FastSppech论文阅读笔记
论链接:https://arxiv.org/abs/1905.09263
文章目录
- 摘要
- 简介
- 非自回归序列生成
- FastSpeech
-
- Feed-Forward Transformer
- Length Regulator
- Duration Predictor
- 实验设置
-
- 数据集
- 模型配置
-
- FastSpeech model
- Autoregressive Transformer TTS model
- 训练和推理
- 结果
-
- 音频质量
- 推理加速
- 鲁棒性
- 长度控制
-
- 音频速度
- 字词间的停顿
- 消融实现
-
- FFT块中的一维卷积
- 结论
摘要
基于神经网络的端到端文语转换(TTS)显著提高了合成语音的质量。主要的方法(例如,Tacotron 2)通常首先从文本生成Mel语谱图,然后使用诸如WaveNet的声码器从Mel语谱图合成语音。
与传统的串接和统计参数方法相比,基于神经网络的端到端模型推理速度慢,合成的语音通常不健壮(即某些单词被跳过或重复),并且缺乏可控性(语音速度或韵律控制)。
论文提出了一种新的基于Transformer的前馈网络来并行生成TTS的MEL谱图。具体地说,从基于编–解码器的教师模型中提取注意力对齐,用于音素持续时间预测,长度调节器使用该教师模型来扩展源音素序列以匹配目标Mel语谱图序列的长度,用于并行生成Mel语谱图。
在LJSpeech数据集上的实验表明,提出的并行模型在语音质量方面与自回归模型相匹配,在特别困难的情况下几乎消除了单词跳过和重复的问题,并能平稳地调整语音速度。最重要的是,与自回归Transformer TTS相比,提出的模型可将融合谱图生成速度提高270倍,将端到端语音合成速度提高38倍。因此模型称为FastSpeech。
简介
目前基于神经网络的TTS系统中,mel谱图的生成是自回归的。由于梅尔谱图的长序列和自回归性质,这些系统面临几个挑战:
- Mel谱图生成的推理速度慢。虽然基于CNN和Transformer的TTS可以加快基于RNN的模型的训练速度,所有模型都以先前生成的MEL谱图为条件生成新的MEL谱图,并且由于MEL谱图序列的长度通常为数百或数千,因此推断速度较慢。
- 合成的语音通常不健壮。由于错误传播和自回归生成中文本和语音之间错误的注意力对齐,生成的MEL谱图通常存在单词跳过和重复的问题。
- 合成语音缺乏可控性。以前的自回归模型自动地一个接一个地生成梅尔谱图,没有显式利用文本和语音之间的对齐。因此,在自回归生成中,通常很难直接控制语速和韵律。
考虑到文本和语音之间的单调对齐,为了加快Mel谱图的生成速度,提出了一种新的模型FastSpeech,该模型以文本(音素)序列作为输入,以非自回归的方式生成Mel谱图。该模型是基于自注意力Transformer和一维卷积的前向网络。由于梅尔谱图序列比其对应的音素序列长得多,为了解决两个序列之间的长度不匹配问题,FastSpeech采用了一种长度调节器,根据音素持续时间(即每个音素对应的梅尔谱图的数量)对音素序列进行上采样,以匹配梅尔谱图序列的长度。该调节器建立在音素持续时间预测器的基础上,该预测器预测每个音素的持续时间。
提出的FastSpeech模型能解决上述提到的三个问题:
- 通过并行生成MEL谱图,FastSpeech极大地加快了合成过程。
- 音素持续时间预测器确保音素及其音谱图之间的硬对齐,这与自回归模型中的软对齐和自注意对齐有很大不同。因此,FastSpeech避免了错误传播和错误注意力对齐的问题,从而降低了跳过单词和重复单词的比例。
- 长度调节器可以通过延长或缩短音素持续时间来轻松调整语音速度,以确定生成的梅尔谱图的长度,还可以通过在相邻音素之间添加间歇来控制部分韵律。
在LJSpeech数据集上进行了实验,以测试FastSpeech。结果表明,在语音质量方面,FastSpeech几乎符合自回归变换模型。此外,与自回归变换TTS模型相比,FastSpeech在MEL谱图生成上的加速比达到270倍,在最终语音合成上的加速比达到38倍,几乎消除了单词跳跃和重复的问题,并且可以平滑地调整语音速度。
非自回归序列生成
与自回归序列生成不同,非自回归模型是并行生成序列的,不需要显式依赖于先前的元素,这可以极大地加快推理过程。非自回归生成已经在一些序列生成任务中被研究过,例如神经机器翻译和音频合成。FastSpeech与上述工作的不同之处有两个:
- 前人的工作主要是在神经机器翻译或音频合成中采用非自回归生成,主要是为了提高推理加速比,而FastSpeech则专注于在TTS中提高推理加速比和提高合成语音的鲁棒性和可控性
- 对于TTS,虽然并行WaveNet、ClariNet和WaveGlow并行地产生音频,但它们是以MEL谱图为条件的,这些谱图仍然是自动回归地产生的。因此,并没有解决这项工作中考虑的挑战
FastSpeech
为了并行生成目标 mel 频谱图序列,设计了一种新颖的前馈结构,而不是使用大多数基于序列到序列的自回归生成的基于编码器-注意力-解码器的架构和非自回归结构。
Feed-Forward Transformer
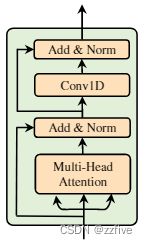
FastSpeech的结构是基于Transformer和一维卷积的自注意前馈结构,论文将该结构成为Feed-Forward Transformer(FFT),如下图1所示。为了实现音素到mel谱图的转换,FFT堆叠了多个FFT块,分别在音素侧和mei谱图侧各堆叠n个FFT块,中间由一个长度调节地,来弥合音素和mel谱图序列之间的长度差距。每个FFT块包含一个自注意力层和一维卷积网络,如图2所示。自注意力层由一个多头注意力组成提取交叉位置信息。与Transformer中的2层密集网络不同,使用了一个具有ReLU激活的2层一维卷积网络;动机是相邻的隐藏状态在语音任务中的字符/音素和梅尔谱图序列中更密切相关。在实验部分评估了一维卷积网络的有效性。FFT块的其他部分基本与Transformer中一致。
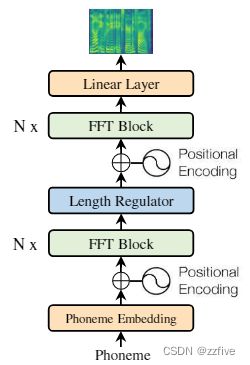
Length Regulator
长度调节器(结构如图3所示)用于解决FFT中音素与谱图序列长度不匹配的问题,以及对语速和部分韵律进行控制。音素序列的长度通常小于mel谱图序列的长度,每个音素对应若干个mel帧;把与音素对应的mel谱的长度称为音素持续时间。基于音素持续时间d,长度调节器将音素序列中每个音素对应的隐藏状态重复c扩展d次,使得隐藏状态的总长度等于mel谱图的长度。将音素序列的隐藏向量表示为 H p h o = [ h 1 , h 2 , . . . , h n ] H_{pho}=[h_1,h_2,...,h_n] Hpho=[h1,h2,...,hn],其中n是序列的长度。将音素持续时间序列表示为 D = [ d 1 , d 2 , . . . , d n ] D=[d_1,d_2,...,d_n] D=[d1,d2,...,dn],其中 ∑ i = 1 n d i = m \sum_{i=1}^{n}d_i=m ∑i=1ndi=m,m是MEL谱图序列的长度。将长度调节器LR表示为 H m e l = L R ( H p h o , D , α ) H_{mel}=LR(H_{pho},D,α) Hmel=LR(Hpho,D,α),其中α是用于确定扩展序列 H m e l H_{mel} Hmel的长度的超参数,从而控制语音速度。
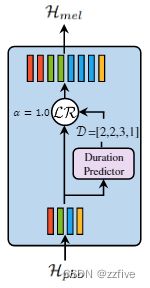
例如,给定 H p h o = [ h 1 , h 2 , h 3 , h 4 ] H_{pho}=[h_1,h_2,h_3,h_4] Hpho=[h1,h2,h3,h4],对应的音素持续时间序列为 D = [ 2 , 2 , 3 , 1 ] D=[2,2,3,1] D=[2,2,3,1]。如果 α = 1 α=1 α=1(正常速度),基于上述公式,转换后 H p h o = [ h 1 , h 1 , h 2 , h 2 , h 3 , h 3 , h 3 , h 4 ] H_{pho}=[h_1,h_1,h_2,h_2,h_3,h_3,h_3,h_4] Hpho=[h1,h1,h2,h2,h3,h3,h3,h4]。当 α = 1.3 α=1.3 α=1.3(慢速),音素持续时间序列变为 D α = 1.3 = [ 2.6 , 2.6 , 3.9 , 1.3 ] ≈ [ 3 , 3 , 4 , 1 ] D_{α=1.3}=[2.6,2.6,3.9,1.3]≈[3,3,4,1] Dα=1.3=[2.6,2.6,3.9,1.3]≈[3,3,4,1],转换后 H p h o = [ h 1 , h 1 , h 1 , h 2 , h 2 , h 2 , h 3 , h 3 , h 3 , h 3 , h 4 ] H_{pho}=[h_1,h_1,h_1,h_2,h_2,h_2,h_3,h_3,h_3,h_3,h_4] Hpho=[h1,h1,h1,h2,h2,h2,h3,h3,h3,h3,h4]。当 α = 0.5 α=0.5 α=0.5(快速),音素持续时间序列变为 D α = 0.5 = [ 1 , 1 , 1.5 , 0.5 ] ≈ [ 1 , 1 , 2 , 1 ] D_{α=0.5}=[1,1,1.5,0.5]≈[1,1,2,1] Dα=0.5=[1,1,1.5,0.5]≈[1,1,2,1],转换后 H p h o = [ h 1 , h 2 , h 3 , h 3 , h 4 ] H_{pho}=[h_1,h_2,h_3,h_3,h_4] Hpho=[h1,h2,h3,h3,h4]。可以通过调整句子中空格字符的时长来控制单词之间的断字,从而调整合成语音的部分韵律。
Duration Predictor
音素持续时间预测对长度调节器很重要。如图4所示,持续时间预测器由一个带有 ReLU 激活的 2 层 1D 卷积网络组成,每个卷积网络后面都有层归一化和 dropout 层,以及一个额外的线性层来输出一个标量,该标量正是预测的音素持续时间。注意,该模块堆叠在音素侧的FFT块上,并与FastSpeech模型联合训练,在均方误差(MSE)损失的情况下预测每个音素对应的Mel谱图的长度。论文中在对数域预测长度,这使它们更高斯化和更容易训练。请注意,训练的持续时间预测器只用于TTS推断阶段,因为可以直接在训练中使用从自回归教师模型中提取的音素持续时间。
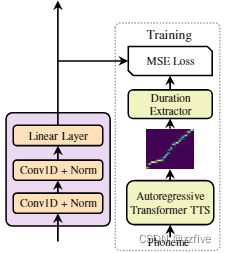
为了训练持续时间预测器,论文从一个自回归教师TTS模型中提取Ground Truth音素持续时间,如图4所示。具体步骤描述如下:
- 首先根据论文Close to Human Quality TTS with Transformer中的方法训练一个基于自回归编码器-注意-解码器的Transformer TTS模型
- 对于每个训练序列对,从训练好的教师模型中提取解码器到编码器的注意力对齐。由于多头自注意力层,存在多个注意力对齐,但并不是所有的注意头都具有对角线属性(音素和音谱序列是单调对齐的)。提出一个聚焦率F来衡量注意力头如何逼近对角线: F = 1 S ∑ s = 1 S m a x 1 ≤ t ≤ T a s , t F=\frac{1}{S}\sum_{s=1}^{S}max_{1≤t≤T}a_{s,t} F=S1∑s=1Smax1≤t≤Tas,t,其中 S 和 T S和T S和T分别是ground-truth频谱和音素序列的长度, a s , t a_{s,t} as,t表示注意力矩阵中第s行、第t列的元素。计算每个头部的焦点率,并选择F值最大的头部作为注意力对准。
- 最后,根据持续时间抽取器 d i = ∑ s = 1 S [ a r g m a x t a s , t = i ] d_i=\sum_{s=1}^{S}[arg max_t a_{s,t}=i] di=∑s=1S[argmaxtas,t=i]提取音素持续时间序列 D = [ d 1 , d 2 , . . . , d n ] D=[d_1, d_2,...,d_n] D=[d1,d2,...,dn]。也就是说,一个音素的持续时间是根据上述步骤中选择的注意头所注意到的音素谱图的数量。
实验设置
数据集
在LJSpeech数据集上执行实验,其包含13100个英文音频片段和对应的文本,总时长约为24小时。随机将其划分为三个数据集,12500个片段作为训练集,验证集和测试集则都是300个片段。为了缓解读音错误问题,使用内部的字素-音素转换工具将文本序列转换为音素序列。对于语音数据,将原始波形按照Tocatron2论文中转换为mel谱图;frame size和hop size分别设置为1024和256。
为了评估提出的FastSpeech的鲁棒性,还选择了50个TTS系统中特别难的句子。
模型配置
FastSpeech model
FastSpeech模型由音素侧和mel谱图侧的各六个FFT块组成。音素词典的大小是51,包括标点符号在内。音素嵌入层、FFT块中自注意力层的hidden_size和一维卷积的输出尺寸都设置为384。自注意力头数是2。在2层的一维卷积网络中kernel size都设置为3,第一层的输入输出尺寸为384/1536,第二层的输入输出大小为1536/384。最后的输出线性层将384维的隐状态转换维80维的mel谱图。在持续时间预测器中,一维卷积层的kernel size大小设置维3,所有层的输入输出尺寸均为384。
Autoregressive Transformer TTS model
自回归Transformer TTS模型在该工作中有两个用途:
- 提取音素持续时间作为训练持续时间预测器的目标
- 在序列级知识蒸馏中生成mel谱图
该模型的配置参考论文Close to Human Quality TTS with Transformer,它由一个6层编码器,一个6层解码器组成,只是本论文中使用的是一维卷积网络,而不是位置FFN。这个教师模型的参数数量与FastSpeech模型相似
训练和推理
首先在4个NVIDIA V100 GPU上训练自回归Transformer TTS模型,每个GPU上的batch size为16。使用 β 1 = 0.9 , β 2 = 0.98 , ε = 1 0 − 9 β_1 = 0.9, β_2 = 0.98, ε = 10^{−9} β1=0.9,β2=0.98,ε=10−9的Adam优化器,遵循与Transformer论文中相同的学习率计划。训练到收敛需要80k步。将训练集中的文本和语音对再次输入到模型中,以获得编码器和解码器的注意对齐,用于训练持续时间预测器。此外,还利用在非自回归机器翻译中取得良好表现的序列级知识蒸馏,将知识从教师模型转移到学生模型。对于每个源文本序列,使用自回归Transformer TTS模型生成mel谱图,并将源文本和生成的mel谱图作为FastSpeech模型训练的数据对。
FastSpeech模型和duration predictor一起进行训练。FastSpeech的优化器和其他超参数与自回归Transformer TTS模型相同。FastSpeech模型训练在4个NVIDIA V100 gpu上大约需要80k步。在推理过程中,利用预训练的WaveGlow将FastSpeech模型的输出光谱转换为音频样本
结果
从音频质量、推断加速、鲁棒性和可控性等方面评估FastSpeech的性能。
音频质量
对测试集进行MOS (mean opinion score)评估,以衡量音频质量。保持不同模型的文本内容一致,排除其他干扰因素,只检测音频质量。每个音频都有至少20名测试者听,他们的母语都是英语。将FastSpeech模型生成的音频样本的MOS值与其他系统进行了比较,包括
- GT, the ground truth audio
- GT (Mel + WaveGlow),首先将GT音频转换为声波谱图,然后使用WaveGlow将声波谱图转换回音频
- Tacotron2 (Mel + WaveGlow)
- Transformer TTS (Mel + WaveGlow)
- Merlin,一个流行的参数化TTS系统,使用WORLD作为声码器
结果如下表1所示,FastSpeech几乎可以匹配Transformer TTS模型和Tacotron 2的质量

推理加速
评估了FastSpeech与Transformer-TTS模型的推断延迟,该模型与FastSpeech具有相似数量的模型参数。在表2中展示了梅尔谱图生成的推断速度。可以看出,与Transformer TTS模型相比,FastSpeech的mel谱图生成速度提高了269.40倍(评估服务器采用Intel Xeon 12个CPU, 256GB内存,1个NVIDIA V100 GPU,批处理大小为1个。两种系统生成的梅尔谱图的平均长度都约为560)。然后展示了使用WaveGlow作为声码器时的端到端加速。可以看出,FastSpeech仍然可以实现38.30倍的音频生成速度。
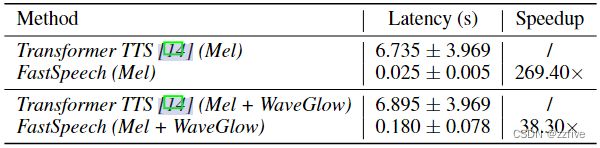
可视化推断延迟和测试集中预测的mel谱图序列长度之间的关系。图 5 显示,FastSpeech 的推理延迟几乎不随预测的 mel 谱图的长度而增加,而在 Transformer TTS 中则大幅增加。这表明由于并行生成,FastSpeech的方法的推理速度对生成的音频的长度不敏感。
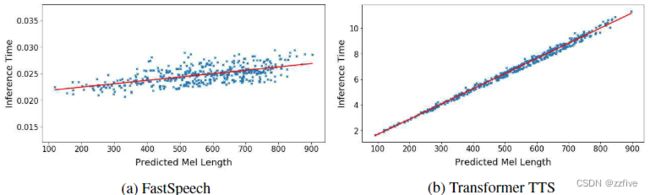
鲁棒性
自回归模型中编码器-解码器的注意机制可能会导致音素和音谱之间错误的注意对齐,从而导致单词重复和单词跳过的不稳定。为了评价FastSpeech的鲁棒性,选取了50个TTS系统中比较难的句子。表3中列出了单词错误计数。可以看出,Transformer TTS对这些困难例子的鲁棒性不强,错误率为34%,而FastSpeech可以有效消除单词重复和跳过,提高可读性。
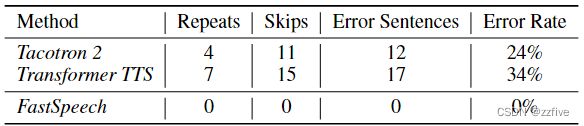
长度控制
音频速度
FastSpeech可以通过调整音素时长来控制语音速度和部分韵律,这是其他端到端的TTS系统所不支持的。以下展示了长度控制前后的mel谱图,并将音频样本放入补充材料中供参考。
通过延长或缩短音素持续时间生成的不同语速的mel-spectrogram如图6所示。通过实验证明,FastSpeech可以平滑地将语音速度从0.5倍调整到1.5倍,音高稳定且几乎不变,其中对应的文本是“For a while the preacher addresses himself to the congregation at large, who listen attentively”。
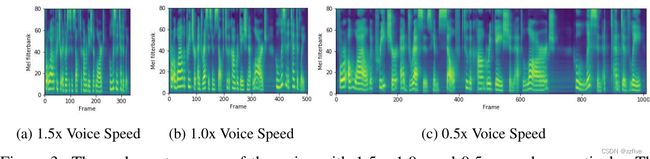
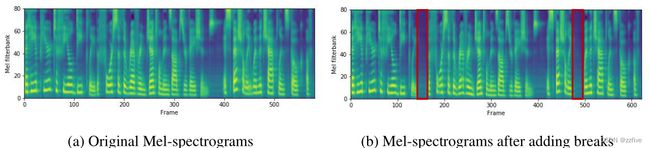
字词间的停顿
FastSpeech可以通过延长句子中空格字符的持续时间来增加相邻单词之间的停顿,从而改善语音的韵律。图7中展示了一个例子,在句子的两个位置添加了停顿来改善韵律;其对应的文本是“that he appeared to feel deeply the force of the reverend gentleman’s observations, especially when the chaplain spoke of ”,在句子中的“deeply”和“especially”后面增加间隔来改善韵律,对应于图7中的红框。
消融实现
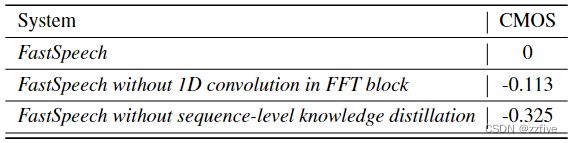
进行消融研究来验证FastSpeech中几个组件的有效性,包括一维卷积和序列级知识蒸馏。对这些消融研究进行CMOS评价。
FFT块中的一维卷积
在此,通过实验将一维卷积的性能与参数数量相近的全连通层进行比较。如表4所示,用全连通层替换1D卷积得到-0.113 CMOS,证明了1D卷积的有效性。
结论
在这项工作中,提出了FastSpeech:一个快速、鲁棒和可控的神经TTS系统。FastSpeech采用一种新颖的前馈网络并行生成语音谱图,该网络由几个关键部件组成,包括FFT块、长度调节器和持续时间预测器。在LJSpeech数据集上的实验表明,提出的FastSpeech在语音质量上几乎可以与自回归Transformer TTS模型相匹配,可以加快270x的mel谱图生成速度和38x的端到端语音合成速度,几乎消除了单词跳过和重复的问题,并可以平滑地调整语音速度(0.5x-1.5x)。
在未来的工作中,将继续提高合成语音的质量,并将FastSpeech应用到多语音和低资源的设置中;还将与并行神经声码器联合训练FastSpeech,使其完全端到端和并行。