Fusion-Extraction Networkfor Multimodal Sentiment Analysis(CCF C类)
本篇文章发表在2020年的Pacific-Asia conference on knowledge discovery and data mining会议,是关于图像和文本情感分类。使用的数据集是来自twitter的MVSA-Single和MVSA-Multiple。本文所提出方法的实验效果达到了当时的SOTA。
目录
一、文章动机
二、本篇文章的贡献
三、本文所提出的模型
1.IIF层
2.SIE层
3.输出层
四、实验
1.对比方法
2.实验结果
五、FENet细粒度和CoMN粗粒度注意力机制的区别
一、文章动机
作者认为许多之前的工作不能够有效利用视觉和文本信息的联系。比如Xu等人的方法仅考虑图像到文本的单向影响,忽略视觉和文本信息之间的交互促进关系;随后提出co-memory网络建模视觉内容和文本单词之间的交互,但是协同记忆仅应用一个加权的文本/视觉向量作为指导来学习视觉/文本表示的注意权重,本文作者认为这是一种粗粒度的注意力机制,产生了信息损失问题。此外,以往的研究直接将多模态的特征表示用于最终的情感分类,该做法存在部分冗余信息,可能造成混淆,不利于最终的情感分类。
二、本篇文章的贡献
提出了Fusion-Extraction Network(FENet)结构解决一种的几个问题。
- 提出Interactive Information Fusion(IIF,交互信息融合)机制学习细粒度的融合特征。该方法基于跨模态的注意力机制,生成特定于视觉的文本特征向量和特定于文本的视觉特征向量表示。
- 提出Specific Information Extraction(SIE,特定信息提取)机制提取视觉和文本中富含信息的特征表示,并将获得的特征表示用于情感分类。
三、本文所提出的模型
模型总览图如下所示:

两个核心模块如下图所示:
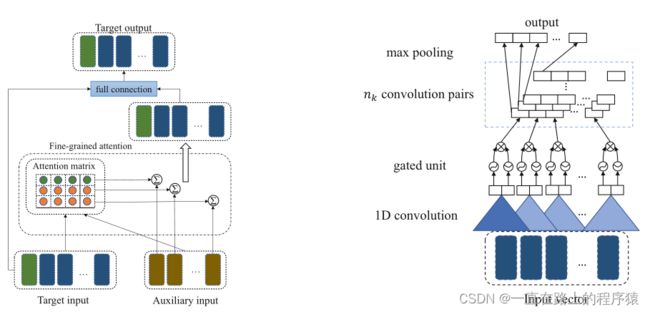
左图是IIF层,有图是SIE层
1.IIF层
该层需要两个模态的输入,一个模态的输入作为Target input,另一个模态的输入作为Auxiliary input。该层的目标是得到Target ouput,方法是将Auxiliary input融入到Target input中来得到Target output。
具体过程如下

上图中的S和A是Target input和Auxiliary input,使用(3)和(4)的方法将S和A映射到同一个共享的空间中。使用变换后的S和A计算细粒度的注意力矩阵M,Mij表示目标输入的第i个内容和辅助输入的第j个内容之间的联系。M计算方式如下,M的size为n*l。
![]()
softmax函数作用在M的每一行,将M中的值转换为行和为1的概率值来量化辅助输入的每一部分对目标输入每一部分的重要性。

接下来可以得到细粒度的注意力输出F
![]()
F其实就是用辅助输入的特征向量来表示目标输入中的每一个特征向量,F的size为辅助输入的词向量维度*目标输入的长度即da*n。
将目标输入与得到的F做concat操作,送进全连接层获得Target input的特殊表示G,G即为Target ouput。
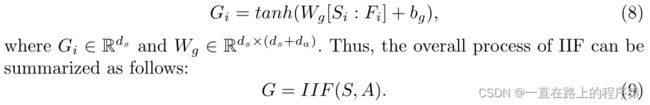
所以,特定于文本的视觉表示Vg和特定于视觉的文本表示Xg可以表示为:

2.SIE层
SIE层作用是提取具有丰富信息的表示,控制所提取的信息对最终情感分类的影响程度。

SIE层中的核心组件为nk个一维卷积核对,使用这些卷积核对来捕捉活跃的局部特征。每一个卷积核是一个特征检测器,可以抽取局部特征的specific pattern。卷积核对由两个使用不同的非线性激活函数组成,一个是tanh激活函数,另一个是sigmoid激活函数。卷积核对中第一个是使用tanh的卷积核来获得信息表示;第二个是使用sigmoid函数的卷积核,该卷积核起到gate的作用,用来控制第一个卷积核的结果有多少流向最终的表示中。
一个卷积核对Wa和Wb在tanh和sigmoid激活函数的作用下,一次可以将r列映射为一个实值a和b。e是a和b相乘的结果。
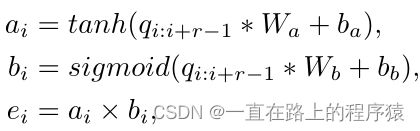
所以当一个卷积核对通过整个输入向量时,可以产生新的特征序列e={e1,e2,…ek-r+1},上述中的“*”表示的是卷积操作。因为有nk个卷积核对,所以最终产生的向量矩阵是(k-r+1)*nk。
最后使用max-pooling层获得每一个卷积核对中富含信息的表示,最终得到的向量矩阵的size为nk*1。

SIE层的内部处理过程使用以下的公式来表示
![]()
将IIF层得到的两个模态的特征送入到SIE层,获得最终的视觉和文本表示。
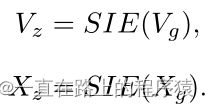
3.输出层
将Vz和Xz做连接操作送入全连接层做分类操作。
![]()
四、实验
1.对比方法
(1)SentiBank & SentiStrength,提取1200个形容词-名词对作为图像的中层表示,基于英语语法和文本拼写风格计算情感得分。
(2)CNN-Multi,使用两个CNN学习文本和图像特征,使用第三个CNN,利用图像和文本之间的内在联系进行情感分类。
(3)DNN-LR,训练CNN和深层的CNN处理文本和图像,后续使用平均策略对概率结果进行统计。
(4)MultiSentiNet,提取图像深层次语义特征,并提出一个视觉特征注意力的LSTM模型来吸收具有视觉语义特征的文本词。
(5)CoMN,提出一个记忆网络对图像和文本的交互进行建模。
2.实验结果
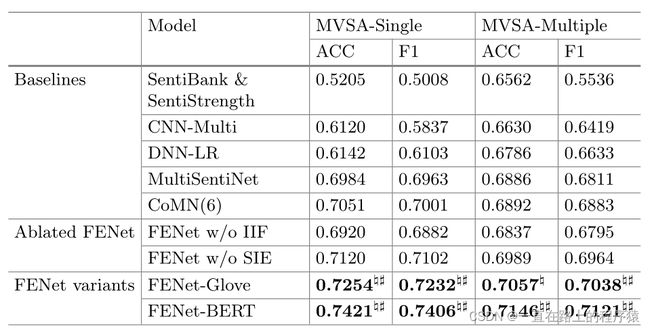
实验结果分析:
(1)CNN-Multi和DNN-LR使用了CNN架构提取特征表示,使得其性能好于使用传统统计特征的SentiBank方法。
(2)MultiSentiNet和CoMN考虑了模态信息之间的交互而获得了更好的结果。CoMN比MultiSentiNet性能略好的原因是因为MultiSentiNet只考虑图像到文本的单方向影响。
(3)CoMN使用粗粒度的注意力机制,而FENet基于细粒度机制使用IIF层,并使用SIE层使用图像和文本的信息进行情感预测,所以FENet的效果好于CoMN,达到了SOTA。
(4)消融实验的结果表明,IIF所产生的两种模态的输出可以为情感分析带来有效的信息。IIF所使用的细粒度的注意力机制可比CoMN的粗粒度注意力机制捕获到更多的信息。
五、FENet细粒度和CoMN粗粒度注意力机制的区别
以下述两个过程为例,在CoMN中,使用文本向量来指导图像向量的形成;在FENet网络中,将图像向量作为Target input,而将文本向量作为Auxiliary input。
| CoMN(粗粒度注意力机制) |
FENet(细粒度注意力机制) |
|
| 所使用的文本向量 |
使用一个综合文本信息的特征向量T,size为(1,dim) |
使用文本向量的原始表示T,size为(t,dim) |
| 注意力权重计算方式 |
将文本向量添加在每一个特征图向量mi的维度上,使用全连接层将拼接后的[mi:T]映射为一个常量,对所有的常量使用softmax函数,得到权重系数 |
图像向量与文本向量进行矩阵乘法操作,得到注意力分数矩阵M,对M的每一行使用softmax操作,得到注意力权重矩阵。 |
| 图像向量表示 |
权重系数与图像向量相乘,求和
|
(1)注意力权重矩阵与文本向量相乘,即使用文本向量表示图像向量中的每一个元素;(2)将(1)的结果拼接到原始的图像向量上;(3)拼接后的图像向量送入全连接层,得到最终的图像表示。 |
