MONAI中,一定要学会的三种Dataset使用方法
在正式学习MONAI功能函数前,以下的网址必须要收藏。
1. MONAI API: https://docs.monai.io/en/latest/index.html
作用:查询功能函数的用法,主要分为以下几类

2. MONAI GitHub项目地址: https://github.com/Project-MONAI
作用:如果上述API 介绍的不够完整,可以去项目里面找一些例子,包括如何做分类,分割,生成模型,异常检测。
以及transform,dataset,metric等等怎么使用。超多丰富的例子,自己去挖掘,项目一直在更新。
-----------------------------------常用Dataset介绍--------------------------------------
MONIA提供了非常多的Dataset, 包括Dataset⭐️, IterableDataset, PersistentDataset, CacheDataset⭐️, SmartCacheDataset, ZipDataset, ArrayDataset⭐️, ImageDataset

今天介绍几个比较常用的。
1.monai.data.Dataset
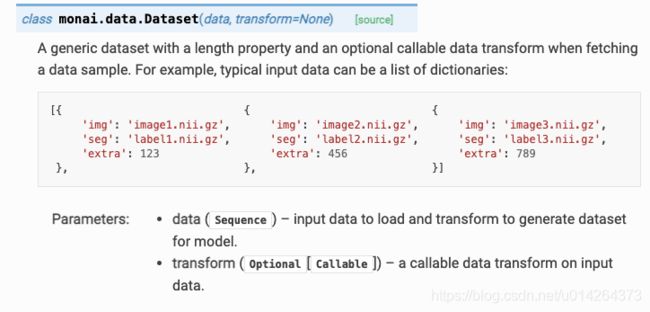
参数简介
data: 将image 和 label 的地址或值存为字典。label可以是分割的图像,也可以是分类的值(如0, 1, 2...)
transform: 根据分类或分割任务来定义
举例
import os
from glob import glob # 注意这是两个glob
import numpy as np
import monai
from monai.data import Dataset
imglist = sorted(glob('/Volumes/Backup Plus/data/COVID_DATA/MONAI-dataset/*.jpg'))[:11]
label = np.concatenate((np.zeros(5, dtype=np.int64), np.ones(6, dtype=np.int64)))
data_dict = [{'image': image, 'label': label} for image, label in zip(image_list, label)]

# 创建字典的意思就是将image和label搞成对,哪幅图像对应哪个标签。这里的image是图像存放的地址,而图像的格式可以使jpg, png, nii.gz, 二维三维都可以,关于label, 如果是分类,那它应该是数值,如果是分割,那它就是图像的mask地址
# 记住这个字典对,之后取数据来训练的时候,就是根据字典的键来取得,也就是这里的'image'和‘label’。你也可以改成其他的,如'img'和‘seg’。不管改成什么,记住就ok
如果是分割,那么image, label都是地址。下图我是直接把image当做label进行演示。
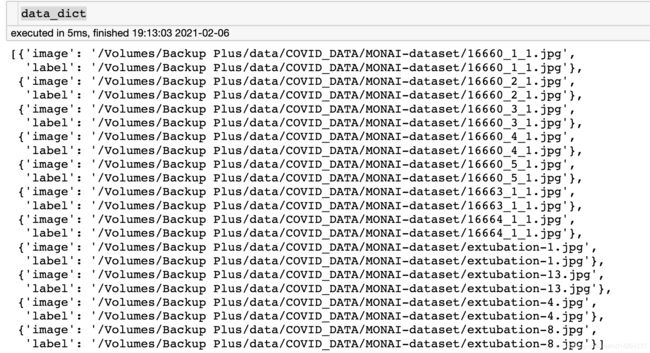
这就把image和label搞好了,接下来就是把配对好的数据组装成dataset和dataloder
注意注意
对于Dataset 这个函数,需要特别注意,因为它只接收图像标签对形式的字典,所有在做transform的时候,要选择字典transform, 也就是所有的变换后面都要加一个’d‘, 如要加在图像,用LoadImage,字典的话就要用LoadImaged.
具体查看API的Dictionary Transforms, 如下图。

from monai.transforms import Compose, LoadImaged, AddChanneld, ToTensord, Resized
transform = Compose(
[
LoadImaged(keys='image'), # 做分类,这里image需要加载
AddChanneld(keys='image'), # 给加载进来的图像加个通道,只针对图像。
Resized(keys='image', spatial_size=(96,96)),
ToTensord(keys='image'), # 把图像转成tensor格式
]
)
train_ds = Dataset(data=data_dict[:7], transform=transform)
val_ds = Dataset(data=data_dict[-4:], transform=transform)
train_loader = monai.data.DataLoader(
train_ds, batch_size=4, shuffle=True, num_workers=10)
test_loader = monai.data.DataLoader(
val_ds, batch_size=2, shuffle=True, num_workers=10)2. monai.data.CacheDataset

具有缓存机制的dataset,就是在第一个epoch之前,把所有训练的数据都加载进缓存,这样可以加快网络提取数据的速度。它有两个注意点。第一个是,它缓存的是确定性变换(或者说是非随机变换)后的数据,而不是原始数据。比如你在transform中,使用了上图所示的变换,其中,LoadImaged, Addchanneld, Spacingd, Orientationd,SacleIntensityRanged都是确定性变化,于是缓存的是经过这些变换之后的数据。而剩余的变换包括(RandCropByPosNegLabels, ToTensord)是每次迭代的时候进行的。
总 结
CacheDataset缓存确定性变换后的结果,其余的随机变换在每次迭代的时候进行。
根据这个规则,我们应该把尽可能多的确定性变换放在随机变换之前。而一般来讲,ToTensord()是确定性的,但通常应该是最后一个变换。
在使用带缓存机制的dataset的时候,会在训练前处理数据,因此加载数据的过程会很慢,但是训练的时候会比普通的快。我一般也是用CacheDataset比较多。官方测试的一个对比如下:

参数介绍
data和transform同前面的Dataset.
cache_num: 要缓存的项目数(int)。默认值为sys.maxsize
cache_rate: 缓存数据占总数的百分比。默认为1(即全部缓存)
num_workers: 要使用的工作进程数目
3.monai.data.ArrayDataset
前面两种Dataset都是基于字典的,如果你不喜欢用字典模式,就可以考虑使用这个数组模式。
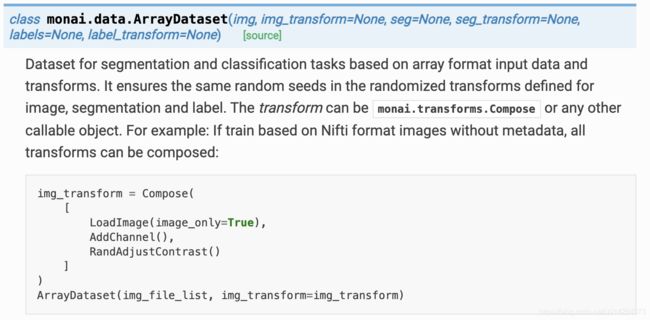
不管是分类还是分割,都可以使用该数组模式。在该模式下,可以确保为图像,分割,分割标签和分类标签用相同的随机数种子。
注意注意
使用ArrayDataset加载数据时,必须设定image_only=True,只加载图像值而不加载元数据,否则会报错。
参数介绍
img: 图像地址
img_transform: 用于图像的transform
seg: 如果是分割,为图像地址,如果是分类,不填即可
seg_transform: 如果是分割,填写对mask的变换
label: 如果是分类, 为数组
label_transform: 如果是分类,对label做的变换,一般不做变换
举例:
import monai
import os
from glob import glob
from monai.data import ArrayDataset
from monai.transforms import Compose, LoadImage, AddChannel, ToTensor, Resize
imglist = sorted(glob('/Volumes/Backup Plus/data/COVID_DATA/MONAI-dataset/*.jpg'))[:11]
label = np.concatenate((np.zeros(5, dtype=np.int64), np.ones(6, dtype=np.int64)))
transform = Compose(
[
LoadImage(image_only=True), # 使用数组加载数据时,必须设定image_only=True,只加载图像值而不加载元数据
AddChannel(),
Resize(spatial_size=(96,96,96)),
ToTensor()
]
)由于加载的是数组,这里所有的transform都不加‘d’。
train_ds = ArrayDataset(img=imglist, img_transform=transform, labels=label)
train_loader = monai.data.DataLoader(
train_ds, batch_size=4, shuffle=True, num_workers=4)
for image, label in train_loader:
print(image.shape)
print(label.shape)
break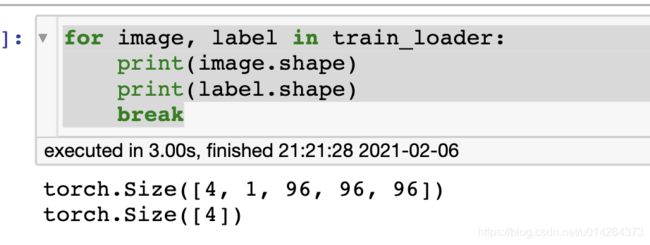
主要分享这三种常用的Dataset, 满足大部分应用场景。本次分享的代码,可以尝试使用任意的二维数据格式或三维数据练一练。需要注意的是,图像格式如果是jpeg,LoadImage()是不支持加载的,图像如果是RGB格式(长*宽*3通道), 也是不能按这种方式加载的,如果手里只有RGB格式的数据,可以在transform中,像我一样,添加一个Resize(),把它变成一个三维数据,练练。但是实际应用中,这样是不科学的。
MONAI本来是为医学图形开发的,而医学图像,尤其是三维医学图像(CT 和MRI)通常都是以nii.gz格式保存的,所以使用nii.gz格式的图像执行上述操作是更好的。
下一次分享transform中常用的一些数据处理方法。