cvday13(Basic和Basicvsr的实现)
basic训练结果,用的是vimeo90k的数据集,模型basic,跑了20min
Eval-PSNR: 37.19113475287104 最大峰值信噪比
(在图像质量评价指标中,有一个指标是PSNR(Peak Signal-to-Noise Ratio) 峰值信噪比,它正好对标L1和L2损失函数,但L1和L2是有一个共性:它们都是基于逐像素比较差异,没有考虑人类视觉感知,更没有考虑人的审美观,所以PSNR指标高,并不一定代表图像质量好。)
Eval-SSIM: 0.9451216528070878( SSIM(结构相似两张图片的对比)损失函数:考虑了亮度 (luminance)、对比度 (contrast) 和结构 (structure)指标,这就考虑了人类视觉感知,一般而言,SSIM得到的结果会比L1,L2的结果更有细节)
有些的实验的损失函数用的是l1和ssim组合起来的一个损失函数。
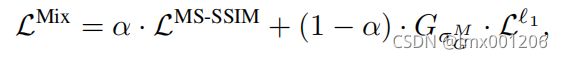
而这篇的是用的是PSNR就是L1损失函数,然后定义了一个SSIM。
然后深度学习的pkl文件就是,跑代码模型训练数据,得到的中间参数啥的。比如本次实验就是可以看到,7080张图片的psnr和ssim。
import pickle
fr = open("work_dirs/vsr_exp/results.pkl", 'rb')
inf = pickle.load(fr)
print(inf)
对这个实验细节的分析:
test.py文件中基本看不出个啥东西,没有对网络什么的介绍都没有。
bascivsr_vimeo90k_bi.py中能看到model settings:
mid_channels=64, num_blocks=30,然后并且利用的是spynet来计算光流的模型:空间金字塔方法与深度学习。
并且设计的fix_iter=5000(即迭代次数是5000)这是在特征提取和光流估计这里模块的权重,在这补充epoch,iter,batchsize的关系:
epoch时期:一个epoch是指将所有训练样本都训练一遍
batchsize批次大小:是指在一次迭代中样本的个数,也即批梯度下降中用来进行一次参数更新的样本数
iter:是指完成一个epoch所需的迭代次数
因此,总样本数/batchsize=iter
总的迭代次数=iter*epoch
在训练样本数通常大于测试样本数,因此训练时的iter也大于测试时的iter。
train_pipeline、val、demo、test都有一个pipeline:
flip_ratio=0.5(翻转率)论文中的解释是可以通过翻转原始序列来临时增加输入序列以获得更长的传播。
channel_order='rgb gt_patch_size=256)
从数据模块data中可以发现载入数据都是啥很清晰,这就是解决了之前的那个报错。它这里都固定了文件的命名
然后发现它的data里面还定义了一个scale=4,在网上找到scale指的是该层特征图的每个像素点等价于原始输入图像中几个像素。通过那个标注信息我发现,正是尺度是4倍。256,448,3.这是开始标注的信息,但是之后是前两个乘4。
还有论文中说到相当于输入是14,但是代码中设计的是num_input_frames=7,所以这也代表了那个翻转率设置的好处就在于此。
然后优化器模块用的是Adam,lr学习率2e-4这些参数一般都是默认设置。
补充:模型结构,blocks是残差模块数量。特征通道设置的是64
mid_channels=64, num_blocks=30,
然后++里面是残差模块只有7个,特征通道仍然是64。