通过随机平滑验证对抗鲁棒性
1 引言
当前很多研究工作提出了用于训练分类器的启发式算法,其目的是使分类器对对抗扰动具有一定鲁棒性。然而,这些启发式算法中的大多数算法缺乏相应的理论基础做支撑。随之而来出现了关于分类器可证鲁棒性的一系列理论研究工作,即在任何输入样本点的预测在围绕在该样本点的某个集合内是一个可验证的常数。在该文中,作者首次提供了随机平滑的严格鲁棒性保证证明,论文分析表明,使用高斯噪声进行平滑会在 ℓ 2 \ell_2 ℓ2范数下产生可证明的鲁棒性,而且论文中验证神经网络鲁棒性的方法可以扩展到像ImageNet等足够大的神经网络中。该论文发表于ICML2019是可证鲁棒性研究领域中非常重要的一篇文章,本文对该论文的核心理论进行了详细地解读。
论文链接: https://proceedings.mlr.press/v97/cohen19c.html
代码链接: https://github.com/locuslab/smoothing
2 随机平滑
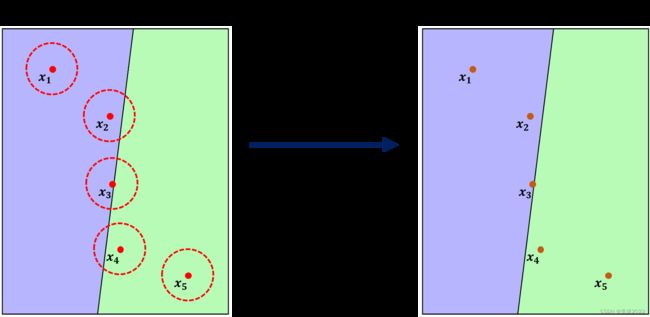
考虑一个从 R d \mathbb{R}^d Rd到 Y \mathcal{Y} Y的分类问题,随机平滑是从一个基础分类器 f f f重新构造出一个分类器 g g g。当输入为 x x x时,平滑分类器 g g g会输出基础分类器 f f f最有可能输出的类别概率,当 x x x由高斯噪声扰动时,即 g ( x ) = arg max c ∈ Y P ( f ( x + ε ) = c ) \begin{aligned}g(x)=\arg\max\limits_{c \in \mathcal{Y}}\mathbb{P}(f(x+\varepsilon)=c)\end{aligned} g(x)=argc∈YmaxP(f(x+ε)=c)其中 ε ∼ N ( 0 , σ 2 I ) \varepsilon \sim \mathcal{N}(0,\sigma^2I) ε∼N(0,σ2I)。以上公式的含义表示的是 g ( x ) g(x) g(x)可以输出类 c c c,其输入图片 { x ′ ∈ R d : f ( x ′ ) = c } \{x^{\prime}\in\mathbb{R}^d:f(x^{\prime})=c\} {x′∈Rd:f(x′)=c}在分布 N ( x , σ 2 I ) \mathcal{N}(x,\sigma^2I) N(x,σ2I)上关于类 c c c有很大的概率测度。噪声 σ \sigma σ是一个平滑分类器 g g g的超参数,其主要平衡模型的鲁棒性和准确率。因为不可能准确估计出分类器 g g g在输入 x x x的预测,以及不能验证模型 f f f在输入 x x x周围的鲁棒性。作者给出平滑分类器 g g g的鲁棒性保证,对于这两个任务作者用蒙特卡洛算法可以高概率估计成功。根据随机平滑的定义,以下列出两种情况下的基分类器 f f f随机平滑为平滑分类器 g g g的例子,可以发现随机平滑的作用可以将曲率较大的决策边界进行一定程度的平滑。

3 鲁棒性保证
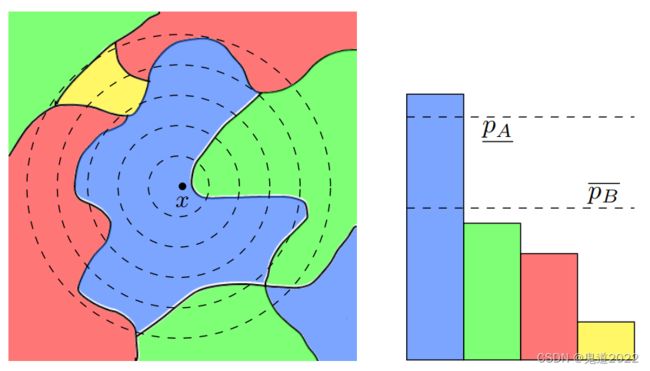
假定基础分类器分类输入 N ( x , σ 2 I ) \mathcal{N}(x,\sigma^2 I) N(x,σ2I)并以概率 p A p_A pA输出类 c c c,以概率 p B p_B pB输出次一级别的类。平滑分类器 g g g在 x x x以 ℓ 2 \ell_2 ℓ2半径 R = σ 2 ( Φ − 1 ( p A ) − Φ − 1 ( p B ) ) R=\frac{\sigma}{2}(\Phi^{-1}(p_A)-\Phi^{-1}(p_B)) R=2σ(Φ−1(pA)−Φ−1(pB))是鲁棒的,其中 Φ − 1 \Phi^{-1} Φ−1是标准正态分布的反函数。如果用下界下界 p A ‾ \underline{p_A} pA替换 p A p_A pA和概率上界 p B ‾ \overline{p_B} pB替换 p B p_B pB,则以上结论依然成立。
定理1(多分类情况): 令 f : R d → Y f:\mathbb{R}^d\rightarrow \mathcal{Y} f:Rd→Y是任何确定或随机函数,且有 ε ∼ N ( 0 , σ 2 I ) \varepsilon\sim \mathcal{N}(0,\sigma^2I) ε∼N(0,σ2I)。平滑分类器 g g g的定义如下所示 g ( x ) = arg max c ∈ Y P ( f ( x + ε ) = c ) \begin{aligned}g(x)=\arg\max\limits_{c \in \mathcal{Y}}\mathbb{P}(f(x+\varepsilon)=c)\end{aligned} g(x)=argc∈YmaxP(f(x+ε)=c)假定 c A ∈ Y c_A\in \mathcal{Y} cA∈Y且有 p A ‾ , p B ‾ ∈ [ 0 , 1 ] \underline{p_A},\overline{p_B}\in[0,1] pA,pB∈[0,1] 满足 P ( f ( x + ε ) = c A ) ≥ p A ‾ ≥ p B ‾ ≥ max c ≠ c A P ( f ( x + ε ) = c ) \mathbb{P}(f(x+\varepsilon)=c_A)\ge \underline{p_A}\ge \overline{p_B}\ge \max\limits_{c \ne c_A}\mathbb{P}(f(x+\varepsilon)=c) P(f(x+ε)=cA)≥pA≥pB≥c=cAmaxP(f(x+ε)=c) 进而对于任意 ∥ δ ∥ 2 < R \|\delta\|_2
∥δ∥2<R ,则有 g ( x + δ ) = c A g(x+\delta)=c_A g(x+δ)=cA,其中 R = σ 2 ( Φ − 1 ( p A ‾ ) − Φ − 1 ( p B ‾ ) ) R=\frac{\sigma}{2}(\Phi^{-1}(\underline{p_A})-\Phi^{-1}(\overline{p_B})) R=2σ(Φ−1(pA)−Φ−1(pB))。
从定理1可以得到如下三个发现:
- 定理1对分类器 f f f没有任何假设。这是至关重要的,因为目前尚不清楚现代深度学习架构满足哪些良好行为假设。
- 当噪声水平 σ \sigma σ较高,或最大类 c A c_A cA的概率值较大,或其它类别概率值较低时,鲁棒性半径 R R R是大的。
- 当鲁棒性半径 R R R趋于 ∞ \infty ∞时,则 p A ‾ → 1 \underline{p_A}\rightarrow 1 pA→1并且 p B ‾ → 0 \overline{p_B}\rightarrow 0 pB→0。高斯分布是在所有的 R d \mathbb{R}^d Rd空间中,所以有概率为 1 1 1使得 f ( x + ε ) = c A f(x+\varepsilon)=c_A f(x+ε)=cA。
定理2(二分类情况): 假定 p A ‾ ∈ ( 1 2 , 1 ] \underline{p_A}\in(\frac{1}{2},1] pA∈(21,1]满足 P ( f ( x + ε ) = c A ) ≥ p A ‾ \mathbb{P}(f(x+\varepsilon)=c_A)\ge \underline{p_A} P(f(x+ε)=cA)≥pA那么对于任意 ∥ δ ∥ 2 < σ Φ − 1 ( p A ‾ ) \|\delta\|_2 < \sigma \Phi^{-1}(\underline{p_A}) ∥δ∥2<σΦ−1(pA),则有 g ( x + δ ) = c A g(x+\delta)=c_A g(x+δ)=cA。
最差分类器 f ∗ f^{*} f∗有 Φ ( Φ − 1 ( p A ‾ ) − ∥ δ ∥ 2 σ ) \Phi(\Phi^{-1}(\underline{p_A})-\frac{\|\delta\|_2}{\sigma}) Φ(Φ−1(pA)−σ∥δ∥2)的概率将 N ( x + δ , σ 2 I ) \mathcal{N}(x+\delta,\sigma^2I) N(x+δ,σ2I)分类为 c A c_A cA。因此为了能够让最差分类器 f ∗ f^{*} f∗有大于 1 2 \frac{1}{2} 21的概率将 N ( x + δ , σ 2 I ) \mathcal{N}(x+\delta,\sigma^2I) N(x+δ,σ2I)分类为 c A c_A cA,则有公式 Φ ( Φ − 1 ( p A ‾ ) − ∥ δ ∥ 2 σ ) > 1 2 \Phi(\Phi^{-1}(\underline{p_A})-\frac{\|\delta\|_2}{\sigma})>\frac{1}{2} Φ(Φ−1(pA)−σ∥δ∥2)>21 此时可求解得到 ∥ δ ∥ 2 < σ Φ − 1 ( p A ‾ ) \|\delta\|_2 < \sigma \Phi^{-1}(\underline{p_A}) ∥δ∥2<σΦ−1(pA)。
定理3: 假设 p A ‾ + p B ‾ ≤ 1 \underline{p_A}+\overline{p_B}\le 1 pA+pB≤1,对于任意扰动 δ \delta δ且有 ∥ δ ∥ 2 > R \|\delta\|_2>R ∥δ∥2>R,则存在一个与类概率 P ( f ( x + ε ) = c A ) ≥ p A ‾ ≥ p B ‾ ≥ max c ≠ c A P ( f ( x + ε ) = c ) \mathbb{P}(f(x+\varepsilon)=c_A)\ge \underline{p_A}\ge \overline{p_B}\ge\max\limits_{c \ne c_A}\mathbb{P}(f(x+\varepsilon)=c) P(f(x+ε)=cA)≥pA≥pB≥c=cAmaxP(f(x+ε)=c) 一致的基分类器 f f f,其中 g ( x + δ ) ≠ c A g(x+\delta)\ne c_A g(x+δ)=cA。
定理3表明,高斯平滑自然会诱导出 ℓ 2 \ell_2 ℓ2鲁棒性:如果对基分类器不做超出类概率的假设,那么高斯平滑分类器可证明鲁棒的扰动集恰好是 ℓ 2 \ell_2 ℓ2球上。定理2是一个简单的结论,对于任意 δ \delta δ,当 f ∗ f^{*} f∗ 是最差基分类器时,则有 g ( x + δ ) = c B g(x+\delta)=c_B g(x+δ)=cB。
线性基分类器: 一个二类线性分类器 f ( x ) = s i g n ( w ⊤ x + b ) f(x)=\mathrm{sign}(w^{\top}x+b) f(x)=sign(w⊤x+b)是可验证的:即从任意输入样本 x x x 到决策边界的距离为 ∣ w ⊤ x + b ∣ / ∥ w ∥ |w^{\top}x+b|/\|w\| ∣w⊤x+b∣/∥w∥并且 ℓ 2 \ell_2 ℓ2范数的扰动 δ \delta δ要小于能改变分类器 f f f预测的距离。因此当 f f f是线性时,总存在一个扰动 δ \delta δ超过可证半径时,分类器 g g g的半径会改变。
噪声水平可以随图像分辨率缩放: 由于验证半径表达式不明确依赖于数据维度 d d d,因此可能会担心随机平滑对于更分辨率高的图像效果较差—— 对于 224 × 224 224\times224 224×224的图像来说,固定可证 ℓ 2 \ell_2 ℓ2半径要比 56 × 56 56\times56 56×56的图像处理效果要差一些。然而,如下图所示,更高分辨率的图像可以在其类别区分内容被破坏之前容忍更高水平的各向同性高斯噪声。因此,在高分辨率下,可以使用更大的 σ \sigma σ执行平滑,从而获得更大的可证半径。
4 算法介绍
评估平滑分类器的预测 g ( x ) g(x) g(x)需要在类分布 f ( x + ε ) f(x + \varepsilon) f(x+ε)中识别具有最大概率的类 c A c_A cA。伪代码中 P R E D I C T \mathrm{PREDICT} PREDICT通过基分类器运行 x x x的 n n n个噪声来采样 n n n个 f ( x + ε ) f(x + \varepsilon) f(x+ε)样本。令 c ^ A \hat{c}_A c^A 为出现次数最多的类别。如果 c ^ A \hat{c}_A c^A出现的频率比任何其他类都多,则 P R E D I C T \mathrm{PREDICT} PREDICT返回 c ^ A \hat{c}_A c^A。作者使用Hung&Fithian的假设检验来校准弃权阈值,以便将返回错误类别的概率限制为 α \alpha α,具体的算法流程图如以下的伪代码所示。


命题1: 在 P R E D I C T \mathrm{PREDICT} PREDICT中的随机性至少有 1 − α 1-\alpha 1−α的概率时, P R E D I C T \mathrm{PREDICT} PREDICT将返回 g ( x ) g(x) g(x),即 P R E D I C T \mathrm{PREDICT} PREDICT返回 g ( x ) g(x) g(x)以外的类别的概率最多为 α \alpha α。
伪代码中的函数 S A M P L E U N D E R N O I S E ( f , x , n u m , σ ) \mathrm{SAMPLEUNDERNOISE}(f, x,\mathrm{num}, \sigma) SAMPLEUNDERNOISE(f,x,num,σ)采样 n u m \mathrm{num} num个噪声样本 ε 1 ⋯ ε n u m ∼ N ( 0 , σ 2 I ) \varepsilon_1\cdots \varepsilon_{\mathrm{num}} \sim N(0, \sigma^2I) ε1⋯εnum∼N(0,σ2I),将每个 x + ε i x + \varepsilon_i x+εi样本通过基分类器 f f f,并输出一个类计数向量。 B I N O M P V A L U E ( n A , n A + n B , p ) \mathrm{BINOMPVALUE}(n_A, n_A + n_B, p) BINOMPVALUE(nA,nA+nB,p)输出假设检验的 p p p值测试 n A ∼ B i n o m i a l ( n A + n B , p ) n_A \sim \mathrm{Binomial}(n_A + n_B,p) nA∼Binomial(nA+nB,p)。定理1的一个变体可以证明一个半径,即 P ( f ( x + δ + ε ) = c A ) \mathbb{P}(f(x +\delta + \varepsilon) = c_A) P(f(x+δ+ε)=cA)比 max c ≠ c A P ( f ( x + δ + ε ) = c ) \max\limits_{c\ne c_A}\mathbb{P}(f(x +\delta + \varepsilon) = c) c=cAmaxP(f(x+δ+ε)=c) 大一些。 B I N O M P V A L U E ( n A , n A + n B , p ) \mathrm{BINOMPVALUE}(n_A, n_A + n_B, p) BINOMPVALUE(nA,nA+nB,p)特指对伯努利实验中成功概率为 p p p的零假设的精确双侧检验,函数返回的是假设检验的 p - v a l u e p\text{-}\mathrm{value} p-value值。由于返回的 p - v a l u e p\text{-}\mathrm{value} p-value 大于 5 % 5\% 5%的临界值,因此不能在 5 % 5\% 5%的显著性水平上拒绝原假设;反之拒绝原假设。令 n A n_A nA表示模型输出最大类出现的计数, n B n_B nB表示模型输出次大类的计数,探讨 n A n_A nA与 n A + n B n_A+n_B nA+nB的出现比率是否为 p = 1 2 p=\frac{1}{2} p=21?
假定原假设 H 0 H_0 H0: p = 1 2 p =\frac{1}{2} p=21,则备择假设 H 1 H_1 H1: p ≠ 1 2 p\ne \frac{1}{2} p=21进而可知 p - v a l u e p\text{-}\mathrm{value} p-value的计算公式为 P { X ≤ n A ∣ H 0 } = ∑ i = 0 n A C n A + n B i p i ( 1 − p i ) n A + n B − i \begin{aligned}P\{X\le n_A|H_0\}=\sum\limits_{i=0}^{n_A}C_{n_A+n_B}^{i}p^i(1-p^i)^{n_A+n_B-i}\end{aligned} P{X≤nA∣H0}=i=0∑nACnA+nBipi(1−pi)nA+nB−i 当 p - v a l u e p\text{-}\mathrm{value} p-value大于 5 % 5\% 5% 的临界值,则不能在 5 % 5\% 5%的显著性水平上拒绝原假设;反之拒绝原假设。
评估和证明平滑分类器 g g g在输入 x x x周围的鲁棒性不仅需要识别 f ( x + ε ) f(x + \varepsilon) f(x+ε)中概率最大的类 c A c_A cA,而且还需要估计 f ( x + ε ) = c A f(x + \varepsilon) = c_A f(x+ε)=cA的概率的下界 p A p_A pA和 f ( x + ε ) f(x + \varepsilon) f(x+ε)等于任何其他类的概率的上限 p B p_B pB。一个简单的解决方案以伪代码形式呈现为 C E R T I F Y \mathrm{CERTIFY} CERTIFY:首先,使用来自 f ( x + ε ) f(x + \varepsilon) f(x+ε)的少量样本来猜测 c A c_A cA;然后使用更多的样本来估计 p A p_A pA;然后简单地取 p B = 1 − p A p_B = 1 - p_A pB=1−pA。
命题2: 在 C E R T I F Y \mathrm{CERTIFY} CERTIFY的随机性上至少有 1 − α 1 - \alpha 1−α的概率,如果 C E R T I F Y \mathrm{CERTIFY} CERTIFY返回一个类 c ^ A \hat{c}_A c^A和一个半径 R R R,那么平滑分类器 g g g在以 x x x为中心半径 R R R区域内预测为 c ^ A \hat{c}_A c^A: g ( x + δ ) = c ^ A ∀ ∥ δ ∥ 2 < R g(x + δ) = \hat{c}_A \quad \forall \|\delta\|_2
g(x+δ)=c^A∀∥δ∥2<R
伪代码中的函数 L O W E R C O N F B O U N D ( k , n , 1 − α ) \mathrm{LOWERCONFBOUND}(k,n,1-\alpha) LOWERCONFBOUND(k,n,1−α)在给定样本 k ∼ B i n o m i a l ( n , p ) k \sim \mathrm{Binomial}(n, p) k∼Binomial(n,p)的情况下返回二项式参数 p p p的单边 ( 1 − α ) (1-\alpha) (1−α) 下置信区间。由定理1可知,当 p A p_A pA接近 1 1 1时,则 R R R接近 ∞ \infty ∞。事实证明 p A p_A pA在 n n n时地接近 1 1 1收敛很慢,以至于 R R R在 n n n时也非常缓慢地接近 ∞ \infty ∞。考虑最有利的情况: f ( x ) = c A f(x) = c_A f(x)=cA,这意味着 g g g在半径 ∞ \infty ∞处是鲁棒的。但是在观察到 f ( x + ε ) f(x+\varepsilon) f(x+ε)的 n n n个样本后,所有样本都等于 c A c_A cA。将 p A = α ( 1 / n ) p_A = \alpha(1/n) pA=α(1/n) 和 p B = 1 − p A p_B = 1 - p_A pB=1−pA 代入可证半径公式里可得出关于 n n n的函数表达式: R = σ Φ − 1 ( α 1 / n ) R=\sigma \Phi^{-1}(\alpha^{1/n}) R=σΦ−1(α1/n)。无论基分类器 f f f如何训练,定理1都成立。然而,为了让 g g g正确且具有一定的鲁棒性地对样本 ( x , c ) (x,c) (x,c)进行分类, f f f需要始终将 N ( x , σ 2 I ) \mathcal{N}(x, \sigma^2I) N(x,σ2I)分类为 c c c。在高维中,高斯分布 N ( x , σ 2 I ) \mathcal{N}(x, \sigma^2I) N(x,σ2I)在 x x x附近分布非常稀疏。因此,当 σ \sigma σ适度高时,自然图像的分布与被 N ( 0 , σ 2 I ) \mathcal{N}(0, σ^2I) N(0,σ2I)扰动的自然图像的分布几乎不相交。因此,如果基分类器 f f f是通过对数据分布的标准监督学习来训练的,那么它在训练期间将看不到噪声图像,因此不一定会学习用 x x x的真实标签对 N ( x , σ 2 I ) \mathcal{N}(x, \sigma^2I) N(x,σ2I)进行分类。因此,在本文中,作者用方差 σ 2 \sigma^2 σ2训练具有高斯数据增强的基分类器。
5 实验结果
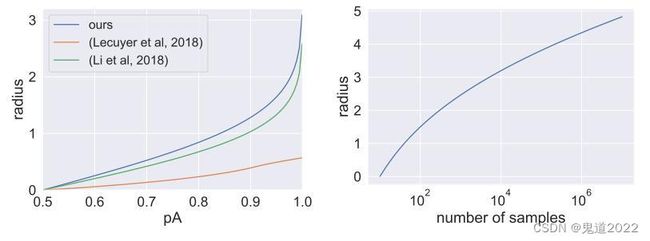
下左图表示三个不同的方法在给定概率下界 p A ‾ \underline{p_A} pA,进而得到的鲁棒半径的比较实验,其中令 p B ‾ = 1 − p A ‾ \overline{p_B}=1-\underline{p_A} pB=1−pA 和 σ = 1 \sigma=1 σ=1。可以直观的发现,论文中的方法得到的鲁棒半径要更大一些。右图表示为鲁棒半径与样本采样数的一个关系,即 R = σ Φ − 1 ( α 1 / n ) R=\sigma \Phi^{-1}(\alpha^{1/n}) R=σΦ−1(α1/n),可以发现当 α = 0.001 \alpha=0.001 α=0.001和 σ = 1 \sigma=1 σ=1 时,鲁棒半径随着采样书的增加而增长的比较缓慢。
如下左图所示,绘制了使用论文中定理 1保证获得的验证准确率以及使用Lecuyer 等人和李等人的类似界限获得的验证准确率。由于作者提出的方法鲁棒半径 R R R的表达式更大(实际上更紧密),所以论文的界限提供了更高的认证精度。如下中图所示预测了如果 CERTIFY 使用更多或更少的样本 n n n(假设计数中的相对类别比例保持不变),验证准确率将如何变化。如下右图所示绘制了随着置信度参数 α \alpha α变化的验证准确率,可以观察到验证准确率对 α \alpha α不是很敏感。
6 论文程序
论文中提供的github代码是在CIFAR10数据集上进行的实验,以下代码是针对ImageNet数据集的程序代码。
import os
from core import Smooth
import torch
from torch.utils.data import Dataset
import torchvision.transforms as T
import csv
import torchvision
import pretrainedmodels
import PIL.Image as Image
class SelectedImagenet(Dataset):
def __init__(self, imagenet_val_dir, selected_images_csv, transform=None):
super(SelectedImagenet, self).__init__()
self.imagenet_val_dir = imagenet_val_dir
self.selected_images_csv = selected_images_csv
self.transform = transform
self._load_csv()
def _load_csv(self):
reader = csv.reader(open(self.selected_images_csv, 'r'))
next(reader)
self.selected_list = list(reader)[0:1000]
def __getitem__(self, item):
target, target_name, image_name = self.selected_list[item]
image = Image.open(os.path.join(self.imagenet_val_dir, image_name))
if image.mode != 'RGB':
image = image.convert('RGB')
if self.transform is not None:
image = self.transform(image)
return image, int(target)
def __len__(self):
return len(self.selected_list)
if __name__ == '__main__':
model_name = 'inception'
batch_size = 1
trans = T.Compose([
T.Resize((256,256)),
T.CenterCrop((224,224)),
T.ToTensor()
])
dataset = SelectedImagenet(imagenet_val_dir='data/imagenet/ILSVRC2012_img_val',
selected_images_csv='data/imagenet/selected_imagenet.csv',
transform=trans
)
ori_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=False, num_workers = 8, pin_memory = False)
if model_name == 'inception':
model = torchvision.models.inception_v3(pretrained=True)
elif model_name == 'senet':
model = pretrainedmodels.__dict__['senet154'](num_classes=1000, pretrained='imagenet')
elif model_name == 'resnet':
model = torchvision.models.resnet50(pretrained=True)
elif model_name == 'densenet':
model = torchvision.models.densenet121(pretrained=True)
else:
print('No implemation')
model.eval()
smoothed_classifier = Smooth(model, 1000, 0.2)
for ind, (ori_img, label)in enumerate(ori_loader):
prediction, radius = smoothed_classifier.certify(ori_img, 5, 10, 0.1, 1)
print(prediction)
7 补充证明
7.1 无穷鲁棒半径
引理1: 令 Z ∼ N ( 0 , 1 ) Z\sim \mathcal{N}(0,1) Z∼N(0,1),对于任意 ℓ ∈ R , t > 0 \ell \in \mathbb{R},t >0 ℓ∈R,t>0,则有 P ( ℓ ≤ ℓ + 2 t ) ≤ P ( − t ≤ Z ≤ t ) \mathbb{P}(\ell \le \ell+ 2t)\le \mathbb{P}(-t\le Z \le t) P(ℓ≤ℓ+2t)≤P(−t≤Z≤t)。
证明: 令 ϕ \phi ϕ为标准正态分布的累积分布函数。因为 ϕ \phi ϕ是对称的即 ∀ x , ϕ ( x ) = ϕ ( − x ) \forall x, \phi(x)=\phi(-x) ∀x,ϕ(x)=ϕ(−x),进而则有 P ( − t ≤ Z ≤ t ) = 2 ∫ 0 t ϕ ( x ) d x \mathbb{P}(-t\le Z \le t)=2 \int^t_0 \phi(x)dx P(−t≤Z≤t)=2∫0tϕ(x)dx考虑以下两种情况:
- 情况1:区间 [ ℓ , ℓ + 2 t ] [\ell,\ell+2t] [ℓ,ℓ+2t]为全正或全负,即 ℓ ≥ 0 \ell \ge 0 ℓ≥0或 ℓ + 2 t ≤ 0 \ell+2t \le 0 ℓ+2t≤0。 因为 ϕ \phi ϕ在 R \mathbb{R} R中是对称的,则可以将 P ( ℓ ≤ Z ≤ ℓ + 2 t ) \mathbb{P}(\ell \le Z \le \ell+2t) P(ℓ≤Z≤ℓ+2t)重新写成随机变量 Z Z Z落在非负区间 [ a , a + 2 t ] [a,a+2t] [a,a+2t]的概率 P ( ℓ ≤ Z ≤ ℓ + 2 t ) = P ( a ≤ Z ≤ a + 2 t ) \mathbb{P}(\ell \le Z \le \ell+2t)=\mathbb{P}(a \le Z \le a+2t) P(ℓ≤Z≤ℓ+2t)=P(a≤Z≤a+2t)因此 P ( − t ≤ Z ≤ t ) − P ( ℓ ≤ Z ≤ ℓ + 2 t ) = ∫ 0 t ϕ ( x ) d x − ∫ a a + t ϕ ( x ) d x + ∫ 0 t ϕ ( x ) d x − ∫ a + t a + 2 t ϕ ( x ) d x = ∫ a a + t ϕ ( x − a ) d x − ∫ a a + t ϕ ( x ) d x + ∫ a + t a + 2 t ϕ ( x − a − t ) d x − ∫ a + t a + 2 t ϕ ( x ) d x = ∫ a a + t [ ϕ ( x − a ) − ϕ ( x ) ] d x + ∫ a + t a + 2 t [ ϕ ( x − a − t ) − ϕ ( x ) ] d x ≥ ∫ a a + t 0 d x + ∫ a + t a + 2 t 0 d x = 0 \begin{aligned}&\mathbb{P}(-t\le Z \le t)-\mathbb{P}(\ell \le Z \le \ell + 2t)\\=&\int_0^t \phi(x)dx -\int^{a+t}_a \phi(x)dx+\int_0^t \phi(x)dx-\int_{a+t}^{a+2t}\phi(x)dx\\=&\int_a^{a+t} \phi(x-a)dx -\int^{a+t}_a \phi(x)dx+\int_{a+t}^{a+2t} \phi(x-a-t)dx-\int_{a+t}^{a+2t}\phi(x)dx\\=&\int_a^{a+t} [\phi(x-a) - \phi(x)]dx+\int_{a+t}^{a+2t} [\phi(x-a-t)-\phi(x)]dx\\\ge& \int_a^{a+t}0dx +\int_{a+t}^{a+2t}0dx\\=&0\end{aligned} ===≥=P(−t≤Z≤t)−P(ℓ≤Z≤ℓ+2t)∫0tϕ(x)dx−∫aa+tϕ(x)dx+∫0tϕ(x)dx−∫a+ta+2tϕ(x)dx∫aa+tϕ(x−a)dx−∫aa+tϕ(x)dx+∫a+ta+2tϕ(x−a−t)dx−∫a+ta+2tϕ(x)dx∫aa+t[ϕ(x−a)−ϕ(x)]dx+∫a+ta+2t[ϕ(x−a−t)−ϕ(x)]dx∫aa+t0dx+∫a+ta+2t0dx0其中不等式成立的原因在于 ϕ \phi ϕ在区间 [ 0 , + ∞ ) [0,+\infty) [0,+∞)上单调递减的。
- 情况2:区间 [ ℓ , ℓ + 2 t ] [\ell,\ell+2t] [ℓ,ℓ+2t]部分为正部分为负,即 ℓ ≤ 0 ≤ ℓ + 2 t \ell \le 0 \le \ell+2t ℓ≤0≤ℓ+2t。 因为 ϕ \phi ϕ在 R \mathbb{R} R中是对称的,则可以将 P ( ℓ ≤ Z ≤ ℓ + 2 t ) \mathbb{P}(\ell \le Z \le \ell+2t) P(ℓ≤Z≤ℓ+2t)重新写成随机变量 Z Z Z落在非负区间 [ 0 , a ] [0,a] [0,a]和 [ 0 , b ] [0,b] [0,b]的概率 P ( ℓ ≤ Z ≤ ℓ + 2 t ) = P ( 0 ≤ Z ≤ a ) + P ( 0 ≤ Z ≤ b ) \mathbb{P}(\ell \le Z \le \ell+2t)=\mathbb{P}(0 \le Z \le a)+\mathbb{P}(0\le Z \le b) P(ℓ≤Z≤ℓ+2t)=P(0≤Z≤a)+P(0≤Z≤b)构造 a + b = t a+b=t a+b=t,且 0 ≤ a ≤ t 0 \le a \le t 0≤a≤t和 t ≤ b ≤ 2 t t\le b \le 2t t≤b≤2t,则有 P ( − t ≤ Z ≤ t ) − P ( ℓ ≤ Z ≤ ℓ + 2 t ) = ( ∫ 0 t ϕ ( x ) d x − ∫ 0 a ϕ ( x ) d x ) − ( ∫ 0 b ϕ ( x ) d x − ∫ 0 t ϕ ( x ) d x ) = ∫ a t ϕ ( x ) d x − ∫ t b ϕ ( x ) d x = ∫ a t ϕ ( x ) d x − ∫ t 2 t − a ϕ ( x ) d x = ∫ a t ϕ ( x ) d x − ∫ t a ϕ ( x − a + t ) d x = ∫ a t ( ϕ ( x ) − ϕ ( x − a + t ) ) d x ≥ ∫ a t 0 d x = 0 \begin{aligned}&\mathbb{P}(-t\le Z \le t)-\mathbb{P}(\ell \le Z \le \ell + 2t)\\=&\left(\int_0^t \phi(x)dx -\int^{a}_0 \phi(x)dx\right)- \left(\int_0^b \phi(x)dx-\int_{0}^{t}\phi(x)dx\right)\\=&\int_a^{t} \phi(x)dx -\int^{b}_t \phi(x)dx\\=&\int_a^{t} \phi(x)dx -\int^{2t-a}_t \phi(x)dx \\=&\int_a^{t} \phi(x)dx -\int^{a}_t \phi(x-a+t)dx\\=&\int_a^{t} (\phi(x) -\phi(x-a+t))dx\\\ge& \int_{a}^t 0dx \\=&0\end{aligned} =====≥=P(−t≤Z≤t)−P(ℓ≤Z≤ℓ+2t)(∫0tϕ(x)dx−∫0aϕ(x)dx)−(∫0bϕ(x)dx−∫0tϕ(x)dx)∫atϕ(x)dx−∫tbϕ(x)dx∫atϕ(x)dx−∫t2t−aϕ(x)dx∫atϕ(x)dx−∫taϕ(x−a+t)dx∫at(ϕ(x)−ϕ(x−a+t))dx∫at0dx0其中不等式成立的原因在于 ϕ \phi ϕ在区间 [ 0 , + ∞ ) [0,+\infty) [0,+∞)上单调递减的。
命题3: 对于任意 τ > 0 \tau > 0 τ>0,存在一个基分类器 f f f和一个输入 x 0 x_0 x0,对应的平滑分类器 g g g在 x 0 x_0 x0处的鲁棒半径为 ∞ \infty ∞。
证明: 令 t = − Φ − 1 ( 1 2 Φ ( τ ) ) t=-\Phi^{-1}\left(\frac{1}{2}\Phi(\tau)\right) t=−Φ−1(21Φ(τ))并考虑一下基分类器 f ( x ) = { 1 i f x < − t − 1 i f − t ≤ x ≤ t 1 i f x > t f(x)=\left\{\begin{array}{ll}1&\mathrm{if}\text{ }x<-t\\-1 & \mathrm{if}-t\le x\le t\\1&\mathrm{if}x>t\end{array}\right. f(x)=⎩ ⎨ ⎧1−11if x<−tif−t≤x≤tifx>t令 g g g表示的当 σ = 1 \sigma=1 σ=1时的 f f f平滑分类器 g g g。令 Z ∼ N ( 0 , 1 ) Z\sim\mathcal{N}(0,1) Z∼N(0,1),对于任意的 x x x,则有 P ( f ( x + ε ) = − 1 ) = P ( − t ≤ x + ε ≤ t ) = P ( − t − x ≤ Z ≤ t − x ) ≤ P ( − t ≤ Z ≤ t ) = 1 − 2 Φ ( − t ) = 1 − Φ ( τ ) ≤ 1 2 \begin{aligned}\mathbb{P}(f(x+\varepsilon)=-1)&=\mathbb{P}(-t\le x+\varepsilon \le t)\\&=\mathbb{P}(-t-x\le Z \le t-x)\\&\le \mathbb{P}(-t\le Z \le t)\\&=1-2\Phi(-t)\\&=1-\Phi(\tau)\\&\le \frac{1}{2}\end{aligned} P(f(x+ε)=−1)=P(−t≤x+ε≤t)=P(−t−x≤Z≤t−x)≤P(−t≤Z≤t)=1−2Φ(−t)=1−Φ(τ)≤21以上第一个不等式令 ℓ = − t − x \ell=-t-x ℓ=−t−x并由引理1推知,因此可知,对于任意的 x x x,有 g ( x ) = 1 g(x)=1 g(x)=1,即 x x x的鲁棒半径为 ∞ \infty ∞。但是由定理1可知,对于 x 0 = 0 x_0=0 x0=0时,则有 P ( f ( x 0 + ε ) = 1 ) = P ( f ( ε ) = 1 ) = P ( Z ≤ − t o r Z > t ) = 2 Φ ( − t ) = Φ ( τ ) \begin{aligned}\mathbb{P}(f(x_0+\varepsilon)=1)&=\mathbb{P}(f(\varepsilon)=1)\\&=\mathbb{P}(Z\le -t \text{ }\mathrm{or}\text{ }Z>t)\\&=2\Phi(-t)\\&=\Phi(\tau)\end{aligned} P(f(x0+ε)=1)=P(f(ε)=1)=P(Z≤−t or Z>t)=2Φ(−t)=Φ(τ)所以可知,在 x 0 = 0 x_0=0 x0=0出的鲁棒半径为 R = τ R=\tau R=τ。
7.2 噪声训练
令 { ( x 1 , c 1 ) , ⋯ , ( x n , c n ) } \{(x_1,c_1),\cdots,(x_n,c_n)\} {(x1,c1),⋯,(xn,cn)}是一个训练集,假定基分类器的形式为 f ( x ) = arg max c ∈ Y f c ( x ) f(x)=\arg\max\limits_{c\in \mathcal{Y}}f_c(x) f(x)=argc∈Ymaxfc(x),其中 f c f_c fc为类别 c c c的概率得分。训练目标为最大化 f f f将 x i + ε x_i+\varepsilon xi+ε分为类 c i c_i ci的对数概率之和 ∑ i = 1 n log P ε ( f ( x i + ε ) = c i ) = ∑ i = 1 n log E ε 1 [ arg max c f c ( x i + ε ) = c i ] \sum\limits_{i=1}^n\log \mathbb{P}_{\varepsilon}(f(x_i+\varepsilon)=c_i)=\sum\limits_{i=1}^n\log \mathbb{E}_\varepsilon {\bf{1}}\left[\argmax\limits_c f_c(x_i+\varepsilon)=c_i\right] i=1∑nlogPε(f(xi+ε)=ci)=i=1∑nlogEε1[cargmaxfc(xi+ε)=ci]因为 s o f t m a x \mathrm{softmax} softmax函数是连续的且可以近似 arg max \argmax argmax函数 1 [ arg max c f c ( x i + ε ) = c i ] ≈ exp ( f c i ( x i + ε ) ) ∑ c ∈ Y exp ( f c ( x i + ε ) ) {\bf{1}}\left[\arg\max\limits_c f_c(x_i+\varepsilon)=c_i\right]\approx \frac{\exp(f_{c_i}(x_i+\varepsilon))}{\sum\limits_{c\in\mathcal{Y}}\exp(f_c(x_i+\varepsilon))} 1[argcmaxfc(xi+ε)=ci]≈c∈Y∑exp(fc(xi+ε))exp(fci(xi+ε))进而目标函数可以近似为 ∑ i = 1 n log E ε [ exp ( f c i ( x i + ε ) ) ∑ c ∈ Y exp ( f c ( x i + ε ) ) ] \sum\limits_{i=1}^n\log\mathbb{E}_\varepsilon\left[\frac{\exp(f_{c_i}(x_i+\varepsilon))}{\sum\limits_{c\in\mathcal{Y}}\exp(f_c(x_i+\varepsilon))}\right] i=1∑nlogEε⎣ ⎡c∈Y∑exp(fc(xi+ε))exp(fci(xi+ε))⎦ ⎤由詹森不等式可知,可得下界 ∑ i = 1 n log E ε [ exp ( f c i ( x i + ε ) ) ∑ c ∈ Y exp ( f c ( x i + ε ) ) ] ≥ ∑ i = 1 n E ε [ log exp ( f c i ( x i + ε ) ) ∑ c ∈ Y exp ( f c ( x i + ε ) ) ] \sum\limits_{i=1}^n\log\mathbb{E}_\varepsilon\left[\frac{\exp(f_{c_i}(x_i+\varepsilon))}{\sum\limits_{c\in\mathcal{Y}}\exp(f_c(x_i+\varepsilon))}\right]\ge \sum\limits_{i=1}^n\mathbb{E}_\varepsilon \left[ \log\frac{\exp(f_{c_i}(x_i+\varepsilon))}{\sum\limits_{c\in\mathcal{Y}}\exp(f_c(x_i+\varepsilon))}\right] i=1∑nlogEε⎣ ⎡c∈Y∑exp(fc(xi+ε))exp(fci(xi+ε))⎦ ⎤≥i=1∑nEε⎣ ⎡logc∈Y∑exp(fc(xi+ε))exp(fci(xi+ε))⎦ ⎤这是高斯数据增强下的交叉熵损失的负数。