分类变量回归: R语言中哑变量编码本质
本篇描述分类变量如何进行回归(翻译自http://www.sthda.com/english/articles/40-regression-analysis/163-regression-with-categorical-variables-dummy-coding-essentials-in-r/)
分类变量(也称为因子或定性变量)是可以将观测数据分组的变量。它们有有限数量的不同值,称为水平。例如,性别作为一个分类变量,它有两个水平:男性或女性。
回归分析需要数值变量。因此,当研究者希望在回归模型中包含一个分类变量时,需要其他步骤使结果具有可解释性。
在这些步骤中,分类变量被重新编码成一组单独的二元变量。这种编码被称为“哑变量编码”,并创建一个称为contrast matrix的表。这是由统计软件自动完成的,如R。
在这里,您将学习如何构建和解释带有分类预测变量的线性回归模型。我们还将在R中提供实际的例子。
加载需要的R包
便于数据操作和可视化的tidyverse

数据集示例
我们将使用Salaries数据集[car package],它包含美国一所大学的助理教授、副教授和教授2008-2009年内9个月的工资。这些数据的收集目的是监测男性和女性教师之间的工资差异。


两个水平的分类变量
回想一下,在预测变量(x)的基础上预测结果变量(y)的回归方程可以简单地写成y = b0 + b1*x。b0和b1为回归系数,分别表示截距和斜率。
假设,我们希望调查男性和女性之间的工资差异。
基于性别变量,我们可以创建一个新的哑变量,取值为:

并将该变量作为回归方程的预测变量,得到如下模型:
这些系数可以解释为:
(1)b0是女性的平均工资,
(2)b0 + b1是男性的平均工资,
(3)b1是男性和女性的平均工资差异。
为了演示,下面的例子通过计算一个简单的关于 Salaries 数据集[car包]的线性回归模型来模拟男性和女性之间的工资差异。R自动创建虚拟变量:
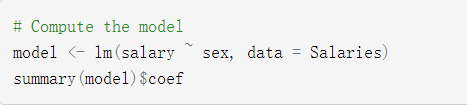

从上面的输出可以看出,女性的平均工资估计为101002,而男性的平均工资估计为101002 + 14088 = 115090。哑变量sexMale的p值非常显著,这表明两性之间的平均工资存在显著差异。
contrasts() 函数的作用是:返回R用来创建哑变量的编码:
![]()

R创建了一个sexMale哑变量,如果性别是男性,则值为1,否则值为0。将男性编码为1,女性编码为0(基线)的决定是任意的,这对回归计算没有影响,但是会改变对系数的解释。
可以使用relevel()函数将基线类别设置为males,如下所示:

之后回归拟合的输出为:


事实上,在回归输出中性别女性的系数是负的,这表明作为女性与薪水(相对于男性)的减少有关。
现在b0和b1的预测值分别为115090和-14088,再次得出男性的平均工资为115090,女性的平均工资为115090 -14088 = 101002。
另外,我们可以创建一个哑变量-1(男性)/1(女性),而不是0/1编码方案。这导致模型:

具有两个以上水平的分类变量
一般来说,一个有n个水平的分类变量会转化为n-1个各有2个水平的哑变量。这n-1个新变量包含的信息与单个变量相同。
例如, Salaries 数据中的**‘‘rank’’**有三个水平:“AsstProf”、“AssocProf”和“Prof”。这个变量可以伪编码成两个变量,一个叫AssocProf,一个叫Prof:

这个哑变量编码由r自动执行。出于演示目的,您可以使用函数model.matrix()为一个因子变量创建一个 contrast matrix :


在建立线性模型时,有不同的方法来编码分类变量,称为对比编码系统。R中的默认选项是使用因子的第一个水平作为参考,并解释相对于该水平的其余水平。
注意,ANOVA(方差分析)只是线性模型的一种特殊情况,其中的预测因子是分类变量。而且,因为R理解ANOVA和回归都是线性模型的例子,它允许您使用R base anova()函数或*ANOVA()*函数[car包]从您的回归模型中提取经典的ANOVA。我们通常推荐Anova()函数,因为它会自动处理不平衡设计。
使用多元回归方法预测工资的结果如下:

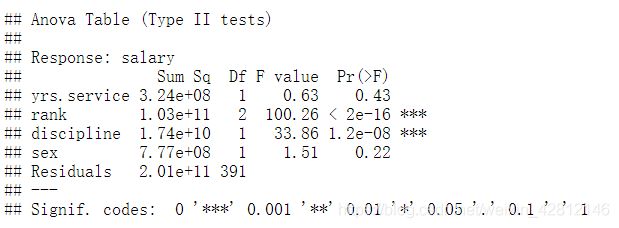
取其他变量(yrs.service, rank and discipline),可以看出分类变量性别不再与个体间薪酬差异显著相关。重要变量是rank和discipline.。
如果你想解释分类变量的对比,输入:

例如,我们可以看到,来自discipline B( applied departments) 的员工相对于discipline A(theoretical departments)平均工资增长13473.38,这是显著相关的。
讨论
在这一篇章中,我们描述了分类变量是如何包含在线性回归模型中的。由于回归需要数字输入,分类变量需要被重新编码成一组二元变量。
我们提供了实际的例子,你有两个或两个以上水平的分类变量的情况。
注意,对于具有大量水平的分类变量,将一些水平组合在一起可能是有用的。
有些类别变量的级别是有序的。它们可以转换为数值并按原样使用。例如,如果教授等级(“AsstProf”、“AssocProf”和“Prof”)有特殊的含义,您可以将它们转换为数值,从低到高排序。
欢迎关注我的公众号:聊无的学习笔记
