chainer-图像分类-MobileNetV3代码重构【附源码】
文章目录
- 前言
- 代码实现
- 调用方式
前言
本文基于chainer实现MobileNetV3网络结构,并基于torch的结构方式构建chainer版的,并计算MobileNetV3的参数量。
本次基于chainer 实现了Hardsigmoid、Hardswish、Relu6、Relu等激活函数
代码实现
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class Hardsigmoid(chainer.Chain):
def __init__(self):
super(Hardsigmoid, self).__init__()
def __call__(self, x):
return F.relu6(x+3) / 6
class Hardswish(chainer.Chain):
def __init__(self):
super(Hardswish, self).__init__()
def __call__(self, x):
out = x * F.relu6(x + 3) / 6
return out
class Relu6(chainer.Chain):
def __init__(self):
super(Relu6, self).__init__()
def __call__(self, x):
out = F.relu6(x)
return out
class ReLU(chainer.Chain):
def __init__(self):
super(ReLU, self).__init__()
def __call__(self, x):
out = F.relu(x)
return out
# 标准卷积+标准化+激活函数
class ConvBNActivation(chainer.Chain):
def __init__(self, in_planes: int, out_planes: int,
kernel_size: int = 3, stride: int = 1, groups: int = 1,
norm_layer = None, activation_layer = None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = L.BatchNormalization
if activation_layer is None:
activation_layer = Relu6()
super(ConvBNActivation, self).__init__()
self.layers = []
self.layers += [('conv',L.Convolution2D(in_channels=in_planes,out_channels=out_planes,ksize=kernel_size,stride=stride,pad=padding,groups=groups, nobias=True))]
self.layers += [('bn',norm_layer(out_planes))]
self.layers += [('relu',activation_layer)]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def __call__(self, x):
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
return x
# SE模块
class SqueezeExcitation(chainer.Chain):
# 注意力机制
def __init__(self, input_c: int, squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
# 满足1/4关系:input_c // squeeze_factor
squeeze_c = _make_divisible(input_c // squeeze_factor, 8)
self.layers = []
self.layers += [('fc1',L.Convolution2D(in_channels=input_c,out_channels=squeeze_c,ksize=1))]
self.layers += [('relu',ReLU())]
self.layers += [('fc2',L.Convolution2D(in_channels=squeeze_c,out_channels=input_c,ksize=1))]
self.layers += [('hardsigmoid',Hardsigmoid())]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
short_cut = x
x = F.average_pooling_2d(x, x.shape[2:], stride=1)
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
return x * short_cut
class InvertedResidualConfig:
def __init__(self, input_c: int, kernel: int, expanded_c: int, out_c: int, use_se: bool, activation: str, stride: int, width_multi: float):
self.input_c = self.adjust_channels(input_c, width_multi)
self.kernel = kernel
self.expanded_c = self.adjust_channels(expanded_c, width_multi)
self.out_c = self.adjust_channels(out_c, width_multi)
self.use_se = use_se
self.use_hs = activation == "HS"
self.stride = stride
@staticmethod
def adjust_channels(channels: int, width_multi: float):
return _make_divisible(channels * width_multi, 8)
class InvertedResidual(chainer.Chain):
def __init__(self, cnf, norm_layer):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
# 是否有shortcut连接
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
self.layers = []
activation_layer = Hardswish() if cnf.use_hs else ReLU()
# 这里开始作bneck层了(两边瘦,中间胖)
# 第一个1*1(升维)
if cnf.expanded_c != cnf.input_c:
self.layers += [('conv_bn_act_1',ConvBNActivation(cnf.input_c, cnf.expanded_c, kernel_size=1, norm_layer=norm_layer, activation_layer=activation_layer))]
# 深度可分离卷积
self.layers += [('conv_bn_act_2',ConvBNActivation(cnf.expanded_c, cnf.expanded_c, kernel_size=cnf.kernel, stride=cnf.stride, groups=cnf.expanded_c, norm_layer=norm_layer, activation_layer=activation_layer))]
# 注意力机制
if cnf.use_se:
self.layers += [('se1',SqueezeExcitation(cnf.expanded_c))]
# 1*1卷基层(降维)
self.layers += [('conv_bn_act_3',ConvBNActivation(cnf.expanded_c, cnf.out_c, kernel_size=1, norm_layer=norm_layer, activation_layer=None))]
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
short_cut = x
for n, f in self.layers:
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
if self.use_res_connect:
return short_cut + x
return x
class MobileNet_V3(chainer.Chain):
cfgs = {
'mobilenetv3_large':None,
'mobilenetv3_small':None
}
def __init__(self,model_name = 'mobilenetv3_large',channels=3,
width_multi=1.0,reduced_tail=False,batch_size=4,
num_classes: int = 1000,image_size = 244,
block = None,
norm_layer = None):
super(MobileNet_V3, self).__init__()
bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)
adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)
reduce_divider = 2 if reduced_tail else 1
self.image_size = image_size
if model_name == 'mobilenetv3_large':
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, False, "RE", 1),
bneck_conf(16, 3, 64, 24, False, "RE", 2), # C1
bneck_conf(24, 3, 72, 24, False, "RE", 1),
bneck_conf(24, 5, 72, 40, True, "RE", 2), # C2
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 5, 120, 40, True, "RE", 1),
bneck_conf(40, 3, 240, 80, False, "HS", 2), # C3
bneck_conf(80, 3, 200, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 184, 80, False, "HS", 1),
bneck_conf(80, 3, 480, 112, True, "HS", 1),
bneck_conf(112, 3, 672, 112, True, "HS", 1),
bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2), # C4
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1),
]
last_channel = adjust_channels(1280 // reduce_divider) # C5
if model_name == 'mobilenetv3_small':
inverted_residual_setting = [
# input_c, kernel, expanded_c, out_c, use_se, activation, stride
bneck_conf(16, 3, 16, 16, True, "RE", 2), # C1
bneck_conf(16, 3, 72, 24, False, "RE", 2), # C2
bneck_conf(24, 3, 88, 24, False, "RE", 1),
bneck_conf(24, 5, 96, 40, True, "HS", 2), # C3
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 240, 40, True, "HS", 1),
bneck_conf(40, 5, 120, 48, True, "HS", 1),
bneck_conf(48, 5, 144, 48, True, "HS", 1),
bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(L.BatchNormalization, eps=0.001)
self.layers = []
# 第一层 #224*224*3 -> 112*112*16
firstconv_output_c = inverted_residual_setting[0].input_c
self.layers += [('conv_bn_act_1',ConvBNActivation(channels, firstconv_output_c, kernel_size=3, stride=2, norm_layer=norm_layer, activation_layer=Hardswish()))]
output_size = int((self.image_size-3+2*((3-1)//2))/2+1)
# 遍历 residual blocks
layer_num = 0
for cnf in inverted_residual_setting:
layer_num +=1
self.layers += [('block{0}'.format(layer_num),block(cnf, norm_layer))]
output_size = math.ceil(output_size / cnf.stride)
# 最后一层卷基层 7*7*160 -> 7*7*960
lastconv_input_c = inverted_residual_setting[-1].out_c
lastconv_output_c = 6 * lastconv_input_c
self.layers += [('conv_bn_act_2',ConvBNActivation(lastconv_input_c, lastconv_output_c, kernel_size=1, norm_layer=norm_layer, activation_layer=Hardswish()))]
output_size = int((output_size-1+2*((1-1)//2))/1+1)
# 平均池化
self.layers += [('_avgpool',AveragePooling2D(ksize=output_size,stride=1,pad=0))]
self.layers += [('_reshape',Reshape((batch_size,lastconv_output_c)))]
self.layers += [('fc1',L.Linear(lastconv_output_c, last_channel))]
self.layers += [('hs',Hardswish())]
self.layers += [("_dropout1",Dropout(0.2))]
self.layers += [('fc2',L.Linear(last_channel, num_classes))]
with self.init_scope():
for n in self.layers:
if not n[0].startswith('_'):
setattr(self, n[0], n[1])
def forward(self, x):
for n, f in self.layers:
origin_size = x.shape
if not n.startswith('_'):
x = getattr(self, n)(x)
else:
x = f.apply((x,))[0]
print(n,origin_size,x.shape)
if chainer.config.train:
return x
return F.softmax(x)
注意此类就是MobileNetV3的实现过程,注意网络的前向传播过程中,分了训练以及测试。
训练过程中直接返回x,测试过程中会进入softmax得出概率
调用方式
if __name__ == '__main__':
batch_size = 4
n_channels = 3
image_size = 224
num_classes = 123
model = MobileNet_V3(num_classes=num_classes, channels=n_channels,image_size=image_size,batch_size=batch_size)
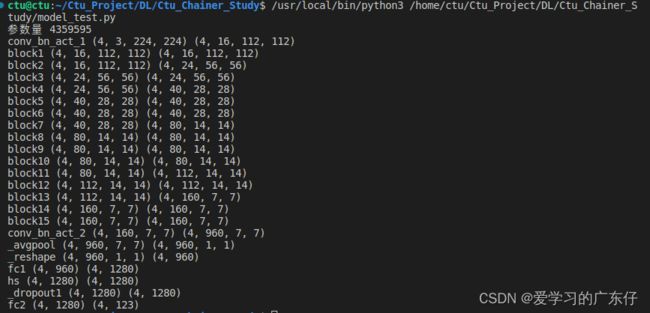
print("参数量",model.count_params())
x = np.random.rand(batch_size, n_channels, image_size, image_size).astype(np.float32)
t = np.random.randint(0, num_classes, size=(batch_size,)).astype(np.int32)
with chainer.using_config('train', True):
y1 = model(x)
loss1 = F.softmax_cross_entropy(y1, t)