(论文阅读笔记)Data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
本文仅为翻译
摘要
虽然自我监督学习的总体思想在不同的模式中是相同的,但实际的算法和目标却有很大的不同。为了让我们更接近于一般的自我监督学习,我们提出了data2vec,一个对语音、NLP或计算机视觉使用相同学习方法的框架。其核心思想是使用标准Transformer体系结构下的自蒸馏(self-distillation),根据输入的隐藏视图预先记录完整输入数据的潜在表示。Data2Vec预测的是包含整个输入信息的情境化潜在表示,而不是预测特定于模态的目标,如单词、视觉标记或人类语音单元(本质上是局部的)。
1 简介
为了更接近以更通用的方式学习环境的机器,我们设计了data2vec,这是一个通用自监督学习框架,适用于图像、语音和文本,其中学习对象在每种模式中都是相同的。目前的工作统一了学习算法,但仍然分别学习每个模态的表示。我们希望,单一算法将使未来的多模式学习更简单、更有效,并通过多种模式产生更好地理解世界的模型。
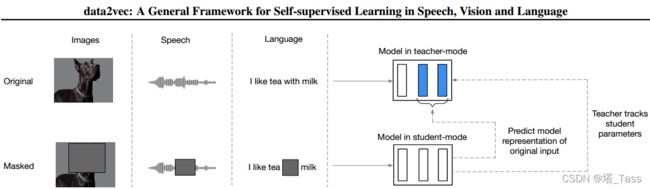
我们的方法将Mask预测与潜在目标表示的学习相结合,但通过使用多个网络层作为目标对后者进行了推广,并表明该方法可以跨多模态工作。具体来说,我们训练一个现成的Transformer网络,我们在教师或学生模式下使用它(图1):
我们首先构建完整输入数据的表示,其目的是作为学习任务的目标(教师模式)。接下来,我们对输入样本的Masked版本进行编码,用它预测完整的数据表示(学生模式)。教师的权重是学生的指数衰减平均值。由于不同的模态具有非常不同的输入,例如像素与单词,我们使用文献中的模态特定特征编码器和Mask策略。由于我们的方法适用于学习者自身的潜在网络表示,因此可以将其视为许多特定于模态的设计的简化,例如学习固定的视觉标记集,或规范输入以创建合适的目标,或学习离散语音单元的词汇表。此外,通过自我注意,我们的目标表征是连续的和情境化的,这使得它们比基于局部语境的固定目标集和/或目标集更丰富,如在大多数以前的工作中使用的。实验结果表明,data2vec在所有三种模式下都是有效的。
2 相关工作
CV领域自监督
计算机视觉的无监督预训练一直是一个非常活跃的研究领域,其方法包括对比相同图像、完全不同图像的增强表示以及在线聚类。与我们的工作类似,BYOL和DINO都对动量编码器的神经网络表示进行了回归,但我们的工作不同之处在于,它使用了一个隐藏的预测任务,我们回归了多个神经网络层表示,而不是我们发现更有效的顶层表示。此外,我们还证明了我们的方法适用于多元数据。
最近的一些工作重点是训练Vision Transformer,这些Transformer具有Masked的预测目标。其中一些方法预测在预训练之前在单独步骤中学习的tokens,而另一些方法则直接预测输入像素。相反,data2vec预测输入数据的潜在表示形式。这一系列工作的另一个不同之处在于,潜在目标表示是情境化的,包含了整个图像中的相关特征,而不是包含与当前补丁隔离的信息的目标,(如视觉tokens或像素)。
NLP领域自监督
预训练在促进自然语言理解方面非常成功。最突出的模型是BERT,它解决了一个Masked预测任务,其中一些输入tokens被Mask掉,以便在给定剩余输入的情况下进行预测。对于许多语言来说,确定单词边界是很容易的,因此大多数方法都可以预测单词或子单词单元,以便进行预训练。还有关于知识蒸馏的工作,以获得更小的类BERT模型,用于预训练和微调。
与以前的NLP算法相比,data2vec不预测离散的语言标记(如单词、子单词或字节),而是一种连续的上下文表示。这有两个优点:第一,目标本身不是预定义的,其数量也不受限制。这使模型能够适应特定的输入示例。第二,目标是语境化的,考虑了语境信息。这与BERT模型不同,BERT模型为每个目标学习单个嵌入,需要在数据中拟合特定目标的所有参数。
3 方法论
Data2vec通过预测给定输入部分视图的完整输入数据的模型表示来进行训练。我们首先对训练样本的Masked版本(学生模式下的模型)进行编码,然后通过使用相同模型对输入样本的未Mask版本进行编码来构建训练目标,但参数化为模型权重的指数移动平均值(教师模式下的模型)。目标表征对训练样本中的所有信息进行编码,学习任务是让学生在给出输入部分视图的情况下预测这些表征。
3.1 模型结构
我们使用标准Transformer架构,对先前工作中获得的输入数据进行模态特定编码:
对于计算机视觉,我们使用ViT策略将图像编码为一系列patches,每个patches为16x16像素,输入到linear transformation模块。
使用多层1-D卷积神经网络对语音数据进行编码,该网络将16 kHz波形映射到50 Hz表示。
文本经过预处理以获得子单词单元,然后通过可学习的embedding向量将其嵌入分布空间。
3.2 MASKING
在将输入样本作为token序列进行embedding之后,我们通过使用已学习的Masked embedding token替换它们来屏蔽这些样本的一部分,并将序列馈送到变压器网络。对于计算机视觉,我们遵循Bao等人(2021)的分块Mask策略,对于语音,我们Mask潜在语音表示的范围,对于语言,我们掩蔽tokens。
3.3 训练目标
对模型进行训练,以根据Masked样本的编码预测原始未 Mask的训练样本的模型表示。我们预测的模型代表性仅为被Maksk的time-step。我们预测的表征是情境化表征,编码特定的time-step,但由于Transformer网络中Self-attention的使用,还编码来自样本的其他信息。这与BERT、wav2vec 2.0 orBEiT、MAE、SimMIM和MaskFeat是一个重要区别——它们预测缺乏上下文信息的目标。下面,我们将详细介绍如何参数化teacher模型,以预测将用作目标的网络表示,以及如何构建最终目标向量,以便在student模式下由模型预测。
Teacher参数化
未Mask训练样本的编码由模型参数的指数移动平均值(EMA)参数化,其中目标模式Δ下模型的权重由下式给出:
Δ←τΔ+(1−τ)θ
在第一次![]() 更新期间,将该参数从
更新期间,将该参数从![]() 线性增加到目标值
线性增加到目标值![]() ,之后该值在剩余的训练中保持不变。这种策略的结果是,当模型是随机的时,教师在训练开始时更新的频率更高,而在训练后期,当已经学习到好的参数时,更新的频率更低。我们发现在教师和学生网络之间共享特征编码器和位置编码器的参数更有效,更精确。
,之后该值在剩余的训练中保持不变。这种策略的结果是,当模型是随机的时,教师在训练开始时更新的频率更高,而在训练后期,当已经学习到好的参数时,更新的频率更低。我们发现在教师和学生网络之间共享特征编码器和位置编码器的参数更有效,更精确。
目标
训练目标是基于教师网络的topK个block的输出构建的,time-step在学生模式下被Mask。在time-step为t处第l个block的输出表示为![]() 。我们对每个块应用归一化得到
。我们对每个块应用归一化得到![]() ,然后对topK个块的输出算平均:
,然后对topK个块的输出算平均:
![]()
如此获得time-step为t处对应的训练目标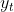 。这将创建在学生模式下由模型回归的训练目标。在初步实验中,我们发现,计算平均值和单独预测每个块同样有效,并且具有更加高效的优势。
。这将创建在学生模式下由模型回归的训练目标。在初步实验中,我们发现,计算平均值和单独预测每个块同样有效,并且具有更加高效的优势。
对目标进行规范化有助于防止模型在所有time-step中崩溃为常数表示,还可以防止具有高规范化的层控制目标特征。对于语音表示,我们在当前输入样本上使用实例归一化(Instance-wise),而不使用任何学习参数,因为相邻表示由于在输入数据上的小跨步而高度相关,而对于NLP和CV,我们发现无参数层归一化(Layer-wise)就足够了。方差不变性-协方差正则化也解决了这个问题,但我们发现上述策略表现良好,并且没有引入额外的超参数。
3.4 目标函数
给定情境化训练目标,我们使用平滑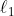 损失回归这些目标:
损失回归这些目标:
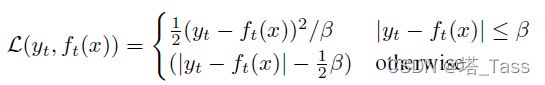
其中,β控制从![]() 损失到损失的转变,这取决于目标和time-step为t处的模型预测值
损失到损失的转变,这取决于目标和time-step为t处的模型预测值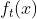 之间的差距大小。这种损失的优点是它对异常值不太敏感,但是,我们需要调整β的设置。
之间的差距大小。这种损失的优点是它对异常值不太敏感,但是,我们需要调整β的设置。