【姿态估计】Joint Training of CNN and a Graphical Model for Human Pose Estimation用于姿态估计的CNN和图模型的联合训练
用于人体姿态估计的CNN和图模型的联合训练
摘要
本文提出了一种新的混合架构,包括深度卷积网络和马尔可夫随机场。 作者展示了该架构如何成功应用于单目图像中人体关节姿态估计的挑战性问题。 该体系结构可以开发结构域的约束,例如身体关节位置之间的几何关系。 作者证明这两种模型范式的联合训练提高了性能,明显优于当时已有的最先进技术。
1 引言
尽管先前工作的历史很长,但人体姿态估计,或者特别是单目RGB图像中人体关节的定位,仍然是计算机视觉中非常具有挑战性的任务。复杂的关节相互依赖性、部件或完整的关节遮挡、身体形变、衣服或照明的变化以及不受限制的视角导致这个任务有非常高的尺度的输入空间,使得简单的搜索方法难以处理。
最近解决这个问题的方法分为两大类:(1)传统的可变形关节模型 [27] (2)基于深度学习的判别模型 [15, 30]。
自下而上的基于部件的模型是这个问题的常见选择,因为人体自然地分成铰接部件。 传统上,这些方法依赖于手工制作的低级特征的集合(如SIFT [18] 或者HoG [7]),然后将其输入标准分类器或更高级别的生成模型。 需要保证的是这些特征对它们试图检测的部件敏感,并且对输入空间中的大量变形(例如光照变化)不变。 另一方面,有辨别力的深度学习方法学习一组经验的低级和高级特征,这些特征通常对训练集的变化更鲁棒,并且最近的表现优于基于部件的模型 [27]。但将关于人体结构的先验(例如作者关于关节互连的先验知识)纳入这样的网络是困难的,因为这些网络的低级机制通常难以解释。
在这项工作中,作者尝试将卷积网络(ConvNet)部件检测器(单独优于所有其他当时已有方法)与基于部件的空间模型结合到一个统一的学习框架中。 作者的变换利用具有重叠感受域的多分辨率特征表示,不改变ConvNet架构。 此外,作者的空间模型能够近似MRF循环信任传播,随后通过反向传播,并使用与部件检测器相同的学习框架进行学习。 作者表明,这两种模型的组合和联合训练提高了性能,使作者能够在人体姿态识别任务上明显优于当时已有的最先进模型。
2 相关工作
在无约束图像域上已经有了许多体系结构,包括来自人体的“形状上下文”基于边缘的直方图 [20] 或只是轮廓特征 [13],有许多技术来提取、学习或推理整个身体特征。有些人使用局部检测器和结构推理的组合 [25] 用于粗跟踪和 [5] 用于依赖于人的跟踪。本着类似的想法,有一些使用“图形结构”的更一般技术,例如Felzenszwalb等人的着作。[10] 通过所谓的“可变形关节模型(DPM)”使这种方法易于处理。随后开发了大量相关模型 [1, 9, 31, 8] 模拟更复杂的关节关系的算法,例如Yang和Ramanan [31]使用由线性SVM建模的灵活的混合模板。Johnson和Everingham [16] 采用级联的身体部位检测器来获得更多的辨别模板。最近的方法旨在模拟高阶关节关系。Pishchulin [23, 24] 提出了一个用Poselet先验增强DPM的模型[3]。Sapp和Taskar [27] 提出了一种多模态模型,其包括用于模式选择和姿态估计的整体和局部线索。Gkioxari等人的Armlets方法是Poselet方法的延伸 [12] ,它采用半全局分类器进行关节配置并在真实数据上显示出良好的性能,但它仅在手臂上进行测试。 此外,所有这些方法都受到以下事实的影响:它们使用手工制作的特征,例如HoG特征,边缘,轮廓和颜色直方图。
现在基于深度卷积网络是针对许多视觉任务的最佳表现算法,特别是人体姿态估计([30, 15, 29]) 。Toshev等 [30] 在 ‘FLIC’ [27] 和’LSP’ [17] 数据集上展示了最新表现。 然而,他们的方法在高精度区域中存在不准确性,作者将其归因于来自图像的姿态向量的低效直接回归,这是高度非线性且难以学习的映射。
Ning等人先前已经提出了神经网络和图模型的联合训练[22]用于图像分割,以及由语音和语言建模中的各种应用 [4, 21]。但当时没有这样的模型成功地用于检测和定位图像中人体部位的问题。最近,Rose等 [26] 使用消息传递启发程序对计算机视觉任务进行结构化预测,例如3D点云分类和单个图像的3D表面估计。与这项工作相反的是,作者以更适合反向传播的方式制定作者的消息解析灵感网络,因此可以在当时已有的神经网络中实现。Heitz等 [14] 训练一系列现成的分类器,以同时执行物体检测、区域标记和几何推理。然而,由于级联的前向性质,后来的分类器不能鼓励早期的分类器将其精力集中在修复某些错误模式上,或者允许较早的分类器忽略可以通过级联中的分类器撤消的错误。 Bergtholdt等 [2] 提出了一种使用基于部件的模型进行对象类检测的方法,在这种模型中,它们能够创建完全连接的模型,并使用A∗搜索在关节上绘制图形、执行MAP推理,但依靠SIFT和颜色特征来创建单个和成对的置信度。
3 模型
3.1 卷积网络部件检测器

图1 具有重叠感受野的多分辨率滑动窗口
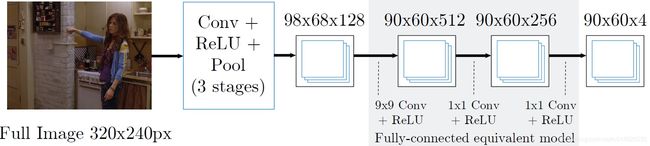
图2 具有单个感受野的高效滑动窗口模型
作者检测流程的第一阶段是用于身体部位定位的深度ConvNet架构。 输入是包含一个或多个人的RGB图像,输出是热图,它产生人类骨骼上的关键关节位置的每像素可能性。
滑动窗口ConvNet架构如图1所示。网络在输入图像上滑动,以产生每个身体关节的密集热图输出。作者的模型结合了具有重叠感受野的多分辨率输入。图1中上面的卷积会得到一个标准的64x64分辨率输入窗口,而下一个卷积层能够得到一个较大的128x128输入上下文,下采样到64x64。 输入图像被局部对比度归一化(LCN [6]) (在较低分辨率的内存中使用抗锯齿进行下采样后)以产生近似的拉普拉斯金字塔。 使用重叠上下文的优点在于它允许网络只看到权重数量的适度增加而看到输入图像的更大部件。 拉普拉斯金字塔的作用是提供不重叠的频谱内容,从而最大限度地减少网络冗余。
滑动窗模型的一个优点(图 1) 是检测器是平移不变的。 然而,主要缺点是由于冗余卷积而导致评估昂贵。 最近的工作 [11, 28] 已经通过在完整输入图像上执行卷积来有效地创建密集特征映射来解决该问题。 然后通过卷积阶段处理这些密集特征图,以在每个像素处复制完全连接的网络。 用于单个分辨率组的滑动窗口模型的等效但有效的版本如图2所示。由于卷积层里的pooling,输出热图的分辨率将低于输入图像。

图3 具有重叠感受域的高效滑动窗口模型
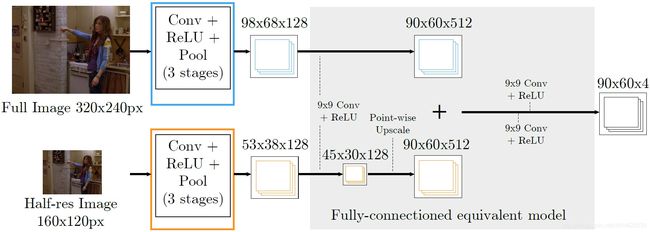
图4 图3的近似。
.对于作者的Part-Detector,作者将基于滑动窗口的高效架构与多分辨率和重叠感受域相结合,后续模型如图3所示。由于大上下文(低分辨率)卷积需要较低分辨率图像中的1/2像素的步幅以产生与滑动窗口模型相同的密集输出,因此它必须处理四个下采样图像,每个图像具有1/2像素偏移,使用共享权重的卷积。这四个输出以及高分辨率卷积特征通过9x9卷积(具有512个输出特征)使用与第一个完全连接阶段相同的权重进行处理(图 1 ) ,然后添加低分辨率存储体的输出并与高分辨率存储体的输出交叉存储。
为了缩短训练时间,作者通过用单个卷积替换较低分辨率的阶段来简化上述架构,如图4所示,然后上采样生成的特征图。在作者的实际实施中,作者使用3个resolution banks,由于较低分辨率的卷积特征被有效地抽取并复制到了完全连接的阶段,简化的体系结构不再等同于图1的原始滑动窗口网络。然而作者从经验上发现,这样的性能损失是最小的。
作者使用带有Nesterov Momentum的随机随机梯度下降(SGD)执行网络的监督训练。 作者使用均方误差(MSE)标准来最小化预测输出和目标热图之间的距离。目标是具有小方差的2D高斯分布,且平均值以ground truth关节位置为中心。 在训练时,作者还对输入图像执行随机扰动(随机翻转和缩放图像)以提高泛化性能。
3.2 更高级别的空间模型

图5 消息在面部和肩关节之间传递的样例

图6 单轮消息传递网络
第3.1章的部件检测器在验证集上的性能预测包含许多假阳性的热图,和解剖学上不正确的姿态。例如,面部检测的峰值异常远离相应肩部检测中的峰值。因此,尽管部件检测器的上下文得到了改进,但前馈网络仍然难以学习身体各部位的身体部位约束的隐式模型。作者使用更高级别的空间模型来约束关节互连,并强制实现全局姿态一致性。 这个阶段的期望是不增加已经接近真实姿态的检测的性能,而是去除在解剖学上不正确的假阳性异常值。
与Jain等人类似[15],作者将空间模型制定为类似MRF的模型用于每个身体部位的空间位置分布。然而,他们模型的最大缺点是身体部位先验和图结构是明显的手工制作的。另一方面,作者学习了先验模型,并隐含了空间模型的结构。与 [15] 的方法不同,作者首先在空间模型中以成对的方式将每个身体部位连接到自身和其他身体部位,以创建全连接图。 部件检测器为每个身体部位提供单元的可能性。图中的成对电位是使用卷积先验计算的,卷积先验模拟一个身体部位到另一个身体部位的条件分布。对于例如,假设身体部位 B B B 位于中心像素处,则卷积先验 P A ∣ B ( i , j ) P_{A | B}(i,j) PA∣B(i,j) 是身体部位A出现在像素位置 ( i , j ) (i,j) (i,j) 的可能性。对于身体部位 A A A ,作者将最终边际可能性 p ~ A \tilde p_A p~A 计算为:
(1) p ~ A = 1 Z Π v ∈ V ( p A ∣ v ∗ p v + b v → A ) \tilde p_A=\frac 1 Z\Pi_{v\in V}(p_{A|v}*p_v+b_{v→A})\tag 1 p~A=Z1Πv∈V(pA∣v∗pv+bv→A)(1)
其中 v v v 是联合位置, p A ∣ v p_{A|v} pA∣v 是上述条件先验, b v → a b_{v→a} bv→a 是一个偏差项,用于描述从关节 v v v 到 A A A 消息的概率, Z Z Z 是分区特征。 对公式1的评价类似于单轮sum-product置信传播。鉴于作者的空间模型不是树形结构,因此无法保证向全局最优的收敛。 但是正如作者的结果所示(图 8b),推断的解决方案对于作者数据集中的所有姿态都足够准确。当应该从图形结构中移除任何成对边缘时,学习的成对分布是均匀的。 图 5 显示了空间模型如何通过结合强大的肩部检测,从面部热图中移除解剖学上不正确的强异常值的实际样本。为简单起见,只显示了肩部和面部关节,然而,该示例可以扩展以包含所有身体部位。如果肩部热图(如图5所示)具有不正确的假阴性(即在正确的肩部位置没有检测),背景偏差 b v → A b_{v→A} bv→A 的添加将阻止输出热图在检测到的面部区域中没有最大值。
图 5 包含在FLIC数据集上学习的面部和肩部的条件分布 [27] 。对于任何 A A A 部件,分布 P A ∣ A P_{A|A} PA∣A 是identity map,因此从任何关节传递给自身的消息是其一元分布。 由于FLIC数据集偏向于正面姿态,其右肩直接位于面部的右下方,因此模型可以学习这些身体部位之间的正确空间分布,并且在描述肩膀和脸之间的空间位置具有高概率。 对于涵盖更大范围的可能姿态的数据集(例如LSP数据集) [17] ,作者希望这些分布受到较少的约束,因此这种简单的空间模型效率会降低。
对于作者的实际实现,作者将上面的分布视为能量来避免对 Z Z Z 的估计。有三个原因作者不包括分区函数:首先,作者只关注网络的最大输出值,因此作者只需要输出能量与正态分布成比例;其次,由于关节检测器和空间模型参数仅包含在像素位置上相等的共享权重(卷积)参数,因此在反向传播期间对分区函数的评估将仅向梯度权重添加标量常数,这将等效的应用每批学习速率修饰符;最后,由于部件的数量不是先验已知的(因为图像中可能存在未标记的人),并且由于分布 p v p_v pv 描述了单个人的部件位置,因此作者无法规范化部件模型输出。 作者的最终模型是对公式1的修改:
(2) e ˉ A = exp ( ∑ v ∈ V [ log ( S o f t P l u s ( e A ∣ v ) ∗ R e L U ( e v ) + S o f t P l u s ( b v → A ) ) ] ) \bar e_A=\exp(\sum_{v\in V}[\log(SoftPlus(e_{A|v})*ReLU(e_v)+SoftPlus(b_{v→A}))])\tag2 eˉA=exp(v∈V∑[log(SoftPlus(eA∣v)∗ReLU(ev)+SoftPlus(bv→A))])(2)
其中 S o f t P l u s ( x ) = 1 β log ( 1 + exp ( β x ) ) , 1 2 < β < 2 R e L U ( x ) = max ( x , ϵ ) , 0 < ϵ < 0.01. SoftPlus(x)=\frac 1\beta\log(1+\exp(\beta x)),\frac 1 2<\beta<2\\ReLU(x)=\max(x,\epsilon),0<\epsilon<0.01. SoftPlus(x)=β1log(1+exp(βx)),21<β<2ReLU(x)=max(x,ϵ),0<ϵ<0.01. 。
注意,上述公式不再完全等同于MRF,但公式1仍然令人满意地编码空间约束。基于网络的公式2实现如图6所示。公式2替换公式1的外部乘法,添加对数空间以提高数值稳定性,并防止卷积输出的梯度耦合(对数空间中的加法意味着损失函数相对于卷积输出的偏导数不依赖于任何其他阶段的输出) 。在权重、偏差和输入热图上加入SoftPlus和ReLU可以保持严格大于零的卷积输出,从而防止导致Log阶段的值出现数值问题。 最后,使用SoftPlus阶段在训练期间保持连续和非零的权值和偏差梯度。公式2使用反向传播和SGD训练。
卷积的大小被调整,以便在卷积窗口内覆盖最大的关节位移。考虑到64像素的联合位移半径,对于作者的90x60像素热图输出,会得到128x128的卷积内核(在热图输入上添加了填充以防止像素丢失)。 因此,对于如此大的内核,作者使用基于Mathieu等人的GPU实现的FFT卷积 [19] 。
卷积权重被使用从训练样本创建的关节位移的经验直方图来初始化。此初始化可提高学习性能,缩短训练时间并提高优化稳定性。在训练期间,作者随机翻转并缩放热图输入以提高泛化性能。
3.3 联合模型
自作者的空间模型(部件 3.2) 使用反向传播训练,作者将Part-Detector和Spatial-Model阶段结合在一个统一模型中,为此,作者首先单独训练关节检测器并存储热图输出,然后,作者使用这些热图来训练空间模型。最后,作者将经过训练的Part-Detector和Spatial-Models组合在一起,并在整个网络中进行反向传播。这种统一的微调进一步提高了性能。假设由于空间模型能够有效地减少可能的热图激活的输出维度,因此Part-Detector可以使用可用的学习能力来更好地定位精确的目标激活。
4 结果
作者在Torch7 [6] 框架实现了来自 3.1 和 3.2 章节的模型(具有上述非标准阶段的自定义GPU实现)。训练检测器大约需要48小时,空间模型需要12小时,而通过两个网络的单个图像的前向传播需要51毫秒。
作者在FLIC [27] 和扩展LSP [17] 数据集上评估了作者的架构。这些数据集由具有使用Amazon Mechanical Turk生成的2Dground truth信息的静止RGB图像组成。FLIC数据集由来自好莱坞电影的5003张图像组成,其中演员主要面向前方站立姿态(1016张图像用于测试),而扩展LSP数据集包含更多种类的运动员参加体育运动(10442幅训练图像,1000幅测试图像)。FLIC数据集包含多个具有多个人的帧,而场景中仅有一个人的关键点位置被标记。因此,为场景中的单个标记人提供近似躯干边界框。作者通过在空间模型的输入中包含额外的“躯干关节热图”来合并这些数据,以便它可以学习在杂乱的场景中选择正确的特征激活。
FLIC-full数据集包含20928个训练图像,但是这些训练集图像中的许多包含来自1016个测试集场景的样本,因此将允许FLIC测试集上的过度训练。作者提出了一个新的数据集,称为FLIC-plus(http://cims.nyu.edu/tompson/flic plus.htm) 。这是来自FLIC-plus数据集的17380图像子集。为了创建这个数据集,作者使用Amazon Mechanical Turk为FLIC测试集和FLIC-plus训练集生成了独特的场景标签。然后,作者从FLIC-plus训练集中删除了与测试集共享场景的所有图像。由于来自原始3987 FLIC训练集的253个样本图像来自与测试集样本相同的场景(因此通过上述过程被移除),作者将这些图像添加回来,以便FLIC-plus训练集是最初的FLIC训练集超集。使用此程序,作者可以保证FLIC-plus中的其他样本与FLIC测试集样本足够独立。
为了评估测试集性能,作者使用Sapp等建议的度量 [27]。对于给定的归一化像素半径(通过每个样本的躯干高度归一化),作者计算测试集中的图像的数量,其中预测的UV关节位置与ground truth位置的距离落在给定半径内。

图7 模型表现

图8 (a)模型表现;(b)有或者没有空间模型;(c)在不同bank数目情况家的部件检测器的表现。

图9 预测的关节位置。顶行:FLIC测试集。底行:LSP测试集。
图 7a 和 7b 显示作者的模型在肘部和腕关节的FLIC测试集上的表现,并使用FLIC和FLIC-plus训练集进行训练。 LSP数据集的性能如图 7c 和 8a 所示。对于LSP评估,作者使用以人为中心(或非以观察者为中心)的坐标与以前的工作进行公平比较 [30, 8].。作者的模型在这两个极具挑战性的数据集上都优于当时已有的最先进技术。
图 8b 说明了作者简单的空间模型的性能改进。正如预期的那样,空间模型对低半径阈值的精度几乎没有影响,但是,对于大半径,它将性能从8%提高到12%。两种模型的统一训练(在独立的预训练之后)为大半径阈值增加了4-5%检测率。
分辨率库数量的影响如图8c所示。正如预期的那样,当添加多个分辨率库时,作者看到了很大的改进。另请注意,感受野的大小以及网络中池化阶段的数量和大小也会对性能产生很大影响。作者使用粗略的元优化来调整网络超参数,以在作者的计算预算内获得最大验证集性能(每个前向传播小于100ms)。
图 9 显示FLIC和LSP测试集中各种输入的预测联合位置。作者的网络在FLIC数据集上产生令人信服的结果(具有比较低的位置误差),但是,因为作者的简单空间模型对于LSP数据集中的许多高度清晰的姿态不太有效,作者的检测器会导致对某些人的图片预测错误。作者认为,增加训练集的规模将改善这些疑难情况的表现。
5 结论
本文证明,将新型ConvNet Part-Detector和MRF启发的空间模型统一到一个学习框架中,明显优于已有的人体姿态识别任务架构。作者的架构的训练和推理使用商品级硬件,并以接近实时帧速率运行,使这种技术适用于各种应用领域。对于未来的工作,作者期望通过增加简单空间模型的复杂性和表现力来进一步改进这些结果(特别像LSP的无约束数据集)。
6 致谢
作者要感谢Mykhaylo Andriluka的支持。 该研究部件由海军研究办公室ONR奖N000141210327资助。
参考文献
[1] M. Andriluka, S. Roth, and B. Schiele. Pictorial structures revisited: People detection and articulated pose estimation. In CVPR, 2009.
[2] M. Bergtholdt, J. Kappes, S. Schmidt, and C. Schn¨orr. A study of parts-based object class detection using complete graphs. IJCV, 2010.
[3] L. Bourdev and J. Malik. Poselets: Body part detectors trained using 3d human pose annotations. In ICCV, 2009.
[4] H. Bourlard, Y. Konig, and N. Morgan. Remap: recursive estimation and maximization of a posteriori probabilities in connectionist speech recognition. In EUROSPEECH, 1995.
[5] P. Buehler, A. Zisserman, and M. Everingham. Learning sign language by watching TV (using weakly aligned subtitles). CVPR, 2009.
[6] R. Collobert, K. Kavukcuoglu, and C. Farabet. Torch7: A matlab-like environment for machine learning. In BigLearn, NIPS Workshop, 2011.
[7] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, 2005.
[8] M. Dantone, J. Gall, C. Leistner, and L. Van Gool. Human pose estimation using body parts dependent joint regressors. In CVPR’13.
[9] M. Eichner and V. Ferrari. Better appearance models for pictorial structures. In BMVC, 2009.
[10] P. Felzenszwalb, D. McAllester, and D. Ramanan. A discriminatively trained, multiscale, deformable part model. In CVPR, 2008.
[11] A. Giusti, D. Ciresan, J. Masci, L. Gambardella, and J. Schmidhuber. Fast image scanning with deep max-pooling convolutional neural networks. In CoRR, 2013.
[12] G. Gkioxari, P. Arbelaez, L. Bourdev, and J. Malik. Articulated pose estimation using discriminative armlet classifiers. In CVPR’13.
[13] K. Grauman, G. Shakhnarovich, and T. Darrell. Inferring 3d structure with a statistical image-based shape model. In ICCV, 2003.
[14] G. Heitz, S. Gould, A. Saxena, and D. Koller. Cascaded classification models: Combining models for holistic scene understanding. 2008.
[15] A. Jain, J. Tompson, M. Andriluka, G. Taylor, and C. Bregler. Learning human pose estimation features with convolutional networks. In ICLR, 2014.
[16] S. Johnson and M. Everingham. Learning Effective Human Pose Estimation from Inaccurate Annotation. In CVPR’11.
[17] S. Johnson and M. Everingham. Clustered pose and nonlinear appearance models for human pose estimation. In BMVC, 2010.
[18] D. Lowe. Object recognition from local scale-invariant features. In ICCV, 1999.
[19] M. Mathieu, M. Henaff, and Y. LeCun. Fast training of convolutional networks through ffts. In CoRR, 2013.
[20] G. Mori and J. Malik. Estimating human body configurations using shape context matching. ECCV, 2002.
[21] F. Morin and Y. Bengio. Hierarchical probabilistic neural network language model. In Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics, 2005.
[22] F. Ning, D. Delhomme, Y. LeCun, F. Piano, L. Bottou, and P. Barbano. Toward automatic phenotyping of developing embryos from videos. IEEE TIP, 2005.
[23] L. Pishchulin, M. Andriluka, P. Gehler, and B. Schiele. Poselet conditioned pictorial structures. In CVPR’13.
[24] L. Pishchulin, M. Andriluka, P. Gehler, and B. Schiele. Strong appearance and expressive spatial models for human pose estimation. In ICCV’13.
[25] D. Ramanan, D. Forsyth, and A. Zisserman. Strike a pose: Tracking people by finding stylized poses. In CVPR, 2005.
[26] S. Ross, D. Munoz, M. Hebert, and J.A Bagnell. Learning message-passing inference machines for structured prediction. In CVPR, 2011.
[27] B. Sapp and B. Taskar. Modec: Multimodal decomposable models for human pose estimation. In CVPR, 2013.
[28] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.
[29] J. Tompson, M. Stein, Y. LeCun, and K. Perlin. Real-time continuous pose recovery of human hands using convolutional networks. In TOG, 2014.
[30] A. Toshev and C. Szegedy. Deeppose: Human pose estimation via deep neural networks. In CVPR, 2014.
[31] Yi Yang and Deva Ramanan. Articulated pose estimation with flexible mixtures-of-parts. In CVPR’11.