Neighbor2Neighbor: Self-Supervised Denoising from Single Noisy Images
下面内容来自智源研究院CVPR2021预讲华为诺亚专场
1、深度学习的图像去噪方法面临的挑战
当前方法主要包括三类:
- 基于监督学习的方法:使用 noisy-clean 图像对进行训练(DnCNN, FFDNet, CBDNet, SGNet)。这类方法的难点在于,在真实场景中,比较难以获取 noisy-clean 的图像对
- Noise2Noise(ICML18): 使用 Noisy-noisy 图像对进行训练,每个场景都需要 multiple independent observations 。在应用上有局限性:室内静态场景、MRI重建等
- 基于自监督的方法: 1)单张图像自身信息挖掘,代表方法是Deep image prior, Self2self, NoiseAsClean;2)Blind-spot network: 需要修改网络结构,训练困难,性能有限(noise2void,DBSN);3)噪声建模方法:预测噪声分布,在实际场景中难以应用(Laine19)
2、Noise2Noise回顾
Noise2Noise是一个不需要 clean 数据的图像修复方法:
- Train arbitrary denosing network without the need of clean images.
- Requires pairs of independent noisy images of the same scene.
训练目标:
- Given two indpendent noisy observations , of the same unobserved image
- minimizing yields the same solution as fully-supervised (noisy-clean pair) training
访方法的局限性:需要采集同一场景噪声独立的多个图像,这个对于动态场景(户外,或者自拍)比较困难。
因此,本工作的 motivation 就来了,构建更通用的Noise2Noise,有两个假设:
- 假设一:Noise2Noise是对一个场景进行多个采样用于训练,能不能对相似的场景进行多个采样进行训练?这样就可以降低数据采集的难度(independent noisy observation of similar scenes)
- 假设二:能不能每个场景使用一个含噪图像就训练整个网络?(One noisy observation per scene)
3、Neighbor2Neighbor
对于假设一: Neighbor2Neighbor使用ground truth相似的图片进行训练(Noise2Noise使用同一张图片的多个噪声图进行训练)。论文中有一个推导,表明找到相似但不相同的含噪图像 和 时,可以训练降噪网络。
对于假设二: 从含噪图像 采样出来的多个图像,被称为neighbors。作者构建了一个带约束的优化问题,具体可以参考作者论文。
整体框架如下图所示。对于含噪图像,进行两个采样得到 和 。然后把用降噪网络处理后的图像 与 做一个 loss ,这部分就是 Pseudo Noise2Noise。同时,构建第二个 loss ,也就是正则项。

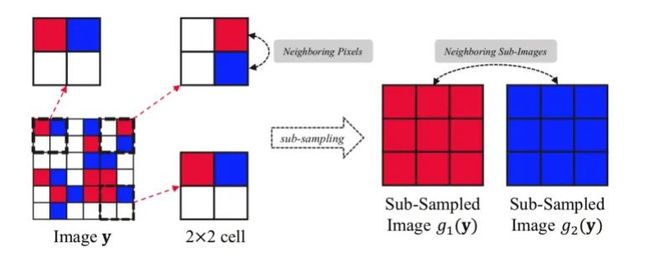
接下来还有一个问题,就是 和 要非常的相似,如何构造这个非常相似的采样呢 ?论文中有一个图示,把图像拆分为好多 的 cell (下图中 )。在每个 cell 中随机选两个像素,一个归 ,另一个归 ,这样就可以构建两个采样的子图。

4、实验结果
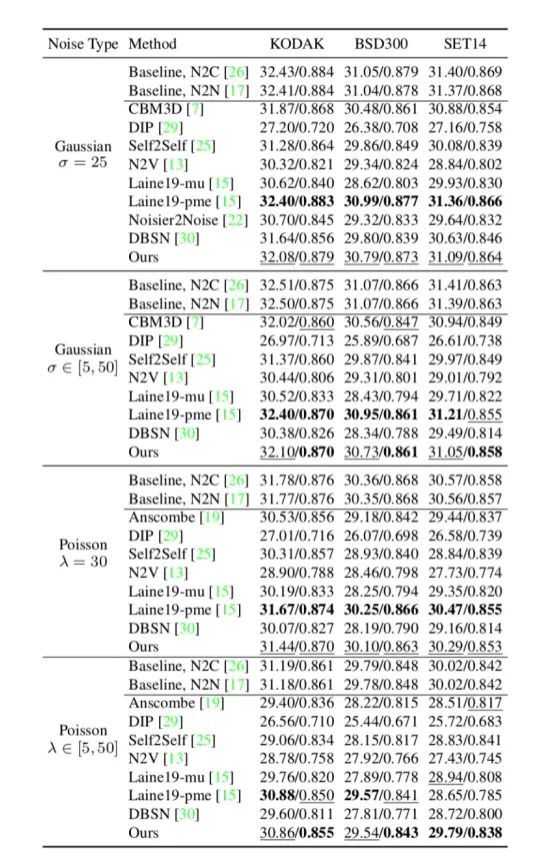
第一个实验是在合成的 RGB 数据集(加高斯噪声)上进行测试,可以看到比 noisy-clean 和 noise2noise 大约低 0.3db。性能比其它自监督的方法性能要明显好,同时,和英伟达 Laine19这个方法相比,性能是差不多的。

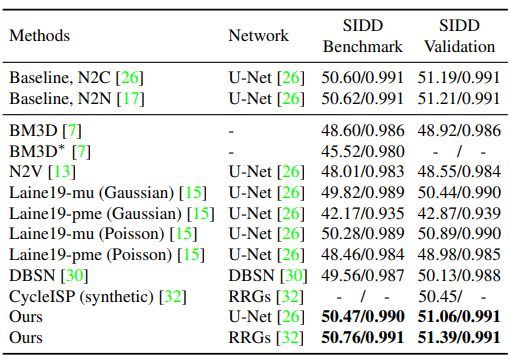
第二个实验是真实专景RAW图像的降噪(SIDD数据集)。与N2C相比,PSNR值低 0.1db。但是性能比其它自监督的方法要好。同时,如果使用更好的网络(RRG),性能会得到明显提升。
接下来的实验是 Ablation study,分析了正则项 的作用。当 值增大时,越来越多的细节保留越多,随之噪声也增多。

本文为52CV粉丝投稿,介绍了CVPR 2021论文 Neighbor2Neighbor: Self-Supervised Denoising from Single Noisy Images ,一种用于图像降噪的自监督学习方法。
作者丨黄涛,李松江,贾旭,卢湖川,刘健庄
单位|中国人民大学,华为诺亚,大连理工大学
审稿丨邓富城
编辑丨极市平台
导读
本文中,我们提出了Neighbor2Neighbor:一种仅需要含噪图像即可训练任意降噪网络的方法。该方法是一种训练策略,可以训练任意降噪网络而无需改造网络结构、无需估计噪声参数,也无需对输出图像进行复杂的后处理。
1. 简介
传统的图像降噪方法中,比较简单的方法降噪效果往往很有限,而降噪效果较好的方法、如BM3D等,又因其巨大的计算量而难以实现实时的运行。随着深度学习的出现和发展,基于神经网络的图像降噪方法逐渐得到了广泛的应用。现有的全监督图像降噪网络(例如DnCNN、FFDNet、CBDNet、SGNet等)需要在大量Noisy-Clean配对图像构成的数据集上训练,而构造Noisy-Clean图像配对是十分困难的。
一方面,很多研究者在干净图像上添加模拟的噪声生成合成的Noisy-Clean配对,由于模拟的噪声与真实图像的噪声存在较大的差异,在合成数据集上训练的方法,在真实数据上的泛化性能往往十分糟糕;
另一方面,采集真实的Noisy-Clean图像对往往需要特殊的设备、或者局限在静态的场景。动态场景、或者医学图像场景,构造真实的Noisy-Clean配对至今仍是一个十分具有挑战性的问题。
为了解决真实场景的图像降噪训练问题,研究者们提出了一系列具有开创性的工作。Noise2Noise提出通过对同一个场景拍摄多张独立的含噪图像即可训练降噪网络,缓解了对干净图像的采集需求。
然而,同一个场景多张独立含噪图像这个要求也是十分苛刻的,对于动态场景、医学图像等场景仍然不具有可行性。之后,Noise2Void、DBSN等方法提出通过限制卷积的感受野,将网络改造成感受野受限的网络,从而实现无需干净图像、无需多张含噪图像的自监督图像降噪。
尽管这一类方法具有一定的可行性,但是其复杂的网络改造流程、缓慢的训练过程和相对较差的降噪效果仍限制了它们的应用价值。也有一些方法通过假定噪声的分布,用后处理的方式增强降噪效果,但是真实图像的噪声往往难以估计,因而其在真实图像上的利用价值有限。
于此同时,还有一类方法,如DIP、Self2Self等,通过学习图像、噪声的先验,对单张含噪图像进行训练,实现了很好的降噪效果。但是这一类方法一张图片需要训练一个模型,不具有泛化能力。
综上可见,现有的无需干净图像的图像降噪方法往往都有额外的约束,而这些约束也很大程度上限制了这些方法的实用性。因此,一种无需干净图像、无需网络改造、无需假定噪声模型的图像降噪方法是十分有意义的。
本文中,我们提出了Neighbor2Neighbor:一种仅需要含噪图像即可训练任意降噪网络的方法。本方法是Noise2Noise的扩展,通过理论分析将Noise2Noise推广到了单张含噪图像和相似含噪图像这两个场景,并通过设计采样器的方式从单张含噪图像构造出相似含噪图像。
随后通过引入正则项的方式解决了采样过程中相似含噪图像采样位置不同而导致的图像过于平滑的问题。本方法是一种训练策略,可以训练任意降噪网络而无需改造网络结构、无需估计噪声参数,也无需对输出图像进行复杂的后处理。
2. 从Noise2Noise到Neighbor2Neighbor
Noise2Noise的核心思想是,对于一个未观察的干净场景 和观察到的两张独立含噪图像 ,在噪声是服从零均值的情况下,用 配对训练的降噪网络和用 配对训练的网络是等价的。Noise2Noise的优化目标是:
由于Noise2Noise要求每一个场景 至少有2张独立的含噪图像 ,这在真实场景中也难以满足。因此,为了增加Noise2Noise的实用价值,我们考虑对Noise2Noise的理论进行一定的扩展,主要考虑以下两个方面:
-
同一场景的两张独立含噪图像相似场景的两张独立含噪图像
-
每个场景多张含噪图像每个场景单张含噪图像。
我们首先考虑第一点,即相似场景的两张独立含噪图像的情况。假设有一个干净图像 ,其对应的含噪图像是 ,即 ;当引入一个非常小的图像差 时, 是另一张含噪图像 对应的干净图像,即 ,则有:
上式表明,在相似含噪图像 所对应的干净图像( 和 )并不相等的情况下,通过 直接构造训练对使用Noise2Noise训练降噪网络并不能得到与 配对相同的结果。进一步分析可以发现,当 时, ,此时 配对可以作为Noise2Noise的一种近似。因此,一旦找到合适的满足"相似但不相同"条件的 , 就可以训练降噪网络。
对于单张含噪图像而言,构造两张"相似但不相同"的图像的一种可行方法是采样。在原图的相邻但不相同的位置采样出来的子图很显然满足了相互之间的差异很小,但是其对应的干净图像并不相同的条件(即 )。给定一张含噪图像 ,我们构造出一对近邻采样器 ,采样出两张子图 ,我们直接用这两张子图构造配对,以类似Noise2Noise的方式训练降噪网络,则有:
我们把这种方式成为Pseudo Noise2Noise。由于 采样的位置不同,即:
直接应用Pseudo Noise2Noise的方式训练,得到的去噪模型不是最优的,会导致过度平滑。因此我们考虑在loss上增加正则项的方式对这种情况进行修正。假设有一个理想的降噪网络 ,它具有理想的降噪能力,即:
则这个理想的降噪网络 满足:
因此,我们考虑在Pseudo Noise2Noise的基础上增加一个约束,即:
此时,带约束的优化问题转化为带正则的优化问题:
至此,我们完成了Neighbor2Neighbor的理论推导。
3. 框架和流程
本方法的训练和推理过程如下图所示:
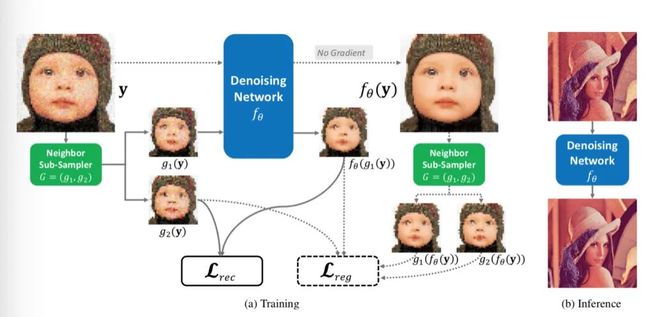
训练策略上,从单张含噪图像 通过采样器G构造出两张子图 ,通过这两个子图构造重建损失函数;之后,对原图 进行推理降噪,得到的降噪图像再通过同样的采样过程G生成两张子图,最后计算正则项。训练好的网络可直接用于图像降噪,无需进行后处理。
对于采样器G,我们设计了近邻采样,即将图像划分成 的单元,在每个单元的四个像素中随机选择两个近邻的像素分别划分到两个子图中,这样构造出来两张"相似但不相同"的子图,我们称他们为"Neighbor"。
4. 实验
为了验证Neighbor2Neighbor在图像降噪上的效果,我们在合成的RGB域和真实的RAW域噪声数据集上进行了实验。为了更公平地进行比较,我们采用同样结构的UNet,分别用全监督(Noise2Clean, N2C)、Noise2Noise (N2N)和其他自监督降噪方法进行训练,并比较数值上的性能(PSNR/SSIM)和视觉效果差异。
在RGB域合成数据上,我们分别测试了Gaussian和Poisson噪声,每种噪声分别尝试了固定噪声水平和动态噪声水平两种情况。数值比较的结果如下表所示。结果表明,在多个测试集上,本方法在性能上比使用配对数据训练的方法(N2C)低0.3dB左右,超越了现有的自监督降噪方法。在动态噪声水平的场景下,本方法显著超越其他自监督方法,甚至与自监督+后处理的Laine19不相上下,这更进一步说明了本方法的有效性。


为了更进一步验证Neighbor2Neighbor的有效性,我们在噪声情况更加复杂的真实RAW域数据集SIDD进行比较实验。可以发现,对于真实的Raw域噪声,由于比较复杂且难以用简单的噪声模型进行估计,依赖后处理的方法(Laine19)效果较差,失去了在合成数据上的优势。
而我们的Neighbor2Neighbor则依然表现出良好的降噪效果,与N2C差异在0.1dB左右,视觉效果上的差异也不显著。换用表达能力更强的网络(UNetRRG)之后,降噪效果能到进一步的提升,这表明我们的方法可以随着网络表达能力的增强而进一步增强。


最后,我们做了一个简单的消融实验来验证正则项的有效性。我们从0开始逐渐增加正则项的权重,观察模型在不同噪声场景下的性能变化。结果如下表所示。可见,当权重为0时,Neighbor2Neighbor退化为Pseudo Noise2Noise,此时模型的PSNR/SSIM水平较低,而网络输出的图像过于模糊而损失了大部分的细节信息;
随着权重增加,模型的PSNR/SSIM开始提高,此时降噪的图像开始保留更多的细节,但是噪声也被更多地保留下来。而当权重太大的时候,模型的PSNR/SSIM开始降低,而降噪图像也变得更加Noisy。
由此可见,正则项起到了平衡降噪能力和细节保留的作用。针对不同的场景,选择合适的权重,可以发挥出Neighbor2Neighbor的最佳效果。


END