ORB-SLAM2源码学习(一)
总结:mono_kitti.cc的框架分为以下步骤:
1.LoadImages 加载图片和时间戳
2.实例化SLAM对象,这里初始化了很多线程
3.SLAM.TrackMonocular(im,tframe) 是代码的核心,特征点提取以及均匀化和描述子计算都在这里实现,同时还有整个系统是如何实现跟踪的,还有就是关键帧的选择方式
4.SLAM.shutdown() 关闭所有线程
5.记录跟踪图片的时间
6.将相机轨迹保存
系统框架梳理
mono_kitti.cc开始代码
首先知道输入的四个参数 argv[0] argv[1] argv[2] argv[3]
./Examples/Monocular/mono_kitti Vocabulary/ORBvoc.txt Examples/Monocular/KITTI00-02.yaml dataset/sequences/00step1 加载图像
main()开始定义了两个容器分别存放每张图片的路径和时间戳
vector vstrImageFilenames; //每张图片存放路径
vector vTimestamps; //每张图片时间戳
然后执行LoadImags函数 , 函数作用:读取数据集下的图片路径和对应的时间戳并将读取结果放到容器中
LoadImages(string(argv[3]), vstrImageFilenames, vTimestamps);重点看函数定义:
// 获取图像序列中每一张图像的访问路径和时间戳
void LoadImages(const string &strPathToSequence, vector &vstrImageFilenames, vector &vTimestamps)
{
// step 1 读取时间戳文件
ifstream fTimes; //定义输入流读取文件中的时间戳
string strPathTimeFile = strPathToSequence + "/times.txt";
//此时 strPathTimeFile = dataset/sequences/00/times.txt
//c_str是string类的一个函数,可以把string类型变量转换成char*变量
//open()要求的是一个char*字符串
//当文件名是string时需要转换,当文件名是字符数组型时就不需要此转换
fTimes.open(strPathTimeFile.c_str());
while(!fTimes.eof()) //eof()函数判断文件夹是否读到最后 end of file
{
string s;
getline(fTimes,s); //自动读取下一行时间戳文件 s是读取的结果,以times.txt第一行为例 s = 0.000000e+00
// 如果该行字符串不是空的,就写进流
if(!s.empty())
{
//stringstream 将string类型的 s 转为double类型
stringstream ss;
ss << s;
double t;
ss >> t;
// 容器中保存了所有图片的时间戳
vTimestamps.push_back(t);
}
}
// step 2 使用左目图像, 生成左目图像序列中的每一张图像的文件名
string strPrefixLeft = strPathToSequence + "/image_0/";
const int nTimes = vTimestamps.size();
vstrImageFilenames.resize(nTimes); //图像的数量要和时间戳一一对应
for(int i=0; i main() 继续执行,定义变量nImages vstrImageFilenames容器中图片的个数
int nImages = vstrImageFilenames.size(); //有nImages个图片
step2 加载SLAM系统(重点)
之后实例化一个SLAM对象
ORB_SLAM2::System SLAM(argv[1],argv[2],ORB_SLAM2::System::MONOCULAR,true);
先看System的构造函数:
System::System(const string &strVocFile, //词典文件路径
const string &strSettingsFile, //配置文件路径
const eSensor sensor, //传感器类型
const bool bUseViewer): //是否使用可视化界面
mSensor(sensor), //初始化传感器类型
mpViewer(static_cast(NULL)), //空。。。对象指针? 视觉SLAMch6 g2o代码中使用过,将指向基类的指针转化为指向派生类的指针
mbReset(false), //无复位标志
mbActivateLocalizationMode(false), //没有这个模式转换标志
mbDeactivateLocalizationMode(false) //没有这个模式转换标志
{ 构造函数主要分为:
①输出欢迎信息和传感器类型;
②打开配置文件(.yaml格式),使用cv::FileStorage进行读操作;
//!2. 打开YAML文件进行读操作
cv::FileStorage fsSettings(strSettingsFile.c_str(), //将配置文件名转换成为字符串
cv::FileStorage::READ); //只读
//如果打开失败,就输出调试信息
if(!fsSettings.isOpened())
{
cerr << "Failed to open settings file at: " << strSettingsFile << endl;
//然后退出
exit(-1);
}③加载ORB词包
//! 加载ORB词包
cout << endl << "Loading ORB Vocabulary. This could take a while..." << endl;
//建立一个新的ORB字典
//使用无参构造方法构造对象,使用System类中定义的ORBVocabulary类的类指针*mpVocabulary 在堆区存储对象的位置
//ORBVocabulary类来源于DBoW2中,能够快速稳定计算两帧图像的相似程度
mpVocabulary = new ORBVocabulary();
//使用指针调用类函数加载词包,并返回bool值判断是否加载成功
bool bVocLoad = mpVocabulary->loadFromTextFile(strVocFile);
//如果加载失败,就输出调试信息
if(!bVocLoad)
{
cerr << "Wrong path to vocabulary. " << endl;
cerr << "Falied to open at: " << strVocFile << endl;
//然后退出
exit(-1);
}
//否则则说明加载成功
cout << "Vocabulary loaded!" << endl << endl;
//!完成词袋的提取④利用词袋初始化关键帧数据库(用于重定位和回环检测),存入关键帧数据库指针
//!4. 利用词袋初始化关键帧数据库(用于重定位和回环检测),存入关键帧数据库指针mpKeyFrameDatabase
mpKeyFrameDatabase = new KeyFrameDatabase(*mpVocabulary);⑤创建一个Map类,存储指向所有关键帧和地图点的指针mpMap
//!5. 创建一个Map类,存储指向所有关键帧和地图点的指针mpMap
mpMap = new Map();⑥创建两个窗口,帧绘制器和地图绘制器mpFrameDrawer 和 mpMapDrawer
//!6. 创建两个窗口,帧绘制器和地图绘制器mpFrameDrawer mpMapDrawer
mpFrameDrawer = new FrameDrawer(mpMap);
mpMapDrawer = new MapDrawer(mpMap, strSettingsFile);⑦初始化线程Tracking
//!7. 初始化追踪线程
mpTracker = new Tracking(this, //现在还不是很明白为什么这里还需要一个this指针 TODO
mpVocabulary, //字典
mpFrameDrawer, //帧绘制器
mpMapDrawer, //地图绘制器
mpMap, //地图
mpKeyFrameDatabase, //关键帧地图
strSettingsFile, //设置文件路径
mSensor); //传感器类型iomanip同样重点看它的构造函数
///构造函数
Tracking::Tracking(
System *pSys, //系统实例
ORBVocabulary* pVoc, //BOW字典
FrameDrawer *pFrameDrawer, //帧绘制器
MapDrawer *pMapDrawer, //地图点绘制器
Map *pMap, //地图句柄
KeyFrameDatabase* pKFDB, //关键帧产生的词袋数据库
const string &strSettingPath, //配置文件路径
const int sensor): //传感器类型
mState(NO_IMAGES_YET), //当前系统还没有准备好
mSensor(sensor),
mbOnlyTracking(false), //处于SLAM模式
mbVO(false), //当处于纯跟踪模式的时候,这个变量表示了当前跟踪状态的好坏
mpORBVocabulary(pVoc),
mpKeyFrameDB(pKFDB),
mpInitializer(static_cast(NULL)), //暂时给地图初始化器设置为空指针
mpSystem(pSys),
mpViewer(NULL), //注意可视化的查看器是可选的,因为ORB-SLAM2最后是被编译成为一个库,所以对方人拿过来用的时候也应该有权力说我不要可视化界面(何况可视化界面也要占用不少的CPU资源)
mpFrameDrawer(pFrameDrawer),
mpMapDrawer(pMapDrawer),
mpMap(pMap),
mnLastRelocFrameId(0) //恢复为0,没有进行这个过程的时候的默认值
{
// Step 1 从配置文件中加载相机参数
cv::FileStorage fSettings(strSettingPath, cv::FileStorage::READ);
float fx = fSettings["Camera.fx"];
float fy = fSettings["Camera.fy"];
float cx = fSettings["Camera.cx"];
float cy = fSettings["Camera.cy"];
// |fx 0 cx|
// K = |0 fy cy|
// |0 0 1 |
//构造相机内参矩阵
cv::Mat K = cv::Mat::eye(3,3,CV_32F); //得到的是对角线为1 其余为0的三阶矩阵
K.at(0,0) = fx;
K.at(1,1) = fy;
K.at(0,2) = cx;
K.at(1,2) = cy;
//内参矩阵赋值给成员变量
K.copyTo(mK);
// 图像矫正系数
// [k1 k2 p1 p2 k3] 部分相机的k3是0
cv::Mat DistCoef(4,1,CV_32F);
DistCoef.at(0) = fSettings["Camera.k1"];
DistCoef.at(1) = fSettings["Camera.k2"];
DistCoef.at(2) = fSettings["Camera.p1"];
DistCoef.at(3) = fSettings["Camera.p2"];
const float k3 = fSettings["Camera.k3"];
//有些相机的畸变系数中会没有k3项
if(k3!=0)
{
DistCoef.resize(5);
DistCoef.at(4) = k3;
}
//畸变参数赋值给成员变量
DistCoef.copyTo(mDistCoef);
// 双目摄像头baseline * fx 50
mbf = fSettings["Camera.bf"];
//相机每秒处理的帧数
float fps = fSettings["Camera.fps"];
if(fps==0)
fps=30;
// Max/Min Frames to insert keyframes and to check relocalisation
//用于插入关键帧和检查重新定位的最大/最小帧
mMinFrames = 0;
mMaxFrames = fps;
//输出
cout << endl << "Camera Parameters: " << endl;
cout << "- fx: " << fx << endl;
cout << "- fy: " << fy << endl;
cout << "- cx: " << cx << endl;
cout << "- cy: " << cy << endl;
cout << "- k1: " << DistCoef.at(0) << endl;
cout << "- k2: " << DistCoef.at(1) << endl;
if(DistCoef.rows==5)
cout << "- k3: " << DistCoef.at(4) << endl;
cout << "- p1: " << DistCoef.at(2) << endl;
cout << "- p2: " << DistCoef.at(3) << endl;
cout << "- fps: " << fps << endl;
// 1:RGB 0:BGR 好像Camera.RGB的值都是1???
int nRGB = fSettings["Camera.RGB"];
mbRGB = nRGB;
if(mbRGB)
cout << "- color order: RGB (ignored if grayscale)" << endl;
else
cout << "- color order: BGR (ignored if grayscale)" << endl;
// Load ORB parameters
// Step 2 加载ORB特征点有关的参数,并新建特征点提取器
// 每一帧提取的特征点数 1000
int nFeatures = fSettings["ORBextractor.nFeatures"];
// 图像建立金字塔时的变化尺度 1.2
float fScaleFactor = fSettings["ORBextractor.scaleFactor"];
// 尺度金字塔的层数 8
int nLevels = fSettings["ORBextractor.nLevels"];
// 提取fast特征点的默认阈值 20
int fIniThFAST = fSettings["ORBextractor.iniThFAST"];
// 如果默认阈值提取不出足够fast特征点,则使用最小阈值 8
int fMinThFAST = fSettings["ORBextractor.minThFAST"];
// !tracking过程都会用到mpORBextractorLeft作为特征点提取器
mpORBextractorLeft = new ORBextractor(
nFeatures, //参数的含义还是看上面的注释吧
fScaleFactor,
nLevels,
fIniThFAST,
fMinThFAST);
// 如果是双目,tracking过程中还会用用到mpORBextractorRight作为右目特征点提取器
if(sensor==System::STEREO)
mpORBextractorRight = new ORBextractor(nFeatures,fScaleFactor,nLevels,fIniThFAST,fMinThFAST);
// 在单目初始化的时候,会用mpIniORBextractor来作为特征点提取器
if(sensor==System::MONOCULAR)
mpIniORBextractor = new ORBextractor(2*nFeatures,fScaleFactor,nLevels,fIniThFAST,fMinThFAST);
cout << endl << "ORB Extractor Parameters: " << endl;
cout << "- Number of Features: " << nFeatures << endl;
cout << "- Scale Levels: " << nLevels << endl;
cout << "- Scale Factor: " << fScaleFactor << endl;
cout << "- Initial Fast Threshold: " << fIniThFAST << endl;
cout << "- Minimum Fast Threshold: " << fMinThFAST << endl;
if(sensor==System::STEREO || sensor==System::RGBD)
{
// 判断一个3D点远/近的阈值 mbf * 35 / fx
//ThDepth其实就是表示基线长度的多少倍
mThDepth = mbf*(float)fSettings["ThDepth"]/fx;
cout << endl << "Depth Threshold (Close/Far Points): " << mThDepth << endl;
}
if(sensor==System::RGBD)
{
// 深度相机disparity转化为depth时的因子
mDepthMapFactor = fSettings["DepthMapFactor"];
if(fabs(mDepthMapFactor)<1e-5)
mDepthMapFactor=1;
else
mDepthMapFactor = 1.0f/mDepthMapFactor;
}
} 东西比较多, 核心的地方是提取ORB特征点
mpORBextractorLeft = new ORBextractor(
nFeatures, //参数的含义还是看上面的注释吧
fScaleFactor,
nLevels,
fIniThFAST,
fMinThFAST);继续看它的构造函数。提取ORB特征点的时候使用图像金字塔使其具有尺度不变性,使用灰度质心法具有旋转不变性。
//存储每层图像缩放系数的vector调整为符合图层数目的大小
mvScaleFactor.resize(nlevels);
//存储这个sigma^2,其实就是每层图像相对初始图像缩放因子的平方
mvLevelSigma2.resize(nlevels);
//对于初始图像,这两个参数都是1
mvScaleFactor[0]=1.0f;
mvLevelSigma2[0]=1.0f;
//然后逐层计算图像金字塔中图像相当于初始图像的缩放系数
for(int i=1; i公式推导:
设第0层面积(像素个数)为S0,每层的缩放因子s(小于1),总面积S为
![]()
每次提取的特征点数量是 N,那么单位面积提取的特征点数量为
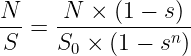
因此第0层提取到的特征点为:

第x层提取到的特征点为:

总结: 每一层提取的特征点数量 = 前一层提取到的数量 X 缩放因子s
然后读取描述子256对点放到pattren中(读取描述子坐标)
//成员变量pattern的长度,也就是点的个数,这里的512表示512个点
const int npoints = 512;
//获取用于计算BRIEF描述子的随机采样点点集头指针
//注意到pattern0数据类型为Points*,bit_pattern_31_是int[]型,所以这里需要进行强制类型转换
const Point *pattern0 = (const Point *)bit_pattern_31_; //bit_pattern_31_就是存放描述子的大数组
//使用std::back_inserter的目的是可以快覆盖掉这个容器pattern之前的数据
//其实这里的操作就是,将在全局变量区域的、int格式的随机采样点以cv::point格式复制到当前类对象中的成员变量中(关键)
std::copy(pattern0, pattern0 + npoints, std::back_inserter(pattern)); //pattern是类ORBextractor的成员变量
这里参考 描述子提取过程 ,bit_pattern_31_ 这个数组里有256行
BRIEF描述子由32* 8位 组成,每一位都是两个像素点(一行)比较像素的结果,每比较一个8bit需要8行的点。
以bit_pattern_31_第一行为例(8 -3 9 5),以某个特征点为中心,构建一个31*31的块,比较(8,-3)和(9,5)这两个地方的像素,大于的话记为1,反之记为0,然后比较8行得到第一组的描述子,继续比较得到32*8的描述子。
计算灰度质心法圆形区域边界
//This is for orientation
//下面的内容是和特征点的旋转计算有关的
//预先计算圆形patch中行的结束位置
//+1中的1表示那个圆的中间行
umax.resize(HALF_PATCH_SIZE + 1);
//cvFloor返回不大于参数的最大整数值(向下取整),cvCeil返回不小于参数的最小整数值(向上取整),cvRound则是四舍五入
int v, //循环辅助变量
v0, //辅助变量
vmax = cvFloor(HALF_PATCH_SIZE * sqrt(2.f) / 2 + 1); //计算圆的最大行号,+1应该是把中间行也给考虑进去了
//NOTICE 注意这里的最大行号指的是计算的时候的最大行号,此行的和圆的角点在45°圆心角的一边上,之所以这样选择
//是因为圆周上的对称特性
//这里的二分之根2就是对应那个45°圆心角
int vmin = cvCeil(HALF_PATCH_SIZE * sqrt(2.f) / 2);
//半径的平方
const double hp2 = HALF_PATCH_SIZE*HALF_PATCH_SIZE;
//利用圆的方程计算每行像素的u坐标边界(max)
for (v = 0; v <= vmax; ++v)
umax[v] = cvRound(sqrt(hp2 - v * v)); //结果都是大于0的结果,表示x坐标在这一行的边界
//这里其实是使用了对称的方式计算上四分之一的圆周上的umax,目的也是为了保持严格的对称(如果按照常规的想法做,由于cvRound就会很容易出现不对称的情况,
//同时这些随机采样的特征点集也不能够满足旋转之后的采样不变性了)
for (v = HALF_PATCH_SIZE, v0 = 0; v >= vmin; --v)
{
while (umax[v0] == umax[v0 + 1])
++v0;
umax[v] = v0;
++v0;
}
//!灰度质心法圆形建立完成关于ORB理论部分参考ORB理解
到这里Tracking.cc中的ORBextractor的构造函数结束,返回Tracking类的构造函数,后续内容是针对双目和RGB-D相机的一些操作,这里先跳过,结束Tracking类的构造函数,返回System.cc中继续执行下一线程。
*************************************************
⑧初始化线程LocalMapping 线程
⑨初始化线程Loop线程
⑩初始化线程View线程
⑪不同的线程之间设置指针
TODO:第八步到第十一步的内容先跳过。
************************************************
此时System.cc的构造函数也结束了,返回到mono_kitti.cc.完成了实例化一个叫SLAM的System对象。
step3 读取图片 + 处理
main()函数继续执行一个for()循环
for (int ni = 0; ni < nImages; ni++)
{……}这个循环中读取每张图片对应的时间戳,之后SLAM对象的成员函数TrackMonocular将图片和时间戳传给Tracking线程
//图片
im = cv::imread(vstrImageFilenames[ni],CV_LOAD_IMAGE_UNCHANGED);
//时间戳
double tframe = vTimestamps[ni];
SLAM.TrackMonocular(im,tframe);TrackMonocular函数是System类的成员函数,再次进入到System.cc
这个函数先是对传感器进行检测,然后是检查是否更换模式、检查是否需要复位,之后进入位姿估计环节
//获取相机位姿的估计结果
//!通过输入图片和时间戳获取位姿结果
cv::Mat Tcw = mpTracker->GrabImageMonocular(im,timestamp);类指针mpTracker使用GrabImageMonocular函数,这个函数输入左目或者RGBA图像,输出世界坐标系到该帧相机坐标系的变换矩阵
继续看它是如何实现的,主要分为三部分:
第一步 将彩色图像转为灰度图像 cvtColor
第二步 构造Frame , 通过一个if 语句实现,如果为真,该帧没用初始化,需要提取两倍的特征点进行初始化;反之,提取指定的特征点。不管真假,都实例化了一个类对象mCurrentFrame,需要看Frame的构造函数。
它的构造函数分为五部分(step1-step5)
step1: nNextId是静态成员变量
// Step 1 帧的ID 自增
mnId=nNextId++;step2:计算图像金字塔的参数,通过mpORBextractorLeft类指针获取的,前面构建图像金字塔的时候已经计算过
step3:对这个单目图像进行提取特征点,
提取图像的ORB特征点,提取的关键点存放在mvKeys,描述子存放在mDescriptors
ExtractORB(0,imGray);通过这个函数实现ORB特征点的提取 (重点),它的实现也在Frame.cc
void Frame::ExtractORB(int flag, const cv::Mat &im)
{
// 判断是左图还是右图
if(flag==0)
// 左图的话就套使用左图指定的特征点提取器,并将提取结果保存到对应的变量中
// 这里使用了仿函数来完成,重载了括号运算符 ORBextractor::operator()
(*mpORBextractorLeft)(im, //待提取特征点的图像
cv::Mat(), //掩摸图像, 实际没有用到
mvKeys, //输出变量,用于保存提取后的特征点
mDescriptors); //输出变量,用于保存特征点的描述子
else
// 右图的话就需要使用右图指定的特征点提取器,并将提取结果保存到对应的变量中
(*mpORBextractorRight)(im,cv::Mat(),mvKeysRight,mDescriptorsRight);
}*mpORBextractorLeft是ORBextractor的类指针,这里对括号运算符进行了重载
先看这个仿函数是如何实现的,
void ORBextractor::operator()( InputArray _image, InputArray _mask, vector& _keypoints,
OutputArray _descriptors)
{
// Step 1 检查图像有效性。如果图像为空,那么就直接返回
if(_image.empty())
return;
//获取图像的大小
Mat image = _image.getMat();
//判断图像的格式是否正确,要求是单通道灰度值
assert(image.type() == CV_8UC1 );
// Pre-compute the scale pyramid
// Step 2 构建图像金字塔
ComputePyramid(image);
这里调用了ComputePyramid函数来构建图像金字塔,也是类ORBextractor的一个成员函数,
为什么要对图片扩展:使用FAST提取特征点时,以像素点为圆心,取半径为3的圆,但是对于边界线上的点无法得到一个完整的圆,因此需要对原始图像扩展三个像素的边界。其次图像要进行高斯滤波(消除噪声),扩展了EDGE_THRESHOLD的边界
/**
* 构建图像金字塔
* @param image 输入原图像,这个输入图像所有像素都是有效的,也就是说都是可以在其上提取出FAST角点的
*/
void ORBextractor::ComputePyramid(cv::Mat image)
{
//开始遍历所有的图层
for (int level = 0; level < nlevels; ++level)
{
//获取本层图像的缩放系数
// 1, 0.833333, 0.694444, 0.578704, 0.482253, 0.401878, 0.334898, 0.279082
float scale = mvInvScaleFactor[level];
//计算本层图像的像素尺寸大小
// [640 x 480], [533 x 400], [444 x 333], [370 x 278], [309 x 231], [257 x 193], [214 x 161], [179 x 134]
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
//全尺寸图像。包括无效图像区域的大小。将图像进行“补边”,EDGE_THRESHOLD区域外的图像不进行FAST角点检测
//[678 x 518], [571 x 438], [482 x 371], [408 x 316], [347 x 269], [295 x 231], [252 x 199], [217 x 172]
Size wholeSize(sz.width + EDGE_THRESHOLD*2, sz.height + EDGE_THRESHOLD*2);
// 定义了两个变量:temp是扩展了边界的图像,masktemp并未使用
Mat temp(wholeSize, image.type()), masktemp;
// mvImagePyramid 刚开始时是个空的vector
// 把图像金字塔该图层的图像指针mvImagePyramid指向temp的中间部分(这里为浅拷贝,内存相同)
mvImagePyramid[level] = temp(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height));
// Compute the resized image
//计算第0层以上resize后的图像
if( level != 0 )
{
//将上一层金字塔图像根据设定sz缩放到当前层级
resize(mvImagePyramid[level-1], //输入图像
mvImagePyramid[level], //输出图像
sz, //输出图像的尺寸
0, //水平方向上的缩放系数,留0表示自动计算
0, //垂直方向上的缩放系数,留0表示自动计算
cv::INTER_LINEAR); //图像缩放的差值算法类型,这里的是线性插值算法
// //! 原代码mvImagePyramid 并未扩充,上面resize应该改为如下
// resize(image, //输入图像
// mvImagePyramid[level], //输出图像
// sz, //输出图像的尺寸
// 0, //水平方向上的缩放系数,留0表示自动计算
// 0, //垂直方向上的缩放系数,留0表示自动计算
// cv::INTER_LINEAR); //图像缩放的差值算法类型,这里的是线性插值算法
//把源图像拷贝到目的图像的中央,四面填充指定的像素。图片如果已经拷贝到中间,只填充边界
//这样做是为了能够正确提取边界的FAST角点
//EDGE_THRESHOLD指的这个边界的宽度,由于这个边界之外的像素不是原图像素而是算法生成出来的,所以不能够在EDGE_THRESHOLD之外提取特征点
copyMakeBorder(mvImagePyramid[level], //源图像
temp, //目标图像(此时其实就已经有大了一圈的尺寸了)
EDGE_THRESHOLD, EDGE_THRESHOLD, //top & bottom 需要扩展的border大小
EDGE_THRESHOLD, EDGE_THRESHOLD, //left & right 需要扩展的border大小
BORDER_REFLECT_101+BORDER_ISOLATED); //扩充方式,opencv给出的解释:
/*Various border types, image boundaries are denoted with '|'
* BORDER_REPLICATE: aaaaaa|abcdefgh|hhhhhhh
* BORDER_REFLECT: fedcba|abcdefgh|hgfedcb
* BORDER_REFLECT_101: gfedcb|abcdefgh|gfedcba
* BORDER_WRAP: cdefgh|abcdefgh|abcdefg
* BORDER_CONSTANT: iiiiii|abcdefgh|iiiiiii with some specified 'i'
*/
//BORDER_ISOLATED 表示对整个图像进行操作
// https://docs.opencv.org/3.4.4/d2/de8/group__core__array.html#ga2ac1049c2c3dd25c2b41bffe17658a36
}
else
{
//对于第0层未缩放图像,直接将图像深拷贝到temp的中间,并且对其周围进行边界扩展。此时temp就是对原图扩展后的图像
copyMakeBorder(image, //这里是原图像
temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101);
}
// //! 原代码mvImagePyramid 并未扩充,应该添加下面一行代码
// mvImagePyramid[level] = temp;
}
} sz 存储了本层图像的大小,就是原始图像在不同层的大小
wholeSize存储了一个扩充后的图像大小
temp是扩展了边界的图像
resize将原始图像Image安装sz的大小以线性压缩的形式压缩到mvImagePyramid[level]中
之后需要使用copyMakerBorder函数填充压缩后图像周围扩充区域的像素
到这里图像金字塔建立完成,保存到mvImagePyramid[level]中,继续看这个仿函数代码。
// Step 3 计算图像的特征点,并且将特征点进行均匀化。均匀的特征点可以提高位姿计算精度
// 存储所有的特征点,注意此处为二维的vector,第一维存储的是金字塔的层数,第二维存储的是那一层金字塔图像里提取的所有特征点
vector < vector > allKeypoints;
//使用四叉树的方式计算每层图像的特征点并进行分配
ComputeKeyPointsOctTree(allKeypoints); 计算图像的特征点,并且将特征点进行均匀化。
先计算特征点(TODO这里关于网格的概念不是很理解)
注意:图像边界是 (minBorderX,minBorderY) 和 (maxBorderX,maxBorderY)两个点围成的矩形区域,也就是扩展了三个像素的图像大小。
这里对 四周扩充了三个像素的图像 划分30*30的网格,然后在网格上提取特征点.
width和height扩充三个像素图片的宽度和高度
nCols 就是扩充三个像素后图像每行有多少网格,nRows同理
wCell是每行网格占了多少像素,wCell同理,前面定义是每个网格占30像素,但图片宽高不一定是30倍数。
void ORBextractor::ComputeKeyPointsOctTree(
vector >& allKeypoints) //所有的特征点,这里第一层vector存储的是某图层里面的所有特征点,
//第二层存储的是整个图像金字塔中的所有图层里面的所有特征点
{
//重新调整图像层数
allKeypoints.resize(nlevels);
//图像cell的尺寸,是个正方形,可以理解为边长in像素坐标
const float W = 30;
// 对每一层图像做处理
//遍历所有图像
for (int level = 0; level < nlevels; ++level)
{
//计算这层图像的坐标边界, NOTICE 注意这里是坐标边界,EDGE_THRESHOLD指的应该是可以提取特征点的有效图像边界,后面会一直使用“有效图像边界“这个自创名词
const int minBorderX = EDGE_THRESHOLD-3; //这里的3是因为在计算FAST特征点的时候,需要建立一个半径为3的圆
const int minBorderY = minBorderX; //minY的计算就可以直接拷贝上面的计算结果了
const int maxBorderX = mvImagePyramid[level].cols-EDGE_THRESHOLD+3;
const int maxBorderY = mvImagePyramid[level].rows-EDGE_THRESHOLD+3;
//存储需要进行平均分配的特征点
vector vToDistributeKeys;
//一般地都是过量采集,所以这里预分配的空间大小是nfeatures*10
vToDistributeKeys.reserve(nfeatures*10);
//计算进行特征点提取的图像区域尺寸 这里的widt和height是上下左右各扩充了三个像素的大小
const float width = (maxBorderX-minBorderX);
const float height = (maxBorderY-minBorderY);
//nCols 就是扩充三个像素后图像每行有多少网格,nRows同理
const int nCols = width/W;
const int nRows = height/W;
//计算每个图像网格所占的像素行数和列数 ,网格行列一定是大于等于30的
const int wCell = ceil(width/nCols); //ceil向上取整
const int hCell = ceil(height/nRows);
通过上面计算知道了扩充三个像素的图像由多少个网格
然后遍历网格:(先行后列)
//开始遍历图像网格,还是以 行 开始遍历的
for(int i=0; i=maxBorderY-3)
//那么就跳过这一行
continue;
//如果图像的大小导致不能够正好划分出来整齐的图像网格,那么就要委屈最后一行了
if(maxY>maxBorderY)
maxY = maxBorderY;
//开始 列 的遍历
for(int j=0; j=maxBorderX-6)
continue;
//如果最大坐标越界那么委屈一下
if(maxX>maxBorderX)
maxX = maxBorderX;
// FAST提取兴趣点, 自适应阈值
//这个向量存储这个cell中的特征点
vector vKeysCell;
//调用opencv的库函数来检测FAST角点
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX), //待检测的图像, 某层金字塔扩充了三个像素后图片的大小
vKeysCell, //存储角点位置的容器
iniThFAST, //检测阈值
true); //使能非极大值抑制
//如果这个图像块中使用默认的FAST检测阈值没有能够检测到角点
if(vKeysCell.empty())
{
//那么就使用更低的阈值来进行重新检测
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX), //待检测的图像
vKeysCell, //存储角点位置的容器
minThFAST, //更低的检测阈值
true); //使能非极大值抑制
}
//当图像cell中检测到FAST角点的时候执行下面的语句
if(!vKeysCell.empty())
{
//遍历其中的所有FAST角点
for(vector::iterator vit=vKeysCell.begin(); vit!=vKeysCell.end();vit++)
{
//NOTICE 到目前为止,这些角点的坐标都是基于图像cell的,现在我们要先将其恢复到当前的【坐标边界】下的坐标
//这样做是因为在下面使用八叉树法整理特征点的时候将会使用得到这个坐标
//在后面将会被继续转换成为在当前图层的扩充图像坐标系下的坐标
//!vKeysCell提取出来的特征点坐标并不是原始图像的坐标
(*vit).pt.x+=j*wCell;
(*vit).pt.y+=i*hCell;
//然后将其加入到”等待被分配“的特征点容器中
vToDistributeKeys.push_back(*vit);
}//遍历图像cell中的所有的提取出来的FAST角点,并且恢复其在整个金字塔当前层图像下的坐标
}//当图像cell中检测到FAST角点的时候执行下面的语句
}//开始遍历图像cell的列
}//开始遍历图像cell的行 先进行行遍历(Y轴),计算网格的初始坐标iniY,然后计算最大的坐标maxY,之后对行也需要进行同样的操作。
上面代码中使用opencv提供的FAST函数:
//调用opencv的库函数来检测FAST角点
FAST(mvImagePyramid[level].rowRange(iniY, maxY).colRange(iniX, maxX), //待检测的图像,这里就是当前遍历到的图像块
vKeysCell, //存储角点位置的容器
iniThFAST, //一般情况下检测阈值
true); //使能非极大值抑制
将提取到的结果放到容器vKeyCell中,如果没用提取到特征点,会改变阈值(minThFAST)的大小再次使用该函数。
之后需要对vKeyCell中的特征点进行坐标调整,因为这个容器中每个坐标都是以取到的那个网格的左上角为原点,调整坐标后放到容器vToDistributekeys

假如第二个红色网格中有一关键点(x,y),该关键点是以第二个网格坐上角为原点的, 需要将坐标变换到以第一个网格左上角为原点
此时 i=0,j=1 变换后的坐标是 x=x+j*wCell=x+wCell , y = y+i*hCwell=y
如果理解错了,请大家评论区留言下
//当图像cell中检测到FAST角点的时候执行下面的语句
if(!vKeysCell.empty())
{
//遍历其中的所有FAST角点
for(vector::iterator vit=vKeysCell.begin(); vit!=vKeysCell.end();vit++)
{
//NOTICE 到目前为止,这些角点的坐标都是基于图像cell的,现在我们要先将其恢复到当前的【坐标边界】下的坐标
//这样做是因为在下面使用八叉树法整理特征点的时候将会使用得到这个坐标
//在后面将会被继续转换成为在当前图层的扩充图像坐标系下的坐标
//!vKeysCell提取出来的特征点坐标并不是原始图像的坐标
(*vit).pt.x+=j*wCell;
(*vit).pt.y+=i*hCell;
//然后将其加入到”等待被分配“的特征点容器中
vToDistributeKeys.push_back(*vit);
}//遍历图像cell中的所有的提取出来的FAST角点,并且恢复其在整个金字塔当前层图像下的坐标
}//当图像cell中检测到FAST角点的时候执行下面的语句 然后进行四叉树筛选特征点,调用DistributeOctTree
可以先去看看四叉树分配特征点的原理
使用四叉树法对一个图像金字塔图层中的特征点进行平均和分发
keypoints = DistributeOctTree(vToDistributeKeys, //当前图层提取出来的特征点,也即是等待剔除的特征点
//NOTICE 注意此时特征点所使用的坐标都是在“半径扩充图像”下的
minBorderX, maxBorderX, //当前图层图像的边界,而这里的坐标却都是在“边缘扩充图像”下的
minBorderY, maxBorderY,
mnFeaturesPerLevel[level], //希望保留下来的当前层图像的特征点个数
level); //当前层图像所在的图层节点分配顺序:后加的先分配。比如先分配下图在第19个节点
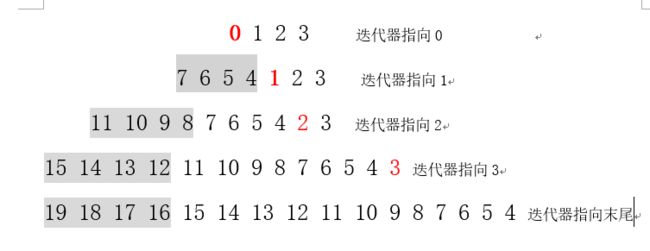
到这里特征点的提取与分配就完成了,后续是对特征点计算方向,调用computeOrientation
// compute orientations
//然后计算这些特征点的方向信息,注意这里还是分层计算的
for (int level = 0; level < nlevels; ++level)
computeOrientation(mvImagePyramid[level], //对应的图层的图像
allKeypoints[level], //这个图层中提取并保留下来的特征点容器
umax); //以及PATCH的横坐标边界为每个特征点计算了角度,使其具有旋转不变性。
继续ORBextractor.cc看仿函数代码
进行描述子的计算,
// Step 4 拷贝图像描述子到新的矩阵descriptors
Mat descriptors;
//统计整个图像金字塔中的特征点
int nkeypoints = 0;
//开始遍历每层图像金字塔,并且累加每层的特征点个数
for (int level = 0; level < nlevels; ++level)
nkeypoints += (int)allKeypoints[level].size();
//如果本图像金字塔中没有任何的特征点
if( nkeypoints == 0 )
//通过调用cv::mat类的.realse方法,强制清空矩阵的引用计数,这样就可以强制释放矩阵的数据了
//参考[https://blog.csdn.net/giantchen547792075/article/details/9107877]
_descriptors.release();
else
{
//如果图像金字塔中有特征点,那么就创建这个存储描述子的矩阵,注意这个矩阵是存储整个图像金字塔中特征点的描述子的
_descriptors.create(nkeypoints, //矩阵的行数,对应为特征点的总个数
32, //矩阵的列数,对应为使用32*8=256位描述子
CV_8U); //矩阵元素的格式
//获取这个描述子的矩阵信息
// ?为什么不是直接在参数_descriptors上对矩阵内容进行修改,而是重新新建了一个变量,复制矩阵后,在这个新建变量的基础上进行修改?
descriptors = _descriptors.getMat();
}
//清空用作返回特征点提取结果的vector容器
_keypoints.clear();
//并预分配正确大小的空间
_keypoints.reserve(nkeypoints);
//因为遍历是一层一层进行的,但是描述子那个矩阵是存储整个图像金字塔中特征点的描述子,所以在这里设置了Offset变量来保存“寻址”时的偏移量,
//辅助进行在总描述子mat中的定位
int offset = 0;
//开始遍历每一层图像
for (int level = 0; level < nlevels; ++level)
{
//获取在allKeypoints中当前层特征点容器的句柄
vector& keypoints = allKeypoints[level];
//本层的特征点数
int nkeypointsLevel = (int)keypoints.size();
//如果特征点数目为0,跳出本次循环,继续下一层金字塔
if(nkeypointsLevel==0)
continue; 然后进行高斯滤波,并且计算高斯滤波后的描述子。
使用GaussianBlur函数消除图像噪声,防止锐利的像素影响描述子的计算。
// Step 5 对图像进行高斯模糊
// 深拷贝当前金字塔所在层级的图像
Mat workingMat = mvImagePyramid[level].clone();
// 注意:提取特征点的时候,使用的是清晰的原图像;这里计算描述子的时候,为了避免图像噪声的影响,使用了高斯模糊
GaussianBlur(workingMat, //源图像
workingMat, //输出图像
Size(7, 7), //高斯滤波器kernel大小,必须为正的奇数
2, //高斯滤波在x方向的标准差
2, //高斯滤波在y方向的标准差
BORDER_REFLECT_101);//边缘拓展点插值类型
// Compute the descriptors 计算描述子
// desc存储当前图层的描述子
Mat desc = descriptors.rowRange(offset, offset + nkeypointsLevel);
// Step 6 计算高斯模糊后图像的描述子
computeDescriptors(workingMat, //高斯模糊之后的图层图像
keypoints, //当前图层中的特征点集合
desc, //存储计算之后的描述子
pattern); //随机采样模板
// 更新偏移量的值
offset += nkeypointsLevel;
// Scale keypoint coordinates
// Step 6 对非第0层图像中的特征点的坐标恢复到第0层图像(原图像)的坐标系下
// ? 得到所有层特征点在第0层里的坐标放到_keypoints里面
// 对于第0层的图像特征点,他们的坐标就不需要再进行恢复了
if (level != 0)
{
// 获取当前图层上的缩放系数
float scale = mvScaleFactor[level];
// 遍历本层所有的特征点
for (vector::iterator keypoint = keypoints.begin(),
keypointEnd = keypoints.end(); keypoint != keypointEnd; ++keypoint)
// 特征点本身直接乘缩放倍数就可以了
keypoint->pt *= scale;
}
// And add the keypoints to the output
// 将keypoints中内容插入到_keypoints 的末尾
// keypoint其实是对allkeypoints中每层图像中特征点的引用,这样allkeypoints中的所有特征点在这里被转存到输出的_keypoints
_keypoints.insert(_keypoints.end(), keypoints.begin(), keypoints.end());
} 使用computeDescriptors函数计算描述子,desc是计算的结果
computeDescriptors(workingMat, //高斯模糊之后的图层图像
keypoints, //当前图层中的特征点集合
desc, //存储计算之后的描述子
pattern); //随机采样模板
总结:到这里仿函数代码就结束了,通过重载括号运算符计算了每层图像的特征点,并把它们均匀分步,最后计算了对应的描述子。
Frame.cc 中的 ExtractORB(0,imGray) 结束。
step4:用OpenCV的矫正函数、内参对提取到的特征点进行矫正
UndistortKeyPoints();
// Set no stereo information
// 由于单目相机无法直接获得立体信息,所以这里要给右图像对应点和深度赋值-1表示没有相关信息
mvuRight = vector(N,-1);
mvDepth = vector(N,-1);
// 初始化本帧的地图点
mvpMapPoints = vector(N,static_cast(NULL));
// 记录地图点是否为外点,初始化均为外点false
mvbOutlier = vector(N,false); 重点看UndistortKeyPoints这个函数,函数中调用opencv的undistortPoints函数
cv::undistortPoints(
mat, //输入的特征点坐标
mat, //输出的校正后的特征点坐标覆盖原矩阵
mK, //相机的内参数矩阵
mDistCoef, //相机畸变参数矩阵
cv::Mat(), //一个空矩阵,对应为函数原型中的R
mK); //新内参数矩阵,对应为函数原型中的Pstep5: 计算去畸变后图像边界,将特征点分配到网格中。这个过程一般是在第一帧或者是相机标定参数发生变化之后进行。
Tracking.cc中的Frame构造函数执行结束。
第三步 跟踪 这个函数的返回的结果是 世界坐标系到该帧相机坐标系的变换矩阵
Track();
//返回当前帧的位姿
return mCurrentFrame.mTcw.clone()*********************
TODO :关于Track函数的具体实现先跳过
追踪线程是ORB-SLAM2的三个线程之一,下一篇文章中会重点介绍。这里先了解下这个线程实现的大概流程:
1.地图初始化,单目初始化和 双目、RGB-D相机不同
2.初始化完成后进入相机跟踪,主要由三种跟踪方式
3.相机跟踪成功后对局部地图进行跟踪,这里需要特征匹配得到更多地图点,也要优化相机位姿
4.更新显示线程中的图像、特征点、地图点等信息
5.跟踪成功,更新恒速运动模型
6.清除观测不到的地图点
7.清除恒速模型跟踪中 UpdateLastFrame中为当前帧临时添加的MapPoints(仅双目和rgbd)
8..对当前帧进行判断是否可以作为关键帧
9.删除BA优化中的外点
10.如果初始化和重定位都失败,需要reset
*******************
到这里 mpTracker->GrabImageMonocular(im,timestamp) 这个函数执行完成,之后会返回计算的位姿结果Tcw。
mono_kitti.cc中的SLAM.TrackMonocular(im,tframe)结束。
step4 Shutdown 关闭SLAM系统
主要是对局部地图和回环线程发生终止请求
SLAM.Shutdown();step5 计算跟踪图片时间的中位数和平均值
cout << "median tracking time: " << vTimesTrack[nImages/2] << endl;
cout << "mean tracking time: " << totaltime/nImages << endl;step6 保存相机轨迹 KeyFrameTrajectory.txt
SLAM.SaveKeyFrameTrajectoryTUM("KeyFrameTrajectory.txt"); 参考:(1条消息) ORB-SLAM2:Tracking线程学习随笔【李哈哈:看看总有收获篇】_正在刷夜的李哈哈的博客-CSDN博客 https://blog.csdn.net/qq_41883714/article/details/114655311?spm=1001.2014.3001.5502(1条消息) 一步步带你看懂orbslam2源码--总体框架(一)_Mr.Silver的博客-CSDN博客_orbslam2框架https://blog.csdn.net/qq_37708045/article/details/101751343
https://blog.csdn.net/qq_41883714/article/details/114655311?spm=1001.2014.3001.5502(1条消息) 一步步带你看懂orbslam2源码--总体框架(一)_Mr.Silver的博客-CSDN博客_orbslam2框架https://blog.csdn.net/qq_37708045/article/details/101751343