m基于AlexNet神经网络和GEI步态能量图的步态识别算法MATLAB仿真
目录
1.算法描述
2.仿真效果预览
3.MATLAB核心程序
4.完整MATLAB
1.算法描述
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg,GoogLeNet。 这对于传统的机器学习分类算法而言,已经相当的出色。Alexnet网络模型于2012年提出。它具有更高维度的特征提取效果和更深层次的网络结构。第一次,在训练过程中使用了退出机制来防止过度配合。其激活功能使用relu功能并支持GPU训练。Alexnet在更深更广的网络中使用CNN,其效果分类精度更高。Alexnet使用ReLU代替sigmoid,这可以更快地训练,并解决更深网络中的梯度消失问题。Alexnet使用最大池化层来避免平均池化层的模糊性影响,并且步长小于池化核心的步长。这样,池化层输出重叠,从而提高了特征的丰富性。alexnet的网络结构如下:
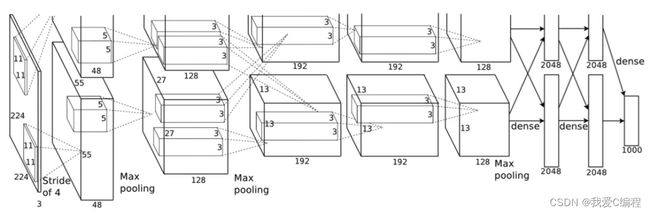
通常,alexnet网络模型由五个卷层和三个全连接层组成。其中,全连接层的输出可以映射1000个分类标签。Alexnet具有大量的模型参数和神经元。模型参数为60m,神经元数为650k。
输入图像为224*224*3。首先,使用96个11*11*3的卷积来进行图像卷积运算,并获得55*55*96的卷积层。然后,在响应归一化和最大池化之后,使用256个5*5*48的卷积来获得第二卷积层,并获得两个27*27*128的卷积层。在第三卷中,使用384个3*3*256的卷积核来获得13*13*192*2个卷积层。在第四卷中,使用384个3*3*192的卷积核来获得13*13*192*2的卷积层。在第五卷中,使用256个3*3*192的卷积核来获得13*13*128*2的卷积层。
AlexNet中包含了几个比较新的技术点,也首次在CNN中成功应用了ReLU、Dropout和LRN等Trick。同时AlexNet也使用了GPU进行运算加速。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
步态识别是一种新兴的生物特征识别技术,旨在通过人们走路的姿态进行身份识别,与其他的生物识别技术相比,步态识别具有非接触远距离和不容易伪装的优点。在智能视频监控领域,比图像识别更具优势。步态是指人们行走时的方式,这是一种复杂的行为特征。罪犯或许会给自己化装,不让自己身上的哪怕一根毛发掉在作案现场,但有样东西他们是很难控制的,这就是走路的姿势。英国南安普敦大学电子与计算机系的马克·尼克松教授的研究显示,人人都有截然不同的走路姿势,因为人们在肌肉的力量、肌腱和骨骼长度、骨骼密度、视觉的灵敏程度、协调能力、经历、体重、重心、肌肉或骨骼受损的程度、生理条件以及个人走路的“风格”上都存在细微差异。对一个人来说,要伪装走路姿势非常困难,不管罪犯是否带着面具自然地走向银行出纳员还是从犯罪现场逃跑,他们的步态就可以让他们露出马脚。
人类自身很善于进行步态识别,在一定距离之外都有经验能够根据人的步态辨别出熟悉的人。步态识别的输入是一段行走的视频图像序列,因此其数据采集与面像识别类似,具有非侵犯性和可接受性。但是,由于序列图像的数据量较大,因此步态识别的计算复杂性比较高,处理起来也比较困难。尽管生物力学中对于步态进行了大量的研究工作,基于步态的身份鉴别的研究工作却是刚刚开始。步态识别主要提取的特征是人体每个关节的运动。到目前为止,还没有商业化的基于步态的身份鉴别系统。
2.仿真效果预览
matlab2022a仿真结果如下:
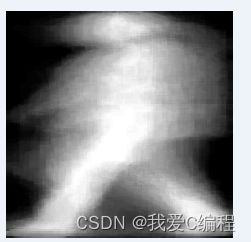
与其他生物识别相比,步态识别具有许多优点,如远距离、非接触等。为了获得良好的识别效果,虹膜识别需要目标在30厘米以内;人脸识别需要目标在3米以内;步态识别需要目标远达50m。不同的体型、头部形状、肌肉骨骼特征、运动神经敏感性、行走姿势等特征决定了步态具有更好的辨别能力。通过复杂的算法设计和海量数据训练,机器可以更好地识别这些细节。首先基于CASIA A数据库来模拟算法的性能,然后基于真实场景来模拟算法性能。CASIA A数据库是2005年1月在室内收集的最大步态数据集。视频大小为320×240,帧数为25fps。数据集中有20名行人。每个人收集了12个序列,包括4个0度序列、4个45度序列和4个90度序 列。因此,序列的总数为240。图4.1显示了CASIA A中的部分步态数据。


3.MATLAB核心程序
GEI = zeros(RR,CC);
CNT = 0;
for ii = 1:length(I1_0)-1
if isempty(I1_0{ii})==0
tmps0 = double(imresize(I1_0{ii},[RR,CC]));
GEI = GEI+tmps0;
CNT = CNT+ 1;
end
end
GEI = GEI/CNT;%得到能量
GEI2(:,:,1) = GEI;
GEI2(:,:,2) = GEI;
GEI2(:,:,3) = GEI;digitDatasetPath = ['步态能量图allt90\'];
imds = imageDatastore(digitDatasetPath,'IncludeSubfolders', true, 'LabelSource', 'foldernames');
%划分数据为训练集合验证集,训练集中每个类别包含1张图像,验证集包含其余图像的标签
numTrainFiles = 2;%设置每个类别的训练个数
[imdsTrain,imdsValidation] = splitEachLabel(imds,10/12);
net = alexnet;
rng(1);
options = trainingOptions('sgdm', ...
'InitialLearnRate', 0.0015, ...
'MaxEpochs', 200, ...
'Shuffle', 'every-epoch', ...
'ValidationData', imdsValidation, ...
'ValidationFrequency', 10, ...
'Verbose', false, ...
'Plots', 'training-progress');
layersTransfer = net.Layers(1:end-3);
layers = [
layersTransfer
fullyConnectedLayer(20,'WeightLearnRateFactor',20,'BiasLearnRateFactor',20)
softmaxLayer
classificationLayer];
%使用训练集训练网络
net = trainNetwork(imdsTrain, layers, options);
05_077_m4.完整MATLAB
V