【神经网络】只用numpy从0到1实现神经网络
目录
1.导包(基本包numpy)
2.网络基本结构
3.初始化函数
4.激活函数
5.单层前向传播
6.完整的前向传播
7.交叉熵损失函数
8.转换函数(概率 -> 类别)
9.求解准确率
10.单层反向传播
11.完整的反向传播
12.梯度更新
13.训练函数
14.导包(sklearn、keras、tensorflow)
15.生成训练数据和测试数据
16.绘制图像函数
17.训练epochs = 1000轮
18.打印准确率
19.使用keras搭建神经网络模型
20.使用keras库搭建模型训练并输出准确率
21.绘制使用keras库搭建模型训练结果图像
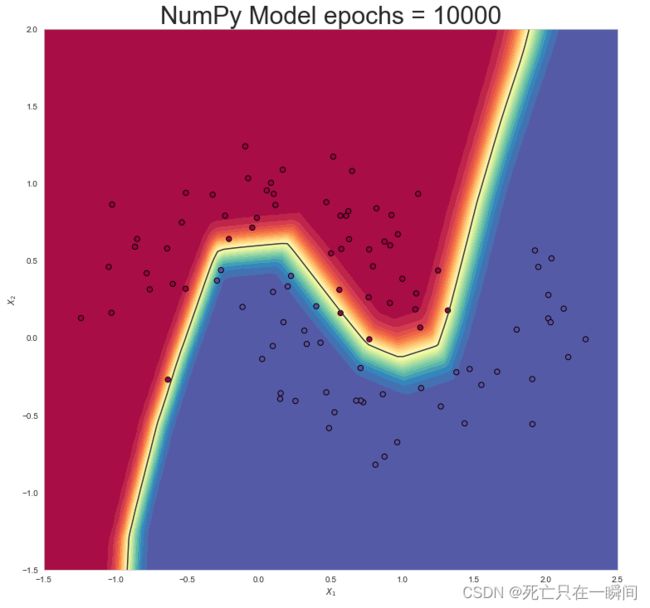
22.绘制numpy搭建的模型结果函数
23.增加epochs数继续训练
epochs = 2000:
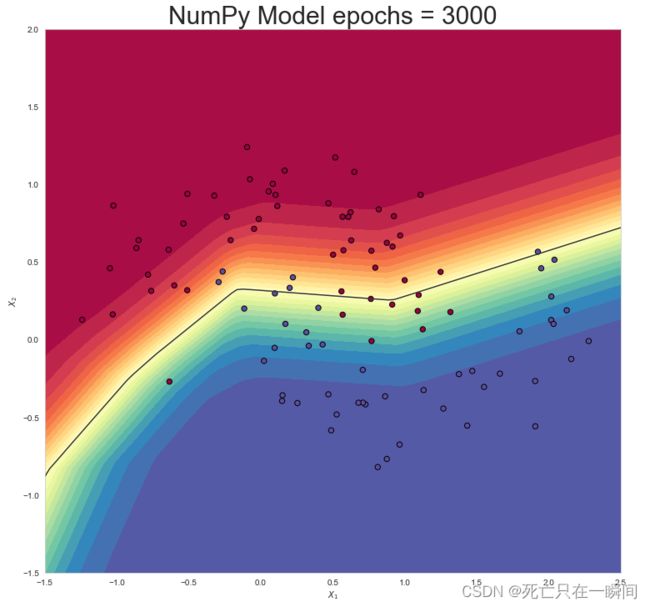
epochs = 3000:
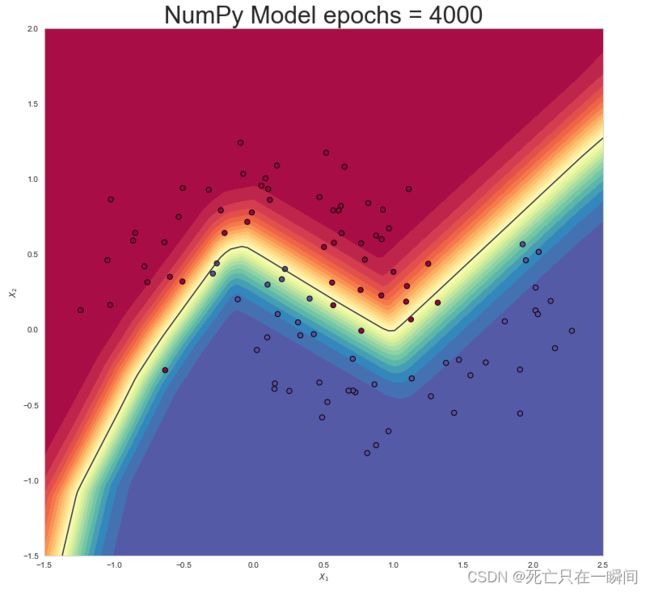
epochs = 4000:
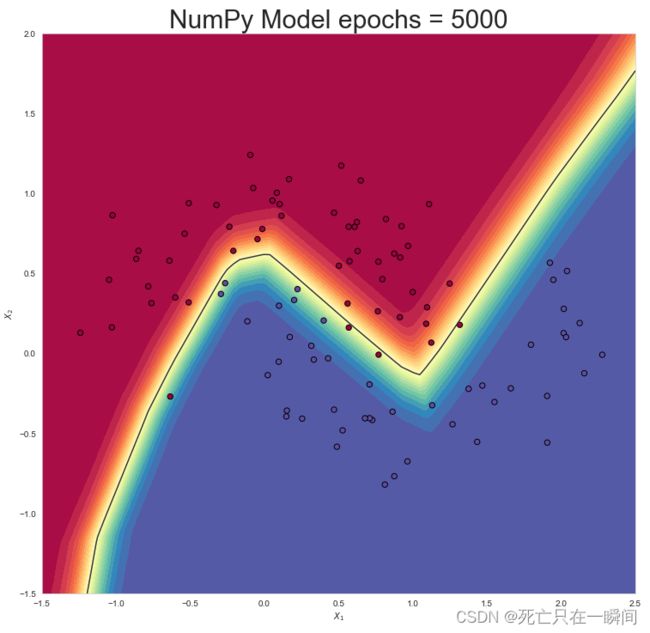
epochs = 5000:
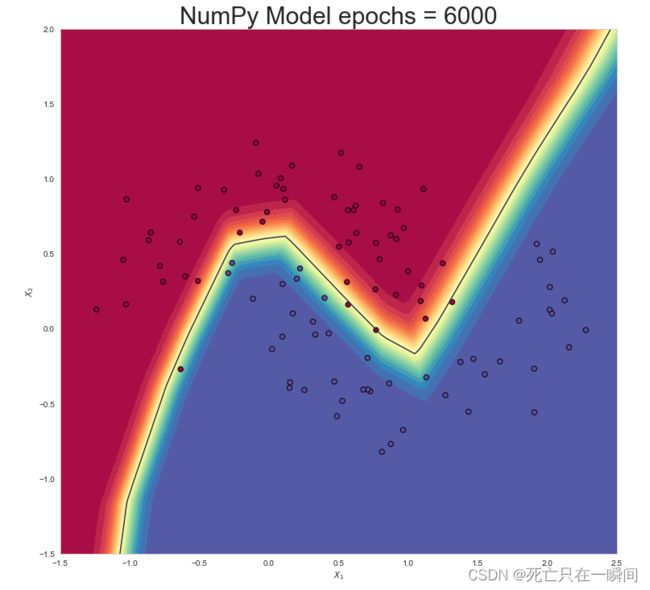
epochs = 6000:
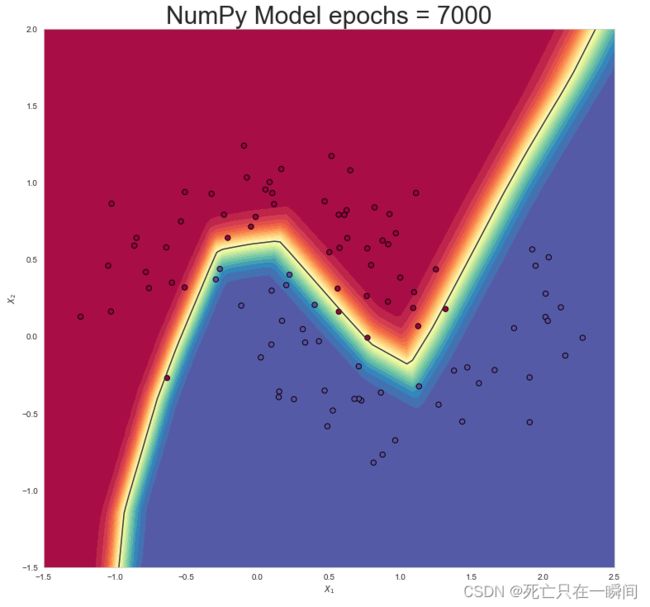
epochs = 7000:
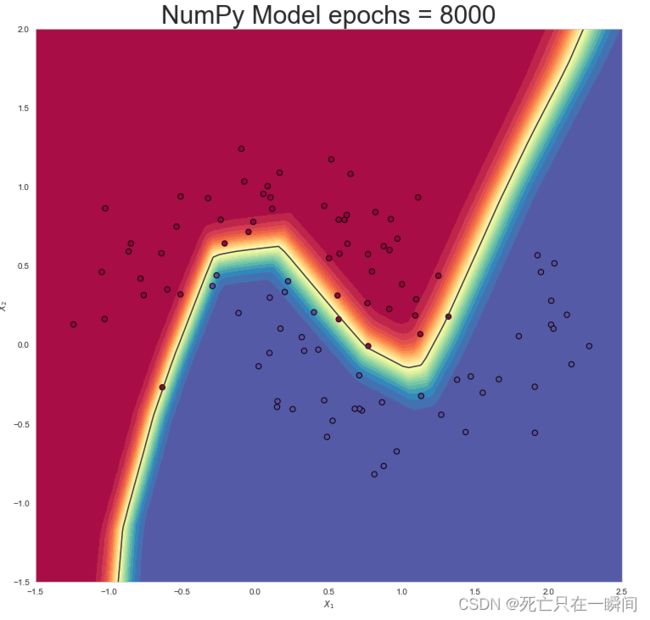
epochs = 8000:
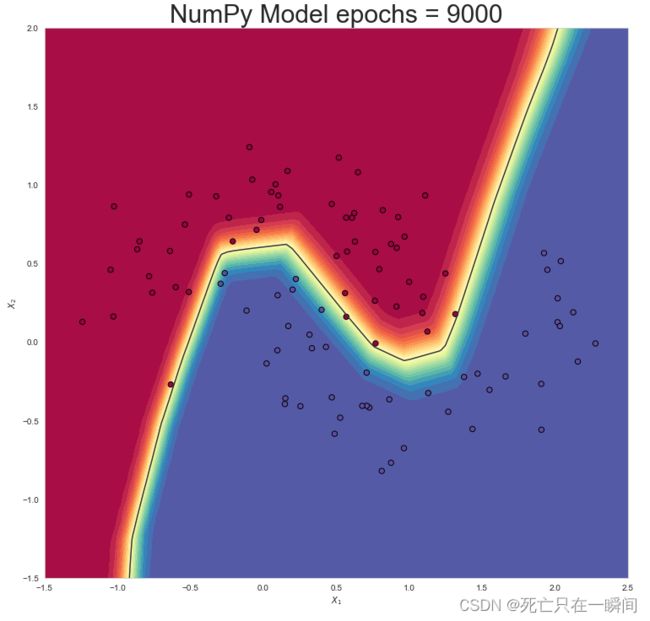
epochs = 9000:
epochs = 10000:
1.导包(基本包numpy)
import numpy as np
from IPython.display import Image2.网络基本结构
NN_ARCHITECTURE = [
{"input_dim": 2, "output_dim": 32, "activation": "relu"},
{"input_dim": 32, "output_dim": 64, "activation": "relu"},
{"input_dim": 64, "output_dim": 128, "activation": "relu"},
{"input_dim": 128, "output_dim": 64, "activation": "relu"},
{"input_dim": 64, "output_dim": 1, "activation": "sigmoid"},
]3.初始化函数
def init_layers(nn_architecture, seed = 99):
# random seed initiation
np.random.seed(seed)
# number of layers in our neural network
number_of_layers = len(nn_architecture)
# parameters storage initiation
params_values = {}
# iteration over network layers
for idx, layer in enumerate(nn_architecture):
# we number network layers from 1
layer_idx = idx + 1
# extracting the number of units in layers
layer_input_size = layer["input_dim"]
layer_output_size = layer["output_dim"]
# initiating the values of the W matrix
# and vector b for subsequent layers
params_values['W' + str(layer_idx)] = np.random.randn(
layer_output_size, layer_input_size) * 0.1
params_values['b' + str(layer_idx)] = np.random.randn(
layer_output_size, 1) * 0.1
return params_values4.激活函数
def sigmoid(Z):
return 1/(1+np.exp(-Z))
def relu(Z):
return np.maximum(0,Z)
def sigmoid_backward(dA, Z):
sig = sigmoid(Z)
return dA * sig * (1 - sig)
def relu_backward(dA, Z):
dZ = np.array(dA, copy = True)
dZ[Z <= 0] = 0;
return dZ;5.单层前向传播
def single_layer_forward_propagation(A_prev, W_curr, b_curr, activation="relu"):
# calculation of the input value for the activation function
Z_curr = np.dot(W_curr, A_prev) + b_curr
# selection of activation function
if activation == "relu":
activation_func = relu
elif activation == "sigmoid":
activation_func = sigmoid
else:
raise Exception('Non-supported activation function')
# return of calculated activation A and the intermediate Z matrix
return activation_func(Z_curr), Z_curr6.完整的前向传播
def full_forward_propagation(X, params_values, nn_architecture):
# creating a temporary memory to store the information needed for a backward step
memory = {}
# X vector is the activation for layer 0
A_curr = X
# iteration over network layers
for idx, layer in enumerate(nn_architecture):
# we number network layers from 1
layer_idx = idx + 1
# transfer the activation from the previous iteration
A_prev = A_curr
# extraction of the activation function for the current layer
activ_function_curr = layer["activation"]
# extraction of W for the current layer
W_curr = params_values["W" + str(layer_idx)]
# extraction of b for the current layer
b_curr = params_values["b" + str(layer_idx)]
# calculation of activation for the current layer
A_curr, Z_curr = single_layer_forward_propagation(A_prev, W_curr, b_curr, activ_function_curr)
# saving calculated values in the memory
memory["A" + str(idx)] = A_prev
memory["Z" + str(layer_idx)] = Z_curr
# return of prediction vector and a dictionary containing intermediate values
return A_curr, memory7.交叉熵损失函数
def get_cost_value(Y_hat, Y):
# number of examples
m = Y_hat.shape[1]
# calculation of the cost according to the formula
cost = -1 / m * (np.dot(Y, np.log(Y_hat).T) + np.dot(1 - Y, np.log(1 - Y_hat).T))
return np.squeeze(cost)8.转换函数(概率 -> 类别)
def convert_prob_into_class(probs):
probs_ = np.copy(probs)
probs_[probs_ > 0.5] = 1
probs_[probs_ <= 0.5] = 0
return probs_9.求解准确率
def get_accuracy_value(Y_hat, Y):
Y_hat_ = convert_prob_into_class(Y_hat)
return (Y_hat_ == Y).all(axis=0).mean()10.单层反向传播
def single_layer_backward_propagation(dA_curr, W_curr, b_curr, Z_curr, A_prev, activation="relu"):
# number of examples
m = A_prev.shape[1]
# selection of activation function
if activation == "relu":
backward_activation_func = relu_backward
elif activation == "sigmoid":
backward_activation_func = sigmoid_backward
else:
raise Exception('Non-supported activation function')
# calculation of the activation function derivative
dZ_curr = backward_activation_func(dA_curr, Z_curr)
# derivative of the matrix W
dW_curr = np.dot(dZ_curr, A_prev.T) / m
# derivative of the vector b
db_curr = np.sum(dZ_curr, axis=1, keepdims=True) / m
# derivative of the matrix A_prev
dA_prev = np.dot(W_curr.T, dZ_curr)
return dA_prev, dW_curr, db_curr11.完整的反向传播
def full_backward_propagation(Y_hat, Y, memory, params_values, nn_architecture):
grads_values = {}
# number of examples
m = Y.shape[1]
# a hack ensuring the same shape of the prediction vector and labels vector
Y = Y.reshape(Y_hat.shape)
# initiation of gradient descent algorithm
dA_prev = - (np.divide(Y, Y_hat) - np.divide(1 - Y, 1 - Y_hat));
for layer_idx_prev, layer in reversed(list(enumerate(nn_architecture))):
# we number network layers from 1
layer_idx_curr = layer_idx_prev + 1
# extraction of the activation function for the current layer
activ_function_curr = layer["activation"]
dA_curr = dA_prev
A_prev = memory["A" + str(layer_idx_prev)]
Z_curr = memory["Z" + str(layer_idx_curr)]
W_curr = params_values["W" + str(layer_idx_curr)]
b_curr = params_values["b" + str(layer_idx_curr)]
dA_prev, dW_curr, db_curr = single_layer_backward_propagation(
dA_curr, W_curr, b_curr, Z_curr, A_prev, activ_function_curr)
grads_values["dW" + str(layer_idx_curr)] = dW_curr
grads_values["db" + str(layer_idx_curr)] = db_curr
return grads_values12.梯度更新
def update(params_values, grads_values, nn_architecture, learning_rate):
# iteration over network layers
for layer_idx, layer in enumerate(nn_architecture, 1):
params_values["W" + str(layer_idx)] -= learning_rate * grads_values["dW" + str(layer_idx)]
params_values["b" + str(layer_idx)] -= learning_rate * grads_values["db" + str(layer_idx)]
return params_values;13.训练函数
def train(X, Y, nn_architecture, epochs, learning_rate, verbose=False, callback=None):
# initiation of neural net parameters
params_values = init_layers(nn_architecture, 2)
# initiation of lists storing the history
# of metrics calculated during the learning process
cost_history = []
accuracy_history = []
# performing calculations for subsequent iterations
for i in range(epochs):
# step forward
Y_hat, cashe = full_forward_propagation(X, params_values, nn_architecture)
# calculating metrics and saving them in history
cost = get_cost_value(Y_hat, Y)
cost_history.append(cost)
accuracy = get_accuracy_value(Y_hat, Y)
accuracy_history.append(accuracy)
# step backward - calculating gradient
grads_values = full_backward_propagation(Y_hat, Y, cashe, params_values, nn_architecture)
# updating model state
params_values = update(params_values, grads_values, nn_architecture, learning_rate)
if(i % 50 == 0):
if(verbose):
print("Iteration: {:05} - cost: {:.5f} - accuracy: {:.5f}".format(i, cost, accuracy))
if(callback is not None):
callback(i, params_values)
return params_values14.导包(sklearn、keras、tensorflow)
import os
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
sns.set_style("whitegrid")
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from keras import regularizers
from sklearn.metrics import r2_score15.生成训练数据和测试数据
# number of samples in the data set
N_SAMPLES = 1000
# ratio between training and test sets
TEST_SIZE = 0.1
# 生成训练数据和测试数据
X, y = make_moons(n_samples = N_SAMPLES, noise=0.2, random_state=100)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=42)16.绘制图像函数
def make_plot(X, y, plot_name, file_name=None, XX=None, YY=None, preds=None, dark=False):
if (dark):
plt.style.use('dark_background')
else:
sns.set_style("whitegrid")
plt.figure(figsize=(16,12))
axes = plt.gca()
axes.set(xlabel="$X_1$", ylabel="$X_2$")
plt.title(plot_name, fontsize=30)
plt.subplots_adjust(left=0.20)
plt.subplots_adjust(right=0.80)
if(XX is not None and YY is not None and preds is not None):
plt.contourf(XX, YY, preds.reshape(XX.shape), 25, alpha = 1, cmap=cm.Spectral)
plt.contour(XX, YY, preds.reshape(XX.shape), levels=[.5], cmap="Greys", vmin=0, vmax=.6)
plt.scatter(X[:, 0], X[:, 1], c=y.ravel(), s=40, cmap=plt.cm.Spectral, edgecolors='black')
if(file_name):
plt.savefig(file_name)
plt.close()
make_plot(X, y, "Dataset")17.训练epochs = 1000轮
# epochs = 1000 Training
params_values = train(np.transpose(X_train), np.transpose(y_train.reshape((y_train.shape[0], 1))), NN_ARCHITECTURE, 1000, 0.01)18.打印准确率
# Prediction
Y_test_hat, _ = full_forward_propagation(np.transpose(X_test), params_values, NN_ARCHITECTURE)
# Accuracy achieved on the test set
acc_test = get_accuracy_value(Y_test_hat, np.transpose(y_test.reshape((y_test.shape[0], 1))))
print("Test set accuracy: {:.2f} - Numpy epochs = 1000".format(acc_test))19.使用keras搭建神经网络模型
# Building a model
model = Sequential()
model.add(Dense(25, input_dim=2,activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(25, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer="sgd", metrics=['accuracy'])
# Training
history = model.fit(X_train, y_train, epochs=1000, verbose=0)20.使用keras库搭建模型训练并输出准确率
Y_test_hat = model.predict(X_test)
acc_test = r2_score(y_test, Y_test_hat)
print("Test set accuracy: {:.2f} - Tensorflow".format(acc_test))21.绘制使用keras库搭建模型训练结果图像
# boundary of the graph
GRID_X_START = -1.5
GRID_X_END = 2.5
GRID_Y_START = -1.0
GRID_Y_END = 2
# output directory (the folder must be created on the drive)
OUTPUT_DIR = "./"grid = np.mgrid[GRID_X_START:GRID_X_END:100j,GRID_X_START:GRID_Y_END:100j]
grid_2d = grid.reshape(2, -1).T
XX, YY = griddef callback_keras_plot(epoch, logs):
plot_title = "Keras Model - It: {:05}".format(epoch)
file_name = "keras_model_{:05}.png".format(epoch)
file_path = os.path.join(OUTPUT_DIR, file_name)
prediction_probs = model.predict_proba(grid_2d, batch_size=32, verbose=0)
make_plot(X_test, y_test, plot_title, file_name=file_path, XX=XX, YY=YY, preds=prediction_probs)
# Adding callback functions that they will run in every epoch
testmodelcb = keras.callbacks.LambdaCallback(on_epoch_end=callback_keras_plot)
prediction_probs = model.predict(grid_2d, batch_size=32, verbose=0)
make_plot(X_test, y_test, "Keras Model", file_name=None, XX=XX, YY=YY, preds=prediction_probs)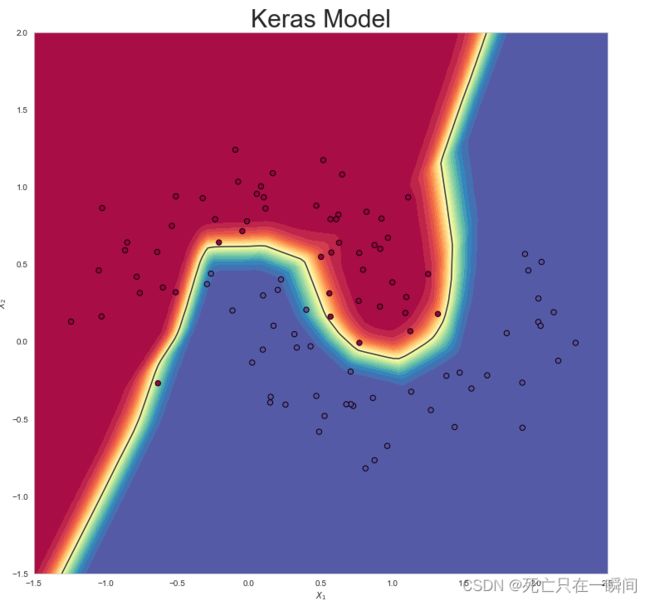
22.绘制numpy搭建的模型结果函数
def callback_numpy_plot(index, params):
plot_title = "NumPy Model - It: {:05}".format(index)
file_name = "numpy_model_{:05}.png".format(index//50)
file_path = os.path.join(OUTPUT_DIR, file_name)
prediction_probs, _ = full_forward_propagation(np.transpose(grid_2d), params, NN_ARCHITECTURE)
prediction_probs = prediction_probs.reshape(prediction_probs.shape[1], 1)
make_plot(X_test, y_test, plot_title, file_name=file_path, XX=XX, YY=YY, preds=prediction_probs, dark=True)callback_numpy_plot(1000, params_values)prediction_probs_numpy, _ = full_forward_propagation(np.transpose(grid_2d), params_values, NN_ARCHITECTURE)
prediction_probs_numpy = prediction_probs_numpy.reshape(prediction_probs_numpy.shape[1], 1)
make_plot(X_test, y_test, "NumPy Model epochs = 1000", file_name=None, XX=XX, YY=YY, preds=prediction_probs_numpy)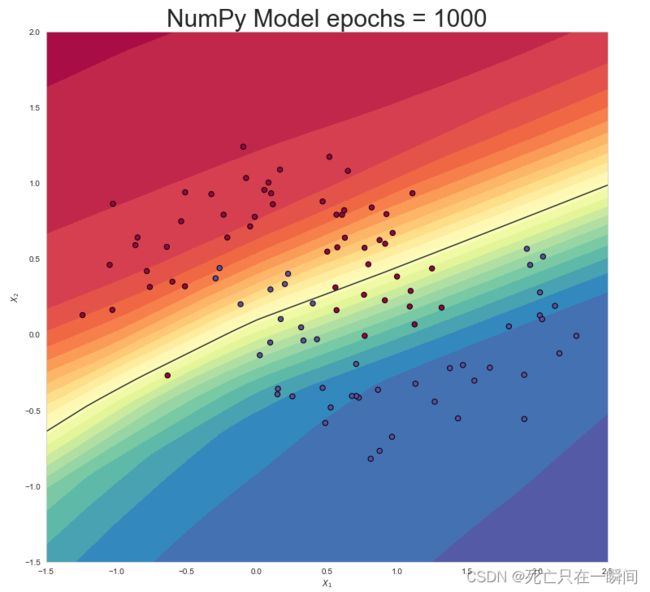
23.增加epochs数继续训练
# epochs = 2000 Training
params_values = train(np.transpose(X_train), np.transpose(y_train.reshape((y_train.shape[0], 1))), NN_ARCHITECTURE, 2000, 0.01)
# Prediction
Y_test_hat, _ = full_forward_propagation(np.transpose(X_test), params_values, NN_ARCHITECTURE)
# Accuracy achieved on the test set
acc_test = get_accuracy_value(Y_test_hat, np.transpose(y_test.reshape((y_test.shape[0], 1))))
print("Test set accuracy: {:.2f} - Numpy epochs = 2000".format(acc_test))callback_numpy_plot(2000, params_values)prediction_probs_numpy, _ = full_forward_propagation(np.transpose(grid_2d), params_values, NN_ARCHITECTURE)
prediction_probs_numpy = prediction_probs_numpy.reshape(prediction_probs_numpy.shape[1], 1)
make_plot(X_test, y_test, "NumPy Model epochs = 2000", file_name=None, XX=XX, YY=YY, preds=prediction_probs_numpy)epochs = 2000:
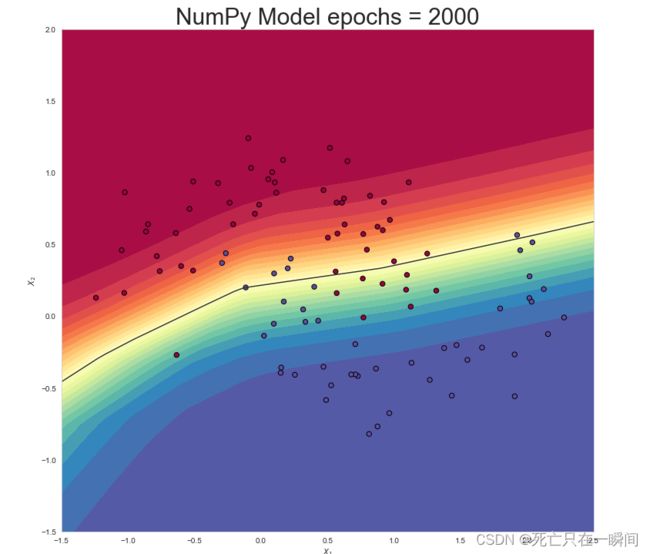
epochs = 3000:
epochs = 4000:
epochs = 5000:
epochs = 6000:
epochs = 7000:
epochs = 8000:
epochs = 9000:
epochs = 10000: