梅尔倒谱系数matlab,科学网—声学信号处理基础最佳入门(译):(一)梅尔频率倒谱系数(MFCC) - 洪峰的博文...
任何自动语音识别系统的第一步是提取特征,即识别音频信号的组成部分,这些组成部分有助于识别语言内容,并丢弃所有其他携带的诸如背景噪声、情绪等信息的东西。
理解语音的要点是人类产生的声音被声道的形状过滤,包括舌头,牙齿等。这种形状决定了声音是什么样的。 如果我们能够准确地知晓该形状,我们就能准确地表示其产生的音素(phoneme)。 声道的形状以短时功率谱的包络的形式表现出来,而MFCC的作用就是是准确表示这个包络。 本文将介绍有关MFCC入门知识。
Mel频率倒谱系数(MFCC)是一种广泛用于自动语音和说话人识别的特征。 它们是 Davis和Mermelstein在20世纪80年代引入的,迄今为止一直都是最先进的。 在引入MFCC之前,线性预测系数(LPC)和线性预测倒谱系数(LPCC)(点击此处获取关于倒谱和LPCC的教程:http://www.practicalcryptography.com/miscellaneous/machine-learning/tutorial-cepstrum-and-lpccs/)并且曾是自动语音识别(Automatic Speech Recognition,ASR)的主要特征类型,特别是对于HMM分类器(http://practicalcryptography.com/miscellaneous/machine-learning/hidden-markov-model-hmm-tutorial/)。 本页将介绍MFCC的主要方面,为什么它们为ASR提供了一个很好的功能,以及如何实现它们。
步骤一览
我们将对下面的步骤进行高级介绍,并深入探讨为什么我们要做这些步骤。 到本文结尾,我们将详细介绍如何计算MFCC。
1. 将信号帧化为短帧。
2. 对于每一帧,计算功率谱的周期图估计(periodogram estimate, https://en.wikipedia.org/wiki/Periodogram)。
3. 将mel滤波器组应用于功率谱,将每个滤波器中的能量相加。
4. 取所有滤波器组能量的对数。
5. 对对数滤波器组能量求DCT。
6. 保持DCT系数2-13,丢弃其余部分。
还有一些常见的事情,有时帧能量会附加到每个特征向量的尾部。 Delta和Delta-Delta特征通常也会附加。 Liftering也常用于最终的特征。
我们为什么要做这些事情?
现在,我们将逐步介绍这些步骤并解释其必要性。
音频信号通常是不断变化的,为了简化,我们假设在短时尺度上音频信号没有太大变化(当我们说它没有变化时,我们的意思是统计上,即统计上平稳,而实际上样本甚至短时间尺度也是不断变化的)。这就是我们将信号帧化为20-40ms帧的原因。如果帧再短的话,我们没有足够的样本来获得可靠的频谱估计,如果帧越长,信号在整个帧中变化太大。
下一步是计算每帧的功率谱。这是由人耳蜗(human cochlea)(耳朵中的器官)启发的,它根据进入的声音的频率在不同的点处振动。根据耳蜗中振动的位置,不同的神经会向大脑发出消息,告知大脑存在某些频率。我们的周期图估计为我们执行类似的工作,识别帧中存在哪些频率。
然而,周期图频谱估计仍然包含自动语音识别(ASR)不需要的许多信息。特别地,耳蜗不能辨别两个紧密间隔的频率之间的差异。随着频率的增加,这种效果变得更加明显。出于这个原因,我们采集了一组周期图bins并总结它们以了解不同频率区域中存在多少能量。这是由我们的Mel滤波器组执行的:第一个滤波器非常窄,并指示在0赫兹附近存在多少能量。随着频率越来越高,我们的滤波器越来越宽,因为我们越来越不关心变化。我们只关心每个点大概产生多少能量。 Mel刻度告诉我们如何间隔我们的滤波器组以及设置它们的宽度为多少。请参阅下文,了解如何计算间距。
一旦我们有了滤波器组能量,我们就取它们的对数。这也是受人类听觉的启发:我们没有听到线性音阶的响度。通常,为了使声音的感知体积增加一倍,我们需要将8倍的能量投入其中。这意味着如果刚开始时声音很大,实际听起来却没有那么大的区别。这种压缩操作使我们的特征与人类实际听到的功能更加接近。那么问题来了,为什么是对数而不是立方根?对数允许我们使用倒频谱平均减法,这是一种信道归一化技术。
最后一步是计算对数滤波器组能量的DCT。这么做主要有两个原因。一来是因为我们的滤波器组都是重叠的,所以滤波器组能量彼此非常相关。而利用DCT可以实现对能量去相关处理,这意味着对角线协方差矩阵可用于对例如HMM分类器的特征进行建模。此外,26个DCT系数中只有12个被保留。这是因为较高的DCT系数代表滤波器组能量的快速变化,并且事实证明这些快速变化实际上是降低了ASR性能的,因此我们通过丢弃它们获得了小的改进。
什么是Mel尺度?
Mel音阶将纯音的感知频率或音调,与其实际测量频率相关联。 人们在识别低频时音高的微小变化方面比在高频时更好。 结合这种尺度,该特征与人类听到的特征更加接近。
频率->mel频率的转换公式为:
![]()
反过来则是:
![]()
实现步骤?
我们从语音信号开始,我们假设采样频率为16kHz。
1.将信号帧化为20-40 ms帧, 25毫秒是标准的。这意味着16kHz信号的帧长度为0.025 * 16000 = 400个样本点。帧步长(Frame step)通常类似于10ms(160个样本点),这允许各帧间有所重叠。第一个400样本帧从样本0开始,下一个400样本帧从样本点160等开始,直到到达语音文件的末尾。如果语音文件没有划分为总帧数为,则用零填充它以使其完成。
接下来的步骤应用于每个帧,为每个帧提取一组12个MFCC系数。一个简短的表示法:我们称
![]() 为时域信号。一旦将其分解为帧,我们就有
为时域信号。一旦将其分解为帧,我们就有
![]() 。这里n的范围在1-400(如果每帧是400个样本),而i的范围则是从0-总帧数-1。当我们计算复DFT时,我们得到
。这里n的范围在1-400(如果每帧是400个样本),而i的范围则是从0-总帧数-1。当我们计算复DFT时,我们得到
![]() - 其中
- 其中
![]() 表示对应于时域帧的帧编号,
表示对应于时域帧的帧编号,
![]() 就是帧
就是帧
![]() 的功率谱。
的功率谱。
2.要对帧进行离散傅里叶变换,请执行以下操作:
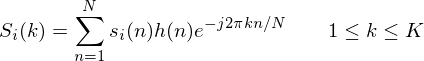
其中
![]() 是
是
![]() 点样本长的分析窗口(例如汉明窗口),
点样本长的分析窗口(例如汉明窗口),
![]() 是DFT的长度。 语音帧
是DFT的长度。 语音帧
![]() 的基于周期图的功率谱估计由下式给出:
的基于周期图的功率谱估计由下式给出:
![]()
这称为功率谱的周期图估计。 我们取复数傅里叶变换的绝对值,并对结果进行平方。 我们通常会执行512点FFT并仅保留前257个系数。
3.计算Mel间隔滤波器组。 这是一组20-40(26是标准)三角滤波器,我们将其应用于步骤2的周期图功率谱估计。我们的滤波器组由26个向量,每个向量长度为257(假设FFT设置如步骤2进行设置)组成。 每个向量大多为零,但对于频谱的某个部分不为零。 为了计算滤波器组能量,我们将每个滤波器组与功率谱相乘,然后将系数相加。 执行此操作后可以得到26个数值,这表明了每个滤波器组中的能量。 有关如何计算滤波器组的详细说明,请参见下文。 这是一个给出了示意图:
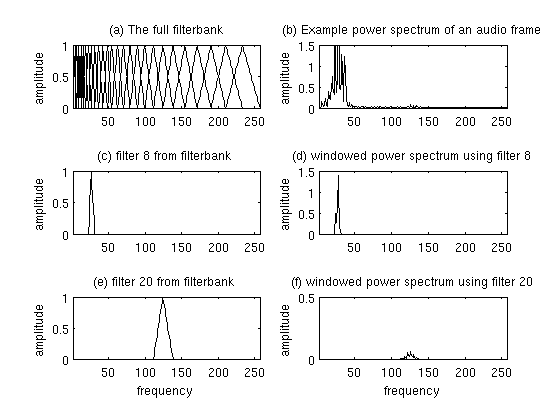 图1 Mel滤波器组和加窗后的功率谱
图1 Mel滤波器组和加窗后的功率谱
4.从步骤3中获取26个能量中的对应的对数,于是我们可以得到26个对数滤波器组能量。
5.对26个对数滤波器组能量进行离散余弦变换(DCT),得到26个倒谱系数。 对于ASR,仅保留26个系数中较低的12-13个。
得到的特征(每帧12个数值)称为梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients)。计算Mel滤波器组
在本节中,示例将使用10个滤波器组,因为它更容易显示,实际上你可以使用26-40滤波器组。
为了获得图1(a)所示的滤波器组,我们首先必须选择上下频率,比如下面为300Hz,上面为8000Hz。当然,如果语音以8KHz采样,则我们的上限频率限制为4KHz。然后按照下列步骤操作:
使用等式(1),将上下频率转换为Mels。在本例中,300Hz是401.25 Mels,8000Hz是2834.99 Mels。
对于这个例子,我们将做10个滤波器组,即需要12个频点。这意味着我们需要在401.25和2834.99之间线性 间隔10个额外频点,也就是:m(i) = 401.25, 622.50, 843.75, 1065.00, 1286.25, 1507.50, 1728.74,
1949.99, 2171.24, 2392.49, 2613.74, 2834.99
现在使用等式2将这些转换回赫兹:h(i) = 300, 517.33, 781.90, 1103.97, 1496.04, 1973.32, 2554.33,
3261.62, 4122.63, 5170.76, 6446.70, 8000
请注意,我们的起点和终点都是我们想要的频率。
在上面计算中,我们没有考虑所需的频率分辨率,以将滤波器放在的精确的点上,因此我们需要将这些频率舍入到最近的FFT区间。此过程不会影响功能的准确性。要将频率转换为FFT的 bin数,我们需要知道FFT大小和采样率,f(i) = floor((nfft+1)*h(i)/sample rate)
这会得到以下序列:f(i) = 9, 16, 25, 35, 47, 63, 81, 104, 132, 165, 206, 256
我们可以看到最后的滤波器组在bin 256处完成,其对应于具有8kHz,该FFT大小为512点。
现在我们创建我们的滤波器组。第一个滤波器组将从第一个点开始,在第二个点达到其峰值,然后在第三个点返回到零。第二个滤波器组将从第2个点开始,在第3个点达到最大值,然后在第4个点处为零,等等。计算这些的公式如下:
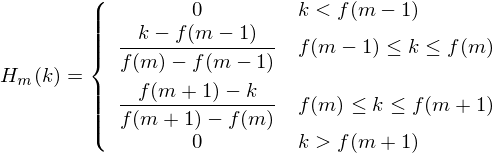
其中M是我们想要的滤波器的数量,
![]() 是M + 2 Mel间隔频率的列表。
是M + 2 Mel间隔频率的列表。
最后,可以得到重叠的10个过滤器的图是:

图210滤波器Mel滤波器组的图,该滤波器组从0Hz开始并以8000Hz结束。这只是一个示意。上面的实际例子的起始点从300Hz开始。
Deltas 和 Delta-Deltas
也称为差分和加速系数。 MFCC特征向量仅描述单帧的功率谱包络,但似乎语音也将具有动态信息,即MFCC系数随时间的轨迹。 事实证明,计算MFCC轨迹并将它们附加到原始特征向量会使ASR性能提高很多(如果我们有12个MFCC系数,则我们还会得到12个delta系数,它们将结合起来给出一个长度为24的特征向量)。为了计算delta系数,可以利用如下公式:
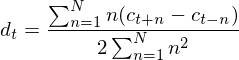
其中
![]() 是delta系数, 计算来自帧
是delta系数, 计算来自帧
![]() 中的静态系数
中的静态系数
![]() 到
到
![]() ,这里
,这里
![]() 典型值为2.
典型值为2.
Delta-Delta(加速度)系数以相同方式计算,但它们是根据deltas计算的,而不是静态系数。
Python及MATLAB实现
1) MFCCs_python, click here. Use the 'Download ZIP' button on the right hand side of the page to get the code. Documentation can be found at readthedocs.
2) MFCCs_MATLABclick here.参考文献
Davis, S. Mermelstein, P. (1980) Comparison of Parametric Representations for Monosyllabic Word Recognition in Continuously Spoken Sentences. In IEEE Transactions on Acoustics, Speech, and Signal Processing, Vol. 28 No. 4, pp. 357-366
X. Huang, A. Acero, and H. Hon. Spoken Language Processing: A guide to theory, algorithm, and system development. Prentice Hall, 2001.
转载本文请联系原作者获取授权,同时请注明本文来自洪峰科学网博客。
链接地址:http://blog.sciencenet.cn/blog-3396477-1162619.html
下一篇:语音深度学习分类解析(一)