pytorch中torch.nn.utils.rnn相关sequence的pad和pack操作
目录
一、pad_sequence
二、pack_padded_sequence
三、pad_packed_sequence
四、pack_sequence
自然语言处理任务中,模型的输入一般都是变长的。为了能够组成batch输入模型进行并行计算,都是要把变长的数据处理为等长的。一个简单的文本分类任务中,一般都会把输入文本做tokenize后输入到Bert或者其他如RNN等模型中,得到句子的embedding后,做一些处理然后过分类器。示例:
texts = [
"你好我是一个NLP工程师",
"中国人",
"我要好好工作努力挣钱买房买车",
"你",
"老婆老婆老婆我爱你"
]
tokenize后
[101, 872, 1962, 2769, 3221, 671, 702, 156, 10986, 2339, 4923, 2360, 102]
[101, 704, 1744, 782, 102]
[101, 2769, 6206, 1962, 1962, 2339, 868, 1222, 1213, 2914, 7178, 743, 2791, 743, 6756, 102]
[101, 872, 102]
[101, 5439, 2038, 5439, 2038, 5439, 2038, 2769, 4263, 872, 102]
可以看出序列有长有短,需要padding!
之前都是自己手动padding来实现的,后面发现torch中已经有了相应的API能够高速快速的处理这样的问题,同时也能够处理好padding无意义的值带来的影响。下面就一起来看看torch.nn.utils.rnn中API是如何处理这些问题的吧!
一、pad_sequence
torch.nn.utils.rnn.pad_sequence(sequences, batch_first=False, padding_value=0.0)
参数说明:sequences:输入的tensor数据,类型为列表或者tuple等等;
batch_first:决定输出中batch这一维度是否在第一维;
padding_value:要填充的值,一般为0
pad_sequence输出结果为一个tensor B*T*H
以上述数据为例——5句话,代码如下:
import torch
from transformers import BertTokenizer
from torch.nn.utils.rnn import pad_sequence,pack_padded_sequence,pack_sequence,pad_packed_sequence
if __name__ == '__main__':
texts = [
"你好我是一个NLP工程师",
"中国人",
"我要好好工作努力挣钱买房买车",
"你",
"老婆老婆老婆我爱你"
]
tokenizer = BertTokenizer.from_pretrained('pretrained_models/chinese-bert-wwm-ext')
# datas = [ torch.tensor(tokenizer(text)['input_ids'],dtype=torch.long) for text in texts]
datas = [tokenizer(text)['input_ids'] for text in texts]
for data in datas:
print(data)
datas = [torch.tensor(data,dtype=torch.long) for data in datas]
print(datas)
pad_datas = pad_sequence(datas,batch_first=True,padding_value=0)
print(pad_datas.shape)
print(pad_datas)
结果如下图:
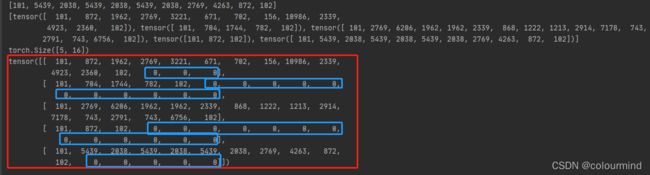
结果中长度效果16的,就自动的填充了0,使得pad_datas成为等长的,可以组成batch,输入到模型中进行并行计算。
二、pack_padded_sequence
torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=False, enforce_sorted=True)
参数说明:input:经过 pad_sequence 处理之后的数据,类型为tensor;
lengths:batch中各个序列的实际长度,如果提供的是tensor,必须是在CPU上
batch_first:决定输出中batch这一维度是否在第一维;
enforce_sorted:如果是 True ,则输入应该是按长度降序排序的序列。如果是 False ,会在函数内部进行排序。默认值为 True 。
输出返回一个 PackedSequence 对象,输出:data、batch_sizes、sorted_indices和unsorted_indices
为什么要用这个函数呢?用了这个函数有什么好处呢?什么时候可以使用这个函数呢?
顾名思义,pack就为压缩压实压紧的含义;对谁进行压缩呢?对经过padded_sequence进行压缩。经过padding后的tensor会含有很多无意义的padding_value,它对模型的效果最终有一定的影响,为了完全消除这个影响,就需要把这些无意义的padding_value进行压缩。压缩就可以采用这个pack_padded_sequence()函数了,当然这个函数压缩后的数据不是什么模型都可以使用的,一般而言,只有RNN类模型可以使用。Bert类模型应该是不支持的,Bert类要消除这个影响,需要配合attention_mask得到embedding后,手动的把padding过的位置的embedding进行处理,参见——Sentence-Bert中pooling的理解——位置实现了如何进行相应的无意义的padding_value的处理。
RNN中padding_value有何影响呢?pack_padded_sequence 和 pad_packed_sequence
一文中进行了详细的描述,截图如下:
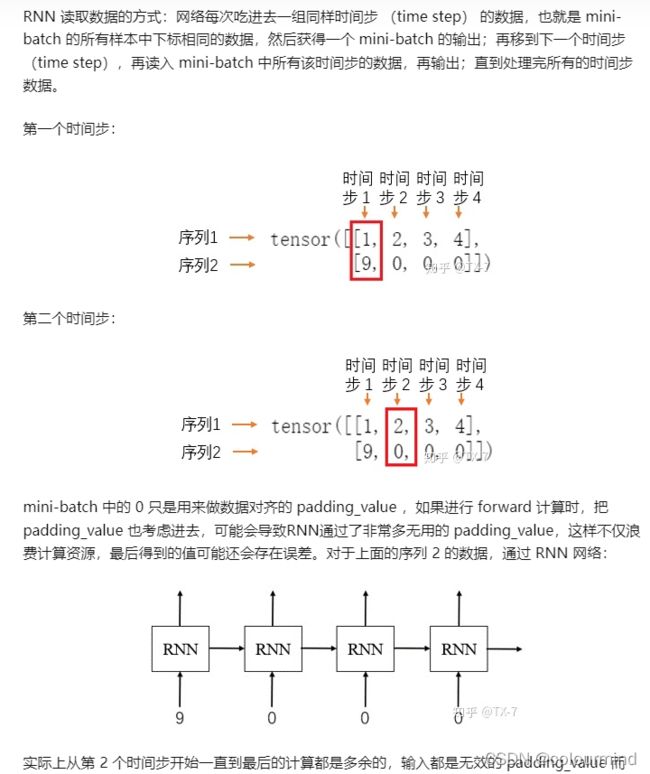
如果不处理padding_value,RNN模型每一个step中都会把batch中全部数据不管是不是padding_value都加载进模型进行计算,很明显的增加了计算量和推理时间。所以正确的做法就是跳过padding_value把所有的非padding_value数据加载进模型,从而减小计算量同时增加准确率。
if __name__ == '__main__':
texts = [
"你好我是一个NLP工程师",
"中国人",
"我要好好工作努力挣钱买房买车",
"你",
"老婆老婆老婆我爱你"
]
tokenizer = BertTokenizer.from_pretrained('pretrained_models/chinese-bert-wwm-ext')
# datas = [ torch.tensor(tokenizer(text)['input_ids'],dtype=torch.long) for text in texts]
datas = [tokenizer(text)['input_ids'] for text in texts]
lengths = [ len(data) for data in datas]
for data in datas:
print(data)
datas = [torch.tensor(data,dtype=torch.long) for data in datas]
print('datas',datas)
pad_datas = pad_sequence(datas,batch_first=True,padding_value=0)
print('pad_datas.shape',pad_datas.shape)
print('pad_datas',pad_datas)
pack_pad_datas = pack_padded_sequence(input=pad_datas,lengths = lengths ,batch_first=True, enforce_sorted=False)
print('pack_pad_datas',pack_pad_datas)pack_padded_sequence的结果:
pack_pad_datas PackedSequence(data=tensor([ 101, 101, 101, 101, 101, 2769, 872, 5439, 704, 872,
6206, 1962, 2038, 1744, 102, 1962, 2769, 5439, 782, 1962,
3221, 2038, 102, 2339, 671, 5439, 868, 702, 2038, 1222,
156, 2769, 1213, 10986, 4263, 2914, 2339, 872, 7178, 4923,
102, 743, 2360, 2791, 102, 743, 6756, 102]), batch_sizes=tensor([5, 5, 5, 4, 4, 3, 3, 3, 3, 3, 3, 2, 2, 1, 1, 1]), sorted_indices=tensor([2, 0, 4, 1, 3]), unsorted_indices=tensor([1, 3, 0, 4, 2]))把batch内序列按照长度从大到小排序后,和pack_padded_sequence对比来看:
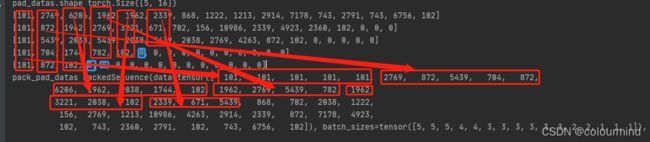
可以看到完美的跳过了padding_value值0。
三、pad_packed_sequence
torch.nn.utils.rnn.pad_packed_sequence(sequence, batch_first=False, padding_value=0.0, total_length=None)
参数说明:sequence:PackedSequence 对象,将要被填充的一个batch数据
batch_first:决定输出中batch这一维度是否在第一维;
padding_value:填充值;
total_length:如果不是None,输出将被填充到长度:total_length,如果是None则会白填充到最大序列长度
函数说明:对已经压缩过的数据进行填充恢复,联合pack_padded_sequence()来看,它们之间应该是互为逆操作的。举例如下:
pad_datas = pad_sequence(datas,batch_first=True,padding_value=0)
print('pad_datas',pad_datas)
pack_pad_datas = pack_padded_sequence(input=pad_datas,lengths = lengths ,batch_first=True, enforce_sorted=False)
print('pack_pad_datas',pack_pad_datas)
origin_data = pad_packed_sequence(sequence=pack_pad_datas,batch_first=True,padding_value=0)
print('origin_data',origin_data)结果如下:
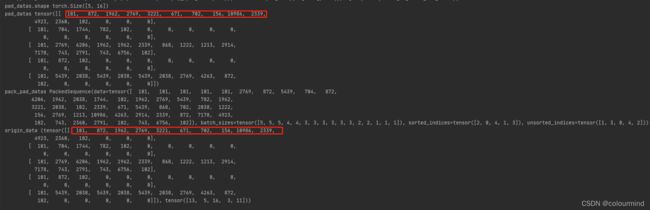
origin_data和pad_datas是相同的,说明pad_packed_sequence()把pack_padded_sequence()压缩的结果逆向填充回去了。
这里为何要填充回来呢?因为经过pack_padded_sequence()压缩后的数据输入到RNN模型中,得到的结果也是没有padding_vaule的,维度和之前的那些没有压缩的数据对不齐,后续的操作就不好处理,则需要逆向填充回来对齐后,方便后续的操作。
RNN模型示例
import torch
import torch.nn as nn
from transformers import BertTokenizer
from torch.nn.utils.rnn import pad_sequence,pack_padded_sequence,pack_sequence,pad_packed_sequence
if __name__ == '__main__':
texts = [
"中国人",
"你",
"老婆老婆"
]
tokenizer = BertTokenizer.from_pretrained('pretrained_models/chinese-bert-wwm-ext')
datas = [tokenizer(text)['input_ids'] for text in texts]
lengths = [ len(data) for data in datas]
datas = [torch.tensor(data,dtype=torch.float) for data in datas]
# print('datas',datas)
pad_datas = pad_sequence(datas,batch_first=True,padding_value=0)
print('pad_datas.shape',pad_datas.shape)
print('pad_datas',pad_datas)
pad_datas = torch.unsqueeze(pad_datas,dim=2)
print('pad_datas.shape',pad_datas.shape)
print('pad_datas', pad_datas)
pack_pad_datas = pack_padded_sequence(input=pad_datas,lengths = lengths ,batch_first=True, enforce_sorted=False)
print('pack_pad_datas',pack_pad_datas)
model = nn.LSTM(input_size=1,hidden_size=3,batch_first=True,bidirectional=False)
out, _ = model(pack_pad_datas)
print(type(out))
print(out)
out = pad_packed_sequence(sequence=out,batch_first=True,padding_value=0.0)
print(out)模型的输出:
PackedSequence(data=tensor([[-7.6159e-01, -4.0967e-32, -7.0377e-05],
[-7.6159e-01, -4.0967e-32, -7.0377e-05],
[-7.6159e-01, -4.0967e-32, -7.0377e-05],
[-7.6159e-01, -0.0000e+00, -7.0377e-05],
[-7.6159e-01, -0.0000e+00, -7.0377e-05],
[-7.6159e-01, -0.0000e+00, -7.0377e-05],
[-7.6159e-01, -0.0000e+00, -7.0377e-05],
[-7.6159e-01, -0.0000e+00, -7.0377e-05],
[-7.6159e-01, -6.2395e-32, -1.4295e-04],
[-7.6159e-01, -0.0000e+00, -7.0377e-05],
[-7.6159e-01, -0.0000e+00, -7.0377e-05],
[-7.6159e-01, -0.0000e+00, -7.0377e-05],
[-7.6159e-01, -6.2395e-32, -1.4295e-04],
[-7.6159e-01, -6.2395e-32, -1.4295e-04]], grad_fn=), batch_sizes=tensor([3, 3, 3, 2, 2, 1]), sorted_indices=tensor([2, 0, 1]), unsorted_indices=tensor([1, 2, 0])) 要想清晰的得到每一句话的向量,还需要做后续处理,采用pad_packed_sequence()填充后如下:
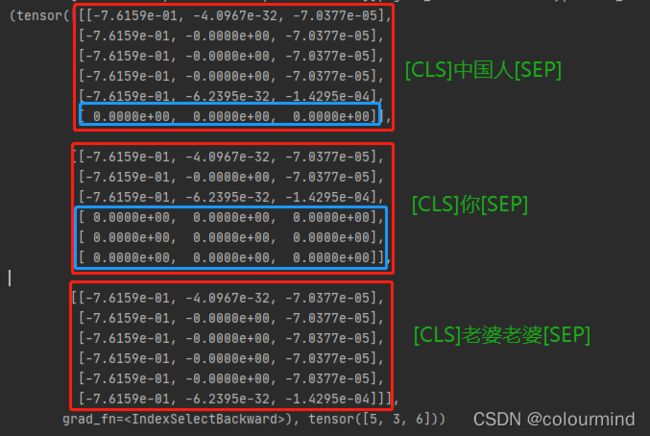
这样的tensor就比较清晰的得到每一句的输出以及padding_value对应的结果都是填充的0.0。
四、pack_sequence
torch.nn.utils.rnn.pack_sequence(sequences, enforce_sorted=True)
参数说明:sequences:输入数据,类型为list或者tuple,元素为tensor
enforce_sorted:True输入数据必须安装序列长度降序排列;False则不需要,函数内部会自动排序的。
函数作用:就是把输入的sequences按照特殊的顺序组装成一个PackedSequence;其实就是相当于pad_sequence()+pack_padded_sequence()。示例如下:
import torch
import torch.nn as nn
from transformers import BertTokenizer
from torch.nn.utils.rnn import pad_sequence,pack_padded_sequence,pack_sequence,pad_packed_sequence
if __name__ == '__main__':
texts = [
"中国人",
"你",
"老婆老婆"
]
tokenizer = BertTokenizer.from_pretrained('pretrained_models/chinese-bert-wwm-ext')
datas = [tokenizer(text)['input_ids'] for text in texts]
lengths = [ len(data) for data in datas]
datas = [torch.tensor(data,dtype=torch.float) for data in datas]
print(datas)
pad_datas = pad_sequence(datas,batch_first=True,padding_value=0)
print('pad_datas.shape',pad_datas.shape)
print('pad_datas',pad_datas)
pack_pad_datas = pack_padded_sequence(input=pad_datas,lengths = lengths ,batch_first=True, enforce_sorted=False)
print('pack_pad_datas',pack_pad_datas)
pack_data = pack_sequence(datas)
print('pack_data',pack_data)
结果:

pack_pad_datas和pack_data结果一模一样
参考文章
pack_padded_sequence 和 pad_packed_sequence
TORCH.NN.UTILS.RNN.PAD_SEQUENCE
TORCH.NN.UTILS.RNN.PACK_SEQUENCE
TORCH.NN.UTILS.RNN.PACK_PADDED_SEQUENCE
TORCH.NN.UTILS.RNN.PAD_PACKED_SEQUENCE