tikhonov正则化 matlab_机器学习中的各种范数与正则化
机器学习中的各种范数与正则化
对于统计机器学习算法一般为缓解过拟合现象的发生需要在进行正则化操作,通过正则化以偏差的增加换取方差的减小,因此优秀的正则化操作即是在保证方差较小的情况下,偏差尽可能的小。有关偏差与方差的介绍可以参考我的这篇笔记
PoderLee:Bias - Variance Dilemma(偏差-方差窘境)zhuanlan.zhihu.com
最常见的方法即为在损失函数中引入矩阵范数,以对模型的复杂程度做出惩罚,即模型的权值参数(一般不考虑惩罚偏置,这主要是因为惩罚偏置首先不会有明显效果,其次惩罚偏置可能会造成模型欠拟合),其目标函数一般如下式所示:
上式中,第一项即为经验风险,第二项即为正则化项。其中
-
范数正则化
这里我们假设模型的偏置参数均为0,则参数
对上式求其梯度有:
使用梯度下降法更新权重
从中可以看出每次权值
进一步地,这里令
上式中
记
故:
(由于Hesian矩阵为半正定矩阵,故其为实对称阵。因此有
当
从上式中可以看出经过正则化后,权重

上图为特征向量的作用效果图,这里矩阵有两个标准正交特征向量,对应的特征值分别为
由于特征向量的缩放因子为
通过
此外,在线性回归的平方误差损失函数中引入二范数,即在原来逆矩阵的基础上加入对角阵,使得矩阵求逆可行,同时缓解过拟合的问题。而由于加入的对角矩阵,其就像一条“山岭”一样,因此,
线性回归目标函数一般为:
上式中第(1)项
另外从另一个角度理解,当
-
范数正则化
如上式所示,
其对应的梯度如下:
上式中,
同理,这里令
对每一维
对
当
a.
b.
同理,当
与
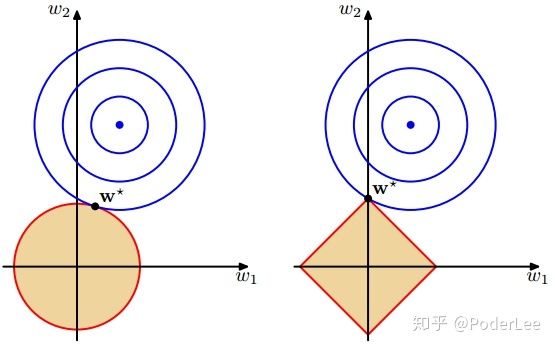
上图中,蓝色的圆圈表示原问题可能的解范围,橘色的表示正则项可能的解范围。而整个目标函数(原问题(损失函数)+正则项)有解当且仅当两个解范围相切。从上图可以很容易地看出,由于
(拉普拉斯分布:
由于目标函数是关于
-
范数
- Frobenius范数
Frobenius范数如下所示:
从上式可以明显看出,矩阵的Frobenius范数就是将矩阵张成向量后的
各类范数一般作为各类机器学习模型权值的约束项(惩罚项)出现在目标函数中,训练过程以使得结构风险最小化,防止过拟合的发生。
此外有关泛化的其它方法如下:
- 数据增强
数据增强也能增加模型的泛化性能,如对图像的彩色通道进行一定程度的抖动(FancyPCA),对图像进行水平翻转(镜像处理),但这里需要注意的是水平翻转不应改变数据类别(如对于文字,字符的识别一般不会进行horizontal flipping)。


- 随机噪声
随机噪声的注入也是一种正则化的方法,其等价于权值正则操作(Bishop,1995)。我们可以将噪声注入至模型的任意部分(当然一般选择将其添加至隐层而非输出),通过噪声的注入虽然无法保证能找到最优解,但我们可以将参数更新至一个相对平坦的区域,使其对于数据的随机扰动更加鲁棒。
- 标签平滑操作
在图像识别中,其标签一般为one-hot值,如[1,0,0,0,0],而模型的预测输出结果一般为经过softmax处理后的概率值如[0.9,0.03,0.01,0.005,0.055]。这样在训练过程中,我们需要让网络尽可能的去拟合one-hot编码,此时将会导致weights的调整越来越大。故一种简单的想法是对label进行smoothing,如下:
上式中,
Early Stopping
在网络的训练过程中,经常会遇到过训练的问题,即模型通过不断训练,其在训练集上的损失不断减小而验证集的误差将不断增加。

从上图可以看出,Validation set loss呈现出一种非对称的"U"形,因此我们期望在validation loss上升前终止迭代,即early stopping。然而在实际的操作中我们一般是通过划分出一部分数据集在每个epoch中计算validation loss,其并非generalization,即其并不能solid的反映数据的整体情况,因此一般情况下是在loss没有较大下降时停止。Early stopping在实际训练中十分常见。
- Dropout
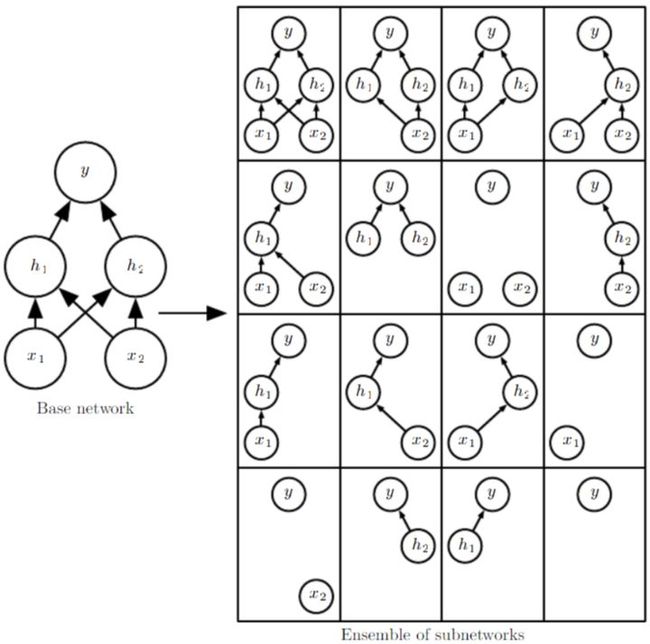
Dropout操作即在训练时随机将部分参数置零(一般为全连接层),在减少训成本的同时提高模型的泛化性能。Dropout本质上也可以理解为多个subnetworks的ensemble且不需要进行votes。此外对于较大规模的数据集,regularization operation对于generalization error 的减少效果并非十分明显,而Dropout则能有效减少计算代价,因此dropout更加实用。
- 对抗样本
对于图像的识别任务,虽然目前深度网在ImageNet上的精度已经超过了人类水平,但是我们只要在原始图片中掺杂一些随机的小扰动,对于人类其并不能察觉,而深度网络的输出将会变得十分的ridiculous,即fool network。因此我们可以利用对抗数据,进行对抗训练。

Reference
[1] Liang Wang. Regulaarization and Optimization. 中科院自动化研究所.