【tensorrt之dynamic shapes】
1. 背景
Dynamic shapes指的是我们可以在runtime(推理)阶段来指定some或者all输入数据的维度,同时,提供C++和Python两种接口。一般需要指定为dynamic的是batch_size这一个维度,使得我们可以根据自己实际情况动态设置batch,而不需要每次都重新生成engine文件。
2. 总体流程
如何生成及使用支持dynamic shapes的engine的大致步骤如下:
1. 使用最新的接口创建NetworkDefinition对象
截止到tensorrt-7.2.2,builder创建NetworkDefinition提供两个接口:createNetwork()和createNetworkV2(),这两者之间区别有两点:1. 后者处理的维度从原来的(C,H,W)变成了(B,C,H,W)即包括了batch_size; 2. 是否支持dynamic shapes.
2. 对于input tensor中dynamic的维度,通过-1来占位这个维度
3. 在build阶段设置一个或多个optimization profiles,用来指定在runtime阶段inputs允许的维度范围,一般设置三个profiles,最小,最大和最优。
通过上述设置,在build阶段就可以生成一个带dynamic shapes的engine文件,然后就是在推理阶段如何使用这个engine。
4. 如何使用带dynamic shapes的engine:
a. 创建一个execution context,此时的context也是dynamic shapes的;
b. 将想要设置的input dimension绑定context,那么此时context处理的维度确定了;
c. 基于这个context进行推理。



3. 代码实现
3.1 创建NetworkDefinition

3.2 设置输入维度
对于3维的input tensor,其name为“foo"的设置流程如下

3.3 设置Optimization Profiles
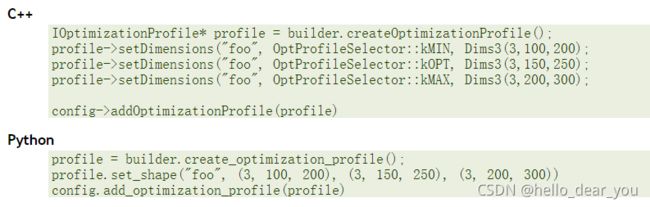 通过上述设置完成后,即可编译得到engine文件。
通过上述设置完成后,即可编译得到engine文件。
3.4 context对象设置
基于engine对象生成一个execution context对象,此时利用get_binding_shape函数得到的结果如下(此时engine和context获取得到的维度相同):

然后通过如下方式将输入tensor的维度绑定到该context上

然后再通过get_binding_shape函数获取维度,得到的结果如下:

此时,输入输出的维度固定,分配输入输出所需的内存和显存,调用enqueueV2()函数进行推理。
4. resnet18部署
重要代码讲解
1. 生成engine
注意点包括如下几点:
- 使用最新的接口创建NetworkDefinition
- 创建config对象来设置workspace,mixed precision
- 如果onnx模型中包含dynamic shape,通过传入dynamic_shapes参数设置对应的op
def build_engine(onnx_file_path, trt_logger, trt_engine_datatype=trt.DataType.FLOAT, batch_size=1, silent=False, dynamic_shapes={}):
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
EXPLICIT_BATCH = [] if trt.__version__[0] < '7' else [1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)]
with trt.Builder(trt_logger) as builder, builder.create_network(*EXPLICIT_BATCH) as network, trt.OnnxParser(network,
trt_logger) as parser:
builder.max_batch_size = batch_size
config = builder.create_builder_config()
config.max_workspace_size = 1 << 30 # work space
if trt_engine_datatype == trt.DataType.HALF: # float 16
config.set_flag(trt.BuilderFlag.FP16)
# Parse model file
if not os.path.exists(onnx_file_path):
print('ONNX file {} not found, please run yolov3_to_onnx.py first to generate it.'.format(onnx_file_path))
exit(0)
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
print('Completed parsing of ONNX file')
if not silent:
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
# dynamic batch_size
if len(dynamic_shapes) > 0:
print("===> using dynamic shapes!")
profile = builder.create_optimization_profile()
for binding_name, dynamic_shape in dynamic_shapes.items():
min_shape, opt_shape, max_shape = dynamic_shape
profile.set_shape(binding_name, min_shape, opt_shape, max_shape)
config.add_optimization_profile(profile)
return builder.build_engine(network, config) 2. 绑定维度
需要在执行execute函数之前绑定维度,从而确定输入输出维度。
dynamic_batch = 6
input_data = np.ones((dynamic_batch, 3, 224, 224), dtype=np.float32)
# At runtime you need to set an optimization profile before setting input dimensions.
# trt_inference_wrapper.context.active_optimization_profile = 0
# specifying runtime dimensions
trt_inference_wrapper.context.set_binding_shape(0, input_data.shape)3. 分配内存和显存
def allocate_buffers(engine, context):
"""Allocates host and device buffer for TRT engine inference.
This function is similair to the one in ../../common.py, but
converts network outputs (which are np.float32) appropriately
before writing them to Python buffer. This is needed, since
TensorRT plugins doesn't support output type description, and
in our particular case, we use NMS plugin as network output.
Args:
engine (trt.ICudaEngine): TensorRT engine
Returns:
inputs [HostDeviceMem]: engine input memory
outputs [HostDeviceMem]: engine output memory
bindings [int]: buffer to device bindings
stream (cuda.Stream): cuda stream for engine inference synchronization
"""
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
# Current NMS implementation in TRT only supports DataType.FLOAT but
# it may change in the future, which could brake this sample here
# when using lower precision [e.g. NMS output would not be np.float32
# anymore, even though this is assumed in binding_to_type]
for binding in range(engine.num_bindings):
size = trt.volume(context.get_binding_shape(binding))
# size = trt.volume(engine.get_binding_shape(binding))
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream完整代码分享在github,支持dynamic和static shapes。
egbertYeah/simple_tensorrt_dynamic: a simple example to learn tensorrt with dynamic shapes (github.com)
参考链接
- tensorrt动态输入(Dynamic shapes) - 知乎 (zhihu.com)
- Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
- TensorRT7 Onnx模型动态多batch问题解决_weixin_45415546的博客-CSDN博客_tensorrt动态batchsize