IN和AdaIN原理与代码实现
Ulyanov发现在风格迁移上使用IN效果比BN好很多,从他开始凡是风格迁移都离不开IN和其变种AdaIN,本文简要介绍IN和AdaIN原理,应用。
下图为特征图张量,可以直观看出BN,LN,IN,GN等规范化方法的区别。N为样本维度,C为通道维度,H为height,W即width,代表特征图的尺寸。
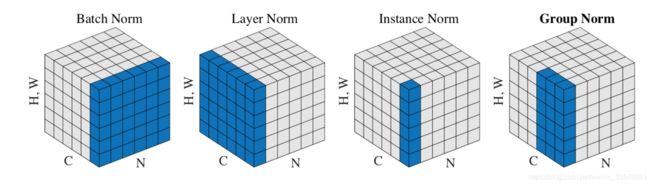
IN
IN对每个样本在每个通道进行规范化,x为特征图,减去均值,除以标准差,规范化后分布均值为0,方差为1。在进行缩放和平移(仿射变换),仿射参数通过反向传播学习。



AdaIN
AdaIN和IN的不同在于仿射参数来自于样本,即作为条件的样本,也就是说AadIN没有需要学习的参数,这和BN,IN,LN,GN都不同。
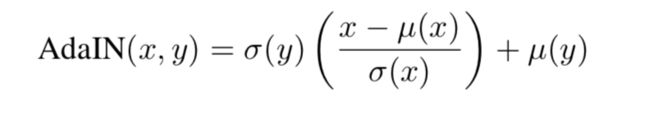
经过实验研究,风格转换中的风格与IN中的仿射参数有很大关系,AdaIN扩展了IN的能力,使用风格图像的均值和标准差作为仿射参数,基于这样一个假设:给定任意的仿射参数能够合成具有任意风格的图像。
实验证实在few-shot image-to-image translation,voice conversion,image style transfer等任务上,AdaIN确实能够实现任意的风格转换。
论文
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
文中使用VGG-19来编码内容和风格,固定编码器,在潜层空间将特征图通过AdaIN层,在其中进行上述仿射变换,解码器根据变换后的特征图试图重建图像,通过反向传播训练解码器,使得解码器输出越来越真实的图像。

代码
import torch
def calc_mean_std(feat, eps=1e-5):
# eps is a small value added to the variance to avoid divide-by-zero.
size = feat.size()
assert (len(size) == 4)
N, C = size[:2]
feat_var = feat.view(N, C, -1).var(dim=2) + eps
feat_std = feat_var.sqrt().view(N, C, 1, 1)
feat_mean = feat.view(N, C, -1).mean(dim=2).view(N, C, 1, 1)
return feat_mean, feat_std
#AadIN
def adaptive_instance_normalization(content_feat, style_feat):
assert (content_feat.size()[:2] == style_feat.size()[:2])
size = content_feat.size()
style_mean, style_std = calc_mean_std(style_feat)
content_mean, content_std = calc_mean_std(content_feat)
normalized_feat = (content_feat - content_mean.expand(
size)) / content_std.expand(size)
return normalized_feat * style_std.expand(size) + style_mean.expand(size)
def _calc_feat_flatten_mean_std(feat):
# takes 3D feat (C, H, W), return mean and std of array within channels
assert (feat.size()[0] == 3)
assert (isinstance(feat, torch.FloatTensor))
feat_flatten = feat.view(3, -1)
mean = feat_flatten.mean(dim=-1, keepdim=True)
std = feat_flatten.std(dim=-1, keepdim=True)
return feat_flatten, mean, std
def _mat_sqrt(x):
U, D, V = torch.svd(x)
return torch.mm(torch.mm(U, D.pow(0.5).diag()), V.t())
def coral(source, target):
# assume both source and target are 3D array (C, H, W)
# Note: flatten -> f
source_f, source_f_mean, source_f_std = _calc_feat_flatten_mean_std(source)
source_f_norm = (source_f - source_f_mean.expand_as(
source_f)) / source_f_std.expand_as(source_f)
source_f_cov_eye = \
torch.mm(source_f_norm, source_f_norm.t()) + torch.eye(3)
target_f, target_f_mean, target_f_std = _calc_feat_flatten_mean_std(target)
target_f_norm = (target_f - target_f_mean.expand_as(
target_f)) / target_f_std.expand_as(target_f)
target_f_cov_eye = \
torch.mm(target_f_norm, target_f_norm.t()) + torch.eye(3)
source_f_norm_transfer = torch.mm(
_mat_sqrt(target_f_cov_eye),
torch.mm(torch.inverse(_mat_sqrt(source_f_cov_eye)),
source_f_norm)
)
source_f_transfer = source_f_norm_transfer * \
target_f_std.expand_as(source_f_norm) + \
target_f_mean.expand_as(source_f_norm)
return source_f_transfer.view(source.size())
class Net(nn.Module):
def __init__(self, encoder, decoder):
super(Net, self).__init__()
enc_layers = list(encoder.children())
self.enc_1 = nn.Sequential(*enc_layers[:4]) # input -> relu1_1
self.enc_2 = nn.Sequential(*enc_layers[4:11]) # relu1_1 -> relu2_1
self.enc_3 = nn.Sequential(*enc_layers[11:18]) # relu2_1 -> relu3_1
self.enc_4 = nn.Sequential(*enc_layers[18:31]) # relu3_1 -> relu4_1
self.decoder = decoder
self.mse_loss = nn.MSELoss()
# fix the encoder
for name in ['enc_1', 'enc_2', 'enc_3', 'enc_4']:
for param in getattr(self, name).parameters():
param.requires_grad = False
# extract relu1_1, relu2_1, relu3_1, relu4_1 from input image
def encode_with_intermediate(self, input):
results = [input]
for i in range(4):
func = getattr(self, 'enc_{:d}'.format(i + 1))
results.append(func(results[-1]))
return results[1:]
# extract relu4_1 from input image
def encode(self, input):
for i in range(4):
input = getattr(self, 'enc_{:d}'.format(i + 1))(input)
return input
def calc_content_loss(self, input, target):
assert (input.size() == target.size())
assert (target.requires_grad is False)
return self.mse_loss(input, target)
def calc_style_loss(self, input, target):
assert (input.size() == target.size())
assert (target.requires_grad is False)
input_mean, input_std = calc_mean_std(input)
target_mean, target_std = calc_mean_std(target)
return self.mse_loss(input_mean, target_mean) + \
self.mse_loss(input_std, target_std)
def forward(self, content, style, alpha=1.0):
assert 0 <= alpha <= 1
style_feats = self.encode_with_intermediate(style)
content_feat = self.encode(content)
#在特征空间进行变换
t = adain(content_feat, style_feats[-1])
t = alpha * t + (1 - alpha) * content_feat
g_t = self.decoder(t)
g_t_feats = self.encode_with_intermediate(g_t)
loss_c = self.calc_content_loss(g_t_feats[-1], t)
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0])
for i in range(1, 4):
loss_s += self.calc_style_loss(g_t_feats[i], style_feats[i])
return loss_c, loss_s
参考
https://github.com/naoto0804/pytorch-AdaIN
https://arxiv.org/pdf/1703.06868.pdf
https://blog.csdn.net/wyl1987527/article/details/70245214