ElasticSearch - 映射(mapping)
官方文档
一、数据类型
1、核心数据类型
- string 字符串
| 字符类型 | 说明 |
|---|---|
| text | ⽤于全⽂索引,搜索时会自动使用分词器进⾏分词再匹配。字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项 |
| keyword | 不分词,搜索时需要匹配完整的值 |
- numberic 数值
| 整数类型 | 说明 (1byte(字节)=8bit(位、比特)) |
|---|---|
| byte | (1字节)-128 到127(- 2^7 到 2^7– 1) |
| short | (2字节)-32,768到32,767 (- 2^15 到 2^15– 1) |
| integer | (4字节)-2,147,483,648到2,147,483,647 (- 2^31 到 2^31– 1) |
| long | (8字节)(- 2^63 到 2^63– 1) |
| 浮点类型 | 说明 |
|---|---|
| float | 32位单精度IEEE 754浮点类型 |
| double | 64位双精度IEEE 754浮点类型 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数(比如价格只需要精确到分,price为57.34的字段缩放因子为100,存起来就是5734) |
- 日期类型
| 类型 | 说明 |
|---|---|
| date | date类型支持到毫秒 参考 |
| date_nanos | date类型支持到纳秒 参考 |
- Boolean
| 类型 | 说明 |
|---|---|
| boolean | true/false |
- binary 二进制
| 类型 | 说明 |
|---|---|
| binary | 该binary类型接受二进制值作为 Base64编码的字符串 |
- range 范围
| 范围类型 | 说明 |
|---|---|
| integer_range | 一个带符号的32位整数范围,最小值为,最大值为。 -2^31到 2^31-1 |
| float_range | 一系列单精度32位IEEE 754浮点值 |
| long_range | 一系列带符号的64位整数,最小值为,最大值为。 -2^63 到 2^63-1 |
| double_range | 一系列双精度64位IEEE 754浮点值 |
| date_range | 自系统时代以来经过的一系列日期值,表示为无符号的64位整数毫秒 |
| ip_range | 支持IPv4或 IPv6(或混合)地址的一系列ip值 |
2、复杂数据类型
- object 对象
| 对象类型 | 说明 |
|---|---|
| object | 对象,用于单个JSON对象 |
由于 JSON 本身具有层级关系,所以文档包含内部对象。内部对象中,还可以再包含内部对象。
PUT product/_doc/2
{
"date":"2020-11-11T11:11:11Z",
"ext_info":{
"address":"China"
}
}
- nested 嵌套
| 对象类型 | 说明 |
|---|---|
| array | 嵌套JSON对象数组 参考 |
nested 是 object 中的一个特例。
如果使用 object 类型,假如有如下一个文档:
{
"user":[
{
"first":"Zhang",
"last":"san"
},
{
"first":"Li",
"last":"si"
}
]
}
由于 Lucene 没有内部对象的概念,所以 es 会将对象层次扁平化,将一个对象转为字段名和值构成的简单列表。即上面的文档,最终存储形式如下:
{
"user.first":["Zhang","Li"],
"user.last":["san","si"]
}
扁平化之后,用户名之间的关系没了。这样会导致如果搜索 Zhang si 这个人,会搜索到。
此时可以 nested 类型来解决问题,nested 对象类型可以保持数组中每个对象的独立性。nested 类型将数组中的每一对象作为独立隐藏文档来索引,这样每一个嵌套对象都可以独立被索引。
{
{
"user.first":"Zhang",
"user.last":"san"
},{
"user.first":"Li",
"user.last":"si"
}
}
3、地图数据类型
- Geo-point 地理位置数据(纬度-经度)
| 地理位置数据类型 | 说明 |
|---|---|
| geo_point | geo_point为纬度/经度点 参考 |
- Geo-shape 地理形状数据类型
| 地理形状数据类型 | 说明 |
|---|---|
| geo_shape | geo_shape支持存储的常用形状数据有:点(point)圆形(circle)矩形(envelope)多边形 (polygon) 参考 |
4、专用的数据类型
| 专用的数据类型 | 说明 |
|---|---|
| ip | ip用于IPv4和IPv6地址 |
| Completion data type | 提供自动完成建议 |
| Token count | 计算字符串中令牌的数量 |
| mapper-murmur3 | 在索引时计算值的哈希并将其存储在索引中 |
| mapper-annotated-text | annotated-text 索引包含特殊标记的文本(通常用于标识命名实体) |
| Percolator | 接受来自query-dsl的查询 |
| Join | 为同一索引内的文档定义父/子关系 |
| Rank feature | 记录数字功能以提高查询时的点击率 |
| Rank features | 记录数字功能以提高查询时的点击率 |
| Dense vector | 记录浮点值的密集向量 |
| Sparse vector | 记录浮点值的稀疏向量 |
| Search-as-you-type | 针对查询进行优化的类文本字段,以实现按需输入完成 |
| Alias | 为现有字段定义别名。 |
| Flattened | Allows an entire JSON object to be indexed as a single field |
| Shape | shape 对于任意笛卡尔几何 |
| Histogram | histogram 用于百分位数聚合的预聚合数值。 |
| Constant keyword | keyword当所有文档具有相同值时的情况的 专业化。 |
二、映射(Mapping)
Mapping 类似于数据库中的表结构定义 schema
1、动态映射(Dynamic Mapping)
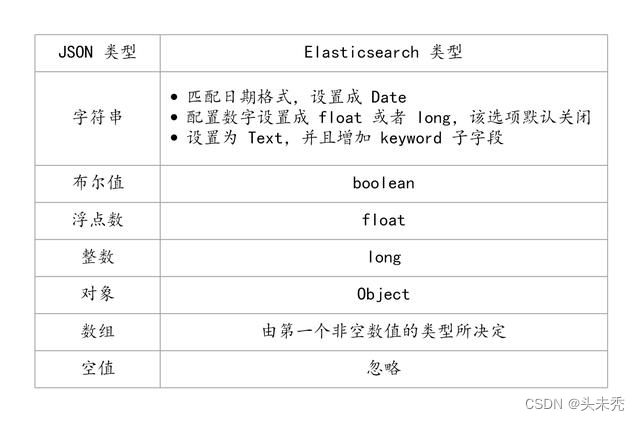
Dynamic Mapping 机制使我们不需要手动定义 Mapping,ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示:
当我们在创建一个索引的时候,可以对 dynamic 进行设置,可以设成 false、true 或者 strict。
- true:遇到陌生字段,就进行dynamic mapping
- false:遇到陌生字段,就忽略
- strict:遇到陌生字段,就报错
PUT /my_index
{
"mappings": {
"dynamic": "strict", #设置了strict,添加字段报错
"properties": {
"title": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": "true" #设置为true可以添加字段
}
}
}
}
PUT /my_index/_doc/1
{
"title": "my article",
"content": "this is my article", #添加新的字段
"address": {
"province": "guangdong",
"city": "guangzhou" #添加新的字段
}
}
#报错,content字段无法新增
{
"error": {
"root_cause": [
{
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [content] within [_doc] is not allowed"
}
],
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [content] within [_doc] is not allowed"
},
"status": 400
}
#成功,city、province字段可以新增
PUT /my_index/_doc/1
{
"title": "my article",
"address": {
"province": "guangdong",
"city": "guangzhou" #添加新的字段
}
}
#最后的映射
GET /my_index/_mapping
#返回数据
{
"my_index" : {
"mappings" : {
"dynamic" : "strict",
"properties" : {
"address" : {
"dynamic" : "true",
"properties" : {
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"province" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"title" : {
"type" : "text"
}
}
}
}
}
2、手动创建映射
ES 自动根据文档信息来判断字段合适的类型时,有时候也会推算的不对,比如地理位置信息有可能会判断为 Text,当类型如果设置不对时,会导致一些功能无法正常工作,比如 Range 查询,所以我们可以手动创建映射。
可以在需要在创建索引的时候先指定映射,这样就可以就可以避免自动创建映射导致字段类型不正确。
示例:
PUT /my_index
{
"mappings": {
"properties": {
"user": {
"properties": {
"title": {
"type": "text"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
},
"blogpost": {
"properties": {
"title": {
"type": "text"
},
"body": {
"type": "text"
},
"user_id": {
"type": "keyword"
},
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
}
}