学习笔记 | Heckman两阶段法介绍
最近看的两篇VC文献,都是有使用到Heckman两阶段法,所以就借此机会系统学习了Heckman两阶段法
本篇内容主要学习了如下文章:
1 CJAR的带你了解Heckman两步法
2 计量经济圈的Heckman两步法是什么? 及其内生性问题?
3 Stata连享会的Heckman 模型:你用对了吗?
4 会计学术联盟的玩转Stata | Heckman两阶段-内生性处理利器
5 社经研究社的您真的懂得如何运用Heckman模型检验吗?
这几篇文章都很有用,这几个公众号也很赞,所以可以多学习多学习~~
Heckman两阶段法介绍
- 1 Heckman两阶段法来源
-
- 1.1 样本不存在随机性
- 1.2 样本自选择
- 1.3 选择偏差产生的后果
- 2 Heckman两阶段法原理
-
- 2.1 基本原理
- 2.2 方法评价
- 3 Heckman两阶段法实现
-
- 3.1 实现步骤
- 3.2 实现示例
- 4 Heckman两阶段法注意事项
1 Heckman两阶段法来源
Heckman两阶段法是由Heckman(1979)提出,主要用于解决样本选择偏差(sample selection bias)问题。那么样本选择偏差问题是什么呢?其实就是内生性的一种。学习内生性,可以看我之前的一篇笔记学习笔记 | 内生性全面介绍
具体而言,样本选择偏差包括两种,一种是不是随机性导致的样本偏差,一种是由于样本自选择导致的偏差。下面介绍一下
1.1 样本不存在随机性
样本不存在随机性就是研究人员根据自己设定的规则抽取样本,而不是随机抽样。
举例1:研究人员在研究公司治理问题时只收集了发达地区的公司作为样本。
举例2:以“找熟人”为研究对象,来探讨使用社会资本对求职结果的影响。假设我们是采用采访的方式,询问自己的工作是不是通过找熟人获得的,来识别这个人是不是使用社会资本。但值得注意的是,那些具有社会资本,但不想使用,可能是高自尊心,或者是想通过自己努力来获得。我们通过采访,进而错过了这些样本,或者说我们只是圈住了那些不自尊、不努力的样本,由此我们使用一个不自尊、不努力的样本来研究社会资本的效应,由此是会高估结果的。
1.2 样本自选择
自选择是指由于经济个体(个人、家庭或厂商)本身具有选择判断能力,因此很可能会采取一些影响抽样过程的行动,从而使抽样失去随机性,造成所收集到的样本不能比例地代表总体。
举例:若我们想研究妇女年龄与工资收入,虽然我们可以观测到有工作的妇女的实际工资收入,但是不知道没有工作的妇女的“保留工资”(即愿意工作的最低工资)。于是我们收集数据时就会缺失没有工作的妇女样本。
1.3 选择偏差产生的后果
整体而言,基于以上两种情形,被选择的样本都无法代表总体,使用这样的样本进行研究是得不到准确的结果的。
延续之前的例子,
比如我们要研究妇女年龄和工资的关系、。显然我们只可能从有工作的妇女那儿获得有关工资的数据,无法获得没出来工作的妇女的数据,这样的话,就存在低估效应。具体而言:
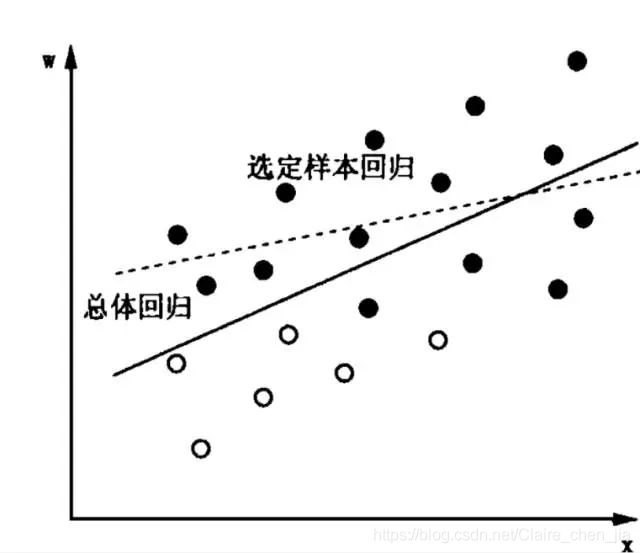
因为有不小比例的妇女没有参加工作,对这些人,我们知道性别,却不知道一小时可以挣多少钱。一般地,人们是否参加工作取决于实际可得的工资与意愿工资,当工资低于意愿工资时,人们就会选择不工作。把不工作这部分人也搬到我们的图上,其分布就是图中的空心点。如图可知,实线是根据总样本(黑点加白点所代表的样本)回归所得,而虚线是根据我们选择的样本回归所得。两线斜率、截距明显不同,即样本选择会带来偏误。可以发现,如果只拿实心点研究,得出的结论实际上低估了受教育程度对工资的影响。
为此,Heckman两阶段法被提出来了!他的大致原理是:
首先,估计出妇女参加工作的概率(可能性)多大,这可以通过经验数据模型得到。然后,删去不工作之妇女的样本,将余留的样本点依其工作概率的不同,垂直往下位移。工作概率愈小,向下位移愈大;工作概率愈大,向下位移愈小。工作概率百分之百的,不作位移。(实心点下移到由空心点标示的新位置。)
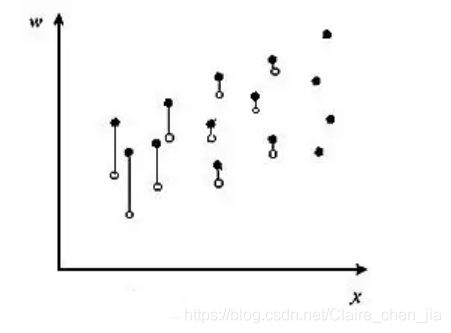
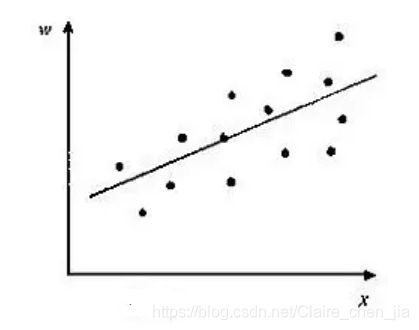
然后,对位移后的样本点,求出其回归线。理论上可以证明,这条回归线,与第一个图中标出的真实关系线,应当是一致的
2 Heckman两阶段法原理
参考自:Stata连享会的Heckman 模型:你用对了吗?
2.1 基本原理
两阶段法包括两个阶段: 处理效应 (treatment effect model)、样本选择 (sample selection model)。
处理效应 (treatment effect model):回归模型中包含一个内生的指示变量(D)。如妇女年龄对工资的影响,(出来工作的女性D=1,没有出来工作的女性D=0)即模型(1),也就是我们要预测的模型(回归模型),θ就是我们关注的
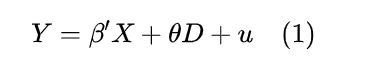
样本选择 (sample selection model):回归样本为一个子样本。例如,在女性样本中 (D=1)分析妇女年龄与工资关系。由于传统上,部分女性因为实际给的工资与意愿工资不一样,所以选择留在家庭。因此,在模型(2)中,D=1内生的 ,导致模型(1)有偏估计。
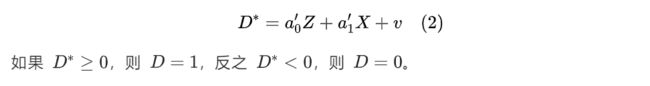
通常,式 (1) 和式 (2) 的随机误差项u 和 v 服从二元正态分布,其均值为 0,协方差矩阵为:
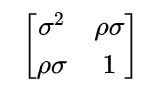
如果随机误差项u 和 v相关 (p不等于 0),则E(u|D)不等于0 ,使得式 (1) 中的 OLS 估计量 θ有偏。
Heckman 方法就是通过式 (2) 构造 逆米尔斯比率 (IMR) 控制这个偏差。 计算如下:

2.2 方法评价
综上,也就说我们传统采用OLS估计θ
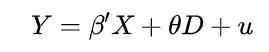
这里我们引入了逆米尔斯比率(IMR)来修正模型(1)中由D引起的选择偏误
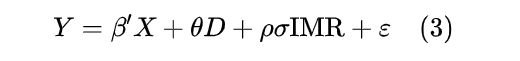
而IMR能够识别选择偏误,主要是通过:
- (1)IMR是X 和Z 变量的非线性函数
- (2)Z变量从式 (3) 中已经排除。
那么 Z变量是什么呢?Z被假定为不会对 Y 变量产生直接的影响,只能通过IMR 产生间接影响,因此也被称为排他性约束 (exclusion restrictions)。Z也被成为排他性约束变量。
那么Z(排他性约束变量)需要满足什么条件呢?简单而言,就是要满足工具变量的条件,排他性和相关性。

但是问题又出来,工具变量的选择一般是很难的,所以我们进行第一阶段的选择模型时,如果没有Z,可以仅把第一阶段的X(即控制变量)放入进行probit回归,通过IMR的非线性去识别偏差。但可能面临以下两个问题:
- 由于只能通过IMR 的非线性识别偏差,非线性模型被错误设定为线性模型会被IMR吸收。
- 在式 (3) 中,IMR 与X 和 D 相关,这种相关性在没有排他性约束变量 (Z) 情况下更加严重。
进一步,高的共线性会产生以下两个问题:
- 高共线性会使得系数的标准差变大,降低了系数的显著性。IMR系数可能会变得不显著,进而得出错误结论。
- 在模型被正确设定下,即使存在高的共线性问题,系数也可以被无偏的估计。但是,事实上,选择模型被错误设定概率是很高的。若模型被错误设定,共线性会吸收这种偏差,导致系数估计有偏。所以我们在采用时,要进行VIF检验共线性问题。
3 Heckman两阶段法实现
3.1 实现步骤
我们还是一如既往以妇女年龄与工资的研究为例,具体步骤如下:
- 第一步:利用从全部妇女(包括出来工作的和留在家里的)中随机抽取的样本,估计妇女出来工作的倾向模型;并利用估计结果计算逆米尔斯比的值。
- 第二步,利用选择性样本观测值和计算得到的逆米尔斯比的值,将(ρσ,)作为- 一个待估计参数,估计妇女年龄与工资模型,得到β的估计。
-注意,在抽取样本时间必须保证所有选择性样本包含于全部样本之中。
实现方法有两种途径:
方法一:Heckman Y(因变量) X(控制变量), select (D(自变量哑变量) =Z(工具变量其他影响因素) X(控制变量)) twostep
这种方法成为最大似然估计 (Maxlikelihood Estimation, MLE)
方法二:先在第一阶段中计算出除逆米尔斯比率IMR,再在第二阶段中将逆米尔斯比率imr作为控制变量,予以考察。基本步骤如下:
步骤1: 通过运用probit模型计算影响所考察变量的哑变量(0-1)的影响因素(即“第一阶段”),
步骤2: 在上述一步基础上,计算预测:predict w,xb,
步骤3: 再次,计算生成:gen IMR=normalden(w)/normal(w),
步骤4: 最后,将所生成的逆米尔斯比率IMR引入主要考察模型,并予以控制(即“第二阶段”)。
这种方法就是常用的两步法
3.2 实现示例
参考自:Stata连享会的Heckman 模型:你用对了吗?
这里搬运的是一个大家都使用的示例,都是女性与工资,不过是女性教育与女性工资的关系。会用上面的第一种和第二种方法分别示例。
首先,我们还是来先谈一下如何选择排他性变量来处理选择性偏误。
了解女性教育对工资的影响,那么这里需要注意到,有些受了教育但也没有参加工作,那这部分样本需要特殊处理。所以,我们就先预测一个女性参加工作的可能性,然后再在那些参加了工作的女性样本中回归工资和教育水平。
预测一个女性参加工作的可能性通过age(年龄) education(教育) married(是否结婚) children(孩子数量)
通常我们认为结婚与孩子的数量一般会与妇女愿不愿出来工作有关,但是与妇女获得工资无关,所以满足排他性和相关性要求,选择为排他性变量
*数据来源: https://gitee.com/arlionn/data
use womenwk.dta, clear
*描述性统计数据
sum age educ married children wage
*简单的ols模型,存在选择性偏误
reg wage educ age
est store OLS
*第一种方法 heckman maximum likelihood
heckman wage educ age, select(married children educ age) //默认最大似然估计
est store HeckMLE
*第二种方法 heckman two-step all-in-one 不可以进行cluster调整
heckman wage educ age, select(married children educ age) twostep
est store Heck2s
*第二种方法 heckman two-step step-by-step 可以进行cluster调整
probit work married children educ age
est store First
predict y_hat, xb
gen pdf = normalden(y_hat) //概率密度函数
gen cdf = normal(y_hat) //累积分布函数
gen imr = pdf/cdf //计算逆米尔斯比率
reg wage educ age imr if work == 1 //女性工作子样本
est store Second
vif //方差膨胀因子
*对比结果
local m "OLS HeckMLE Heck2s First Second"
esttab `m', mtitle(`m') nogap compress pr2 ar2
4 Heckman两阶段法注意事项
- 虽然有人在运用该方法时,在第一步没有选择排他性变量,但一般模型的运用是需要一个工具变量问题。因为在前面我们也讲过,如果不加入会存在共线性问题,估计也存在偏误。
- 工具变量的选择需要很多的思考。我看到之前有很多人用变量密度或者区域经济变量均值作为工具变量。在选择工具变量的时候,我们需要解释一下为何选择要有具有的支撑。
以李小荣和刘行(2012)高管性别与股价崩盘风险的研究为例。第一阶段回归Probit模型(女性高管=1),模型中加入影响女性高管选择的因素和排除性约束变量。排除性约束变量为同年同行业中其他公司的女性CEO比例,由于已有文献证明同年同行业中其他公司的女性CEO比例影响本公司CEO性别选择;同年同行业中其他公司女性CEO的比例对本公司的股价崩盘风险无直接影响。
-
在第一阶段中,因变量为0-1哑变量,所以第一阶段一般都是运用Probit分析模型。此外,在第二阶段分析中,当引入IMR予以控制后,选择偏误调整项IMR系数如果通过显著性检验,这表明虚拟变量选择的内生性偏误一定程度是存在的,这表明采取文章分析样本自选择问题是必要的,这将进一步提升文章研究结论的稳健性。
-
将IMR放入第二阶段可能会造成多重共线问题,因此需要在回归结果中报告VIFs(Variance Inflaction Factors)。通常认为VIFs值超过10,即存在多重共线问题。
-
需要注意的是,方法一中Heckman直接命令代码的运用具有明显的局限性,这里的因变量一般要求为“连续性变量”,而当因变量为哑变量(0-1)或其他非连续性变量时,上述方法一的直接运用将存在明显的统计偏误。为此,当在实证研究过程中,遇到因变量为非连续性变量时,方法一不再适用,可借鉴方法二,将Heckman二阶段分析进行拆分。
-
多数论文使用两步法省略了报告第一阶段。有必要明确报告第一阶段模型使用了哪些变量,以便清楚地识别排除性约束变量。第二阶段的回归模型中,除排除性约束变量外,需加入第一阶段模型的所有控制变量。
-
在使用过程中,可以综合借鉴和学习如下这三篇文章。
Lennox C S, Francis J R, Wang Z. Selection models in accounting research[J]. The accounting review, 2012, 87(2): 589-616.
Kim C, Zhang L. Corporate political connections and tax aggressiveness[J]. Contemporary Accounting Research, 2016, 33(1): 78-114.
李小荣, 刘行. CEO vs CFO: 性别与股价崩盘风险[J]. 世界经济, 2012, 12: 102-129.