【深度学习】实验流程-语义分割框架
这里写目录标题
- 笔记参考
- 常见的Research workflow
- swin做backbone
- 实验方法
笔记参考
1.【干货】深度学习实验流程及PyTorch提供的解决方案
常见的Research workflow
某一天, 你坐在实验室的椅子上, 突然:
你脑子里迸发出一个idea
你看了关于某一theory的文章, 想试试: 要是把xx也加进去会怎么样
你老板突然给你一张纸, 然后说: 那个谁, 来把这个东西实现一下
于是, 你设计了实验流程, 并为这一idea 挑选了合适的数据集和运行环境, 然后你废寝忘食的实现了模型, 经过长时间的训练和测试, 你发现:
这idea不work --> 那算了 or 再调调
这idea很work --> 可以写paper了
我们可以把上述流程用下图表示:

常见的流程由下面几项组成起来:
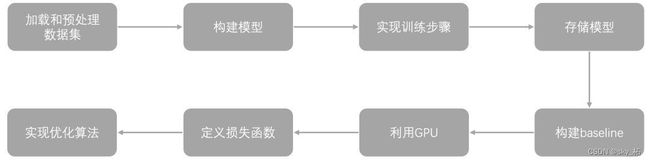
1 一旦选定了数据集, 你就要写一些函数去load 数据集, 然后pre-process数据集, normalize 数据集, 可以说这是一个实验中占比重最多的部分, 因为:
a每个数据集的格式都不太一样
b预处理和正则化的方式也不尽相同
c需要一个快速的dataloader 来feed data, 越快越好
2然后, 你就要实现自己的模型, 如果你是CV方向的你可能想实现一个ResNet,如果你是NLP相关的你可能想实现一个Seq2Seq
3接下来, 你需要实现训练步骤, 分batch, 循环epoch
4在若干轮的训练后, 总要checkpoint一下, 才是最安全的
5你还需要构建一些baseline,以验证自己idea的有效性
6如果你实现的是神经网络模型, 当然离不开GPU的支持
7很多深度学习框架提供了常见的损失函数, 但大部分时间, 损失函数都要和具体任务结合起来, 然后重新实现
8使用优化方法, 优化构建的模型, 动态调整学习率
swin做backbone
对于语义分割任务来说,Swin Transformer任务中是作为backbone的存在。demo中给出的模型pspnet_r50-d8_512x1024_40k_cityscapes是以PSPNet为检测方法,以ResNet-d8为backbone提取特征图。为了感受Swin Transformer在语义分割任务中的效果,我还配置了以UPerNet为检测方法,以Swin Transformer作为backbone的检测模型。但是在Swin-Transformer-Semantic-Segmentation中对于Swin Transformer框架的支持有一些细节问题,需要进行一些调整,特此将踩坑过程详细列出,
实验方法
图像语义分割如何下手?算法如何实现?
模型搭建完毕,使用骨干网络(轻量骨干搭建,复杂骨干搭建,多任务骨干搭建持续更新种)的节点引出自己的分割分支,运用辅助模型容器搭建分割头的类,完成分割网络的搭建过程。
从已经成熟的项目入手,根据自己的课题或者任务进行需要的修改。推荐用 OpenMMLab 系列之一的 MMSegmentation,是目前开源项目中模型最丰富的语义分割代码库。如果实验室的显卡不太充裕,可以用 modelzoo 里提供的与训练模型进行 finetune,这样不仅能获得较高的性能,也能节约训练时间的呐~具体来说,可以先从配环境开始,在自己的环境下跑起来别人开源的代码。完成这一步以后,基本的 setup 就完成了。然后就是按照课题自由发挥的时候了。根据你的课题要求,先明确想要解决的问题或者证明的事情,然后选择适合的数据集(大小和 domain 合适),如果是要提升某一方面的效果,先做一些基线实验作为对照,再应用自己的提出的可能解决基线实验出现的问题的方法,一步一步进行方法的迭代~