DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement---论文翻译
DPCRN:用于单通道语音增强的双路径卷积递归网络
Xiaohuai Le1;2;3, Hongsheng Chen1;2;3, Kai Chen1;2;3, Jing Lu1;2;31Key Laboratory of Modern Acoustics, Nanjing University, Nanjing 210093, China 2NJU-Horizon Intelligent Audio Lab, Horizon Robotics, Beijing 100094, China 3Nanjing Institute of Advanced Artificial Intelligence, Nanjing 210014, China fmg20220173, [email protected], fchenkai, [email protected]
摘要
双路径RNN(DPRNN)被提出来,以便更有效地对时域中的极长序列进行语音分离建模。通过将长序列分割成较小的块,并应用块内和块间的RNN,DPRNN在有限的模型规模下,在语音分离中达到了很好的性能。在本文中,我们将DPRNN模块与卷积递归网络(CRN)相结合,设计了一个名为双路径卷积递归网络(DPCRN)的模型,用于时频域的语音增强。我们用DPRNN模块取代了CRN中的RNN,其中块内RNN被用来模拟单帧的频谱模式,块间RNN被用来模拟连续帧之间的依赖。仅凭0.8M的参数,提交的DPCRN模型在Interspeech 2021年深度噪声抑制(DNS)挑战赛的宽频带场景赛道上取得了3.57的总体平均意见得分(MOS)。对其他一些测试集的评估也显示了我们模型的功效。
关键词: 语音增强,深度学习,时频域,双路径RNN
1. 绪论
广泛存在的噪声和混响可能会严重降低自动语音识别(ASR)系统的性能,并降低通信中的语音清晰度。 语音增强的目的是将干净的语音从背景干扰中分离出来,以提高语音可懂度和感知质量。尽管最近基于DNN的语音增强取得了快速进展,但其在实际应用中的表现仍然面临着低信噪比(SNR)、高混响和远场拾取等挑战。Interspeech 2021年深度噪声抑制(DNS)挑战赛[1]是为了培养在恶劣环境下更具竞争力的语音增强系统而举办的,并为此提供了训练数据集和评估指标。
作为一种数据驱动的监督学习方法,基于DNN的语音增强主要可以分为时频域[2-4]和时域[5-7]方法。时频域(T-F)方法旨在从噪声语音的特征中提取干净语音的声学特征(如复数谱或对数功率谱)。常见的训练目标包括理想比率掩码(IRM)[8]和目标幅度谱(TMS)[3]等。相位谱也被认为有利于提高语音质量[9]。然而,由于相位谱的非结构化特征,很难直接估计它。相位敏感掩码(PSM)[4]被提出来,以利用相位信息进行语音增强。最近的方法,如PHASEN[10],利用幅值和相位谱之间的相互联系来进行更好的相位估计。其他一些方法通过优化复数频谱的实部和虚部[11]或估计复数比率掩码(CRM)[12]来隐式检索相位。由于复值权重适合对频谱的固有信息进行建模,复值神经网络[13]也被用于语音增强。
时域方法通过端到端训练直接估计干净的语音波形,规避了在T-F域估计相位信息的麻烦。 作为时域的典型方法,Conv-Tasnet[5]利用一维卷积神经网络(Conv-1D)[14]作为编码器,将时域波形转换为有效的表征,以实现有效的清洁语音估计,然后通过一个称为解码器的转置卷积层将表征转换回波形。时域方法存在对极长序列进行建模的困难,因此必须利用非常深的卷积层,如wave-u-net[7]来进行特征压缩。传统的递归神经网络(RNNs)也不能有效地对这种长序列进行建模。双路径递归神经网络(DPRNN)[15]被提出来解决这个问题,在这个网络中,长的序列特征被分割成较小的块,由块内和块间的RNN迭代处理,减少每个RNN要处理的序列长度。
DPRNN中的块内操作旨在对一帧内的信号特征进行建模,这也适用于频域,其潜在的好处是充分利用了语音的谐波频谱结构。因此,在T-F域实现类似的网络是合理的。在设计实时语音增强的模型时,应用层数过多的卷积神经网络(CNN)或双向长短期记忆(BiLSTM)等非因果结构是不现实的[10]。最近,一种叫做卷积递归网络(CRN)[16]的网络结构被提出。利用CNN和RNN的优势,CRN不仅可以捕捉到频谱的局部模式,还可以对连续帧之间的依赖性进行建模。在本文中,我们在T-F域中结合了DPRNN和CRN。在CRN的基础上,我们提出了一个新的模型,称为双路径卷积递归网络(DPCRN)。与时域中的DPRNN类似,DPCRNN也使用两种RNN。 块内RNN用于模拟单个时间段的频谱,而块间RNN则用于模拟频谱随时间的变化。由卷积层压缩的特征被送入DPRNN模块进行进一步处理,然后是由转置的卷积层组成的解码器。CRM由最后一个转置的卷积层输出。我们在Interspeech 2021 DNS挑战数据集上评估DPCRN。实验结果显示,DPCRN优于基线模型,包括NSNet2[17]、DTLN[18]和DCCRN[13]。在模拟测试数据集上,我们的模型取得了与基线模型相竞争的结果,并且在低信噪比的情况下表现出更好的性能。根据ITU-T P.835[19]对DNS挑战盲测集的主观评价,仅用0.8M的参数,我们的模型就取得了3.57的总体MOS,并在宽频场景赛道上达到第三名。
2. 双路径卷积递归网络
2.1. 问题的提出
在时域,观察到的噪声语音可以表述为x(t)=s(t)+n(t),其中x(t)、s(t)和n(t)分别指的是噪声、清洁和噪音信号。该公式可以通过短时傅里叶变换(STFT)转化为时频域,即:
![]()
其中X(t; f)、S(t; f)和N(t; f)分别代表在时间帧t和频率指数f上的噪声、干净和噪声语音频谱的时频仓。 为了从混合物中恢复干净的语音,一个常见的方法是估计一个掩码M(t; f)并将其与噪声语音X(t; f)相乘[3]。对于相位检索,我们可以分别估计幅度谱和相位谱的掩码或复数谱的实部和虚部[13]。另一种方法是直接估计复比掩码(CRM)[12],表示为M(t; f) = Mr(t; f) + iMi(t; f),其中Mr(t; f)和Mi(t; f) 代表掩码的实部和虚部。那么去噪过程可以表示为掩码和噪声语音的复数乘积,形式为:
![]()
其中表示逐元乘法,Se(t; f)是增强的语音。应用信号近似法(SA)[20]通常能带来更好的优化,而不是直接估计掩码。SA使增强的语音和干净的语音之间的差异最小,损失函数描述为L = Loss(Se(t; f); S(t; f))。
2.2. 模型结构
双路径RNN(DPRNN)最初在[15]中提出,在时域的单通道语音分离任务中取得了最先进的(SOTA)性能。在这个模型中,语音波形被一个由Conv-1D层组成的编码器转换为有效的表示。然后,通过将编码器的特征传递给一个精心设计的DNN来进行分离。为了获得更好的性能,通常利用较小的Conv-1D核大小,从而产生极长的特征块。传统的RNN难以对如此长的序列进行建模。在DPRNN中,一个长序列被分成重叠的块,并由块内和块间的RNN处理,以获得更好的优化。最近,DPRNN还与自我注意机制相结合,用于时间域语音增强[21]。
DPRNN中的块内操作也适用于频域,其潜在的好处是充分利用了语音的频谱结构。通过结合DPRNN和CRN,有可能在T-F域获得一个良好的模型。与原始的DPRNN类似,我们的模型由一个编码器、一个双路径RNN模块和一个解码器组成,如图1(a)所示。编码器和解码器的结构类似于CRN[16]。我们将噪声信号的复数谱图的实部和虚部作为两个数据流送入编码器。编码器使用二维卷积(Conv-2D)层从噪声频谱图中提取局部模式并降低特征分辨率。解码器使用转置的卷积层将低分辨率特征恢复到原来的大小,与编码器形成一个对称结构。编码器和解码器之间有跳过的连接,以传递详细的信息。每一个卷积层之后都有一个批量归一化和一个PReLU函数[22]。我们用DPRNN模块取代CRN的RNN部分,如图1(b)所示。与原始DPRNN不同,我们将STFT中的帧视为DPRNN处理的块。与其在时域中学习依赖性,不如应用块内RNN来对单帧的光谱模式进行建模。我们认为,由于语音的谐波结构,对频率的依赖性进行建模有利于语音增强。RNNs可以克服CNNs接受领域有限的缺点,并捕获长期的谐波相关性。至于分块间的RNNs,我们使用LSTM对某一频率的时间依赖性进行建模,这样就可以保证严格的因果关系。 这些LSTM是并行计算的。 BiLSTM被用来进行块内建模,这不会影响整个系统的因果性。LSTM和BiLSTM之后是一个全连接层(FC)和一个层规范化(LN)[23]。 然后在RNN的输入和LNN的输出之间应用一个残差连接[24],以进一步缓解梯度消失的问题。
在我们的模型中,我们使用即时层归一化(iLN)[18],而不是普通的LN,所有帧都独立计算频率轴f和信道轴c的统计数据,并共享相同的可训练参数。记Ft 2 RN×K为第t帧的特征矩阵,N和K为f和c的特征维度,E和D为均值和方差算子,γ和β 2 RN×K可训练参数," 为正则化参数,则时间索引t的特征的iLN定义为
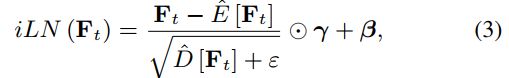
其中
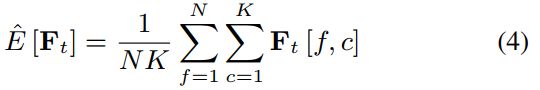
以及

为了降低模型输出对输入信号能量的敏感性,我们还在输入频谱图上应用iLN。
2.3. 学习目标和损失函数
在我们的实验中,DPCRN的学习目标是CRM。CRM的实部和虚部作为两个数据流从解码器输出。在训练阶段,学习目标通过信号近似(SA)进行优化。用估计的掩码M=Mr+iMi乘以噪声语音的频谱图,我们得到增强的频谱图,其形式为:
![]()
使用反STFT(iSTFT)将其转换为波形:
![]()
我们在实验中使用两个损失函数进行比较。 第一个损失函数f是负信噪比(SNR)[25],定义为:
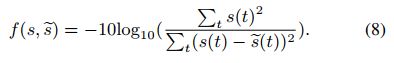
与常用的尺度不变信噪比(SI-SNR)相比,它可以约束输出的振幅,避免输入和输出之间的电平偏移,这对实时处理很重要。考虑到频谱质量,我们将频谱的均方误差(MSE)与负信噪比相加,得到第二个损失函数,其定义如下:

增加的MSE损失由三部分组成,分别测量估计谱图和真实谱图之间的实部、虚部和幅度的差异。我们取MSE损失的对数,以确保它与负信噪比具有相同的数量级。

3. 实验
3.1. 数据集
我们在Interspeech 2021 DNS挑战数据集上训练DPCRN。我们生成了60000个混响语音片段(约500小时),其中55000个片段用于训练,5000个片段用于验证。 噪声片段主要由Audioset[26]、DEMAND[27]和Freesound1生成。在训练阶段,我们将波浪随机分割成5秒钟的片段,并与从openSLR26和openSLR28[28]中随机选择的房间脉冲响应(RIRs)进行卷积。然后,通过混合混响的语音和噪声来生成噪声语音。混合物的信噪比范围被设定在-5到5dB之间。
为了测试各种未知噪声下的性能,我们还使用了WSJ-0[29]的测试集作为测试语音。它包含来自8个发言人的651个语料。有两个噪声数据集用于测试;一个是MUSAN[30]的音乐数据,另一个是NOISEX92[31]的babble、factory1和f16。测试噪声语音的SNR范围与训练集相同。我们还在DNS挑战赛提供的开发测试集和盲测集上评估了该模型。所有使用的音频都是以16kHz采样的。
3.2. 参数设置
在我们的模型中,窗长和跳数分别为25ms和12.5ms,总延迟为37.5ms,满足DNS挑战要求。FFT长度为400,在FFT和overlapadd之前应用正弦窗口。201维的复数频谱被送入模型。编码器中卷积层的通道数为f32,32,32,64,128g。核大小和步长分别设置为f(5,2),(3,2),(3,2),(3,2)g和f(2,1),(2,1),(1,1),(1,1)g,在频率和时间维度上。 所有的Conv-2D和转置的Conv-2D层都是因果计算的。我们使用两个DPRNN模块,每个模块都有RNN,隐藏维度为128。模型的总参数约为0.8M。在下面的实验中,有三个模型供比较。具有方程(8)和(9)所示损失函数的模型分别称为DPCRN-1和DPCRN-2。在第三个模型中,称为DPCRN-3,我们将跨度设置为f(2,1),(2,1),(2,1),(1,1)g,将送入DPRNN的特征的频率分辨率减少一半。 同时,在相同的计算复杂度下,我们将集群内RNN的隐藏维度增加一倍。DPCRN-3的损失函数与DPCRN-1相同。
模型由Adam优化器[32]训练,批次大小为8。初始学习率为1e-3,如果验证集上的损失连续5个epochs都没有改善,则学习率减半。如果验证集上的损失在10个epochs内没有改善,也会在训练中采用早期停止。TensorFlow被用于模型实现,Nvidia GeForce GTX 1080Ti被用于训练。
3.3. 基线和评价指标
我们将我们的模型与Interspeech 2020 DNS挑战赛中在第一个测试集上排名靠前的模型进行比较,包括DTLN[18]和DCCRN[13]。DTLN结合了STFT和一个只有1M参数的可学习的变换。DCCRN使用复值卷积神经网络,并获得了实时赛道的第一名。由Interspeech 2021 DNS挑战赛提供的基线模型NSNet2[17]也在DNS测试集上进行了比较。
在模拟的WSJ0测试集上,我们使用了三个客观的评价指标:语音质量的感知评价(PESQ)[33]、较短时间的客观可懂度(STOI)[34]和信号失真比(SDR)[35]。在DNS挑战开发测试集上,我们使用DNSMOS[36]进行评估,这是一个基于DNN的非侵入式语音质量评估指标。 根据ITU-T P.835[19]的主观评价也被应用在DNS盲测集上作为最终结果。


3.4. 结果和分析
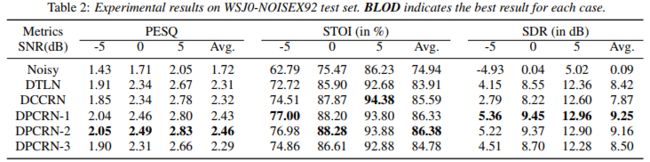
表1中列出了模拟WSJ0-MUSAN测试集的性能。可以看出,当信噪比大于或等于0dB时,DPCRN-1的性能略弱于DCCRN,但优于DTLN。需要注意的是,在较低的信噪比下,DPCRN-1的表现比DCCRN好。表2显示了WSJ0-NOISEX92测试集的结果。在NOISEX92更多的干扰性噪声下,DPCRN-1在所有三个指标方面都超过了基线模型,这表明DPRNN模块对频谱建模的好处。在这两个数据集上,DPCRN-2在PESQ和STOI方面的表现都比DPCRN-1好,但其SDR略差,表明在损失函数中包括时频MSE对语音质量有好处。DPCRN-3比DPCRN-1有更多的参数,但其性能更差,这表明降低输入DPRNN的特征的频率分辨率对系统是不利的。RNN面临着并行计算的困难,这对实时处理是一个挑战。在我们提交的模型中,我们将特征的频率维度设置为50,以保证在满足DNS挑战的实时性要求的同时,有一个体面的频率分辨率。
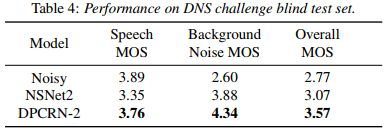
在表3中,我们将DPCRN与基线模型在DNS挑战开发测试集上进行比较。表中的 "Para. "和 "lookahead "分别代表模型的参数量和使用的未来信息的长度。在大约0.8M的参数和没有任何未来信息的情况下,我们的模型在DNSMOS方面比基线模型表现更好,其中DPCRN-2是最好的一个。因此,我们选择这个模型来进行宽频带情景跟踪。 表4显示了DNS挑战盲测集上的最终P.835 MOS,其中给出了语音、背景噪声和总体MOS。在语音质量稍有下降的情况下,提交的模型取得了3.57的总体MOS值,在宽频场景轨道中排名第三。我们模型的计算复杂度约为每秒7.45千兆浮点运算(GFLOPS),在四核英特尔i5-6300HQ上,TensorFlow实现的一帧处理时间为8.9毫秒。
4. 结论
受DPRNN和CRN成功应用的启发,我们提出了一种基于深度学习的时频域语音增强模型,命名为DPCRN。它结合了CNN的局部模式建模能力和DPRNN的长期建模能力。与CRN相比,DPCRN显示了RNN在频谱建模方面的优势。仅用0.8M的参数,我们的模型在各种未知噪声数据集上取得了有竞争力的结果。在未来,我们将尝试降低模型的计算复杂度,用于更宽频带的频谱处理。
5. 鸣谢
中国国家科学基金会以11874219号拨款支持这项工作。
6. 参考文献
[1] C. K. A. Reddy, H. Dubey, K. Koishida, A. Nair, V. Gopal, R. Cutler, S. Braun, H. Gamper, R. Aichner, and S. Srinivasan, “Interspeech 2021 Deep Noise Suppression Challenge,” arXiv e-prints,p. arXiv:2101.01902, 2021.
[2] Y. Xu, J. Du, L. Dai, and C. Lee, “A regression approach to speech enhancement based on deep neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23,no. 1, pp. 7–19, 2015.
[3] D. Wang and J. Chen, “Supervised speech separation based on deep learning: An overview,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 10, pp. 1702–1726, 2018.
[4] H. Erdogan, J. R. Hershey, S. Watanabe, and J. Le Roux, “Phasesensitive and recognition-boosted speech separation using deep recurrent neural networks,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015,pp. 708–712.
[5] Y. Luo and N. Mesgarani, “Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, 2019.
[6] S. Fu, T. Wang, Y. Tsao, X. Lu, and H. Kawai, “Endto-end waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 9, pp. 1570–1584, 2018.
[7] D. Stoller, S. Ewert, and S. Dixon, “Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation,” arXiv e-prints, p. arXiv:1806.03185, 2018.
[8] C. Hummersone, T. Stokes, and T. Brookes, On the Ideal Ratio Mask as the Goal of Computational Auditory Scene Analysis,2014, pp. 349–368.
[9] K. Paliwal, K. Wojcicki, and B. Shannon, “The importance of phase in speech enhancement,” Speech Communication, vol. 53,pp. 465–494, 2011.
[10] D. Yin, C. Luo, Z. Xiong, and W. Zeng, “Phasen: A phase-andharmonics-aware speech enhancement network,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 9458–9465, 2020.
[11] K. Tan and D. Wang, “Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 380–390, 2020.
[12] D. S. Williamson, Y. Wang, and D. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 3, pp. 483–492, 2016.
[13] Y. Hu, Y. Liu, S. Lv, M. Xing, S. Zhang, Y. Fu, J. Wu, B. Zhang,and L. Xie, “DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement,” arXiv e-prints, p.
arXiv:2008.00264, 2020.
[14] C. Lea, R. Vidal, A. Reiter, and G. Hager, “Temporal convolutional networks: A unified approach to action segmentation,”2016.
[15] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-path rnn: Efficient long sequence modeling for time-domain single-channel speech separation,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp.
46–50.
[16] H. Zhao, S. Zarar, I. Tashev, and C. Lee, “Convolutional-recurrent neural networks for speech enhancement,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 2401–2405.
[17] Y. Xia, S. Braun, C. K. A. Reddy, H. Dubey, R. Cutler, and I. Tashev, “Weighted speech distortion losses for neural-networkbased real-time speech enhancement,” in ICASSP 2020 - 2020IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 871–875.
[18] N. L. Westhausen and B. T. Meyer, “Dual-Signal Transformation LSTM Network for Real-Time Noise Suppression,” arXiv eprints, p. arXiv:2005.07551, 2020.
[19] B. Naderi and R. Cutler, “A Crowdsourcing Extension of the ITU-T Recommendation P.835 with Validation,” arXiv e-prints,p. arXiv:2010.13200, 2020.
[20] F. Weninger, J. R. Hershey, J. Le Roux, and B. Schuller, “Discriminatively trained recurrent neural networks for single-channel speech separation,” in 2014 IEEE Global Conference on Signal and Information Processing (GlobalSIP), 2014, pp. 577–581.
[21] A. Pandey and D. Wang, “Dual-path Self-Attention RNN for Real-Time Speech Enhancement,” arXiv e-prints, p.
arXiv:2010.12713, 2020.
[22] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1026–1034.
[23] J. Lei Ba, J. R. Kiros, and G. E. Hinton, “Layer Normalization,”arXiv e-prints, p. arXiv:1607.06450, Jul. 2016.
[24] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
[25] I. Kavalerov, S. Wisdom, H. Erdogan, B. Patton, K. Wilson, J. Le Roux, and J. R. Hershey, “Universal sound separation,” in 2019IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2019, pp. 175–179.
[26] J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen,W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set:An ontology and human-labeled dataset for audio events,” in 2017IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 776–780.
[27] J. Thiemann, N. Ito, and E. Vincent, “The diverse environments multi-channel acoustic noise database (demand): A database of multichannel environmental noise recordings,” The Journal of the Acoustical Society of America, vol. 133, p. 3591, 2013.
[28] T. Ko, V. Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur,“A study on data augmentation of reverberant speech for robust speech recognition,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp.
5220–5224.
[29] D. Paul and J. Baker, “The design for the wall street journal-based csr corpus,” 1992.
[30] D. Snyder, G. Chen, and D. Povey, “MUSAN: A Music, Speech,and Noise Corpus,” arXiv e-prints, p. arXiv:1510.08484, 2015.
[31] A. Varga and H. Steeneken, “Assessment for automatic speech recognition: Ii. noisex-92: A database and an experiment to study the effect of additive noise on speech recognition systems,”Speech Communication, vol. 12, pp. 247–251, 1993.
[32] D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” arXiv e-prints, p. arXiv:1412.6980, 2014.
[33] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra,“Perceptual evaluation of speech quality (pesq)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), vol. 2,2001, pp. 749–752 vol.2.
[34] C. Taal, R. Hendriks, R. Heusdens, and J. Jensen, “A shorttime objective intelligibility measure for time-frequency weighted noisy speech,” 2010, pp. 4214 – 4217.
[35] E. Vincent, R. Gribonval, and C. Fevotte, “Performance measurement in blind audio source separation,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 4, pp. 1462–1469, 2006.
[36] C. K. A. Reddy, V. Gopal, and R. Cutler, “DNSMOS: A NonIntrusive Perceptual Objective Speech Quality metric to evaluate Noise Suppressors,” arXiv e-prints, p. arXiv:2010.15258, 2020.