【RL 第6章】Actor Critic、DDPG、A3C
皆さん、こんにちは、明日は新年です、明けましておめでとうございます!
前几天因为各种原因吧,摆了三天,什么也没学....进度也落下了一大截...唉>_<
今早找了个时间学习,看了看进度也是最后一章了,索性就一块写了,不出意外的话,今天这节内容应该是强化学习的最后一节了,后面会更新什么也不清楚了~可能也就写到这?可能也会继续写下去?一切的一切到了特定的时刻才会揭晓。
以下内容除了基本的概念外,其他大部分都是个人理解,欢迎各位大佬补充纠正

一、Actor Critic
之前,我们介绍了Q-Learning与Policy Gradients两种强化学习的算法,而今天我们所讲的Actor Critic算法,则是之前两种算法的结合体, 具体是什么意思呢?
Actor Critic可以拆成Actor与Critic两个部分,其中Actor的前身是Policy Gradients,因为他是表演者,可以在连续的动作区间中选取动作,而Q-Learning在这件事上就会瘫痪(参照我们之前所讲的Flappy Bird例子。而Critic的前身则是Q-Learning,因为Q-Learning是单步更新(走一步Q表更新一次),而Policy Gradients则是回合制更新,效率不如Q-Learning。
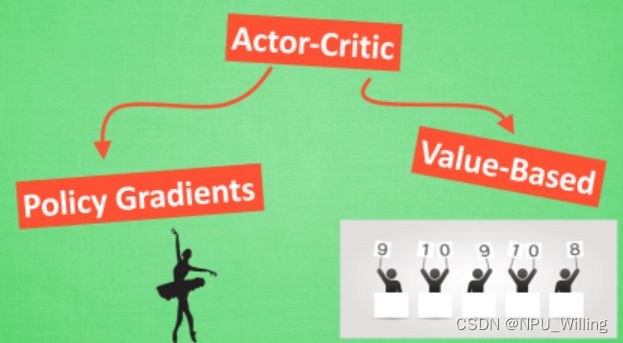
我们有了以上定义,那么我们的Actor Critic是如何进行的呢?过程其实并不复杂,个人理解如下:
- Critic依据当前所属的environment,学习奖惩机制(建立Q表)
- Actor看到游戏目前的state,做出一个action。
- Critic根据state和action两者,对Actor刚才的表现打一个分数。
- Actor依据critic(评委)的打分,调整自己的策略(Actor神经网络参数),争取下次做得更好。
- Critic根据系统给出的reward和其他评委的打分(critic target)来调整自己的打分策略(Critic神经网络参数)。
- 一开始actor随机表演,critic随机打分。但是由于reward的存在,critic评分越来越准,actor表现越来越好。
这样,Actor Critic就可以实现单步更新,而相较于之前Policy Gradients的回合更新,明显效率更高。
但相对的,因为有两个神经网络在相互的碰撞,并且是在连续的动作状态中选取action,所以很可能导致神经网络只能片面的看待问题(陷入局部最优,导致参数不更新),为了解决这一问题,Google的DeepMind修改了Actor Critic算法(即引入DQN,从而升级为Deep Deterministic Policy Gradient, 成功的解决的在连续动作预测上的学不到东西问题)
二、DDPG
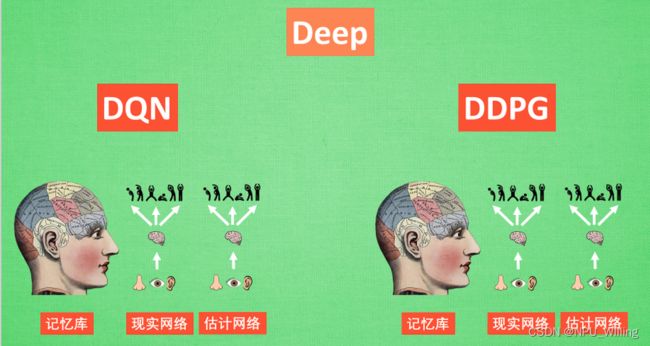
DDPG正如上文所说,是Actor Critic+DQN的结合体,我们可以将DDPG分为“Deep”和“Determinostic Policy Gradients”,其中“Determinostic Policy Gradients”又能被细分为“”Deterministic“与”Policy Gradients“。

(1)Deep
DDPG中也使用了DQN的思想,所使用的是一套记忆库和两套结构相同但参数更新频率不同的神经网络。
(2)Deterministic Policy Gradients
前几章我们提到过Policy Gradients,是一种能够在连续动作空间中选取动作的算法,而前面的”Deterministic“则增加了选取的动作的确定性,准确的来说,Deterministic改变了输出动作的过程,斩钉截铁的在连续动作空间上输出一个动作。

(3)DDPG
DDPG中所使用的神经网络与前文提到的Actor Critic差不多,但不同的是,也需要有基于策略Policy的神经网络与基于价值Value的神经网络,但不同的是,在DDPG中这两套神经网络被细分成为了两个,首先看Policy Gradients这边,一共有两个网络,其中动作估计网络用于输出Actor的现实动作,而动作现实网络则用于更新价值网络系统的;再看Q-Learning这边,也是两套网络,他们都在输出这个State的价值,但输入端确不同,其中状态现实网络会根据动作显示网络输出的动作加上对状态的观测值来输出价值,而状态估计网络则根据Actor的动作加上对状态的观测值来输出价值。
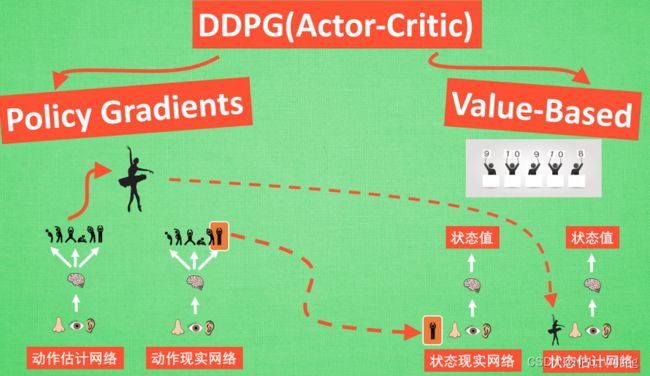
DDPG大概就是以上内容,如果需要数学推导过程,可以参照这篇文章:DDPG数学推导,这里不再赘述~
三、Asynchronous Advantage Actor-Critic (A3C)
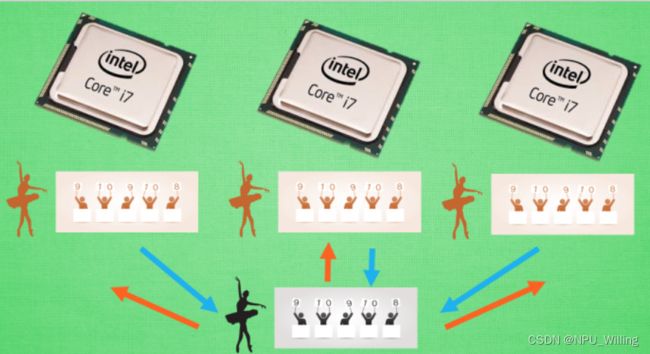
在介绍A3C,之前,我们可以设想这样一种场景:假设有3个平行宇宙,里面有三个你,现在,我要求你写作业,假设3个不同平行宇宙的你可以相互通信,这样,你们就可以商量:你写前三分之一,我写中间三分之一,他写后三分之一,于是这样,仅用三分之一的时间你们就将作业全部做完了,听起来是不是很棒?
这就是A3C的工作流程,或者说,是A3C的运算方式。A3C依旧采用Actor Critic的方式,不同的是,在A3C中,我们为了训练一对Actor Critic,我们将其复制成红色的三份,然后将他们放置在不同的宇宙中,让他们自己弄自己的,在训练的过程中,每个红色的副本都可以告诉黑色的主体,自己的训练如何,有什么经验可以分享,当然,这种交流并不是单向的,红色的部分同样可以从黑色主体那里获取经验,这样,就形成了一种效率较高的学习方式。
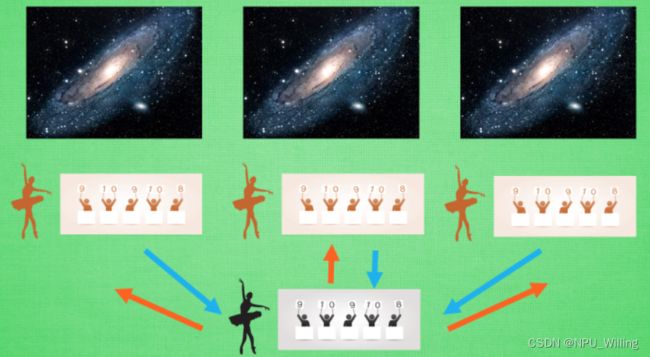
当前的计算机大多为多核系统,使用了A3C的方法,我们可以给他安排不同的核去并行进行运算,这样运算的效率就会大幅提升。