Describing like Humans: on Diversity in Image Captioning
Describing like Humans: on Diversity in Image Captioning
原文地址
时间:2019 CVPR
Intro
当前的image captioning模型虽然在各种指标(BLEU METEOR ROUGE CIDEr)上超过了人类水平,但是这些以accuracy为度量甚至是训练目标的模型缺少了diversity,为此,本文提出了一个度量图片diversity的metric。
diversity包括三个层次:
- word diversity指仅仅替换某个词而不影响语义
- syntactic diversity指在词序、词组和句子结构上的不同
- semantic diversity值描述的概念、细节、主体、客体上的不同
本文主要衡量的就是semantic diversity
Motivation
- 一张图片胜过千言万语,图片中包括了各种不同的概念,因此对它的描述是多样性的
- 仅仅注重accuracy会导致模型产生常见的短语来避免错误
- diversity可以度量captioner的variance
Measuring Diversity of Image Captions
为了度量一个caption集合 C = c 1 , c 2 , . . . , c m \mathcal{C}={c_1,c_2,...,c_m} C=c1,c2,...,cm,需要考虑两Gee方面:accuracy和diversity,对于accuracy,传统方法是计算平均相似度得分,对于diversity,我们会考虑caption集合 C \mathcal{C} C中成对的相似度
Latent Semantic Analysis
latent semantic analysis(LSA)是一个线性模型,被广泛用于information retrieval中。LSA考虑co-occurrence的信息(words或者n-grams),然后使用奇异值分解来得到不同topic的低维的表示,将LSA应用在caption set中,更多的topic则意味着更多的diversity,为了使用LSA,首先要将每个caption用向量表示,这里使用bag-of-words(BoW),然后在下一小节使用CIDEr将它kernelize
给定一个caption集合 C = c 1 , c 2 , . . . , c m \mathcal{C}={c_1,c_2,...,c_m} C=c1,c2,...,cm和一个字典 D = w 1 , w 2 , . . . , w d \mathcal{D}={w_1,w_2,...,w_d} D=w1,w2,...,wd,我们用词频来表示一个caption c i c_i ci, f i = [ f 1 i , . . . , f d i ] T \mathbf{f_i}=[f_1^i,...,f^i_d]^T fi=[f1i,...,fdi]T,其中 f j i f_j^i fji表示词 w j w_j wj在 c i c_i ci中出现的频率,从而caption集合 C \mathcal{C} C可以表示为word-caption矩阵 M = [ f 1 , . . . , f m ] M=[f_1,...,f_m] M=[f1,...,fm]???(没考虑词序)
通过SVD分解, M = U S V T M=USV^T M=USVT, S = d i a g ( σ 1 , . . . , σ m ) S=diag(\sigma_1,...,\sigma_m) S=diag(σ1,...,σm)是对角矩阵,其中的每个奇异值都表示了topic的强度,如果 C \mathcal{C} C中只有一个caption,则 σ 1 = 1 , σ i = 0 , i > 1 \sigma_1=1,\sigma_i=0,i>1 σ1=1,σi=0,i>1,如果每个caption不一样,则所有奇异值是一样的(?怎么就一样了),因此, r = σ 1 ∑ i = 1 m σ i r=\frac{\sigma_1}{\sum_{i=1}^m\sigma_i} r=∑i=1mσiσ1则表示了caption的diversity,因为 r r r在[1/m,1]之间,因此我们可以把他映射到[0,1], d i v = − log m ( r ) div=-\log_m(r) div=−logm(r)
考虑矩阵 K = M T M K=M^TM K=MTM,其中每个元素 k i j = f i T f j k_{ij}=f_i^Tf_j kij=fiTfj是BoW向量 f i f_i fi和 f j f_j fj的内积,因为 f i f_i fi的维度可能很大,更好的计算方法是使用特征值分解 K = V Λ V T K=V\Lambda V^T K=VΛVT,其中 Λ = d i a g ( λ 1 , . . . , λ m ) \Lambda=diag(\lambda_1,...,\lambda_m) Λ=diag(λ1,...,λm),是 K K K特征值,则 σ i = λ i \sigma_i=\sqrt{\lambda_i} σi=λi,注意 K K K是一个核矩阵,这里使用的是线性核
Kernelized Method via CIDEr
上一节的diversity度量方法忽略了词组和句子的结构,为了解决这个问题,这里使用n-gram或p-spectrum核,映射函数使用n-gram将caption空间 C C C映射到特征空间 F F F,
![]()
其中 f i n ( c ) f^n_i(c) fin(c)是第i个n-gram的频率, D n D^n Dn是n-gram的字典
CIDEr现将caption映射到带权特征空间 F F F, Φ n ( c ) = [ w i n f i n ( c ) ] i \Phi^n(c)=[w_i^nf_i^n(c)]_i Φn(c)=[winfin(c)]i其中 w i n w^n_i win是第i个n-gram的IDF,CIDEr得分是每个n的余弦相似度
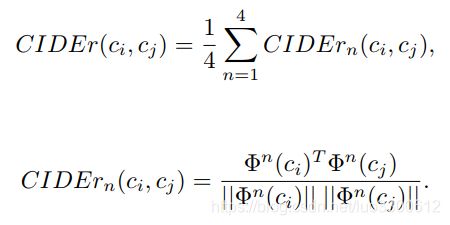
其中feature space被 Φ n ( c ) \Phi^n(c) Φn(c)映射
因为CIDEr可以被解释为一个核函数,我们可以重新考虑LSA中的矩阵 K K K,通过使用 k i j = C I D E r ( c i , c j ) k_{ij}=CIDEr(c_i,c_j) kij=CIDEr(ci,cj),基于CIDEr的diversity可以通过核矩阵的特征值KaTeX parse error: Expected '}', got '\lamdba' at position 16: {\lambda_1,...,\̲l̲a̲m̲d̲b̲a̲_m}计算为 r = λ 1 ∑ i = 1 m λ i r=\frac{\sqrt{\lambda_1}}{\sum_{i=1}^m\sqrt{\lambda_i}} r=∑i=1mλiλ1, d i v = − log m ( r ) div=-\log_m(r) div=−logm(r)
Conclusion
本文设计了一个度量image caption模型的diversity的制表,它基于CIDEr根据核矩阵计算特征值得到