11.06周报 实验流程以simple baseline代码为例解析
目录
-
- 前言
- human-pose-estimation.pytorch-master
-
- 源码项目结构
- 配置文件
- 训练train.py
-
- 过程结构
- 代码注释
- 数据读取,预处理
-
- coco.py
- JointsDataset.py
- 构建模型
- 验证
- 补充知识
-
- 数据增强
- 使用增加数据训练
- parser.add_argument()用法——命令行选项、参数和子命令解析器
- 总结
前言
以simple baseline代码为例,将人体姿态估计的整个流程走了一遍,了解到了数据处理,训练,验证的过程以及参数的作用。
human-pose-estimation.pytorch-master
源码项目结构


配置文件
数据存在yaml配置文件中,更容易进行数据更改和查看,调用也很方便
改yaml为coco数据集,resnet50,3x256x192的配置文件

训练train.py
过程结构
- 解析参数
- 构建网络模型
- 加载训练测试数据集迭代器
- 迭代训练
- 模型评估保存
代码注释
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
# Written by Bin Xiao ([email protected])
# ------------------------------------------------------------------------------
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os
import pprint
import shutil
import torch
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from tensorboardX import SummaryWriter
import _init_paths
from lib.core.config import config
from lib.core.config import update_config
from lib.core.config import update_dir
from lib.core.config import get_model_name
from lib.core.loss import JointsMSELoss
from lib.core.function import train
from lib.core.function import validate
from lib.utils.utils import get_optimizer
from lib.utils.utils import save_checkpoint
from lib.utils.utils import create_logger
import lib.dataset
import lib.models
def parse_args():
parser = argparse.ArgumentParser(description='Train keypoints network')
# general
# general,指定yaml文件的路径
parser.add_argument('--cfg',
help='experiment configure file name',
required=True,
type=str)
args, rest = parser.parse_known_args()
# update config
update_config(args.cfg)
# training
parser.add_argument('--frequent',
help='frequency of logging',
default=config.PRINT_FREQ,
type=int)
parser.add_argument('--gpus',
help='gpus',
type=str)
parser.add_argument('--workers',
help='num of dataloader workers',
type=int)
args = parser.parse_args()
return args
def reset_config(config, args):
if args.gpus:
config.GPUS = args.gpus
if args.workers:
config.WORKERS = args.workers
def main():
# 对输入参数进行解析
args = parse_args()
# 根据输入参数对cfg进行更新
reset_config(config, args)
# 创建logger,用于记录训练过程的打印信息
logger, final_output_dir, tb_log_dir = create_logger(
config, args.cfg, 'train')
logger.info(pprint.pformat(args))
logger.info(pprint.pformat(config))
# cudnn related setting
# 使用GPU的一些相关设置
cudnn.benchmark = config.CUDNN.BENCHMARK
torch.backends.cudnn.deterministic = config.CUDNN.DETERMINISTIC
torch.backends.cudnn.enabled = config.CUDNN.ENABLED
# 根据配置文件构建网络
model = eval('models.'+config.MODEL.NAME+'.get_pose_net')(
config, is_train=True
)
# copy model file
# 拷贝lib /models/pose_resnet.py文件到输出目录之中
this_dir = os.path.dirname(__file__)
shutil.copy2(
os.path.join(this_dir, '../lib/models', config.MODEL.NAME + '.py'),
final_output_dir)
# 用于训练信息的图形化显示
writer_dict = {
'writer': SummaryWriter(log_dir=tb_log_dir),
'train_global_steps': 0,
'valid_global_steps': 0,
}
# 用于模型的图形化显示
dump_input = torch.rand((config.TRAIN.BATCH_SIZE,
3,
config.MODEL.IMAGE_SIZE[1],
config.MODEL.IMAGE_SIZE[0]))
writer_dict['writer'].add_graph(model, (dump_input, ), verbose=False)
# 让模型支持多GPU训练
gpus = [int(i) for i in config.GPUS.split(',')]
model = torch.nn.DataParallel(model, device_ids=gpus).cuda()
# define loss function (criterion) and optimizer,用于计算loss
criterion = JointsMSELoss(
use_target_weight=config.LOSS.USE_TARGET_WEIGHT
).cuda()
optimizer = get_optimizer(config, model)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(
optimizer, config.TRAIN.LR_STEP, config.TRAIN.LR_FACTOR
)
# Data loading code 数据集加载
# Data loading code,对输入图象数据进行正则化处理
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# 创建训练以及测试数据的迭代器
train_dataset = eval('dataset.'+config.DATASET.DATASET)(
config,
config.DATASET.ROOT,
config.DATASET.TRAIN_SET,
True,
transforms.Compose([
transforms.ToTensor(),
normalize,
])
)
valid_dataset = eval('dataset.'+config.DATASET.DATASET)(
config,
config.DATASET.ROOT,
config.DATASET.TEST_SET,
False,
transforms.Compose([
transforms.ToTensor(),
normalize,
])
)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=config.TRAIN.BATCH_SIZE*len(gpus),
shuffle=config.TRAIN.SHUFFLE,
num_workers=config.WORKERS,
pin_memory=True
)
valid_loader = torch.utils.data.DataLoader(
valid_dataset,
batch_size=config.TEST.BATCH_SIZE*len(gpus),
shuffle=False,
num_workers=config.WORKERS,
pin_memory=True
)
# 模型加载以及优化策略的相关配置
best_perf = 0.0
best_model = False
# 循环迭代进行训练
for epoch in range(config.TRAIN.BEGIN_EPOCH, config.TRAIN.END_EPOCH):
lr_scheduler.step()
# train for one epoch
train(config, train_loader, model, criterion, optimizer, epoch,
final_output_dir, tb_log_dir, writer_dict)
# evaluate on validation set
perf_indicator = validate(config, valid_loader, valid_dataset, model,
criterion, final_output_dir, tb_log_dir,
writer_dict)
if perf_indicator > best_perf:
best_perf = perf_indicator
best_model = True
else:
best_model = False
logger.info('=> saving checkpoint to {}'.format(final_output_dir))
save_checkpoint({
'epoch': epoch + 1,
'model': get_model_name(config),
'state_dict': model.state_dict(),
'perf': perf_indicator,
'optimizer': optimizer.state_dict(),
}, best_model, final_output_dir)
final_model_state_file = os.path.join(final_output_dir,
'final_state.pth.tar')
logger.info('saving final model state to {}'.format(
final_model_state_file))
torch.save(model.module.state_dict(), final_model_state_file)
writer_dict['writer'].close()
if __name__ == '__main__':
main()
数据读取,预处理
总的来说就是读取coco数据的标签信息,然后转换为热图
在pose_estimation/train.py部分中可以看见创建数据迭代器的代码片段
# 创建训练以及测试数据的迭代器
train_dataset = eval('dataset.'+config.DATASET.DATASET)(
config,
config.DATASET.ROOT,
config.DATASET.TRAIN_SET,
True,
transforms.Compose([
transforms.ToTensor(),
normalize,
])
)
valid_dataset = eval('dataset.'+config.DATASET.DATASET)(
config,
config.DATASET.ROOT,
config.DATASET.TEST_SET,
False,
transforms.Compose([
transforms.ToTensor(),
normalize,
])
)
其具体实现过程,先查看lib/dataset/coco.py文件,其中COCODataset初始化的相关函数注释如下
coco.py
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft
# Licensed under the MIT License.
# Written by Bin Xiao ([email protected])
# ------------------------------------------------------------------------------
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import logging
import os
import pickle
from collections import defaultdict
from collections import OrderedDict
import json_tricks as json
import numpy as np
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
from dataset.JointsDataset import JointsDataset
from nms.nms import oks_nms
logger = logging.getLogger(__name__)
class COCODataset(JointsDataset):
'''
"keypoints": {
0: "nose",
1: "left_eye",
2: "right_eye",
3: "left_ear",
4: "right_ear",
5: "left_shoulder",
6: "right_shoulder",
7: "left_elbow",
8: "right_elbow",
9: "left_wrist",
10: "right_wrist",
11: "left_hip",
12: "right_hip",
13: "left_knee",
14: "right_knee",
15: "left_ankle",
16: "right_ankle"
},
"skeleton": [
[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13], [6,7],[6,8],
[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],[2,4],[3,5],[4,6],[5,7]]
'''
def __init__(self, cfg, root, image_set, is_train, transform=None):
super().__init__(cfg, root, image_set, is_train, transform)
# nms 阈值,默认为1
self.nms_thre = cfg.TEST.NMS_THRE
# 默认设置为0
self.image_thre = cfg.TEST.IMAGE_THRE
# oks 阈值
self.oks_thre = cfg.TEST.OKS_THRE
# ==默认为0.2
self.in_vis_thre = cfg.TEST.IN_VIS_THRE
# box文件,该文件主要记录person的box
self.bbox_file = cfg.TEST.COCO_BBOX_FILE
# 是否使用ground truch
self.use_gt_bbox = cfg.TEST.USE_GT_BBOX
# 模型输入图象的宽和高
self.image_width = cfg.MODEL.IMAGE_SIZE[0]
self.image_height = cfg.MODEL.IMAGE_SIZE[1]
# 输入图象宽和高的比例
self.aspect_ratio = self.image_width * 1.0 / self.image_height
# 标准化参数
self.pixel_std = 200
# 根据annotion文件,加载数据集信息,该处只加载了person关键点的数据
self.coco = COCO(self._get_ann_file_keypoint())
# deal with class names,获得数据集中标注的类别,该处只有person一个类
cats = [cat['name']
for cat in self.coco.loadCats(self.coco.getCatIds())]
# 所有类别前面,加上一个背景类
self.classes = ['__background__'] + cats
logger.info('=> classes: {}'.format(self.classes))
# 计算包括背景所有类别的总数
self.num_classes = len(self.classes)
# 字典 类别名:类别编号
self._class_to_ind = dict(zip(self.classes, range(self.num_classes)))
# 字典 类别标签编号:coco数据类别编号
self._class_to_coco_ind = dict(zip(cats, self.coco.getCatIds()))
# 字典 coco数据类别编号:类别标签编号
self._coco_ind_to_class_ind = dict([(self._class_to_coco_ind[cls],
self._class_to_ind[cls])
for cls in self.classes[1:]])
# load image file names
# 获得包含person图象的标号
self.image_set_index = self._load_image_set_index()
# 计算总共多少图片
self.num_images = len(self.image_set_index)
logger.info('=> num_images: {}'.format(self.num_images))
# 需要检测关键点的数目
self.num_joints = 17
# 人体水平对称关键印射
self.flip_pairs = [[1, 2], [3, 4], [5, 6], [7, 8],
[9, 10], [11, 12], [13, 14], [15, 16]]
# 父母ids?
self.parent_ids = None
self.db = self._get_db()
if is_train and cfg.DATASET.SELECT_DATA:
self.db = self.select_data(self.db)
logger.info('=> load {} samples'.format(len(self.db)))
def _get_ann_file_keypoint(self):
""" self.root / annotations / person_keypoints_train2017.json """
prefix = 'person_keypoints' \
if 'test' not in self.image_set else 'image_info'
return os.path.join(self.root, 'annotations',
prefix + '_' + self.image_set + '.json')
def _load_image_set_index(self):
""" image id: int """
image_ids = self.coco.getImgIds()
return image_ids
def _get_db(self):
# 如果是进行训练或者设置self.use_gt_bbo==Ture
if self.is_train or self.use_gt_bbox:
# use ground truth bbox
gt_db = self._load_coco_keypoint_annotations()
# 使用目标检测模型
else:
# use bbox from detection
# 使用来自检测结果的box
gt_db = self._load_coco_person_detection_results()
return gt_db
# 加载coco所有数据关键点信息
def _load_coco_keypoint_annotations(self):
""" ground truth bbox and keypoints """
gt_db = []
for index in self.image_set_index:
gt_db.extend(self._load_coco_keypoint_annotation_kernal(index))
return gt_db
def _load_coco_keypoint_annotation_kernal(self, index):
"""
根据index,加载单个person关键点数据信息
coco ann: [u'segmentation', u'area', u'iscrowd', u'image_id', u'bbox', u'category_id', u'id']
iscrowd:
crowd instances are handled by marking their overlaps with all categories to -1
and later excluded in training
bbox:
[x1, y1, w, h]
:param index: coco image id
:return: db entry
"""
# 获得包含person图片信息
im_ann = self.coco.loadImgs(index)[0]
# 获得图片的大小
width = im_ann['width']
height = im_ann['height']
# 获得包含person图片的注释id
annIds = self.coco.getAnnIds(imgIds=index, iscrowd=False)
# 根据注释id,获得对应的注释信息
objs = self.coco.loadAnns(annIds)
# sanitize bboxes
# 对box进行简单的清理,清除一些不符合逻辑的box
valid_objs = []
for obj in objs:
x, y, w, h = obj['bbox']
x1 = np.max((0, x))
y1 = np.max((0, y))
x2 = np.min((width - 1, x1 + np.max((0, w - 1))))
y2 = np.min((height - 1, y1 + np.max((0, h - 1))))
if obj['area'] > 0 and x2 >= x1 and y2 >= y1:
# obj['clean_bbox'] = [x1, y1, x2, y2]
obj['clean_bbox'] = [x1, y1, x2-x1, y2-y1]
valid_objs.append(obj)
objs = valid_objs
rec = []
for obj in objs:
# 获得物体的类别id,person默认为1,如果不为1,则continue跳过该obj
cls = self._coco_ind_to_class_ind[obj['category_id']]
if cls != 1:
continue
# ignore objs without keypoints annotation
# 如果该obj没有包含keypoints的信息也直接跳过
if max(obj['keypoints']) == 0:
continue
# 获取人体的关节信息,使用3维表示
joints_3d = np.zeros((self.num_joints, 3), dtype=np.float)
joints_3d_vis = np.zeros((self.num_joints, 3), dtype=np.float)
for ipt in range(self.num_joints):
joints_3d[ipt, 0] = obj['keypoints'][ipt * 3 + 0]
joints_3d[ipt, 1] = obj['keypoints'][ipt * 3 + 1]
joints_3d[ipt, 2] = 0
t_vis = obj['keypoints'][ipt * 3 + 2]
if t_vis > 1:
t_vis = 1
joints_3d_vis[ipt, 0] = t_vis
joints_3d_vis[ipt, 1] = t_vis
joints_3d_vis[ipt, 2] = 0
# 获取box的中心点
center, scale = self._box2cs(obj['clean_bbox'][:4])
rec.append({
'image': self.image_path_from_index(index),
'center': center,
'scale': scale,
'joints_3d': joints_3d,
'joints_3d_vis': joints_3d_vis,
'filename': '',
'imgnum': 0,
})
return rec
def _box2cs(self, box):
x, y, w, h = box[:4]
return self._xywh2cs(x, y, w, h)
def _xywh2cs(self, x, y, w, h):
center = np.zeros((2), dtype=np.float32)
center[0] = x + w * 0.5
center[1] = y + h * 0.5
if w > self.aspect_ratio * h:
h = w * 1.0 / self.aspect_ratio
elif w < self.aspect_ratio * h:
w = h * self.aspect_ratio
scale = np.array(
[w * 1.0 / self.pixel_std, h * 1.0 / self.pixel_std],
dtype=np.float32)
if center[0] != -1:
scale = scale * 1.25
return center, scale
def image_path_from_index(self, index):
""" example: images / train2017 / 000000119993.jpg """
file_name = '%012d.jpg' % index
if '2014' in self.image_set:
file_name = 'COCO_%s_' % self.image_set + file_name
prefix = 'test2017' if 'test' in self.image_set else self.image_set
data_name = prefix + '.zip@' if self.data_format == 'zip' else prefix
image_path = os.path.join(
self.root, 'images', data_name, file_name)
return image_path
def _load_coco_person_detection_results(self):
all_boxes = None
with open(self.bbox_file, 'r') as f:
all_boxes = json.load(f)
if not all_boxes:
logger.error('=> Load %s fail!' % self.bbox_file)
return None
logger.info('=> Total boxes: {}'.format(len(all_boxes)))
kpt_db = []
num_boxes = 0
for n_img in range(0, len(all_boxes)):
det_res = all_boxes[n_img]
if det_res['category_id'] != 1:
continue
img_name = self.image_path_from_index(det_res['image_id'])
box = det_res['bbox']
score = det_res['score']
if score < self.image_thre:
continue
num_boxes = num_boxes + 1
center, scale = self._box2cs(box)
joints_3d = np.zeros((self.num_joints, 3), dtype=np.float)
joints_3d_vis = np.ones(
(self.num_joints, 3), dtype=np.float)
kpt_db.append({
'image': img_name,
'center': center,
'scale': scale,
'score': score,
'joints_3d': joints_3d,
'joints_3d_vis': joints_3d_vis,
})
logger.info('=> Total boxes after fliter low score@{}: {}'.format(
self.image_thre, num_boxes))
return kpt_db
# need double check this API and classes field
def evaluate(self, cfg, preds, output_dir, all_boxes, img_path,
*args, **kwargs):
res_folder = os.path.join(output_dir, 'results')
if not os.path.exists(res_folder):
os.makedirs(res_folder)
res_file = os.path.join(
res_folder, 'keypoints_%s_results.json' % self.image_set)
# person x (keypoints)
_kpts = []
for idx, kpt in enumerate(preds):
_kpts.append({
'keypoints': kpt,
'center': all_boxes[idx][0:2],
'scale': all_boxes[idx][2:4],
'area': all_boxes[idx][4],
'score': all_boxes[idx][5],
'image': int(img_path[idx][-16:-4])
})
# image x person x (keypoints)
kpts = defaultdict(list)
for kpt in _kpts:
kpts[kpt['image']].append(kpt)
# rescoring and oks nms
num_joints = self.num_joints
in_vis_thre = self.in_vis_thre
oks_thre = self.oks_thre
oks_nmsed_kpts = []
for img in kpts.keys():
img_kpts = kpts[img]
for n_p in img_kpts:
box_score = n_p['score']
kpt_score = 0
valid_num = 0
for n_jt in range(0, num_joints):
t_s = n_p['keypoints'][n_jt][2]
if t_s > in_vis_thre:
kpt_score = kpt_score + t_s
valid_num = valid_num + 1
if valid_num != 0:
kpt_score = kpt_score / valid_num
# rescoring
n_p['score'] = kpt_score * box_score
keep = oks_nms([img_kpts[i] for i in range(len(img_kpts))],
oks_thre)
if len(keep) == 0:
oks_nmsed_kpts.append(img_kpts)
else:
oks_nmsed_kpts.append([img_kpts[_keep] for _keep in keep])
self._write_coco_keypoint_results(
oks_nmsed_kpts, res_file)
if 'test' not in self.image_set:
info_str = self._do_python_keypoint_eval(
res_file, res_folder)
name_value = OrderedDict(info_str)
return name_value, name_value['AP']
else:
return {'Null': 0}, 0
def _write_coco_keypoint_results(self, keypoints, res_file):
data_pack = [{'cat_id': self._class_to_coco_ind[cls],
'cls_ind': cls_ind,
'cls': cls,
'ann_type': 'keypoints',
'keypoints': keypoints
}
for cls_ind, cls in enumerate(self.classes) if not cls == '__background__']
results = self._coco_keypoint_results_one_category_kernel(data_pack[0])
logger.info('=> Writing results json to %s' % res_file)
with open(res_file, 'w') as f:
json.dump(results, f, sort_keys=True, indent=4)
try:
json.load(open(res_file))
except Exception:
content = []
with open(res_file, 'r') as f:
for line in f:
content.append(line)
content[-1] = ']'
with open(res_file, 'w') as f:
for c in content:
f.write(c)
def _coco_keypoint_results_one_category_kernel(self, data_pack):
cat_id = data_pack['cat_id']
keypoints = data_pack['keypoints']
cat_results = []
for img_kpts in keypoints:
if len(img_kpts) == 0:
continue
_key_points = np.array([img_kpts[k]['keypoints']
for k in range(len(img_kpts))])
key_points = np.zeros(
(_key_points.shape[0], self.num_joints * 3), dtype=np.float)
for ipt in range(self.num_joints):
key_points[:, ipt * 3 + 0] = _key_points[:, ipt, 0]
key_points[:, ipt * 3 + 1] = _key_points[:, ipt, 1]
key_points[:, ipt * 3 + 2] = _key_points[:, ipt, 2] # keypoints score.
result = [{'image_id': img_kpts[k]['image'],
'category_id': cat_id,
'keypoints': list(key_points[k]),
'score': img_kpts[k]['score'],
'center': list(img_kpts[k]['center']),
'scale': list(img_kpts[k]['scale'])
} for k in range(len(img_kpts))]
cat_results.extend(result)
return cat_results
def _do_python_keypoint_eval(self, res_file, res_folder):
coco_dt = self.coco.loadRes(res_file)
coco_eval = COCOeval(self.coco, coco_dt, 'keypoints')
coco_eval.params.useSegm = None
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()
stats_names = ['AP', 'Ap .5', 'AP .75', 'AP (M)', 'AP (L)', 'AR', 'AR .5', 'AR .75', 'AR (M)', 'AR (L)']
info_str = []
for ind, name in enumerate(stats_names):
info_str.append((name, coco_eval.stats[ind]))
eval_file = os.path.join(
res_folder, 'keypoints_%s_results.pkl' % self.image_set)
with open(eval_file, 'wb') as f:
pickle.dump(coco_eval, f, pickle.HIGHEST_PROTOCOL)
logger.info('=> coco eval results saved to %s' % eval_file)
return info_str
通过COCODataset的初始化函数,我们主要是获得一个rec的数据,其中包含了,coco中所有人体,以及对应关键点的信息。同时附带图片路径,以及标准化缩放比例等信息。
但是到这里还没有结束,我们还要进一步处理,因为在计算 loss 的时候,我们需要的是heatmap。也就是接下来,我们需要根据rec中的信息,读取图片像素(用于训练),同时把标签信息(人体关键点位置)转化为heatmap,其实现的过程位于代码lib/dataset/JointsDataset.py
JointsDataset.py
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft
# Licensed under the MIT License.
# Written by Bin Xiao ([email protected])
# ------------------------------------------------------------------------------
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import copy
import logging
import random
import cv2
import numpy as np
import torch
from torch.utils.data import Dataset
from utils.transforms import get_affine_transform
from utils.transforms import affine_transform
from utils.transforms import fliplr_joints
logger = logging.getLogger(__name__)
class JointsDataset(Dataset):
def __init__(self, cfg, root, image_set, is_train, transform=None):
# 人体关节的数目
self.num_joints = 0
# 像素标准化参数
self.pixel_std = 200
# 水平翻转
self.flip_pairs = []
# 父母ID==
self.parent_ids = []
# 是否进行训练
self.is_train = is_train
# 训练数据的根目录
self.root = root
# 图片数据集名称,如train2017
self.image_set = image_set
# 输出目录
self.output_path = cfg.OUTPUT_DIR
# 数据格式如‘jpg’
self.data_format = cfg.DATASET.DATA_FORMAT
# 缩放因子
self.scale_factor = cfg.DATASET.SCALE_FACTOR
# 旋转角度
self.rotation_factor = cfg.DATASET.ROT_FACTOR
# 是否进行水平翻转
self.flip = cfg.DATASET.FLIP
# 图片大小
self.image_size = cfg.MODEL.IMAGE_SIZE
# 目标数据类型,默认为高斯分布
self.target_type = cfg.MODEL.EXTRA.TARGET_TYPE
#标签热图大小
self.heatmap_size = cfg.MODEL.EXTRA.HEATMAP_SIZE
# sigma参数,默认为2
self.sigma = cfg.MODEL.EXTRA.SIGMA
#数据增强,转换等
self.transform = transform
# 用于保存训练数据的信息,由子类提供
self.db = []
# 由子类实现
def _get_db(self):
raise NotImplementedError
# 由子类实现
def evaluate(self, cfg, preds, output_dir, *args, **kwargs):
raise NotImplementedError
def __len__(self,):
return len(self.db)
def __getitem__(self, idx):
# 根据 idx 从db获取样本信息
db_rec = copy.deepcopy(self.db[idx])
# 获取图像名
image_file = db_rec['image']
# filename与imgnum暂时没有使用
filename = db_rec['filename'] if 'filename' in db_rec else ''
imgnum = db_rec['imgnum'] if 'imgnum' in db_rec else ''
# 如果数据格式为zip则解压
if self.data_format == 'zip':
from utils import zipreader
data_numpy = zipreader.imread(
image_file, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
# 否则直接读取图像,获得像素值
else:
data_numpy = cv2.imread(
image_file, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
# 如果读取到的数据不为numpy格式则报错
if data_numpy is None:
logger.error('=> fail to read {}'.format(image_file))
raise ValueError('Fail to read {}'.format(image_file))
# 获取人体关键点坐标
joints = db_rec['joints_3d']
joints_vis = db_rec['joints_3d_vis']
# 获取训练样本转化之后的center以及scale,
c = db_rec['center']
s = db_rec['scale']
# 如果训练样本中没有设置score,则加载该属性,并且设置为1
score = db_rec['score'] if 'score' in db_rec else 1
r = 0
# 如果是进行训练
if self.is_train:
# 缩放因子scale_factor=0.35,以及旋转因子rotation_factor=0.35
sf = self.scale_factor
rf = self.rotation_factor
# s大小为[1-0.35=0.65,1+0.35=1.35]之间
s = s * np.clip(np.random.randn()*sf + 1, 1 - sf, 1 + sf)
# r大小为[-2*45=95,2*45=90]之间
r = np.clip(np.random.randn()*rf, -rf*2, rf*2) \
if random.random() <= 0.6 else 0
# 进行数据水平翻转
if self.flip and random.random() <= 0.5:
data_numpy = data_numpy[:, ::-1, :]
joints, joints_vis = fliplr_joints(
joints, joints_vis, data_numpy.shape[1], self.flip_pairs)
c[0] = data_numpy.shape[1] - c[0] - 1
# 进行反射变换,样本数据关键点发生角度旋转之后,每个像素也旋转到对应位置.
# 获得旋转矩阵
trans = get_affine_transform(c, s, r, self.image_size)
# 根据旋转矩阵进行反射变换
input = cv2.warpAffine(
data_numpy,
trans,
(int(self.image_size[0]), int(self.image_size[1])),
flags=cv2.INTER_LINEAR)
# 进行正则化,形状改变等
if self.transform:
input = self.transform(input)
# 对人体关键点也进行反射变换
for i in range(self.num_joints):
if joints_vis[i, 0] > 0.0:
joints[i, 0:2] = affine_transform(joints[i, 0:2], trans)
# 获得ground truch, 热图target[17,64,48], target_weight[17,1]
target, target_weight = self.generate_target(joints, joints_vis)
target = torch.from_numpy(target)
target_weight = torch.from_numpy(target_weight)
meta = {
'image': image_file,
'filename': filename,
'imgnum': imgnum,
'joints': joints,
'joints_vis': joints_vis,
'center': c,
'scale': s,
'rotation': r,
'score': score
}
return input, target, target_weight, meta
def select_data(self, db):
db_selected = []
for rec in db:
num_vis = 0
joints_x = 0.0
joints_y = 0.0
for joint, joint_vis in zip(
rec['joints_3d'], rec['joints_3d_vis']):
if joint_vis[0] <= 0:
continue
num_vis += 1
joints_x += joint[0]
joints_y += joint[1]
if num_vis == 0:
continue
joints_x, joints_y = joints_x / num_vis, joints_y / num_vis
area = rec['scale'][0] * rec['scale'][1] * (self.pixel_std**2)
joints_center = np.array([joints_x, joints_y])
bbox_center = np.array(rec['center'])
diff_norm2 = np.linalg.norm((joints_center-bbox_center), 2)
ks = np.exp(-1.0*(diff_norm2**2) / ((0.2)**2*2.0*area))
metric = (0.2 / 16) * num_vis + 0.45 - 0.2 / 16
if ks > metric:
db_selected.append(rec)
logger.info('=> num db: {}'.format(len(db)))
logger.info('=> num selected db: {}'.format(len(db_selected)))
return db_selected
def generate_target(self, joints, joints_vis):
'''
:param joints: [num_joints, 3]
:param joints_vis: [num_joints, 3]
:return: target, target_weight(1: visible, 0: invisible)
'''
# target_weight形状为[17,1]
target_weight = np.ones((self.num_joints, 1), dtype=np.float32)
target_weight[:, 0] = joints_vis[:, 0]
# 检测制作热图的方式是否为gaussian,如果不是则报错
assert self.target_type == 'gaussian', \
'Only support gaussian map now!'
# 如果使用高斯模糊的方法制作热图
if self.target_type == 'gaussian':
# 形状为[17, 64, 48]
target = np.zeros((self.num_joints,
self.heatmap_size[1],
self.heatmap_size[0]),
dtype=np.float32)
# self.sigma 默认为2, tmp_size=6
tmp_size = self.sigma * 3
# 为每个关键点生成热图target以及对应的热图权重target_weight
for joint_id in range(self.num_joints):
# 先计算出原图到输出热图的缩小倍数
feat_stride = self.image_size / self.heatmap_size
# 计算出输入原图的关键点,转换到热图的位置
mu_x = int(joints[joint_id][0] / feat_stride[0] + 0.5)
mu_y = int(joints[joint_id][1] / feat_stride[1] + 0.5)
# Check that any part of the gaussian is in-bounds
# 根据tmp_size参数,计算出关键点范围左上角和右下角坐标
ul = [int(mu_x - tmp_size), int(mu_y - tmp_size)]
br = [int(mu_x + tmp_size + 1), int(mu_y + tmp_size + 1)]
# 判断该关键点是否处于热图之外,如果处于热图之外,则把该热图对应的target_weight设置为0,然后continue
if ul[0] >= self.heatmap_size[0] or ul[1] >= self.heatmap_size[1] \
or br[0] < 0 or br[1] < 0:
# If not, just return the image as is
target_weight[joint_id] = 0
continue
# # Generate gaussian
# 产生高斯分布的大小
size = 2 * tmp_size + 1
x = np.arange(0, size, 1, np.float32)
y = x[:, np.newaxis]
x0 = y0 = size // 2
# The gaussian is not normalized, we want the center value to equal 1
# g形状[13,13], 该数组中间的[7,7]=1,离开该中心点越远数值越小
g = np.exp(- ((x - x0) ** 2 + (y - y0) ** 2) / (2 * self.sigma ** 2))
# Usable gaussian range
# 判断边界,获得有效高斯分布的范围
g_x = max(0, -ul[0]), min(br[0], self.heatmap_size[0]) - ul[0]
g_y = max(0, -ul[1]), min(br[1], self.heatmap_size[1]) - ul[1]
# Image range
# 判断边界,获得有有效的图片像素边界
img_x = max(0, ul[0]), min(br[0], self.heatmap_size[0])
img_y = max(0, ul[1]), min(br[1], self.heatmap_size[1])
# 如果该关键点对应的target_weight>0.5(即表示该关键点可见),则把关键点附近的特征点赋值成gaussian
v = target_weight[joint_id]
if v > 0.5:
target[joint_id][img_y[0]:img_y[1], img_x[0]:img_x[1]] = \
g[g_y[0]:g_y[1], g_x[0]:g_x[1]]
return target, target_weight
构建模型
在lib/models/pose_renest.py中,在10月23日的周报中有过具体分析,就不把代码粘贴上来了。
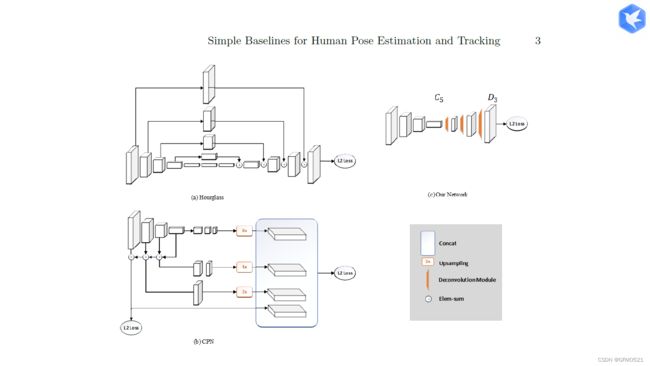
验证
完整的模型验证套路:利用已经训练好的模型,然后给他提供输入,应用到实际环境过程中
验证集有2个主要的作用:
(1)评估模型效果,为了调整超参数而服务
(2)调整超参数,使得模型在验证集上的效果最好
# ------------------------------------------------------------------------------
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
# Written by Bin Xiao ([email protected])
# ------------------------------------------------------------------------------
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os
import pprint
import torch
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import _init_paths
from lib.core.config import config
from lib.core.config import update_config
from lib.core.config import update_dir
from lib.core.loss import JointsMSELoss
from lib.core.function import validate
from lib.utils.utils import create_logger
from lib import dataset
import lib.models
def parse_args():
parser = argparse.ArgumentParser(description='Train keypoints network')
# general
#配置文件
parser.add_argument('--cfg',
help='experiment configure file name',
required=True,
type=str)
args, rest = parser.parse_known_args()
# update config
update_config(args.cfg)
# training
parser.add_argument('--frequent',
help='frequency of logging',
default=config.PRINT_FREQ,
type=int)
parser.add_argument('--gpus',
help='gpus',
type=str)
parser.add_argument('--workers',
help='num of dataloader workers',
type=int)
parser.add_argument('--model-file',
help='model state file',
type=str)
parser.add_argument('--use-detect-bbox',
help='use detect bbox',
action='store_true')
# 使用翻转测试
parser.add_argument('--flip-test',
help='use flip test',
action='store_true')
parser.add_argument('--post-process',
help='use post process',
action='store_true')
parser.add_argument('--shift-heatmap',
help='shift heatmap',
action='store_true')
parser.add_argument('--coco-bbox-file',
help='coco detection bbox file',
type=str)
args = parser.parse_args()
return args
def reset_config(config, args):
if args.gpus:
config.GPUS = args.gpus
if args.workers:
config.WORKERS = args.workers
if args.use_detect_bbox:
config.TEST.USE_GT_BBOX = not args.use_detect_bbox
if args.flip_test:
config.TEST.FLIP_TEST = args.flip_test
if args.post_process:
config.TEST.POST_PROCESS = args.post_process
if args.shift_heatmap:
config.TEST.SHIFT_HEATMAP = args.shift_heatmap
if args.model_file:
config.TEST.MODEL_FILE = args.model_file
if args.coco_bbox_file:
config.TEST.COCO_BBOX_FILE = args.coco_bbox_file
def main():
args = parse_args()
reset_config(config, args)
logger, final_output_dir, tb_log_dir = create_logger(
config, args.cfg, 'valid')
logger.info(pprint.pformat(args))
logger.info(pprint.pformat(config))
# cudnn related setting cudnn相关设置
cudnn.benchmark = config.CUDNN.BENCHMARK
torch.backends.cudnn.deterministic = config.CUDNN.DETERMINISTIC
torch.backends.cudnn.enabled = config.CUDNN.ENABLED
model = eval('models.'+config.MODEL.NAME+'.get_pose_net')(
config, is_train=False
)
if config.TEST.MODEL_FILE:
logger.info('=> loading model from {}'.format(config.TEST.MODEL_FILE))
model.load_state_dict(torch.load(config.TEST.MODEL_FILE))
else:
model_state_file = os.path.join(final_output_dir,
'final_state.pth.tar')
logger.info('=> loading model from {}'.format(model_state_file))
model.load_state_dict(torch.load(model_state_file))
gpus = [int(i) for i in config.GPUS.split(',')]
model = torch.nn.DataParallel(model, device_ids=gpus).cuda()
# define loss function (criterion) and optimizer
# 用MSE L2loss函数
criterion = JointsMSELoss(
use_target_weight=config.LOSS.USE_TARGET_WEIGHT
).cuda()
# Data loading code
# 对输入图象数据进行正则化处理
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# 创建测试数据迭代器
valid_dataset = eval('dataset.'+config.DATASET.DATASET)(
config,
config.DATASET.ROOT,
config.DATASET.TEST_SET,
False,
transforms.Compose([
transforms.ToTensor(),
normalize,
])
)
valid_loader = torch.utils.data.DataLoader(
valid_dataset,
batch_size=config.TEST.BATCH_SIZE*len(gpus),
shuffle=False,
num_workers=config.WORKERS,
pin_memory=True
)
# evaluate on validation set 对验证集进行评估
validate(config, valid_loader, valid_dataset, model, criterion,
final_output_dir, tb_log_dir)
if __name__ == '__main__':
main()
补充知识
数据增强
增加一个已有数据集,使得有更多的多样性
- 在语言里面加入各种不同的背景噪音
- 改变图片的颜色的形状

对色温,亮度,图片大小形状都进行变换
使用增加数据训练
读原始图片,随机做增强再进入模型进行训练,最后得到

常见增强
- 翻转 (左右翻转,上下翻转(不总是可行)
- 切割—从图片中切割一块,然后变形到固定形状(随机高宽比,随机大小,随机位置,最后一定是固定形状)
- 颜色(改变色调,饱和度,明亮度)

parser.add_argument()用法——命令行选项、参数和子命令解析器
介绍
argparse 模块是 Python 内置的一个用于命令项选项与参数解析的模块,argparse 模块可以让人轻松编写用户友好的命令行接口。通过在程序中定义好我们需要的参数,然后 argparse 将会从 sys.argv 解析出这些参数。argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息
每个参数解释
name or flags - 选项字符串的名字或者列表,例如 foo 或者 -f, --foo。
action - 命令行遇到参数时的动作,默认值是 store。
store_const,表示赋值为const;
append,将遇到的值存储成列表,也就是如果参数重复则会保存多个值;
append_const,将参数规范中定义的一个值保存到一个列表;
count,存储遇到的次数;此外,也可以继承 argparse.Action 自定义参数解析;
nargs - 应该读取的命令行参数个数,可以是具体的数字,或者是?号,当不指定值时对于 Positional argument 使用 default,对于 Optional argument 使用 const;或者是 * 号,表示 0 或多个参数;或者是 + 号表示 1 或多个参数。
const - action 和 nargs 所需要的常量值。
default - 不指定参数时的默认值。
type - 命令行参数应该被转换成的类型。
choices - 参数可允许的值的一个容器。
required - 可选参数是否可以省略 (仅针对可选参数)。
help - 参数的帮助信息,当指定为 argparse.SUPPRESS 时表示不显示该参数的帮助信息.
metavar - 在 usage 说明中的参数名称,对于必选参数默认就是参数名称,对于可选参数默认是全大写的参数名称.
dest - 解析后的参数名称,默认情况下,对于可选参数选取最长的名称,中划线转换为下划线.
总结
这周对于数据预处理,训练和验证的流程代码进行了分析。才开始看这部分代码的时候,觉得好多,每个都看不懂,后面发现其中有很多都是固定同样的,不需要自己能够完整全部写出来,但需要在看代码的时候了解该部分是完成什么任务,可以根据自己的模型来选取合适的参数。第一次复现simple baseline模型代码的时候,我看不明白配置文件中的参数,觉得用起来好麻烦啊,所以我的参数都是在代码里直接定义的。现在觉得将所需参数放在yaml文件里,可以清晰明了的知道自己的需要以及更改。之后的模型复现也尽可能的用这种方式,变得规范起来。