【Dataset】GoEmotions: A Dataset of Fine-Grained Emotions
GoEmotions: A Dataset of Fine-Grained Emotions
Abstract
理解用语言表达的情感有广泛的应用,从建立有同情的聊天机器人到检测有害的在线行为。可以使用具有细粒度类型的大规模数据集来改进,以适应该领域的进展。本文介绍了GoEmotits数据集,这是最大的58k个英语Reddit注释的手动注释数据集,标记为27种情绪类别或中性。作者通过主保留成分分析来演示了高质量的注释,用现有的情绪基准进行了迁移学习实验,以表明本文数据集可以很好地推广到其他领域和不同的情绪分类。作者基于BERT的模型在所提出的分类法中的平均f1分数为0.46,留下了很大的改进空间。
1. Introduction
情感的表达和检测是人类体验和社会互动的核心。几个单词,就能够表达各种各样的微妙和复杂的情感,因此,使机器能够理解情感和情感一直是一个长期的目标。
在过去的十年里,NLP研究人员为各种领域和应用提供了一些基于语言的情感分类数据集,包括新闻标题、推文和叙事序列等等。然而,现有的可用数据集是(1)大多数很小,包含多达几千个实例;(2)涵盖有限的情感分类。
最近,Bostan和Klinger在一个统一的框架下聚合了14个流行的情绪分类语料库,允许对现有资源进行直接比较。重要的是,他们的分析表明,在最大的手动注释情绪分类数据集CrowdFlower(其中包含了标记为13种情绪之一的40K条推文)中,注释质量存在差距。虽然他们的工作能够进行这种比较评估,但它强调了需要一个大规模的、一致标记的情感数据集,而不是一个细粒度的分类法,并演示了高质量的注释。

为此,作者编制了GoEmotits,这是最大的人类注释数据集,包括58k个精心选择的Reddit评论,标记为27个情绪类别或中性,并从流行的英语字幕中提取评论。表1显示了数据的说明性样本。作者设计情感分类考虑到了心理学的相关工作和数据覆盖。与Ekman的分类法只包含一种积极的情绪(快乐)相比,本文的分类法包含了大量的积极、消极和模糊的情绪类别,这使得它适合于下游的需要对情绪表达进行微妙理解的对话理解任务,如对客户反馈的分析或聊天机器人的增强。
本文包括了对注释数据和注释质量的全面分析。通过主保留成分分析,显示了所有27种情绪类别之间可靠分离的强有力支持,表明本文的注释适合建立一个情绪分类模型。
作者对情绪判断进行了层次聚类,发现与强度相关的情绪紧密地聚类在一起,而顶层的聚类对应于情绪类别。如果需要进行下游任务,这些情绪之间的关系允许将它们潜在的分组到更高的层次的类别中。
作者提供了一个强大的基线来建模精细的情绪分类。通过微调bert基模型,本文的分类法的平均f1得分为0.46,Ekman风格的分类为0.64,情绪分组为0.69。这些结果留下了很大的改进空间,展示了目前最先进的NLU模型还没有完全解决这一任务。
作者用现有的情绪基准进行了迁移学习实验,以表明本文的数据可以推广到不同的分类法和领域,比如推文和个人叙述。实验表明,由于有有限的资源来标记特定领域的额外情绪分类数据,我们的数据可以提供基线的情绪理解,并有助于提高目标领域的模型准确性。
2. Related Work
2.1 Emotion Datasets
自从Affective Text,情感识别的第一个基准被引入以来,该领域已经看到了几个在大小、领域和分类法上都不同的情感数据集。大部分的情绪数据集都是手工构建的,但往往相对较小。最大的手动标记数据集是CrowdFlower,有39k个标记的例子,Bostan和Klinger发现,与其他情绪数据集相比是嘈杂的。其他数据集基于推特上的情感相关标签进行自动弱标记。作者人工构建数据集,使其成为最大的人工注释数据集,每个示例都有多个注释以保证质量。
一些现有的数据集来自推特的领域,因为它的非正式语言和表达性内容,比如 emojis and hashtags。其他数据集注释新闻标题、对话框、童话、电影字幕、基于框架网或自我报告的经历等领域。作者是第一个基于Reddit评论进行情感预测的人。
2.2 Emotion Taxonomy
区分本文数据集的一个主要方面是它的情感分类法。绝大多数现有数据集包含了Ekman提出的6个基本情绪类别(快乐、愤怒、恐惧、悲伤、悲伤、厌恶和惊讶)和/或情感维度(效价和觉醒)的注释,这些维度支持了情感的循环模型。
心理学的最新进展提供了新的概念和方法方法,通过计算技术研究情绪对不同刺激的反应分布,来捕捉更复杂的情绪“语义空间”。研究指导这些原则已经确定了27个不同品种的情感体验通过短视频,13音乐,28的面部表情,12通过演讲韵律,和24日非语言发声。在这项工作中,作者在这些方法和发现的基础上,设计了基于文本的情感识别的细粒度分类法,并研究了基于语言的情感空间的维度。
2.3 Emotion Classifification Models
基于特征的模型和神经模型都已被用于构建自动情绪分类模型。基于特征的模型通常使用手工构建的词汇,如效价唤醒词汇。使用代表BERT,基于transformer的语言模型与预训练模型。最近显示达到最先进的性能在几个自然语言处理的任务,还包括情绪预测:情绪中表现最好的模型挑战都采用预先训练的BERT模型。作者在实验中也使用了BERT模型,发现它优于biLSTM模型。
3. GoEmotions
数据集由58KReddit评论组成,标记为27种情绪中的一个或多个,或中性。
3.1 Selecting & Curating Reddit comments
本文使用来自Reddit数据工具项目的Reddit数据转储,其中包含从2005年(Reddit的开始)到2019年1月的评论,选择至少有10k注释的字幕,并删除已删除和非英语注释。
Reddit以倾向于年轻男性用户的人口偏见而闻名,这并不能反映全球人口的多样性。该平台还引入了对有毒、冒犯性语言的倾斜。因此,Reddit内容已被用于研究抑郁症、微侵犯。Yanardag 和 Rahwan 通过训练“精神病患者”机器人来显示使用有偏见的Reddit数据的效果。为了解决这些问题,并能够使用GoEmotions建立具有广泛代表性的情绪模型,作者采取了一系列数据管理措施,以确保数据不会强化一般的或特定情绪的语言偏见。
作者使用预先定义的列表来识别有害的评论,其中包括冒犯/成人、粗俗(轻度冒犯的亵渎)、身份和宗教术语(包括作为补充材料)。这些数据用于数据过滤和掩蔽,如下所述。列表是内部编译的,作者相信它们对于数据集的管理是全面的和广泛有用的,但是,它们可能并不完整。
Reducing profanity. 作者删除了对工作不安全的副评论,其中10%的+评论包括攻击性/成人和粗俗的token,删除了包括攻击性/成人token在内的剩余评论。粗俗的评论被保留了下来,因为作为认为它们是学习负面情绪的核心。数据集包括过滤的token列表。
Manual review. 作者手动审查身份评论,并删除那些对特定种族、性别、性取向或残疾的冒犯。
Length filtering. 作者应用NLTK的单词标记化器,并选择3-30个标记长的注释,包括标点符号。为了创建一个相对平衡的注释长度分布,作者执行降采样,并使用中值标记计数(12)来限制注释的数量。
Sentiment balancing. 作者通过消除很少代表积极、消极、模糊或中性情绪的微妙偏见来减少情绪偏见。为了估计评论的情绪,作者运行自己的情绪预测模型,在2.2k个注释的示例上进行训练。情绪与情绪类别的映射如图2所示。排除了超过30%的中性评论或少于20%的负面、积极或模糊评论的评论。
Emotion balancing. 作者使用上面描述的试点模型为每个评论分配一个预测的情绪。然后通过对弱标记数据进行降采样来减少情绪偏差,并限制使用属于情绪数量中位数的评论数量。
Subreddit balancing. 为了避免流行字幕的过度表示,作者采用降采样,限制中位数字幕计数。从剩下的315k条注释(来自482个子引用)中,随机抽样进行注释。
Masking. 作者使用基于bert的命名实体标记器,用一种宗教标记来掩盖宗教术语。这些术语的列表也包含在本文的数据集中。请注意,评分者在评级期间查看了未隐藏的评论。
3.2 Taxonomy of Emotions
在创建分类法时,作者会寻求共同最大化以下目标
- Provide greatest coverage in terms of emotions expressed in our data. 为了解决这个问题,作者手动标记了数据的一小部分子集,并运行了一个试点任务,评分者可以在预定义的数据集上建议情绪标签。
- Provide greatest coverage in terms of kinds of emotional expression. 作者查阅了关于情感表达和认知的心理学文献。目前,还没有研究在文本领域识别情绪识别的主要类别(见2.2节),作者认为那些在其他领域(视频和语音)被识别为基本的情绪,可以假设也适用于文本。
- Limit overlap among emotions and limit the number of emotions. 作者不想包含太相似的情绪,因为这会使注释任务更加困难。此外,将类似的标签结合在高覆盖率会导致注释标签的爆炸式增长。
最后一组被选择的情绪列在表4和图1中。有关本文的多步骤分类法选择过程的更多细节,请参见附录B。
3.3 Annotation
作者给每个例子分配了三个评分者。对于那些没有评分者就至少一个情绪标签达成一致的例子,分配了另外两个评分者。所有的评分者的母语都是来自印度的英语。
Instructions. 评分者被要求识别文本作者表达的情绪,给出预先定义的情感定义(见附录A)和每种情绪的一些示例文本。评分者可以自由选择多种情绪,但被要求只选择那些他们有理由相信在文本中表达的情绪。如果评分者不确定所表达的任何情绪,他们就被要求选择中性的。我们为评分者提供了一个复选框,以表明一个例子是否特别难以贴上标签,在这种情况下,他们就不能选择任何情绪。我们删除了所有没有选择情感的例子。
The rater interface. Reddit的评论没有提供额外的元数据(如作者或子编辑)。为了帮助评分者在分类法中有情绪的大空间,他们得到了一个包含所有情绪类别的表(如图2),以及该情绪是否通常表达于某物(如不赞成),或者更多的是一种内在的感觉(如快乐)。该说明强调,这种分类的分离绝不是明确的,而是抓住了一般的趋势,作者鼓励评分者在他们认为合适的时候忽略分类。通过一个直接映射到表情符号上的情绪在UI中显示了一个表情符号,以进一步简化他们的解释。
4. Data Analysis

表2显示了数据的汇总统计数据。大多数的例子(83%)都有一个单一的情感标签,并且至少有两个评分者在一个标签上达成一致(94%)。中性类别占所有情绪标签的26%。作者从下面的分析中排除了该类别,因为作者不认为它是情绪语义空间的一部分。
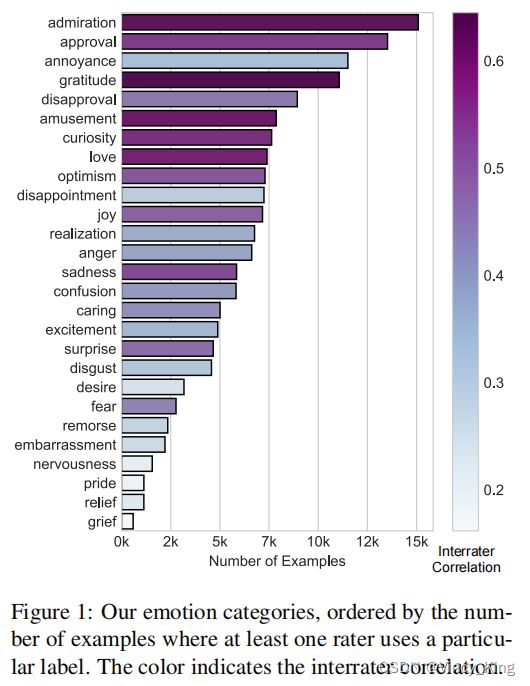
图1显示了情绪标签的分布情况。尽管在数据选择时采取了情感和情感平衡的步骤,但可以看到在情感频率方面的巨大差异(例如,admiration的频率是grief的30倍)。考虑到人类自然表达中情绪的不同频率,这是意料之中的。
4.1 Interrater Correlation
作者通过评估者之间的相关性来评估每种情绪的一致性。对于每个评分者 r ∈ R r ∈ R r∈R,计算 r r r的判断和其他评分者判断的平均值之间的Spearman correlation,对于所有 r r r评级的例子。然后,取这些评分者水平的相关性分数的平均值。第4.3节表明,在控制了几个潜在的混杂因素后,每种情绪都有显著的评分者间相关性。
图1显示, gratitude, admiration 和 amusement的相关性最高,而grief和nervousness的相关性最低。情绪频率与评分者之间的一致性相关,但两者并不相等。不频繁的情绪可能有相对较高的相关性(例如,fear),而频繁的情绪可能有相对较低的相关性(例如,annoyance)。
4.2 Correlation Among Emotions
为了更好地理解数据中情绪之间的关系,作者研究了它们之间的相关性。假设 N N N是数据集中的示例的数量。作者通过平均评分者对所有标记有该情绪的例子的判断,得到了每种情绪的N维向量。作者计算了每对情绪之间的皮尔逊相关值。图2中的热力图显示,与强度相关的情绪(如annoyance and anger,joy and excitement, nervousness and fear)有很强的正相关关系。另一方面,与情绪相反的情绪呈负相关。
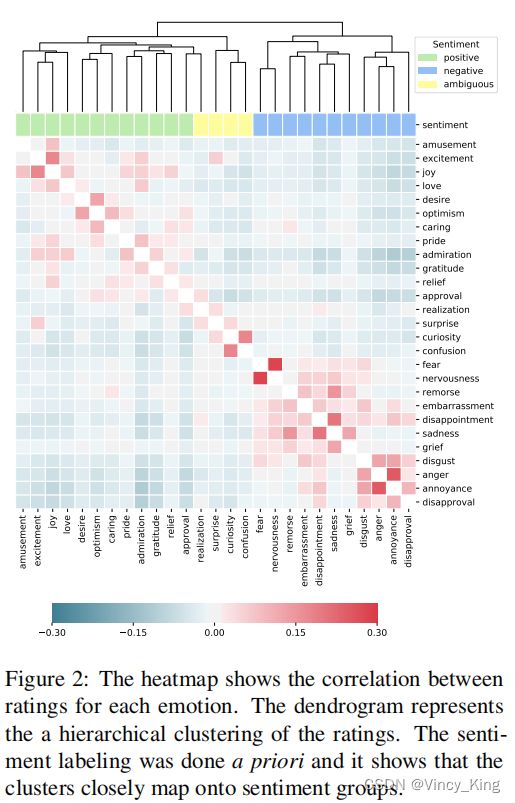
作者还使用分层聚类来揭示分类法的嵌套结构,使用相关性作为距离度量,ward作为链接方法,应用于平均评级。图2顶部的树状图显示,与强度相关的情绪是相邻的,而较大的集群与情绪类别紧密相连。有趣的是,将这些情绪标记为“ambiguous”的情绪(例如,surprise)更接近于积极的类别,而不是消极的类别。这表明,在本文的数据中,模糊的情绪更容易发生在积极情绪的背景下,而不是消极情绪。
4.3 Principal Preserved Component Analysis
为了更好地理解评分者之间的一致性和情绪空间的潜在结构,作者将主保留成分分析(PPCA)应用于本文数据。PPCA提取属性的线性组合(这里是情感判断),这些属性最大限度地跨越两组测量相同属性的数据(这里,为每个例子随机分割判断)。因此,PPCA允许揭示在评分者之间具有高度一致的情感的潜在维度。
与主成分分析(PCA)不同,PPCA检查的是数据集之间的交叉协方差,而不是单个数据集中的变异生态方差矩阵。通过计算对称交叉协方差矩阵 X T Y + Y T X X^TY+Y^TX XTY+YTX的特征向量,得到了两个数据集(矩阵) X , Y ∈ R N × ∣ E ∣ X,Y∈R^{N×|E|} X,Y∈RN×∣E∣的主保留分量(PPCs),其中 N N N是例子的数量, ∣ E ∣ |E| ∣E∣是情绪的数量。
Extracting significant dimensions. 作者删除标记为中性的示例,并保留那些在此过滤步骤之后仍然有3个评级的示例。然后使用leave-one-rater的分析来确定重要维度的数量,如算法1所描述的那样。
作者发现所有27个PPCs都是非常重要的。具体来说,Bonferroni-corrected p-values对所有维度都小于1.5e-6(校正后的α=0.0017),表明情绪是高度可分离的。对所有维度如此高的意义是不平凡的。
t-SNE projection. 为了更好地理解这些例子在情绪空间中是如何组织的,作者应用了t-SNE,一种降维方法,旨在保持数据点之间的距离。该数据集可以在交互式图进行探索,也可以查看文本和注释。每个数据点的颜色是RGB值的加权平均值,这些值代表了至少一半的评分者所选择的那些情绪。
4.4 Linguistic Correlates of Emotions
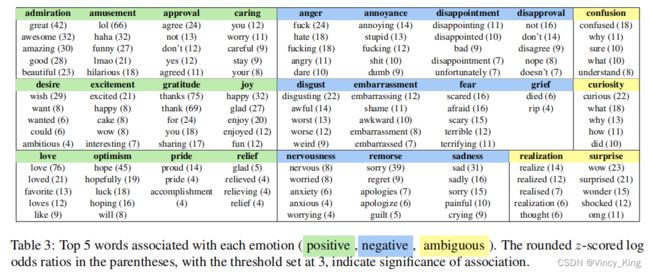
作者通过计算每个情绪类别的所有情绪的所有标记的对数比、informative Dirichlet prior来提取每种情绪的词汇相关性。由于对数概率是z分数,所有大于3的值都表明与相应的情绪有高度显著的(>3 std)关联。表3中列出了每个类别的前5个标记。作者发现,那些与某些标记高度显著相关的情绪(例如,对“thanks”的gratitude,对“lol”的amusement)往往具有最高的评估者间相关性(见图1)。相反,具有较少显著相关标记的情绪(如grief 和 nervousness)往往具有较低的内部相关性。这些结果表明,某些情绪在口头上是隐性的,可能需要更多的背景来解释。
5. Modeling
作者提出了一个强大的基线情绪预测模型。
5.1 Data Preparation
为了最小化数据中的噪声,作者只过滤掉由一个注释者选择的情绪标签。在执行此过滤后,保留了至少有一个标签的示例——这相当于原始数据的93%。作者将这些数据随机分成训练(80%)、dev(10%)和测试(10%)集。
尽管作者为基线实验过滤了数据,但在4K的例子中看到了缺乏一致性的特定值。这个数据子集可能包含情绪领域的边缘/困难例子(例如,情感模糊文本),并提出进一步探索提出挑战。这就是为什么作者发布了所有58K的例子和所有注释器的评级。
Grouping emotions. 作者为分类法创建一个分层分组,并在层次结构的每个级别上评估模型的性能。情绪水平将标签分为4个类别——positive, negative, ambiguous 和 Neutral ,中性类别是完整的,其余的映射如图2所示。Ekman级别使用中性标签和以下6组:anger(映射:anger, annoyance, disapproval)、disgust(映射:disgust)、fear(映射:fear, nervousness)、joy(all positive emotions)、sadness (映射:sadness, disappointment, embarrassment, grief, remorse)和surprise(all ambiguous emotions)。
5.2 Model Architecture
作者使用BERT-base模型进行实验。为了进行微调,在预先训练好的模型上添加了一个dense的输出层,并使用 sigmoid交叉熵损失函数来支持多标签分类。作为一个额外的baseline,作者训练了一个双向的LSTM。
5.3 Parameter Settings
在对预先训练好的BERT模型进行微调时,作者保持Devlin设置的大部分超参数不变,只改变批处理大小和学习率。我们发现,至少4个训练对于学习数据是必要的,但更多的训练会导致过拟合。batch size为16和学习率为5e-5可以产生最好的性能。对于biLSTM,作者将hidden layer dimensionality设置为256,学习率设置为0.1,衰减率为0.95,使用0.7的dropout。
5.4 Results
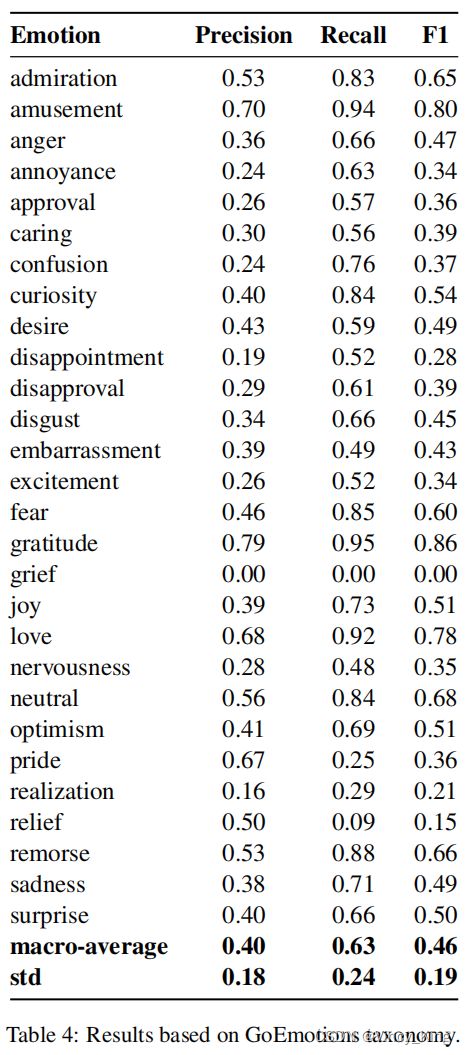
表4总结了最佳模型BERT在测试集上的性能,它的平均f1-score为0.46(std=.19)。该模型具有明显的词汇标记,如gratitude(0.86)、amusement(0.8)和love(0.78)。该模型在grief(0)、relief(.15)和realization(.21)上得到的f1分数最低,这是频率最低的情绪。作者发现,较不频繁的情绪往往被与情绪和强度相关的更频繁的情绪的模型所混淆(例如,grief with sadness, pride with admiration, nervousness with fear)——更详细的分析见附录G。


表5和表6分别显示了sentiment-groupted模型(f1-score=.69)和Ekman-grouped模型(f1-score=.64)的结果。从完全分类法到Ekman级分类法的性能显著提高表明,这种分组减轻了内部组较低级类别之间的混淆。biLSTM模型的表现明显低于BERT,完整分类法的平均f1-score为0.41,Ekman-grouped模型为0.53,sentiment-grouped模型的平均得分为0.6。
6. Transfer Learning Experiments
作者在现有的情绪基准上进行迁移学习实验,以显示本文数据概括跨领域和分类。目的是证明,给定目标领域的少量标记数据,可以利用GoEmotions作为基线情绪理解数据。
6.1 Emotion Benchmark Datasets
作者考虑了来自Bostan和Klinger的统一数据集的9个基准数据集,它们在大小、领域、质量和分类学方面都有所不同。为了空间的考虑,作者在这里只讨论其中三个数据集,它们是根据领域的多样性选择的。在实验中,作者观察到附加基准的类似趋势,所有这些都包含在附录H中。
The International Survey on Emotion Antecedents and Reactions (ISEAR) 是一组关于情感事件的个人报告,由3000名来自不同文化背景的人撰写。该数据集包含8k个句子,每个句子都标有一种情感。这些类别包括anger, disgust, fear, guilt, joy, sadness and shame。
EmoInt是SemEval2018基准的一部分,它包含7k条推文的人群注释。这些标签是对anger, joy, sadness, and fear的f-score强度注释。作者通过使用0.5作为截止点来获得针对这些情绪的二进制注释
Emotion-Stimulus包含了基于FrameNet的情绪导向框架生成的2.4k个句子的注释。他们的分类是anger, disgust, fear, joy, sadness, shame and surprise。
6.2 Experimental Setup
Training set size. 本文对来自目标域数据集的不同数量的训练数据进行了实验,包括100、200、500、1000和80%(称为“max”)的数据集示例。作者为每个train集的大小生成10个随机分割,剩下的例子作为一个测试集。本文报告了下面详细介绍的每个数据大小的微调实验的结果,以及基于使用分割的重复实验的证据间隔。
Finetuning. 本文比较了三种不同的微调设置。在baseline设置中,只对目标数据集进行微调BERT。在FREEZE设置中,首先对GoEmotions进行微调,然后替换最后的dense层,冻结除最后一层外的所有层,并对目标数据集进行微调。NOFREEZE的设置与冻结相同,只是不冻结底层。在所有实验中,保持批大小为16,学习速率在2e-5,epoch为3。
6.3 Results
图3中的结果表明,本文数据集可以很好地推广到不同的领域和分类,并且在来自目标领域的数据有限或用于标记的情况下,使用GoEmotions的模型可以提供帮助。给定有限的目标域数据(100或200个示例),对于所有三个数据集,冻结和不冻结产生的性能都显著高于基线。重要的是,无冻结结果显示所有训练集大小的性能显著更高,除了“max”,其中无冻结和基线表现相似。

7. Conclusion
本文提供了一个大型的、手动注释的、精心管理的数据集GoEmotions,用于细粒度的情绪预测。作者提供了详细的数据分析,演示了对完整分类法的注释的可靠性,并且通过迁移学习实验展示了数据跨领域和分类的通用性。作者通过微调BERT模型来建立一个强大的基线,结果表明未来有很大的改进空间。未来的工作可以探索情感评级的跨文化健壮性,并将分类法扩展到其他语言和领域。
Data Disclaimer: 该数据集包含偏差,并不能代表全局多样性,其也包含潜在的问题内容。数据中的潜在偏见包括:Reddit中的固有偏见和用户基础偏见,用于数据过滤的冒犯性/粗俗词汇列表,在评估冒犯性身份标签时的固有或无意识偏见,注释者的母语都来自印度。所有这些都可能会影响一个训练模型的标记、精确度和召回率。用于情绪标记的情绪试点模型,是根据研究团队回顾的例子进行训练的。任何使用这个数据集的人都应该知道这个数据集的这些限制。
心管理的数据集GoEmotions,用于细粒度的情绪预测。作者提供了详细的数据分析,演示了对完整分类法的注释的可靠性,并且通过迁移学习实验展示了数据跨领域和分类的通用性。作者通过微调BERT模型来建立一个强大的基线,结果表明未来有很大的改进空间。未来的工作可以探索情感评级的跨文化健壮性,并将分类法扩展到其他语言和领域。
Data Disclaimer: 该数据集包含偏差,并不能代表全局多样性,其也包含潜在的问题内容。数据中的潜在偏见包括:Reddit中的固有偏见和用户基础偏见,用于数据过滤的冒犯性/粗俗词汇列表,在评估冒犯性身份标签时的固有或无意识偏见,注释者的母语都来自印度。所有这些都可能会影响一个训练模型的标记、精确度和召回率。用于情绪标记的情绪试点模型,是根据研究团队回顾的例子进行训练的。任何使用这个数据集的人都应该知道这个数据集的这些限制。
Appendix A - Emotion Definitions
admiration:找到一些令人印象深刻的或值得尊重的东西。
amusement:寻找一些有趣的东西或被娱乐的东西。
anger:一种强烈的不满性或对抗性的情绪。
annoyance:轻微的愤怒,刺激。
approval:有或表达有利意见。
caring:对他人的关心和关心。
confusion:缺乏理解,缺乏不确定性。
curiosity :一种想知道或学习某样东西的强烈愿望。
desire:一种强烈的想要什么事情或希望有什么事情发生的感觉。
disappointment:因不实现其希望或期望而引起的悲伤或不满。
disapproval:有或表达不利意见的。
disgust:由不愉快或冒犯的东西引起的厌恶或强烈的反对。
embarrassment:自我意识、羞耻感或尴尬。
excitement:感到极大的热情和渴望。
fear:害怕或担心。
gratitude:一种感激和感激的感觉。
grief:强烈的悲伤,尤其是由某人的死亡引起的。
joy:一种快乐和幸福的感觉。
love:强烈的积极情感。
nervousness:恐惧,担心,焦虑。
optimism:对未来或某件事的成功的希望和信心。
pride:因自己的成就或与之密切相关的人的成就而获得的快乐或满足。
realization:意识到一些事情。
relief:从焦虑或痛苦中释放后的安慰和放松。
remorse:遗憾或内疚的感觉。
sadness:情感上的痛苦,悲伤。
surprise:感到惊讶,被一些意想不到的事情感到震惊。
Appendix B - Taxonomy Selection & Data Collection
作者通过仔细的多轮过程选择本文的分类法。在第一轮数据收集试点中,我们使用了Cowen and Keltner确定的显著情绪,确保集合包括Ekmans情绪类别,就像在之前的NLP工作中使用的那样。在这一轮中,作者还包括了一个开放的输入框,其中注释者可以建议不在选项中的情绪。在第一轮中注释了3K个例子,作者根据这一轮的结果更新了分类法(见下面的细节)。在第二轮数据收集试点中,用2k个新示例重复了这个过程,再次更新了分类法。
在回顾试点轮的结果时,作者识别并删除了那些注释者几乎没有选择的情绪和/或由于与其他情绪非常相似或难以从文本中检测而导致评估者间一致性较低的情绪。这些情绪都是boredom, doubt, heartbroken, indifference and calmness.。作者还确定并添加了这些情绪到分类法中,这些情绪经常被评分者建议和/或似乎在人工检查的数据中被代表。这些情绪是desire, disappointment, pride, realization, relief and remorse。在这个过程中,做则会还改进了类别名称(例如,用excitement取代ecstasy),细化到注释者似乎可以解释的名称。这就是如何到达最后一套27种情绪+中性。作者在构建分类法中考虑了可解释性,因此在网络数据中考虑了可解释性。发布的数据集在最终分类的第三轮中被标记。
Appendix C - Cohen’s Kappa Values
在第4.1节中,作者根据Delgado和Tibau的考虑,通过Spearman correlation来衡量评分者之间的一致性。在表7中,作者报告了用于比较的Cohen’s kappa值,通过为每个例子随机抽样两个评分,并计算这两组评分之间的Cohen’s kappa来获得这些比较。本文发现所有Cohen’s kappa值都大于0,显示出评分者的一致。此外,Cohen’s kappa值与评分者间高度相关(Pearson r = 0*.85, p < 0.*001),为每种情绪的参与者之间的显著一致性提供了确证的证据。

Appendix D - Sentiment of Reddit Subreddits
在第3节中,作者描述了如何获得在情感上是平衡的子属性。在这里,在应用过滤之前,作者注意到了情绪的分布:neutral (M=28%,STD=11%)、positive (M=41%,STD=11%)、negative(M=19%,STD=7%)、ambiguous (M=35%,STD=8%)。经过过滤后,剩下的情绪分布变为:neutral(M=24%,STD=5%)、positive(M=35%,STD=6%)、negative(M=27%,STD=4%)、ambiguous(M=33%,STD=4%)。
Appendix E - BERT’s Most Activated Layers
为了更好地理解BERT中是否有任何对本文的任务特别重要的层,作者冻结了BERT,并基于标量混合权重计算重心。作者发现所有的层对于本文的任务都同样重要,gravity=为6.19(见图4)。这与Tenney等人的观点一致,他们还发现,涉及高级语义的任务倾向于使用所有的BERT层。

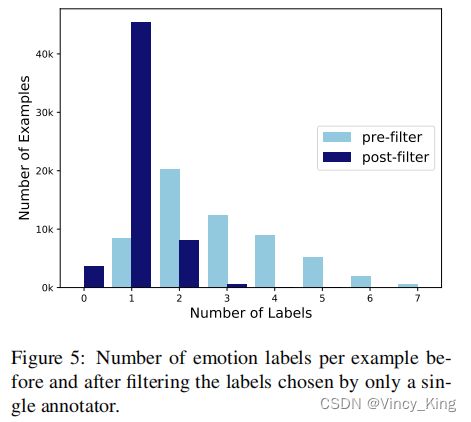
Appendix F - Number of Emotion Labels Per Example
图5显示了过滤那些有一致的标签前后的情绪标签的数量。作者使用过滤后的标签集来训练和测试模型。
Appendix G - Confusion Matrix
图6显示了模型预测的标准化混淆矩阵。由于GoEmotions是一个多标签数据集,所以计算混淆矩阵相当于计算一个共现矩阵:对于每个真实的标签,增加每个预测标签的计数。具体地说,定义了一个矩阵 M M M,其中 M i , j M_{i,j} Mi,j表示真实标签 i i i和预测标签 j j j之间的原始混淆计数。例如,如果真正的标签是joy和admiration,而预测的标签是joy和admiration,那么就增加了对 M j o y , j o y M_{joy,joy} Mjoy,joy, M j o y , p r i d e M_{joy,pride} Mjoy,pride, M a d m i r a t i o n , j o y M_{admiration,joy} Madmiration,joy和 M a d m i r a t i o n , p r i d e M_{admiration,pride} Madmiration,pride的数量。在实践中,由于大多数示例只有一个标签(见图5),因此混淆矩阵与为单标签分类任务计算的混淆矩阵非常相似。
给定标签之间的不同频率,作者通过将每一行的计数(表示每个真实情绪标签的计数)除以该行的和来规范化M。图6中的热力图显示了这些标准化的计数。该模型倾向于混淆与情绪和强度相关的情绪(例如,grief and sadness, pride and admiration, nervousness and fear)。

作者还使用相关性作为距离度量和ward作为链接方法对归一化混淆矩阵进行分层聚类。结果发现,该模型学习的集群与图2中的集群相对相似,尽管训练数据只包括具有一致性的标签子集(见图5)。
Appendix H - Transfer Learning Results
图7显示了 Unified Dataset 中所有9个数据集中可下载的数据集的结果。这些数据集是DailyDialog、Emotion-Stimulus、 Affective Text、Crowd Flower、 Electoral Tweets、ISEAR、the Twitter Emotion Corpus (TEC)、 EmoInt和the Stance Sentiment Emotion Corpus (SSEC)。
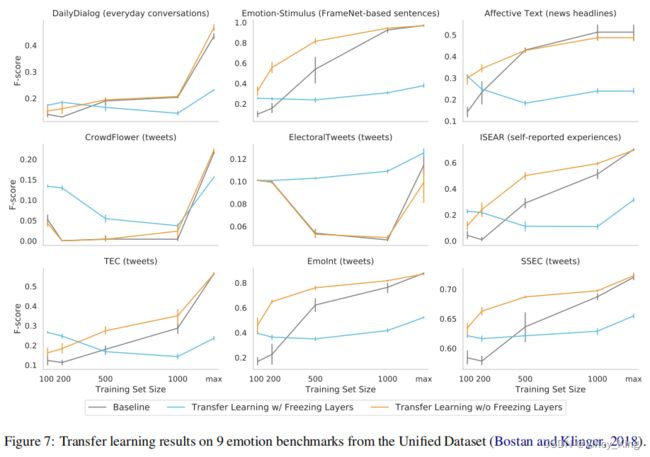
作者在第6.2节中描述了实验设置,在所有数据集上使用它。结果发现,迁移学习在所有数据集上都有帮助,特别是在有限的训练数据的情况下。有趣的是,Crowd Flower是已知的嘈杂和Electoral Tweets,这是一个4k的小标签的例子和36个大型分类情绪的数据集,FREEZE意味着不能提高性能的基线和冻结所有训练集大小除了“max”。
对于其他数据集,作者发现,与其他设置相比,冻结往往会提高性能,但最高可达几百个训练示例。对于500-1000个训练示例,NOFREEZE 往往优于基线,但可以看到,当有更多的训练数据时,这两个设置更接近。这些结果表明,如果来自目标域的数据有限,数据集会有帮助。