推荐算法:序列召回
目录
序列召回(一)
序列召回(二)
序列召回(三)
序列召回(四)
序列召回(一)
源自论文:http://arxiv.org/abs/1511.06939
基于GRU的序列召回中通过GRU得到用户的embedding,与所有item的embedding做内积。两个向量内积就是用户-item的相似度。
一个用户和所有item的内积,相当于获得了所有item的得分。
序列召回(二)
召回:输入一个用户的(点击)序列,通过某种方法(序列建模的方法),把用户输入的序列变为向量,用用户向量,在所有的item的向量进行快速检索,依次达到序列召回的效果。
核心:对一个序列进行建模。(怎么把用户的行为序列变为一个用户的向量)
论文链接:https://arxiv.org/abs/1811.00855
手把手教你读推荐论文-SR-GNN (baidu.com)
用GNN对序列进行建模。
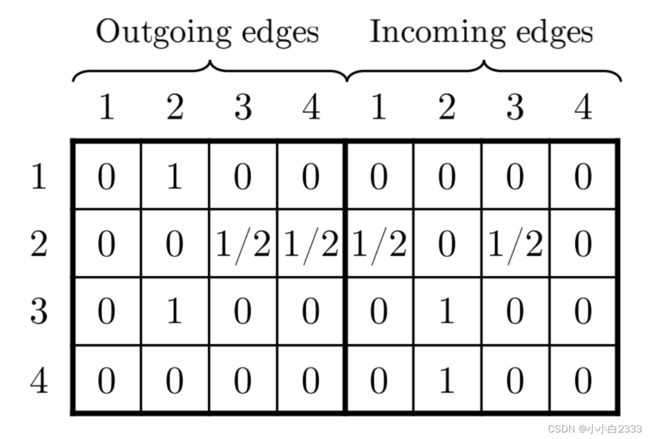
记录了节点的出边信息和入边信息。
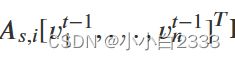
把和第i个节点相连的item的embedding加权求和的效果。(消息聚合)

全连接层的操作。

n:序列里面item的个数
d:序列embedding的维度

matmul 矩阵乘法
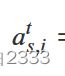 表示第t层GNN向量特征提取的中间变量。
表示第t层GNN向量特征提取的中间变量。

把算出的结果进行综合,第t层GNN新得到的特征。
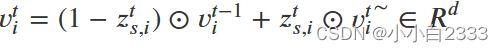
通过z 来控制保留多少前一层的信息和多少这一层更新出来的信息。
由此,到这里已经完成从vt-1到vt的一次GNN操作。每一个item的embdding里面有更多的图结构的信息。
输入的行为序列是一个用户的。(每一个session)
序列召回(三)
多兴趣召回:把用户的行为序列,从行为序列里面提取出多个这个用户的行为表征。
MIND
论文链接:https://arxiv.org/pdf/1904.08030
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)
输入:序列的embdedding
输出:用户的多兴趣表征
 从用户行为序列第i个embedding ei到第j个兴趣向量 uj之间的权重。按照高斯分布进行初始化。
从用户行为序列第i个embedding ei到第j个兴趣向量 uj之间的权重。按照高斯分布进行初始化。
动态路由 需要循环k次,本论文里k=3。
1.先给bij做一个softmax。意味着每一个兴趣向量都是可以由原始输入序列进行加权求和得到,并且权重做了归一化。对i这个维度做的softmax。
2. 用户的embedding向量通过S矩阵进行映射到一个新空间。S矩阵 d×d的维度。
用户的embedding向量通过S矩阵进行映射到一个新空间。S矩阵 d×d的维度。
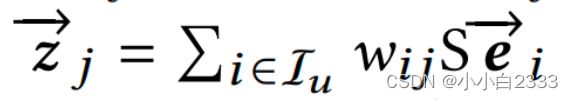 得到每一个兴趣向量的前身Zj
得到每一个兴趣向量的前身Zj
3.对Zj做个激活函数就可。获得真正的输出Uj
 对向量进行单位向量(单位化)
对向量进行单位向量(单位化)
4.胶囊网络不做梯度更新。bij用公式进行更新,不用反向传递。
循环三遍后,输出最终的兴趣向量。
怎么根据用户的多兴趣表征来进行loss训练
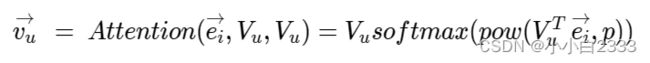
Vu^T :用户的多兴趣表征,4个兴趣向量。维度为4×32(4×64)
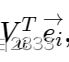 :让item的embedding和用户所有兴趣向量都做一个内积。是四维向量。
:让item的embedding和用户所有兴趣向量都做一个内积。是四维向量。
每一个维度表示:用户的每一个兴趣向量和item的embedding的内积。(内积可以代表两个向量的相似度)
 做完内积做指数的操作。对内积的结果做一个p次幂。
做完内积做指数的操作。对内积的结果做一个p次幂。
如何通过用户的多兴趣向量完成一次序列召回
每个兴趣向量分别召回五十个商品。对200个相似度进行排序,之后取相似度的前五十。
序列召回(四)
Comirec:Controllable Multi-Interest Framework for Recommendation
论文链接:https://arxiv.org/abs/2005.09347
Comirec-DR
Comirec-SA
输入:用户序列
输出:用户多个兴趣表征
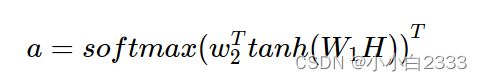 归一化之后的attention score
归一化之后的attention score
 :对序列里面所有item的embedding做了一个映射,映射到新的向量空间,维度从d变为da,da是四倍的d。da×n 。n是序列的长度。
:对序列里面所有item的embedding做了一个映射,映射到新的向量空间,维度从d变为da,da是四倍的d。da×n 。n是序列的长度。
![]() 要用tanh,因为值域是-1~1,换其他的激活函数效果可能不太好。
要用tanh,因为值域是-1~1,换其他的激活函数效果可能不太好。
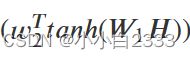 结果n的向量。就是注意力的分数,就是对序列每一个item进行打分。
结果n的向量。就是注意力的分数,就是对序列每一个item进行打分。
多样性控制
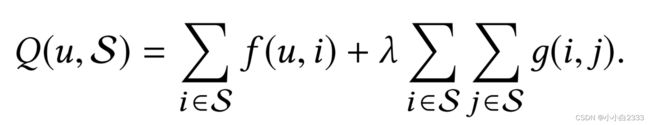
f(u,i) 推荐出的所有item的embedding和user的embedding做内积,得到用户对所有item的得分的求和。(推荐准确性的指标)
贪心算法:
从200个选出50个item,这五十个Q(u,S)最大。
涉及到的博客:
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)
(8条消息) 什么是推荐系统?推荐系统类型、用例和应用_Jericho2022的博客-CSDN博客_推荐系统
推荐系统2--隐语义模型(LFM)和矩阵分解(MF)_Evey_zhang的博客-CSDN博客_隐语义空间
【技术分享】交换最小二乘 - 知乎 (zhihu.com)