2022CS231n PPT笔记 - 迁移学习
Index of /slides/2022一切图片来自官网
目录
什么是迁移学习
为什么要迁移学习
迁移学习方式
案例
导包
定义和初始化模型
微调模型
注意事项
什么是迁移学习
别人在一个非常大的数据集上训练CNN,然后我们直接使用该模型(全部或部分)结构和参数,用于自己的目标任务
为什么要迁移学习
- 对于数据集本身很小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠微调已经训练好的模型。In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a dataset of sufficient size.
- 可以降低训练成本:如果使用导出特征向量的方法进行迁移学习,后期的训练成本非常低,用 CPU 都完全无压力,没有深度学习机器也可以做。
- 前人花很大精力训练出来的模型在大概率上会比你自己从零开始搭的模型要强悍,没有必要重复造轮子。
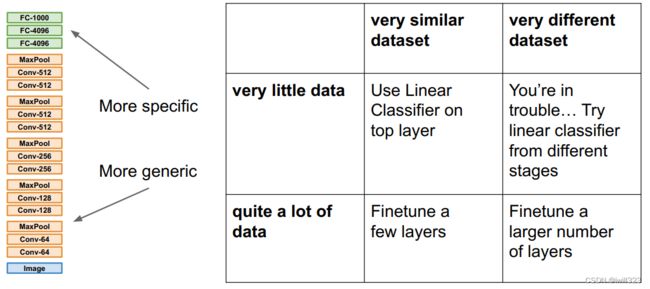
迁移学习方式
最重要的决定因素是新数据集的大小和与原来数据集的相似程度
- 训练数据很少,并且新数据集和原始数据集合类似
把网络前面的层当做feature extractor固定住,最后一个全连接层换成新的(最后一层通常是不一样的,因为分类的数量不同),随机初始化该层的模型参数,在⽬标数据集上只训练这一层。这是因为模型前面的卷积层从图片提取到的是更一般的特征(比如边缘或者颜色),对很多识别任务都有用,但是CNN后面的卷积层学习到的特征就更针对于原来的数据集了
- 训练数据较多且新旧数据集较相似 或 新旧数据集差异较大
输出层将从头开始进行训练,而部分层的参数将根据源模型的参数进行微调。First you can freeze the feature extractor, and train the head. After that, you can unfreeze the feature extractor (or part of it), set the learning rate to something smaller, and continue training.
- 训练数据很多,并且和原来数据集差异非常大
网络所有层都可以调整,只是用预训练的参数作为初始化参数,训练过程和往常一样。It is common in this method to set the learning rate to a smaller number. This is done because the network is already trained, and only minor changes are required to “finetune” it to a new dataset

案例
在一个小型数据集上微调ResNet模型,用于热狗识别。取自14.2. Fine-Tuning — Dive into Deep Learning 1.0.0-alpha1.post0 documentation (d2l.ai)
导包
%matplotlib inline
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])定义和初始化模型
在下面的代码中,目标模型finetune_net中输出层之前的参数被初始化为源模型相应层的模型参数。 由于模型参数是在ImageNet数据集上预训练的,并且足够好,因此通常只需要较小的学习率即可微调这些参数。输出层的参数是随机初始化的,通常需要更高的学习率。 假设基础学习率为,我们将输出层中参数的学习率设置为10。
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight);微调模型
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
train(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)其中用到的训练函数:
def train(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""Train a model with mutiple GPUs (defined in Chapter 13)."""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch(net, features, labels, loss, trainer,
devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(
epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3], None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
def train_batch(net, X, y, loss, trainer, devices):
"""Train for a minibatch with mutiple GPUs (defined in Chapter 13)."""
if isinstance(X, list):
# Required for BERT fine-tuning (to be covered later)
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
使用较小的学习率,通过微调预训练获得的模型参数
train_fine_tuning(finetune_net, 5e-5)注意事项
- 由于卷积层和池化层的计算与输入图片的尺寸无关,所以新数据集的大小可以和原来的不一样(只要该尺寸和步长大小“配合”)。对于最后的FC层,可以将其转变为卷积层。比如AlexNet中, 第一个FC层前的最后一个池化层输出为[6x6x512]. 于是该FC层等价于一个0 padding、感受野为6x6的卷积层。否则,新数据集的大小要与原始数据集相同
- 对于不同的层可以设置不同的学习率。对于使用原始数据做初始化的层设置的学习率要小一些(一般可设置小于10倍),这样保证对于已经初始化的数据不会扭曲的过快,而使用随机初始化的新线性分类层使用的学习率要大一点。
- 有一些微调的小技巧,比如先计算出预训练模型的卷积层对所有训练和测试数据的特征向量,然后抛开预训练模型,只训练自己定制的简配版全连接网络。 这个方式的一个好处就是节省计算资源,每次迭代都不会再去跑全部的数据,而只是跑一下简配的全连接


TensorFlow: https://github.com/tensorflow/models
PyTorch: https://github.com/pytorch/vision
参考:CS231n Convolutional Neural Networks for Visual Recognitionchapter4/4.1-fine-tuning.ipynb · 基础简单工具代码/pytorch-handbook - Gitee.com
官方推荐资料
- CNN Features off-the-shelf: an Astounding Baseline for Recognition trains SVMs on features from ImageNet-pretrained ConvNet and reports several state of the art results.
- DeCAF reported similar findings in 2013. The framework in this paper (DeCAF) was a Python-based precursor to the C++ Caffe library.
- How transferable are features in deep neural networks? studies the transfer learning performance in detail, including some unintuitive findings about layer co-adaptations.