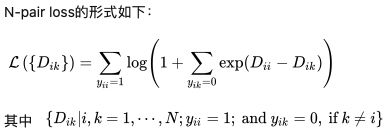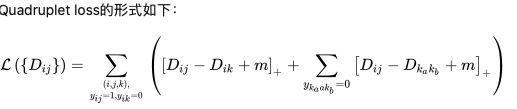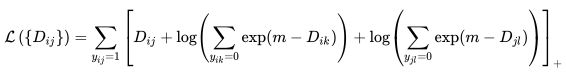定义
Metric learning 是学习一个度量相似度的距离函数:相似的目标离得近,不相似的离得远.
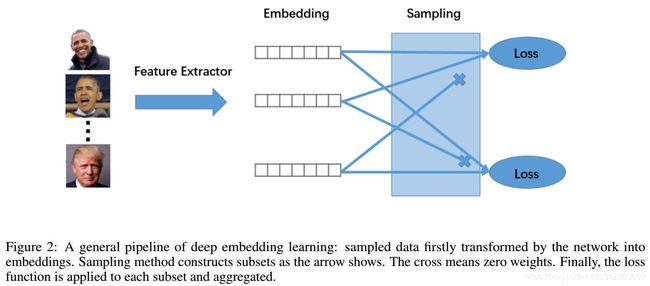
一般来说,DML包含三个部分, 如下图.。
1)特征提取网络:map embedding
2)采样策略:将一个mini-batch里的样本组合成很多个sub-set
3)loss function:在每个sub-set上计算loss.
应用场景
通常是在个体级别的细粒度识别上使用,传统的分类是花鸟狗的大类别的识别,但是有些需求是要精确到个体级别,比如精确到哪个人的人脸识别,还有一种场景是训练和部署的类别不同,比如训练只有100个人,部署需要分辨200人,所以triplet loss的最主要应用也就是:人脸识别、人脸验证、图像检索、签名验证、行人重识别等。
为什么不用分类:
1)这类场景用分类往往最后会造成softmax的维数远大于feature的维数,想想resnet50 global ap出来- -个2048的feature对应到一 -个几万,几十万的分类softmax就可怕。
2)triplet loss通常能比classification得到更好的feature(这个需要实验,因为网上有人的场景比分类高10个点,拍照购陈越测试分类更好)
3)triplet loss可以卡阈值, triplet losi训练的时候要设置- 个margin, 这个margin可以控制正负样本的距离,当feature 进行normalization之后,可以更加方便的卡个阈值来判断是不是同一个ID。(这个同样存疑,因为加了margin的分类,也可以卡阈值)。
度量学习缺点:依赖采样的策略,如果采样策略过简单,只会学习到简单的样本,无法继续训练;如果采样过难,会导致收敛慢、不收敛,甚至过拟合。(2015年度量学习的思路已经具备,主要还是看采样即困难样本的挖掘)
一、特征提取网络
参考各类分类等的主干网络
二、损失函数
主要讲两个大类:对比损失(contrastive loss)和三元组损失(triplet loss),其中项目中用的多的还是三元组损失,所以重点理解和掌握三元组其余建议了解即可。
注意:
1)这两种loss函数如果单独使用则会遭遇收敛速度慢的问题(三元组的选取导致数据的分布并不一定均匀,所以在模型训练过程表现很不稳定,而且收敛慢,需要根据结果不断调节参数,而且Triplet loss比分类损失更容易过拟合。)。
2)样本空间的量级( ( 2 ) O(N^2) O ( N 2 ) 或者 ( 3 )O(N^3) O( N3 ))非常大,在学习过程的后期,大多数样本都能满足损失函数的约束条件,这些样本对应进一步学习的贡献很小。因此,这两种损失函数都需要配合hard sample mining的学习策略一起使用。
3)大多数情况下,我们会把这种方法放在模型的预训练过程中,或者和softmax函数(分类损失)结合在一起使用。
对比损失
1、思想为:
正样本对尽可能的近,负样本对尽可能的远,这样可以增大类间差异,减小类内差异。具体为 ,取一样本对,如果:
1) 是正样本对,则其产生的loss就应该等于其特征之间的距离 (例如L2 loss);因为我们的期望是他们之间的距离为0,所以凡是大于零的loss都需要被保留。
2) 如果是负样本对,他们之间的距离应该尽可能的大,至于应该大到多少则由我们人为的设定,假设设定的阈值为 m ,如果距离大于 m,其loss为0,不需要对模型进行更新了,如果小于 m,则认为模型还不够好,需要继续训练。
2、缺点:
需要指定一个固定的margin,即公式中的 m ,因为 m 是固定的,所以这里就隐含了一个很强的假设,即每个类目的样本分布都是相同的,不过一般情况下这个强假设未必成立。
例如,有一个数据集有三种动物,分别是狗、狼 、猫,直观上狗和狼比较像,狗和猫的差异比较大,所以狗狼之间的margin应该小于狗猫之间的margin,但是Contrastive loss使用的是固定的margin,如果margin设定的比较大,模型可能无法很好的区分狗和狼,而margin设定的比较小的话,可能又无法很好的区分狗和猫。
三元组损失
1、思想为:
让负样本对之间的距离大于正样本对之间的距离。
Triplet-Loss的效果比Contrastive Loss的效果要好,因为他考虑了正负样本与锚点的距离关系。
当负样本对之间的距离比正样本对之间的距离大m的时候,loss为0 ,认为当前模型已经学的不错了,所以不对模型进行更新。
公式如下:
2、margin选择
对于阈值margin的设置需要注意选择合适大小的值,理论上来说,较大的margin能够增强模型对不同类样本的区分度,但是如果在训练初期就将margin设置得比较大,则可能会增加模型训练的难度,进而出现网络不收敛的情况。在模型训练初期先使用一个较小的值对网络进行初始化训练,之后再根据测试的结果对margin的值进行适当的增大或缩小,这样可以在保证网络收敛的同时让模型也能拥有一个较好的性能。
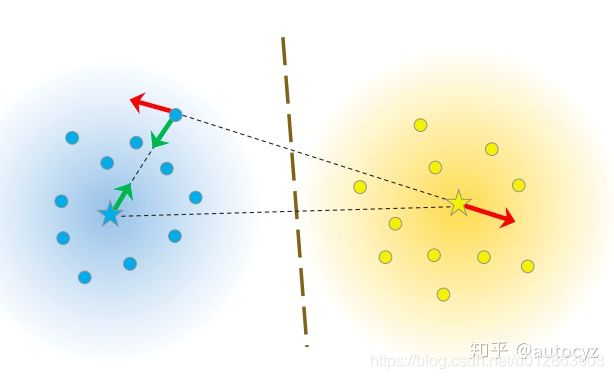
3、困难样本挖掘
如上图, 理论上讲,使用hard triplets训练模型最好,因为这样模型能够有很好的学习能力,但由于margin的存在,这类样本可能模型没法很好的拟合,训练比较困难;其次是使用semi-hard triplet,这类样本是实际使用中最优选择,因为这类样本损失不为0,而且损失不大,模型既可以学习到样本之间的差异,又较容易收敛;至于easy triplet,损失为0,不用拿来训练。
针对不同的业务,其实构造的原则也不一样,比如人脸识别场景,选择semi-hard triplets样本,这样一来,损失函数的公式不容易满足,也就意味着损失值不够低,模型必须认真训练和更新自己的参数,从而努力让d(a,n)的值尽可能变大,同时让 d(a,p) 的值尽可能变小。
1)离线挖掘
训练集所有数据经过计算得到对应的embedding,根据embedding计算得到(a,p)和(a,n)之间的距离,根据这个距离判断三元组属于semi-hard triplets,hard triplets还是easy triplets中的哪一类。Offline triplet mining 仅仅用于选择hard或者semi-hard的三元组类型,因为easy triplet太容易了,没有必要训练。总得来说,这个方法效率不高。
1)离线挖掘
训练集所有数据经过计算得到对应的embedding,根据embedding计算得到(a,p)和(a,n)之间的距离,根据这个距离判断三元组属于semi-hard triplets,hard triplets还是easy triplets中的哪一类。Offline triplet mining 仅仅用于选择hard或者semi-hard的三元组类型,因为easy triplet太容易了,没有必要训练。总得来说,这个方法效率不高。
2)在线挖掘(不要慌,使用pytorch实现均仅仅需要几行代码便可实现)
为每一batch动态挖掘有用的三元组,即只计算batch中的triplets。假设一个batch的数据有P个人,每人K张图片,则共包含P*K张人脸。针对valid triplet的挑选(即构成A-P-N对),有如下两种策略:
Batch all:计算所有的valid triplet,对hard 和 semi-hard triplets上的loss进行平均(easy triplets不参与计算,平均会导致loss很小),可以得到PK(K-1)(PK-K)个三元组。
Batch hard: 对于每一个锚点,选择距离最大的正样本(a,p)和距离最小的负样本(a,n),可以得到PK个三元组。
加权:对于每一个锚点,通过样本到anchor的最大距离加权计算所有样本到anchor的距离的加权和(正负样本同理),可以得到PK个三元组(逻辑上其实并不再是真实存在的三元组,为加权均值,包含easy,semi-hard 和hard)。
再详细理解可以参考:https://zhuanlan.zhihu.com/p/266916361
Fastreid(截止20210730)实现了batch hard 和加权的功能,,可以参考对应的实现:https://github.com/JDAI-CV/fast-reid/blob/master/fastreid/modeling/losses/triplet_loss.py
Triplet center loss
triplet样本的选取至关重要,如果选取的triplet对没啥难度,模型不更新;而如果使用hard mining的方法对难例进行挖掘,又会导致模型对噪声极为敏感。
Triplet Center loss的思想非常简单,原来的Triplet是计算anchor到正负样本之间的距离,现在Triplet Center是计算anchor到正负样本所在类别的中心的距离。类别中心就是该类别所有样本embedding向量的中心。
N-pair loss
triplet loss同时拉近一对正样本和一对负样本,这就导致在选取样本对的时候,当前样本对只能够关注一对负样本对,而缺失了对其他类别样本的区分能力。
为了改善这种情况,N-pair loss就选取了多个负样本对,即一对正样本对,选取其他所有不同类别的样本作为负样本与其组合得到负样本对。如果数据集中有 N个类别,则每个正样本对 yii都对应了N-1个负样本对。
Quadruplet loss
Quadruplet loss由两部分组成:
1)正常的triplet loss,这部分loss能够让模型区分出正样本对和负样本对之间的相对距离。
2)正样本对和其他任意负样本对之前的相对距离。这一部分约束可以理解成最小的类间距离都要大于类内距离,不管这些样本对是否有同样的anchor。即不仅要要求 A1A2
Lifted Structure Loss
思想是对于一对正样本对而言,不去区分这个样本对中谁是anchor,谁是positive,而是让这个正样本对中的每个样本与其他所有负样本的距离都大于给定的阈值。此方法能够充分的利用mini-batch中的所有样本,挖掘出所有的样本对。
三、采样策略
最自然的就是按loss里面的项每一对样本都算距离,那么就是N*N对。
其他的策略详见上面对应的损失函数。
参考链接:
1、 https://zhuanlan.zhihu.com/p/68200241
2、 https://zhuanlan.zhihu.com/p/72516633
3、 https://www.cnblogs.com/luckforefforts/p/13642695.html
4、 https://blog.csdn.net/zenglaoshi/article/details/106928204
5、 https://bindog.github.io/blog/2019/10/23/why-triplet-loss-works/
6、 https://flashgene.com/archives/151266.html
7、 https://blog.csdn.net/zenglaoshi/article/details/106928204
8、 https://zhuanlan.zhihu.com/p/266916361