1.15学习记录
14 【numpy数组】01numpy的数组的创建
数组的创建及数组类型的操作
# -*- coding=utf-8 -*-
import numpy as np
import random
#创建数组
t1=np.array([1,2,3])
t2=np.array(range(10))
t3=np.arange(10)#快速生成数组和np.array(range(10))一样的效果
#都是nparray 的类型
print(t3.dtype)# 查看对象的数据类型
#numpy中的数据类型
t4=np.array(range(1,4),dtype=float) #指定特定的数据类型
#numpy中的bool类型
t5=np.array([1,1,0,1,0,0],dtype=bool) #指定为布尔类型
#调整数据类型
t6=t5.astype("int") #astype 改变数据类型
#numpy中的小数
t7=np.array([random.random() for i in range(10)]) #10个小数,从0到1
print(t7)
t8=np.round(t7,2)#保留2位小数
15 【numpy数组】02数组的计算和数组的计算
数组的形状,表示几行几列
shape 命令
t4=np.arange(12)
t5=np.arange(24).reshape(2,3,4)# 2块 每块里边3行 4列
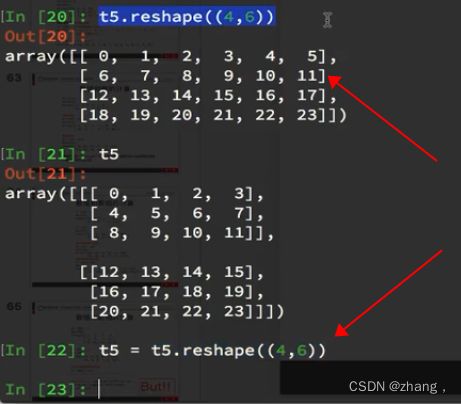
t5.reshape(4,6) #得到一个新的值返回值,不会对本人t5这个发生什么改变
t5.reshape(24,1)#24行1列
t5.reshape(1,24)#1行24列 但是是有两个[[]]表示的是二维的数组
t6=t5.reshape((t5.shape[0]*t5.shape[1],)) #shape[0]表示行 shape[1]表示列 传入具体的行数列数
t5.flatten() #将数组展开 展开成一维的
数组的计算
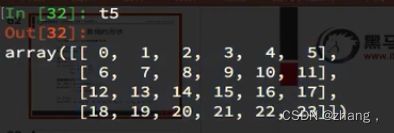
t5+2 #广播机制,对每个数都+2,对每个都进行这么操作
数组和数组的计算
t6=np.arrange(100,124).reshape(4,6)
t5+t6 #当形状一样时对应位置的数字进行计算
t7=np.arrange(0,6)
t5-t7 #t5对t7的每一行进行计算,在行的维度上都进行计算
t8=np.arrange(4),reshape((4,1))
t5-t8 #在每一列上都对t5进行计算
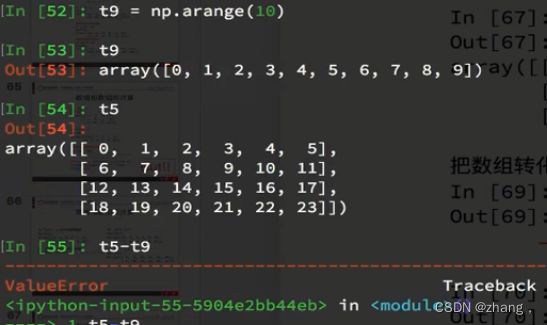
t9=np.arrange(10)
t5-t9 # 长度不一样,在这里直接报错了 简单理解,只要有行或者列相同 (扩展为后缘维度相同)就能进行计算
16 【numpy读取本地数据和索引】01numpy读取本地数据
在numpy中可以理解为方向,使用0,1,2…数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2, 3)),有0(块方向),1(行方向),2(列方向)轴
有了轴的概念之后,我们计算会更加方便,比如计算一个2维数组的平均值,必须指定是计算哪个方向上面的数字的平均值
那么问题来了:
在前面的知识,轴在哪里?
回顾np.arange(0,10).reshape((2,5)),reshpe中2表示0轴长度(包含数据的条数)为2,1轴长度为5,2X5一共10个数据
import numpy as np
us_file_path="./video_data/US_video_data_numbers.csv"
uk_file_path="./video_data/GB_video_data_numbers.csv"
#t1=np.loadtxt(us_file_path,delimiter=",",dtype=np.int,unpack=True)#相当于转置了一下,行变列,列变行
t2=np.loadtxt(us_file_path,delimiter=",",dtype=np.int)
# print(t1)
# print("*"*100)
print(t2)

#转置的
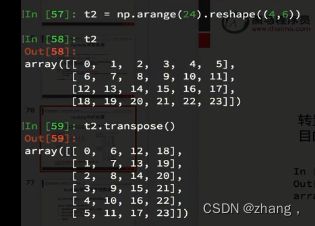
t2=np.arrange(24).reshape((4,6))
t2.transpose()
t2.T
t2.swapaxes(1,0)#交换轴,行和列变一下,也就是转换。
解决问题的思路
1 我们想要反映出什么样的结果,解决什么问题?
2 选择什么样的呈现方式?
3 数据还需要做什么样的处理?
4 写代码
17 【numpy读取本地数据和索引】numpy中的索引和切片

对于取数值的行列操作
# -*- coding=utf-8 -*-
import numpy as np
us_file_path="./video_data/US_video_data_numbers.csv"
uk_file_path="./video_data/GB_video_data_numbers.csv"
#t1=np.loadtxt(us_file_path,delimiter=",",dtype=np.int,unpack=True)#相当于转置了一下,行变列,列变行
t2=np.loadtxt(us_file_path,delimiter=",",dtype=np.int)
# print(t1)
# print("*"*100)
print(t2)
#取行
print(t2[2])
#取连续的多行
#print(t2[2:])
#取不连续的多行
# print(t2[[2,8,10]]) #和给开始 结束 步长那种不一样 指定取多行的数据
# #取行
# print(t2[1,:])#, 前边放行,后边放列
# print(t2[2:,:])#表示从第二行开始,到后边。列都要
# print(t2[[2,10,11],:])#取不连续的多行
#取列
# print(t2[:,2:]) #连续的多列 :表示每行都要
# print(t2[:,[0,2]]) #不连续的多列,用[]来指定
# a=t2(2,3) #第三行第四列的数据
# print(a)
# print(type(a)) #取成了 numpy.int64的类型
#取多行多列,如3到5行 2到4列的数据
b=t2[2:5,1:4]#取的是行和列交叉点的位置
# print(b)
c=t2[[0,2],[0,1]] #多个不相邻的点,得到的是点的值 (0,0) (2,1)这样对应的点
18 【numpy读取本地数据和索引】03numpy中更多的索引方式
clip 裁剪 where 三元运算符 判定句 结果 非结果 nan的操作
# -*- coding=utf-8 -*-
import numpy as np
t=np.arange(24).reshape(4,6)
print(t)
np.where(t<10,0,10) #numpy中的三元运算符 把小于10的数换成0 否则的话数换成10
# clip 的操作,裁剪
t.clip(10,18) #把小于或小于等于10的换成10 把大于18或大于等于的换成18
#nan
#t[3,3]=np.nan #不能把浮点数nan换成integer 既nan是浮点型
t=t.astype(float) #把t的内容都换成浮点型
t[3,3]=np.nan #这个时候就可以吧第4行第四列的数值换成nan
19 【numpy中的nan和常用方法】01数据的拼接
其实只是说了下数据的拼接
import numpy as np
t1=np.arange(12).reshape(2,6)
t2=np.arange(12,24).reshape(2,6)
#数组的拼接
np.vstack(t1,t2)#竖直拼接 想一下竖直分割 横着画一条线
np.hstack(t1,t2)#水平拼接 竖着画一条线
#交换数据行列
t=np.arange(12,24).reshape(3,4)
t[[1,2],:]=t[[2,1],:] #行交换
t[:,[0,2]]=t[:,[2,0]] #列交换 想一下[a,b]=[b,a]
20【numpy中的nan和常用方法】02numpy中的随机方法
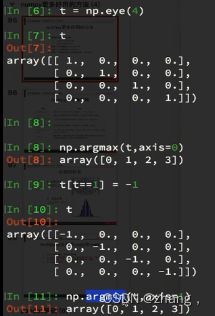
1 获取最大值最小值的位置
1 np.argmax(t,axis=0) #找每一行最大值的位置
2 np.argmin(t,axis=1) #找每一列最小值的位置
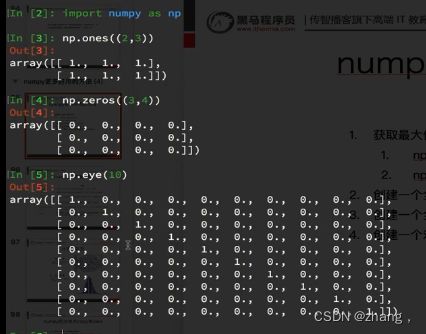
2 创建一个全0的数组: np.zeros((3,4))
3 创建一个全1的数组:np.ones((3,4))
4 创建一个对角线为1的正方形数组(方阵):np.eye(3)
# coding=utf-8
import numpy as np
np.random.seed(10) #种子 锚定了随机数
t=np.random.randint(0,20,(3,4))
print(t)
21 【numpy中的nan和常用方法】03numpy中的nan和常用统计方法
这个顺序乱了 视频和ppt的内容顺序乱了
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf)
比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)

nan的特点

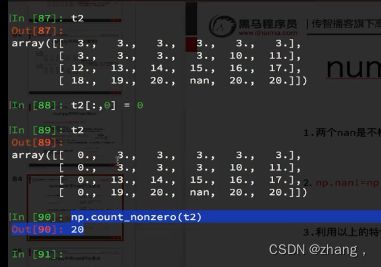
t2!=t2 #只有那个nan位置的数是nan!=nan的,因此t2!=t2
np.count_nonzero(t2!=t2) #数组中有哪些值为nan 既有多少个nan!=nan为真值
np.isnan(t2) #就是用来判断t2哪些值是nan的
np.count_nonzero(np.isnan(t2)) #数组中有哪些值为nan 既有多少个nan!=nan为真值
np.sum(t2) #sum是用来求和的 t2 里边有nan所以求和的结果是nan
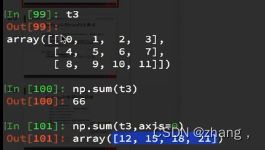
t3=np.arange(12).reshape(3,4)
np.sum(t3)
np.sum(t3,axis=0) #计算行和(竖的加起来),每行对应列相加的结果,0行的列结果轴
注意点:
那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响?(数据失真)
比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者是直接删除有缺失值的一行
那么问题来了:
如何计算一组数据的中值或者是均值
如何删除有缺失数据的那一行(列)[在pandas中介绍]
numpy中常用统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None)
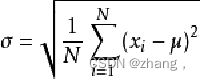
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值反映出数据的波动稳定情况,越大表示波动越大,约不稳定
默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上(对应方向)的结果
22 【numpy中的nan和常用方法】04numpy中填充nan和youtube数据的练习
nan数据处理的练习
#用平均值把nan处理掉
# coding=utf-8
import numpy as np
def fill_ndarray(t1):
for i in range(t1.shape[1]):#遍历t1中的每一列
temp_col=t1[:,i]
nan_num=np.count_nonzero(temp_col != temp_col) #布尔索引
if nan_num!=0: #说明当前这一列中有nan
temp_not_nan_col=temp_col[temp_col==temp_col] #把真值的数取出来 成数组
#求不为nan的列的各自的均值
temp_col[np.isnan(temp_col)]=temp_not_nan_col.mean() #把是nan值的地方换成平均值
#isnan 和==这个意思并不相等,nan是不确定的 两个nan isnan是真值 np.nan==np.nan就是错误的
return t1
if __name__=='__main__':
t1 = np.arange(12).reshape(3,4).astype("float")
t1[1,2:]=np.nan #把第二行第3 4个数赋值成nan
print(t1)
t1=fill_ndarray(t1)
print(t1)
# -*- coding=utf-8 -*-
import numpy as np
from matplotlib import pyplot as plt
us_file_path="./video_data/US_video_data_numbers.csv"
uk_file_path="./video_data/GB_video_data_numbers.csv"
#t1=np.loadtxt(us_file_path,delimiter=",",dtype=np.int,unpack=True)#相当于转置了一下,行变列,列变行
t_us=np.loadtxt(us_file_path,delimiter=",",dtype="int")
#取评论的数据
t_us_comments=t_us[:,-1] #最后一列取-1
#选择比5000小的数据
t_us_comments=t_us_comments[t_us_comments<=5000]
print(t_us_comments.max(),t_us_comments.min())#根据最大值最小值确定组距
d=250 #组距应该选择的比较合适
bin_nums=(t_us_comments.max()-t_us_comments.min())//d
#绘图,绘制散点图表示两组数据的关系
plt.figure(figsize=(20,8),dpi=80)
plt.hist(t_us_comments,bin_nums)
plt.show()
处理数据 把能用到的500000以内的摘出来
# -*- coding=utf-8 -*-
import numpy as np
from matplotlib import pyplot as plt
us_file_path="./video_data/US_video_data_numbers.csv"
uk_file_path="./video_data/GB_video_data_numbers.csv"
#t1=np.loadtxt(us_file_path,delimiter=",",dtype=np.int,unpack=True)#相当于转置了一下,行变列,列变行
t_uk=np.loadtxt(uk_file_path,delimiter=",",dtype="int")
#选择数据时,让x和y的数值对应得上
t_uk=t_uk[t_uk[:,1]<=500000] #选择喜欢数小于50w的对应的数据
t_uk_comment=t_uk[:,-1]
t_uk_like=t_uk[:,1]
t_uk_like[t_uk_like<=500000]
plt.figure(figsize=(20,8),dpi=80)
plt.scatter(t_uk_like,t_uk_comment)
plt.show()