day21笔记(知行教育结构说明+数据仓库概念+维度、指标概念)
1、项目背景
1、近年来,在线教育产业发展十分迅速。尤其是2018年以来,在线教育平台动作不断,除了洋葱数学、考虫、作业盒子、火花思维、VIPKID、阿卡索等平台纷纷融资外,诸多在线教育平台纷纷上市。新东方在线也在2019年3月成功上市。
在市场规模方面,在线教育很大程度上是随着移动互联网的浪潮发展起来的,在传统的PC时代,虽然出现了网络教育形式,但是真正的所谓在线教育仍然是在2011年左右开始爆发的,这也正是移动互联网发展和普及的时间点。
统计数据显示,2011-2017年中国在线教育市场规模呈逐年增长趋势。2011年中国在线教育市场规模已达574.9亿元,2014年中国在线教育市场规模突破了千亿元,截止至2017年中国在线教育市场规模增长至突破2000亿元,达到了2089.1亿元,同比增长28.1%。2018年我国在线教育市场规模达到2670.6亿元左右。中国在线教育市场规模同比增长稳健。
2、公司角度:
- 数据量大
- 数据比较分散
- 分析难度大
2、教育项目业务说明
2.1、项目流程

如图:
项目的流程大致为:客户访问网站,进行网络咨询,客户产生学习意向,客户留下联系方式,服务人员和客户进行沟通,客户确认学习后报名,客户进行网络学习。
整个流程中产生的数据分为以下几块:
1、客户访问网站和进行网络咨询时产生访问咨询的数据;
2、客户表达学习意向后产生意向数据;
3、客户留下联系方式后,产生客户线索数据;
4、客户报名学习后,产生客户报名相关数据;
5、客户学习过程中,产生客户的学习情况、考勤等数据。
总结,总计五大模板:
1) 访问咨询主题看板
2) 意向用户主题看板
3) 有效线索主题看板
4) 报名用户主题看板
5) 学生出勤主题看板
3、项目架构说明
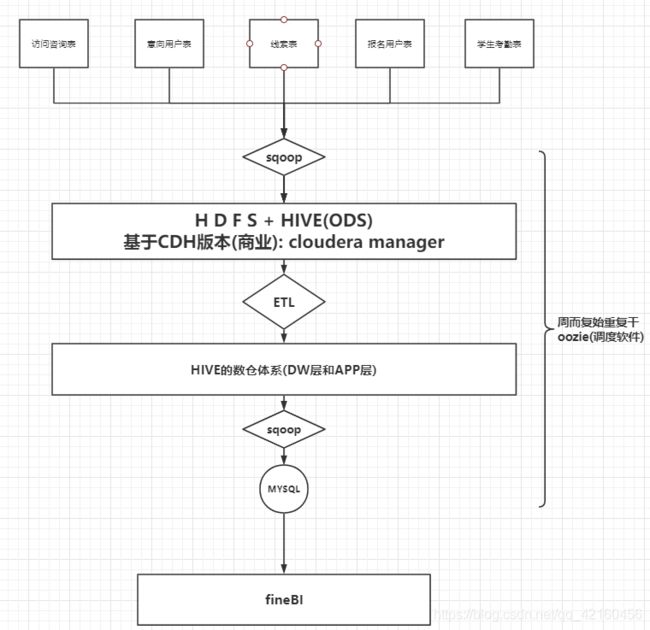
如图:总结整个项目的架构: cloudera manager + hadoop + hive + hue + sqoop + oozie
1) 整个项目是基于cloudera Manger构建的大数据离线分析平台
2) 在此平台上会搭建HADOOP , HIVE OOZIE SQOOP ZOOKEEPER...
3) HADOOP 主要负责数据的存储和分析计算
4) hive 主要负责SQL的书写, 用于转换为MR进行数据分析
5) oozie 主要负责最终的任务调取工作
6) HUE 是hadoop的用户管理界面, 主要通过此工具进行对大数据各个软件进行更加友好操作
7) sqoop主要是负责数据的导入和导出操作
4、Clodera背景说明
4.1 apache版本的hadoop
优点:
完全开源,更新速度很快
大数据组件在部署过程中可以深刻了解其底层原理
可以了解各个组件的依赖关系
弊端:
部署过程极其复杂,超过20个节点的时候,手动部署已经超级累
各个组件部署完成后,各个为政,没有统一化管理界面
组件和组件之间的依赖关系很复杂,一环扣一环,部署过程心累
各个组件之间没有统一的metric可视化界面,比如说hdfs总共占用的磁盘空间、IO、运行状况等
优化等需要用户自己根据业务场景进行调整(需要手工的对每个节点添加更改配置,效率极低,我们希望的是一个配置能够自动的分发到所有的节点上)
4.2、clodera manager版本
优点:
统一化的可视化界面 自动部署和配置,大数据各类组件(hadoop、hive、hue、kudu、impala、zookeeper等)安装、调优极其便捷 零停机维护(免费版本不具有弹性升级)
多用户管理(权限控制)
稳定性极好(部分优化措施都已经调整好)
弊端:
内存消耗较高
4.3、clodera manager版本介绍
cloudera manger管理平台是否cloudera公司推出的一款集中化管理可视化监控平台, 此平台主要是用于对cloudera推出CDH版本大数据软件进行统一化监控管理工作;
提供了诸如安装自动化, 提供统一的管理平台, 进行针对化配置修改, 细粒度化监听....
CM的应用场景:
- 大数据集群的节点大于5个以上
- 专业大数据公司
- 运维工作较为频繁场景
5、数据仓库介绍
基本概念:
1、数仓本质上是存储数据的仓库,但它本身不生产数据,也不消耗数据,它的数据来源于各个数据源
2、数仓是面向主题的,主要用于数据分析,对过去已经产生的数据进行分析处理,从而对未来提供决策支持
数仓的特征:
1、面向主题:数仓都是面向分析主题进行构建的
2、多样性:数仓中的数据来源于各个平台和系统
3、非易失性:数仓的数据不会进行修改,但会进行增加
4、新增性:数仓数据会随着时间推移进行新增
6、分析维度说明
维度:即事物的特征,分析问题的时候,会站在不同的角度进行分析,这些不同的角度就是事务的维度。
维度分类:定性维度、定量维度
1、定性维度:数据中已经能够确定的值,常用于group by字句后的条件
2、定量维度:会进行范围伸缩的值,如时间范围、年龄范围等等,常用于where后的条件对数据进行筛选
维度的分层和分级:
当一个维度确定以后,依然可以再对维度进行细化分层
如时间维度,年可以细化为季度、月、日
地区维度:市可以细化为县、镇
维度的上卷和下钻:
以时间维度为例,确定基础分析维度为日
如果需要将每月的数据分析出来,可以理解为上卷到月
如果需要将每小时的数据分析出来,可以理解为下钻到小时
指标:衡量事务发展的标准,也叫度量,在根据维度分析以后,计算哪些度量值
常见的度量值:count sum max min avg topn...
指标分类:
绝对数值:count sum max min avg topn
相对数值:计算比率
7、数仓建模
建模:指如何来构建表结构,一般在构建表的时候,都会有一定的规则来规范建模方式
常见的建模方式:
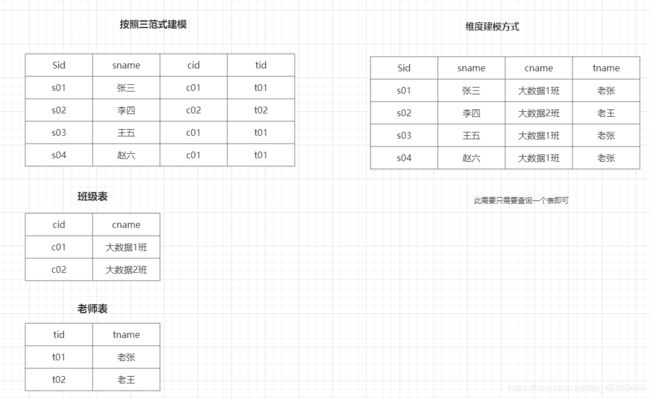
1、三范式建模
适用于OLTP类型数据库,或者业务库
三范式建模规范中,要求每一个表中要有一个主键,避免出现数据冗余
2、维度建模
适用于分析型数据库,表中可以没有主键,也可以出现数据冗余,只要利于数据分析即可
常见的三范式建模和维度建模对比图:
8、维度建模
8.1、维度建模_事实表
事实表是针对分析主题的,分析主题是需要使用的分析表就是事实表
事实表的分类:
事务事实表:
- 事务事实表记录的事务层面的事实,保存的是最原子的数据,也称“原子事实表”或“交易事实表”
- 沟通中常说的事实表,大多指的是事务事实表。
周期快照事实表:
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,时间间隔如每天、每月、每年
累积快照事实表:
累积快照事实表代表的是完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点
8.2、维度建模_维度表
维度表:分析需求的过程中,事实表需要结合其他的表来进行分析,这些表就是维度表
维度表的分类:
- 高基数维度数据 : 维度表中数据量一般比较庞大, 例如商品表, 用户表
- 低基数维度数据: 维度表中数据量一般比较小, 地区表, 日期表
8.3、维度建模数据模型
- 1) 星型模型:
- 特点: 只有一个事实表, 也就是说只有一个分析的主题, 在事实表周围围绕了多个维度表, 维度表与维度表没有任何的关联
- 请问, 星型模型是数仓发展在什么期在最容易产生模型: 初期阶段
- 2) 雪花模型:
- 特点: 只有一个事实表, 也就是说只有一个分析的主题, 在事实表周围围绕了多个维度表, 维度表可以接着关联维度表
- 请问, 雪花模型是数仓发展在什么期在最容易产生模型: 出现畸形的时候
- 这种模型会导致维护维度提升, 并且分析的SQL难度也提升, 好处 划分更加明确了
- 3) 星座模型:
- 特点: 有多个事实表, 也就说有多个分析的主题, 在事实表周围围绕了多个维度表, 在条件合适情况下, 多个事实表之间可以共享维度表
- 请问, 星座模型是数仓发展在什么期在最容易产生模型? 一般是在 中 后 期最容易产生模型

9、渐变维
用于处理历史变化数据,是否需要存储变化的历史变更数据
解决方案:
SCD1: 直接覆盖, 不保存历史变更数据, 仅适合于错误数据的处理
SCD2: 采用拉链表方案, 建表时需要多出两个字段(起始时间和结束时间)
- 在发生变更数据后, 对之前数据进行过期处理, 然后新增最新变更后的数据即可
- 好处:
- 维护简单, 利于分析
- 弊端:
- 会有冗余数据的出现
- 适用于需要保存多个历史版本的场景
SCD3:
- 当发生数据变更后,在表中新增一个字段, 用于记录最新变更数据即可
- 好处:
- 尽可能避免冗余
- 弊端:
- 维护复杂, 不利于维护多个历史版本
- 效率降低
- 适用于保存少量历史版本, 而且磁盘空间不足的情况下