问题
给定一布尔电路表达式,检查是否存在一种输入,使得其结果可满足为1(satisfiability)。
范式(Normal form (NF))
这边引用同站的帖子解释链接
————————————————
析取 (Disjunctive) 就是或操作 (∨)。那些仅由或运算符连接而成的布尔表达式称之为 析取子句 (Disjunctive clause)。如 ( a ∨ b ∨ ¬ c ) 。
合取 (Conjunctive) 就是与操作 (∧)。那些仅由与运算符连接而成的布尔表达式称之为 合取子句 (Conjunctive clause)。如 ( a ∧ b ∧ ¬ c ) 。
合取范式 (Conjunctive Normal Form)
是命题公式的一个标准型,它由一系列 析取子句 用 合取操作 连接而来。如 ( a ) ∧ ( a ∨ ¬ c ) ∧ ( b ∨ c )。
析取范式 (Disjunctive Normal Form)
是命题公式的另一个标准型,它由一系列 合取子句 用 析取操作 连接而来。如 ( a ) ∨ ( a ∧ ¬ c ) ∨ ( b ∧ c )。
————————————————
判断问题和最优化问题
判断问题(Decision problems)
输出为1或0的问题–Circuit-SAT问题。存在不能被算法解决的判断问题。
Halting Problem (AlanTuring 1936):
“Given a computer program and an input to it, determine whether the program will halt on that input or continue working indefinitely on it.”
最优化问题(Optimisation problems)
试图找出使结果最大或最小的组合的问题–背包问题
最优化问题可以变为判断问题,例如,背包问题中给一待定解,询问算法是否存在能使背包更值钱,更轻的解法。
如果判断问题是复杂(hard)的,那么最优化问题也是hard的。
解决(solving)问题和判别(verifying)待定解
解决一个问题往往比较复杂,但验证一个待定解candidate是否正确certificate则比较简单。
例如:Circuit-SAT问题中,给定一个输入,咱们能够验证这个输入的结果是否为1,进而为判断问题提供正确解。
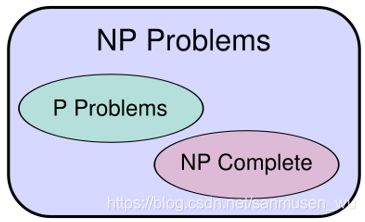
P和NP复杂类
P复杂类(Complexity Classes P )
能够在多项式时间内解决的问题集合(MST,Single-source-shortest-path)
NP复杂类(Complexity Classes NP )
算法求解过程是不确定的Nondeterministic,但是能够在多项式Polynomia时间内验证一个待定解是否正确的问题集合(Hamiltonian circuit,Knapsack problem,Circuit-SAT)
P类是NP类的子类
多项式规约(Polynomial-time reduction)
对于判断问题A,B,如果存在一转换关系,可以将待定解a转化为待定解b,当且仅当问题B有解的时候问题A有解,则称A规约B(A is reducible to B), 符号为A≤pB,意味着B至少和A一样难,或者说A是B的一个子类问题。进一步说,如果B存在一个高效算法,则A也存在一个高效算法。
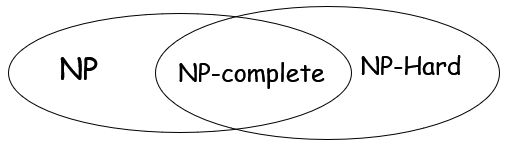
NP-hard
如果NP问题都多项式制约于一个问题M,则称该问题M为NP-hard问题。
NP-complete
如果M既是NP问题,又是NP-hard,则M为NP-complete问题。
或者另一种表述
即是NP问题,又被其他NP问题多项式制约的问题M,M为NP-complete问题。
(Hamiltonian Circuit Problem,Knapsack Problem,Circuit-SAT)
NP=P?
如果P问题和NP-comlete问题存在非空交集,那么NP=P—》代表NP问题可以规约成一个NP-complete问题,象征着这些交集内的NP-complete问题下属NP问题都可以在多项式时间内求解,也就是存在NP问题多项式可解。
部分例题:
- 把最优化问题转述为判断形式
Given a weighted graph G and a source vertex a, find the shortest paths from a to every other vertex
----》
Given a weighted graph G, a source vertex a and a value k, are there shortest paths from a to every other vertex such that each path is of weight at most k ?
week11 回溯剪枝DFS算法设计
解决NP-hard问题有两种主要解决方案
- 求解精确解,但不一定能在多项式时间内得解(“提交结果:超出时间限制”)
- 在多项式时间内,求近似解
精确解策略(Exact Solution Strategies)
- 暴解(Brute Force)
- 回溯(Backtracking)
- 剪枝(Branch-and-bound)
- 动规(Dynamic Programming)
算法设计(Algorithm Design Techniques)
- 贪婪(Greedy
- 分治(Divide and Conquer)
- 动规(Dynamic Programming)
- 回溯(Backtracking)
创建状态空间树(state space tree),二叉树的节点记录的是值,状态空间树的节点记录的是当前待定解,一般来说精确解就在叶子节点中,算法整体就是对这颗树的DFS。
回溯就是找到一个叶子节点后继续DFS,寻找其他叶子,直到找到一个精确解或者全部叶子都找完。
剪枝(Prune)就是发现当前节点的子树不可能到达最优解,直接舍弃当前树枝,返回当前节点上一个节点继续DFS。
n皇后问题(n-Queens Problem)
国际象棋中,将n个皇后放到一个n x n方格中,使每行每列每对角线上只有一个皇后。
通过剪枝(不满足条件)回溯可以DFS所有排列方式,找到符合条件的。
哈密顿电路(Hamiltonian Circuit )
给定图要求一笔画
通过剪枝(重复走过某一节点)回溯可以DFS所有笔画方式,直到符合一笔画条件。
N数之和问题(Subset-Sum Problem)
给定一非负数组和数字t,从数组中选择若干个数字,使其总和为该特定数字t
剪枝(当前选择的数字之和大于t)回溯DFS所有选择,直到总和等于该特定数字。
指派问题(Assignment Problem)

将4个人分配到4个岗位,16种组合都有各自的工资,求解使总工资最少的分配方式(?ppt说的cost指的是工资吗)。
该算法有个剪枝策略,需要记录各个节点的下限,如果有节点下限高于现存最优解,则舍弃那个节点。
各个节点的下限计算方式为:
- 忽略已被分配的job那列,忽略已被分配的人那行
- 在剩下的工资表中,把每个人最低工资累加到下限值中
- 下限值再加上已被分配确定的那几个人的工资。
算法:
DPS状态空间树,剪枝:删除下限值高于现存最优解的节点及其子节点
找到叶子节点后,如果叶子节点的下限值低于现存最优解,则更新最优解。
例题:
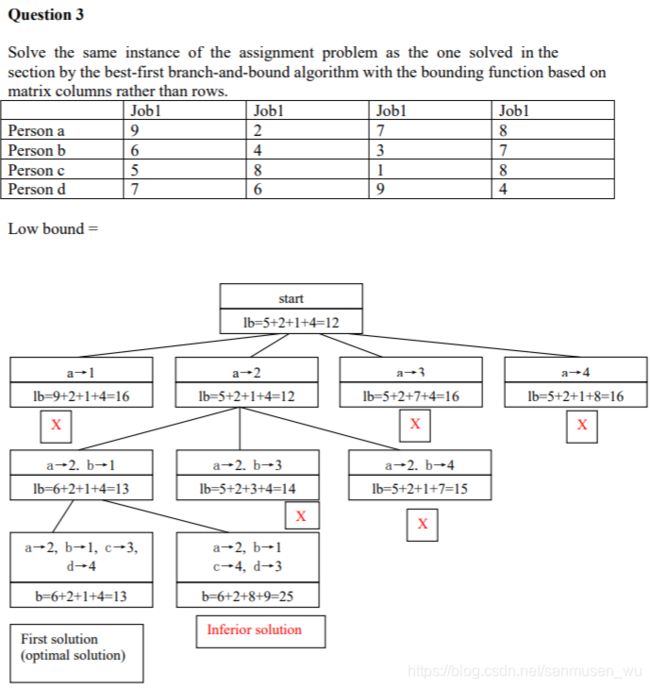
- 简便计算
- 可以看出来寻找第一个叶子节点的过程中,优先走下限值低的枝干,这样可以减去尽可能多的枝
- 在下面的旅行商问题中,旅行商走过的路径看上去是个圆环,也就是说顺时针走和逆时针走的距离一样,只是方向不同。通过规定某两个点间的先后顺序可以减少一半的讨论
旅行商问题(Traveling Salesman Problem)
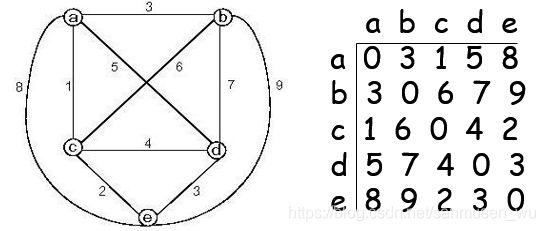
给定一无向图,要求算出旅行商从一点出发尽可能短地走过所有节点然后回到起点的走法。
依旧是剪枝,下限计算:
- 把已走过的边标记为必选的。
- 在邻接表中,每行选取两个值的平均数累加到下限值中,如果有被标记为必选的,则必选那个值,再选出尽可能小的数。
- 下限值再加上已走过的边的值。
每次在状态空间树中选择下限值最低的节点或多个下限值最低相等的节点,进入它的子树进行DFS选择如何走剩下几座城市,剪掉其他下限值较高的节点。
例题:
week12 更多动态规划dp
- 求小问题
- dp公式
- 基本情况(需要提前初始化)
一维动态规划问题 1-dimensional DP
目标和的加法式数量
例题:求出所有由1,3,4组成的和为5加法算式(如:1+1+3=5)的数量
大问题:在数组[a1,a2…am]中寻找和为n的加法算式有多少
如:1+1+1+1+1,1+1+3,1+3+1,3+1+1,1 +4,4 +1
子问题:假设ai必在大问题的加法算式内,在数组[a1,a2…am]中寻找和为n-ai的加法算式有多少
如:假设1在父问题的加法算式内,子问题既是求解1,3,4组成的和为5-1=4的加法算式的数量
假设3在父问题的加法算式内,子问题既是求解1,3,4组成的和为5-3=2的加法算式的数量
假设4在父问题的加法算式内,子问题既是求解1,3,4组成的和为5-4=1的加法算式的数量
dp自底部向上求解,算法维护一个数组,记录不同和的情况下加法式子的数量,和的值将从0逐渐迭代到大问题中的n(i会逐渐增加到n),D[n]即为问题答案
(基本情况base case:前 数组长度+1 个dp值需要先自己算):

贴砖 Troll Tiling
问题:用2x1的小砖块铺满3xn的区域
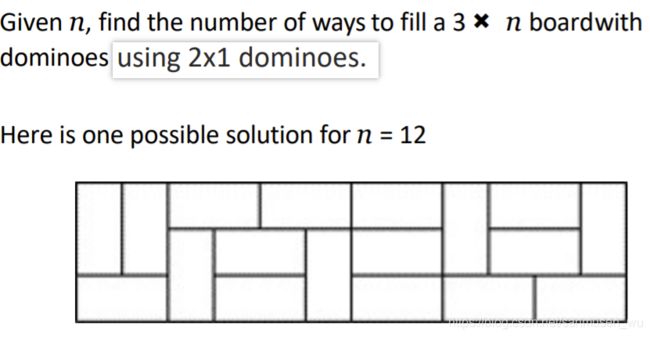
问题以二维表述,但仍然是个一维dp问题。要点主要在于大问题和小问题之间的衔接过程。
算法维护两个一维数组,分别记录两种情况下的小瓷砖排列情况。
大问题是正好摆放n列,小问题是正好摆放n-1列
首先讨论子问题的两种情况,当我们尽可能照样子按照每列排放 j 列小瓷砖时,可能:
- 最右边一列(这里是n-2列)中能够铺满三个小格子(下图白色),此时白色的铺法为F(n-2)
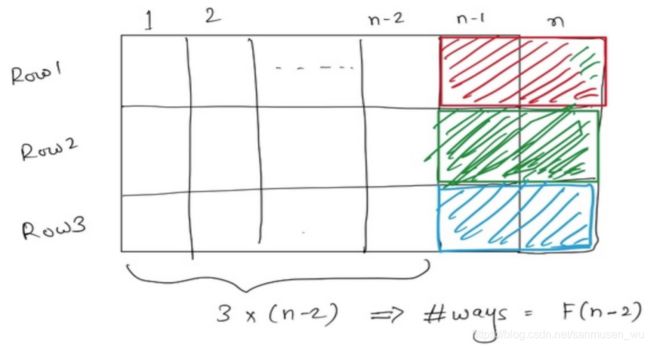
- 最右边一列(这里是n-1列)中铺满了两个小格子,空出一个(可能空下方的,可能空上方的)下图白色.
此时白色的铺法称为G(n-1),当然因为空法不同,所以这个方法包含两个G(n-1)
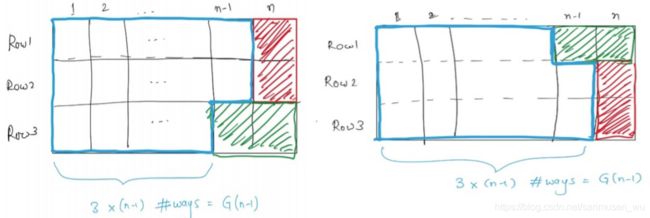
对于以上两种情况:
-
观察其边界,发现铺下一个情况1且不违反其定义的铺法各自有一种和两种(彩色)。
(为什么第一种情况三个彩色的小瓷砖只能全横着铺:
···· 竖着铺的途中会变成第二种情况,禁止情况间交叉)
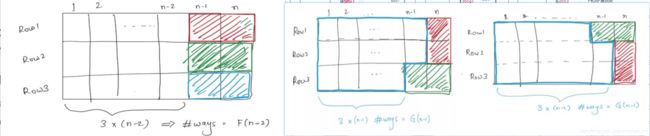
-
观察其边界,发现铺下一个情况2且不违反定义的铺法各自有一种和一种(彩色)
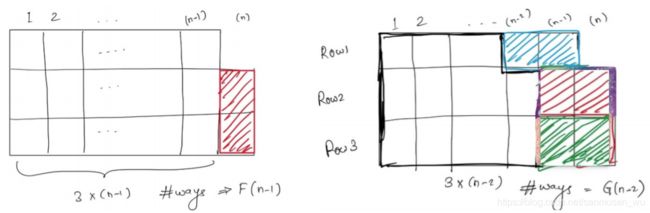
最后分析大问题与子问题的关系:
(基本情况base case:只有0,1,2 列时的G(),F()的值)
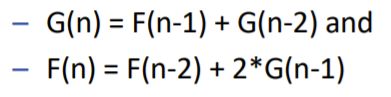
二维动态规划问题 2-dimensional DP
LCS Problem
week9讲过了,可以看出dp是以二维table的形式体现。
间隔DP Interval DP
给定一字符串,添加最少的字符,使字符串变成对称的回文字符串 (palindrome)
Example:
– x: “Ab3bd”
– Can get “dAb3bAd” or “Adb3bdA” by inserting 2 characters (one ‘d’, one ‘A’)
将字符串看成滑块,左边界i和右边界j可以滑动。
大问题:字符串需要添加至少多少字符使之回文
子问题:左右边界同时向内移1的字符串需要添加至少多少字符使之回文
dp维护一个table,记录不同滑块范围时使之回文的添加的字符数
问题间关系:
如果内移掉的字符与另一侧内移掉的字符不同,则需要 一侧不移动的子问题的dp值 加上一个另一侧的内移掉的额外字符 使之回文,在两侧之间找最小。
如果内移掉的字符与另一侧内移掉的字符相同,代表该次dp不要添加字符,大问题与子问题dp值相同。
基本情况base case:dpi,i,dpi,i-1=0 for all i
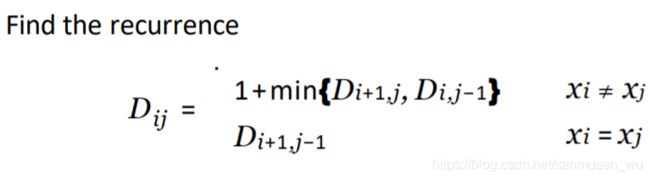
Tree DP
问题:

直接贴dp式子了,
v:根节点
Bv:根节点为黑色,其子树的最大黑色数量
Wv:根节点为白色,其子树的最大黑色数量
dp从叶子推到树根

dp背包问题 Knapsack 0-1 Example
大问题:物品有重量和价值,给定一限重为5的背包,怎样挑选物品使背包内价值最大
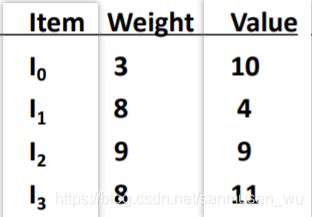
dp思想大问题:物品有重量和价值,dp可供挑选的物品范围和限重从0到w的背包,求每次dp怎么在当前可选的物品范围挑选物品使物品价值最大
wi:当前dp背包限重
vt:当前dp预拿取物品的价值
dpi,w:当前dp背包最大价值
wt:当前dp预拿取物品的重量
子问题:背包限重缩小1,或者物品范围缩小1,或者物品范围缩小1同时背包限重缩小1
自底向上:
大问题与子问题的关系,随着背包的容量逐步上涨和物品范围的扩大,会出现两种情况:
- 新的物品可以单独进背包,此时考虑拿还是不拿,二者选最大
(例如,dp限重为10的时候物品范围新增了一个重量为10的物品,这时就要判断是维持限重为9时的配置还是单独拿重量为10的那一个物品)- 拿的话为了使当前dp最优,应当按照拿取当前物品后剩下来的重量所在的dp值算当前dp,当前价值dpi,w应该等于dpi,w-wt+vt
也就是与上次比物品范围变大,容量上涨,价值变动 - 不拿的话当前dpi,w=dpi-1,w
也就是与上次比物品范围变大但是不拿,容量上涨,价值与上次一样
- 拿的话为了使当前dp最优,应当按照拿取当前物品后剩下来的重量所在的dp值算当前dp,当前价值dpi,w应该等于dpi,w-wt+vt
- 新的物品压根塞不进背包,wt>wi,单个物品重量大于限重,此时dpi,w=dpi-1,w,
也就是物品范围没法变大,容量上涨一格,价值与上次一样
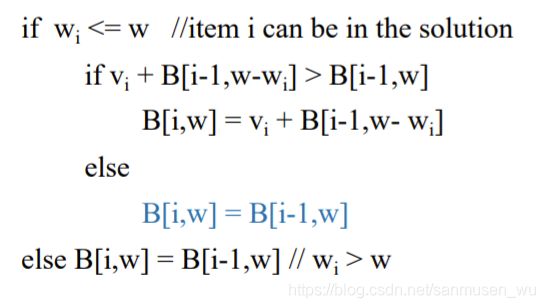
以下既是推至背包限重为5,物品范围为4的情况
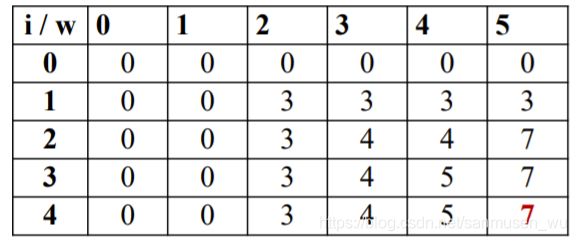
根据这个dp table可以从取值方向逐渐逆推至最佳拿取组合
从右下角7开始:(4,5,7)-没拿-(3,5,7)-没拿-(2,5,7)-拿2-(1,2,3)-拿1-(0,0,0)
拿取的物品有2和1
算法复杂度O(n*W)
week13 近似求解
NP-completeness 问题是没办法在多项式时间求最优解的,
但是可以用较好的方法在多项式内求得足够优秀的解
三种思路:
爆算 Brute-force algorithms
枚举所有解;能找到最优,没法保证运行时间
启发法 Heuristics
开发直观算法intuitive algorithms;不确定找的是最优,可以保证多项式时间
基于先验规则(或者说经验)的方法,例如:TSP问题中下一个选最近的城市走,背包问题选价质比最高的物品。
近似算法 Approximation algorithms
可以保证找到最优解的近似值(误差很小);可以保证多项式时间
准确率Accuracy Ratio
在最优化极小值问题中r(sa) = f(sa)/f(s*) =近似算法结果/最优解结果
在最优化极大值问题中r(sa) = f(s*)/f(sa) =最优解结果/近似算法结果
c-approximation algorithm
常数c≥1,能使得对于任意参数的一种问题(all instance of a problem)的准确率都能≤c的算法叫做c近似算法
在这之中最小的c被称为performance ratio,RA
不幸的是c几乎没有上限。
if P≠NP, no c-approximation algorithm for TSP exists.
近似解顶点覆盖问题VERTEX-COVER
问题:给定一无向图,找到一个最小的点的集合,使无向图中的线至少有一个端点在该集合中。
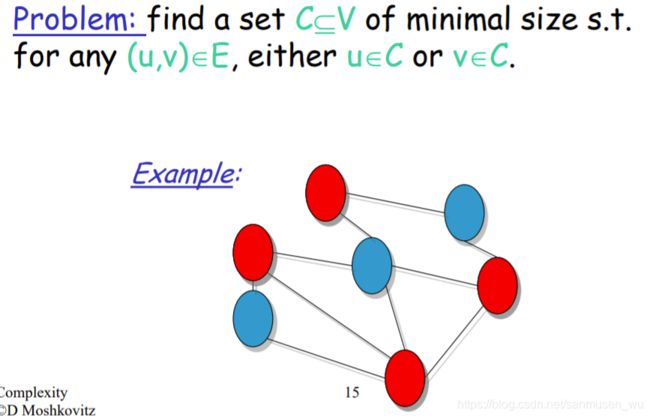
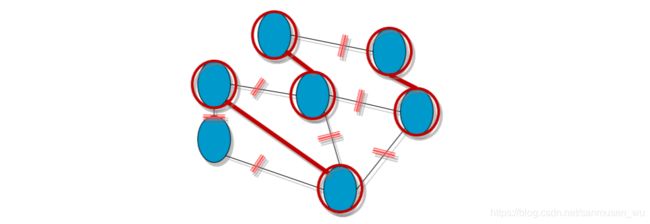
VC - Approximation Algorithm:把问题近似解
随机选一个边及其两端点,然后在图中去掉与这个边的两点相连的所有边,重复直到未选边为空

近似解的一个结果:
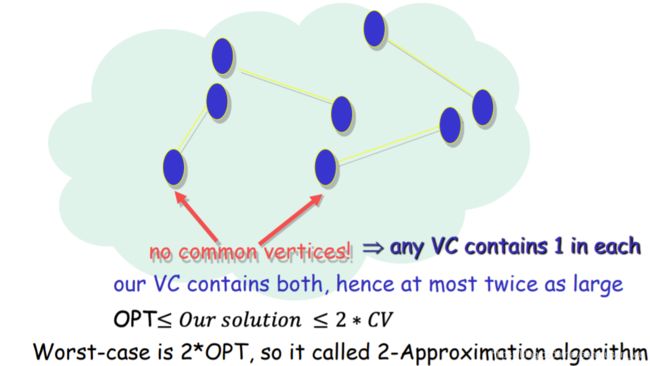
评估VC问题的近似算法:
显然不是OPT(最优)的,按理来说最优解中的点之间应该尽可能不相连以分散所有点而减少点的数量,但是近似解法要求每对被选取的连线同时取其两端点。
近似解TSP问题
Nearest-neighbor
旅行者下一步走向离自己最近且未走过的城市
但是这个近似解准确度与最后一条边关联性大,因为最后一条边无论多长都得走
Euclidean instances
既要求城市满足2d地图的自然几何学(natural geometry):
也就是两城市之间直接相连的距离要短于经过中转城市的距离
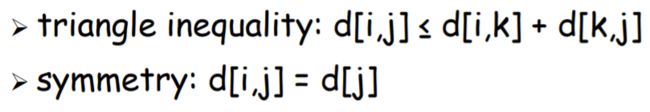

Multifragment-heuristic
把边按照距离从小到大排列,每次选择一个边加入集合,要求:
- 新的边不会使集合内的任意一点出现三个度
- 新的边不会使n-1之内的点形成环
比nearest-neighbor复杂,正确率相同
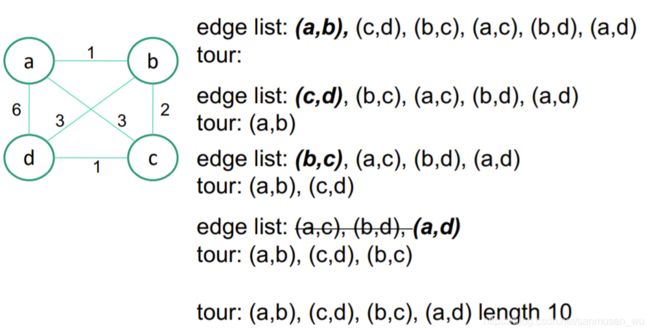
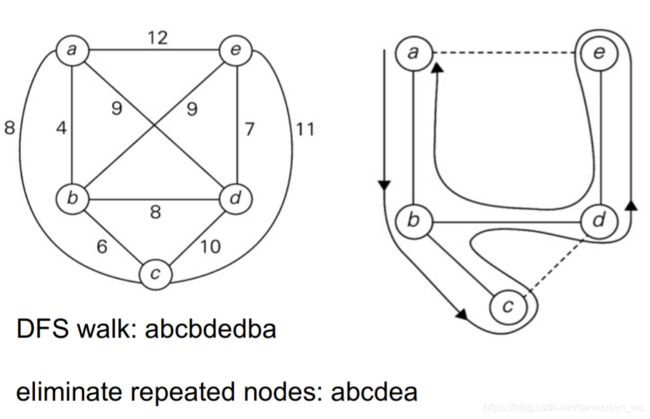
Twice-Around-the-Tree Algorithm
- 创建图的最小生成树
- 从生成树的一个点开始,按照最外围依次走过所有点并返回至起始点,所有点都被走了两次
- 尝试添加新的边(捷径)进入生成树,使需要重复走两次的点的数量减少至1(起始点)
往往比nearest-neighbor算法的正确率高
完