《ICNet for Real-Time Semantic Segmentation on High-Resolution Images》论文阅读及代码实现
论文原文
https://arxiv.org/pdf/1704.08545.pdf
香港中文大学,腾讯优图,商汤科技联合发表的一篇用于语义分割的论文。
摘要
ICNet是一个基于PSPNet的实时语义分割网络,设计目的是减少PSPNet推断时期的耗时,论文对PSPNet做了深入分析,在PSPNet的基础上引入级联特征融合模块,实现快速且高质量的分割模型。论文报告了在Cityscape上的表现。
摘要
主要通过下面的图来表现:
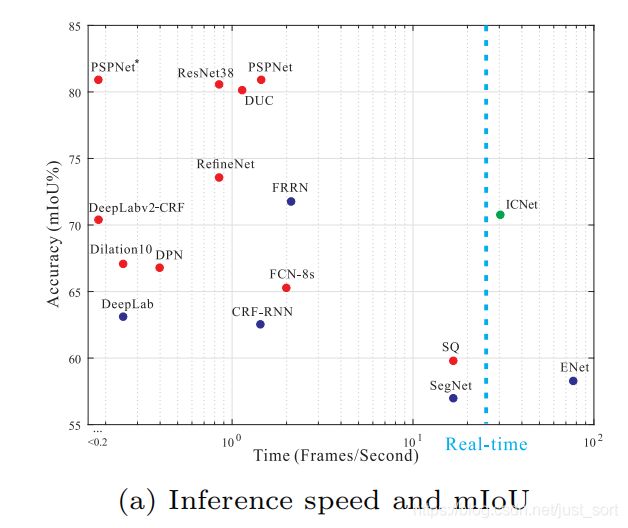 可以看到之前的许多分割的经典方法速度不快,而速度快的ENet的精度又不高,PSPNet在速度和精度找到了一个平衡点。论文的主要贡献在于:
可以看到之前的许多分割的经典方法速度不快,而速度快的ENet的精度又不高,PSPNet在速度和精度找到了一个平衡点。论文的主要贡献在于:
- 综合低分辨率的处理速度和高分辨率图像的推断质量,提出图像级联框架逐步细化分割预测
- ICNet可以在1024 × \times × 2048分辨率下保持30fps运行
相关工作
高质量的语义分割模型
先驱工作FCN将全连接层换成卷积层;DeepLab等使用空洞卷积(dilated convolution);Encoder-Decoder结构融合高层的语义和底层的细节;也有使用CRG,MRF模拟空间关系;PSPNet采用空间上的金字塔池化结构。这些方法对于提升性能有效,但不能用于实时系统。
快速的语义分割模型
SegNet放弃层信息来提速;ENet是一个轻量级网络,这些方法虽然快,但是性能差。
视频分割模型
视频中包含大量冗余信息,可利用减少计算量。
PSPNet给出了一个快读的语义分割的层次结构,利用级联图像作为输入加速推理,构建一个实时分割系统。
时间分析
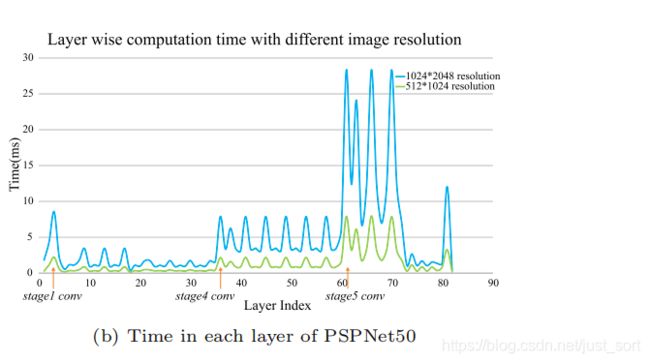 蓝色的分辨率为1024 × \times × 2048,绿色的分辨率为512 × \times × 512。上图显示了多个信息:
蓝色的分辨率为1024 × \times × 2048,绿色的分辨率为512 × \times × 512。上图显示了多个信息:
- 不同分辨率下的速度差异很大,呈平方趋势增加
- 网络的宽度越大速度越慢
- 核数量越多速度越慢
加速策略
输入降采样
根据上面的分析,半分辨率的推断时间为全分辨率的1/4。测试不同分辨率下输入下的预测情况。一个简单的测试方法使用1/2,1/4的输入,将输出上采样回原来的大小。实验如下:
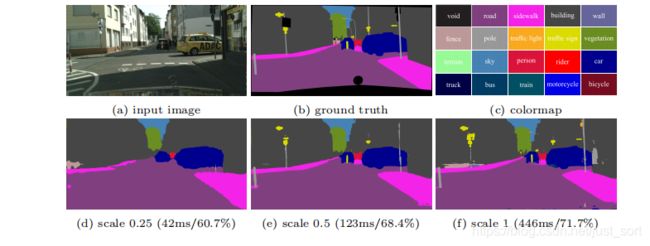 对比在不同缩放比例下得到的结果可以发现,在缩放比例为0.25的情况下,虽然推断时间大大减短,但是预测结果非常粗糙,丢失了很多小但是重要的细节。缩放0.5相对来说好了很多,但丢失了很多细节,并且最麻烦的是推理速度达不到实时要求了。
对比在不同缩放比例下得到的结果可以发现,在缩放比例为0.25的情况下,虽然推断时间大大减短,但是预测结果非常粗糙,丢失了很多小但是重要的细节。缩放0.5相对来说好了很多,但丢失了很多细节,并且最麻烦的是推理速度达不到实时要求了。
特征降采样
输入能降采样,自然特征也可以降采样。这里以1:8,1:16,1:32的比例测试PSPNet50,结果如下: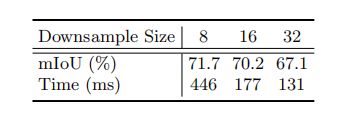 较小的特征图可以以牺牲准确度换取更快的推断,但考虑到使用1:32(132ms)依然达不到实时要求。
较小的特征图可以以牺牲准确度换取更快的推断,但考虑到使用1:32(132ms)依然达不到实时要求。
模型压缩
减少网络的复杂度,有一个直接的方法就是修正每层的核数量,论文测试了一些有效的模型压缩策略。即使只保留四分之一的核,推断时间还是很长。并且准确率大大降低了。
ICNet的结构
ICNet在总结了上面的加速策略后,提出了一个综合性的方法:使用低分辨率加速捕捉语义,使用高分辨率获取细节,使用级联网络结合,在限制的时间内获得有效的结果。模型结构如下:
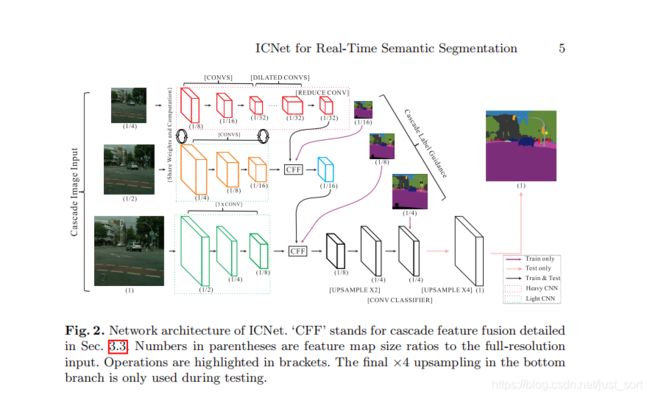 图片分为1,1/2,1/4这3个尺度分三路送到模型中。3个分支介绍如下:
图片分为1,1/2,1/4这3个尺度分三路送到模型中。3个分支介绍如下:
- 对于第一个1/4分支,可以看到经过3次卷积(下采样)后分辨率为原图的1/32,经过卷积后使用几个空洞卷积层扩展感受野但不缩小尺寸,最终以原图的1/32大小输出feture map。这一个分支虽然层数较多,但分辨率小,速度快,且与第二个分子共享一部分权重。
- 以原图的1/2分辨率作为输入,经过卷积后以1/8缩放,得到原图1/16大小的feature map,再将低分辨率分支的输出feature map通过CFF单元融合得到最终输出。这一和分子有17个卷积层,与第一个分支共享一部分权重,与分支1一共耗时6ms。
- 第3个分支以原图作为输入,经过卷积后以1/8缩放,得到原图大小1/8的特征图,再将中分辨率处理后的输出通过CFF单元融合,第3层有3个卷积层,虽然分辨率高,但层少,耗时9ms。
\quad 对于每个分支的输出特征,首先会上采样二倍做输出,在训练的时候,会以ground truth的1/16,1/8,1/4来指导各个分支的训练,这样的辅助训练使得梯度优化更加平滑,便于训练收敛,随着每个分支学习能力的增强,预测没有被任何一个分支主导。利用这样渐变的特征融合和级联引导结构可以产生合理的预测结果。ICNet使用低分辨率完成语义分割,使用高分辨率帮助细化结果,在结构上,产生的feature大大减少,同时仍然保持必要的细节。
CFF单元
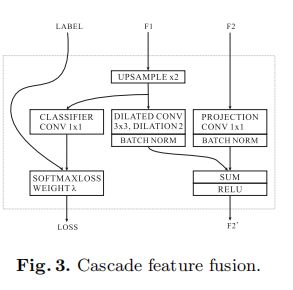 F1代表低分辨率输入,F2代表高分辨率输入。将低分辨率的图片上采样后使用空洞卷积(dilated conv),扩大上采样结果的感受野范围。注意将辅助的标签引导设置为0.4(根据PSPNet的实验结果),即如果下分支的 l o s s L 3 loss L_3 lossL3的占比 λ 3 \lambda_3 λ3为1的话,则中分支的 l o s s L 2 loss L_2 lossL2的占比 λ 2 \lambda_2 λ2为0.4,上分支的 l o s s L 1 loss L_1 lossL1的占比 λ 1 \lambda_1 λ1为0.16。
F1代表低分辨率输入,F2代表高分辨率输入。将低分辨率的图片上采样后使用空洞卷积(dilated conv),扩大上采样结果的感受野范围。注意将辅助的标签引导设置为0.4(根据PSPNet的实验结果),即如果下分支的 l o s s L 3 loss L_3 lossL3的占比 λ 3 \lambda_3 λ3为1的话,则中分支的 l o s s L 2 loss L_2 lossL2的占比 λ 2 \lambda_2 λ2为0.4,上分支的 l o s s L 1 loss L_1 lossL1的占比 λ 1 \lambda_1 λ1为0.16。
损失函数和模型压缩
损失函数
依据不同的分支定义如下: L = λ 1 L 1 + λ 2 L 2 + λ 3 L 3 L=\lambda_1L_1+\lambda_2L_2+\lambda_3L_3 L=λ1L1+λ2L2+λ3L3,根据CCF的设置,下分支的 l o s s L 3 loss L_3 lossL3的占比 λ 3 \lambda_3 λ3为1的话,则中分支的 l o s s L 2 loss L_2 lossL2的占比 λ 2 \lambda_2 λ2为0.4,上分支的 l o s s L 1 loss L_1 lossL1的占比 λ 1 \lambda_1 λ1为0.16。
压缩模型
这里不是很懂,论文采用的一个简单而有效的办法:渐进式压缩。例如以压缩率1/2为例,我们可以先压缩到3/4,对压缩后的模型进行微调,完成后,再压缩到1/2,再微调。保证压缩稳定进行。这里采用Pruning filters for efficient convnets(可以查一下这篇论文)的方法,对于每个滤波器计算核权重的L1和,降序排序,删除权重值较小的。
模型压缩的结果
 mIoU降低了,但推理时间170ms达不到实时要求。这表明只是模型压缩是达不到有良好分割结果的实时性能。对比ICNet,有类似的分割结果,但速度提升了5倍多。
mIoU降低了,但推理时间170ms达不到实时要求。这表明只是模型压缩是达不到有良好分割结果的实时性能。对比ICNet,有类似的分割结果,但速度提升了5倍多。
级联结构的有效性
 sub4代表只有低分辨率输入的结果,sub24代表前两个分支,sub124全部分支。注意到全部分支的速度很快,并且性能接近PSPNet了,且能保持30fps。而且内存消耗也明显减少了。
sub4代表只有低分辨率输入的结果,sub24代表前两个分支,sub124全部分支。注意到全部分支的速度很快,并且性能接近PSPNet了,且能保持30fps。而且内存消耗也明显减少了。
结论
论文在PSPNet的基础上改进出一个ICNet。 核心的思想是利用低分辨率的快速获取语义信息,高分辨率的细节信息。将两者相融合搞出一个折中的模型。
代码实现
https://github.com/BBuf/Keras-Semantic-Segmentation