RNN、LSTM及GRU的理解学习笔记
参考博客:
https://blog.csdn.net/v_JULY_v/article/details/89894058
https://www.cnblogs.com/jiangxinyang/p/9376021.html
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
RNN
RNN 输入维度,输出维度
batch_first = True
输入:batch_size, seq_len, input_size (input_size是每个seq的shape)
h0:num_layers * num_directions, batch, hidden_size
输出:batch_size,seq_len, num_directions * hidden_size
hn:num_layers * num_directions, batch, hidden_size
网络结构图
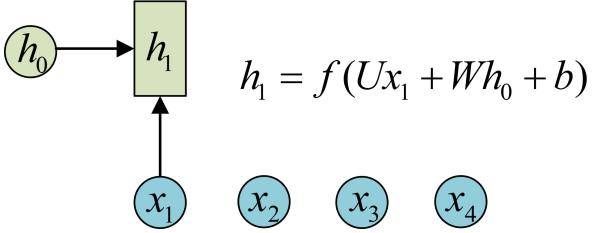
图示中记号的含义是:
- 圆圈或方块表示的是向量。
- 一个箭头就表示对该向量做一次变换。如上图中h0和x1分别有一个箭头连接,就表示对h0和x1各做了一次变换
经典RNN
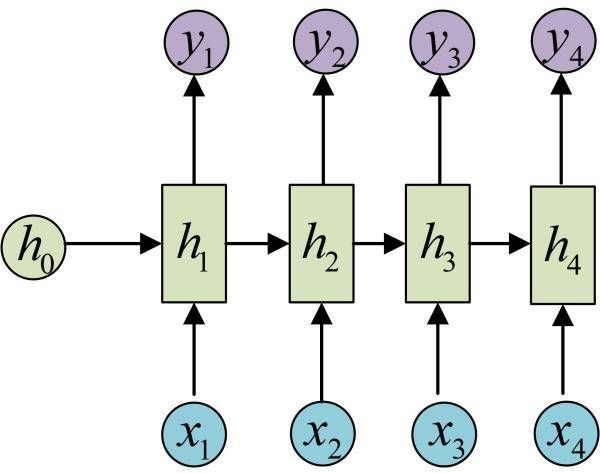
RNN变种N VS M
这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型
Encoder-Decoder结构先将输入数据编码成一个上下文向量c
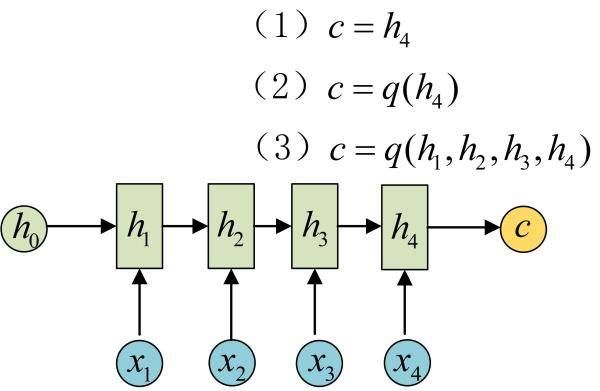
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
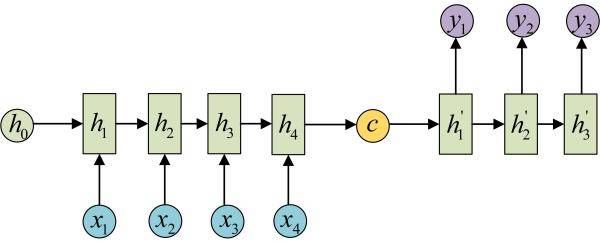
还有一种做法是将c当做每一步的输入

Attention机制
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码。
因此, c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。
如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。
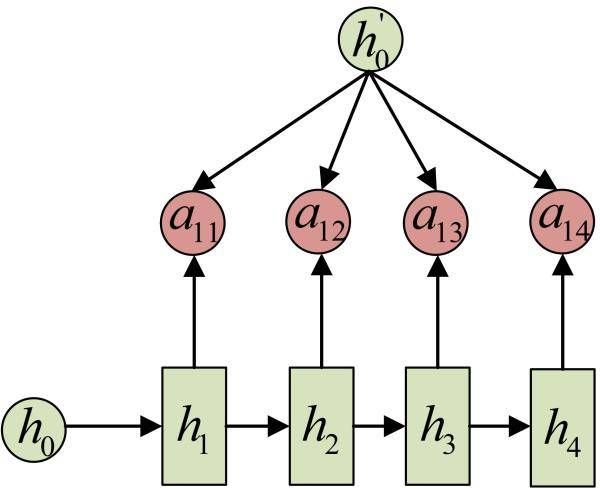
Attention机制通过在每个时间输入不同的c来解决这个问题,下图是带有Attention机制的Decoder:

每一个c会自动去选取与当前所要输出的y最合适的上下文信息。
具体来说,我们用 a i j a_{ij} aij 衡量Encoder中第j阶段的 h j h_j hj和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息 c i c_i ci 就来自于所有 h j h_j hj 对 a i j a_{ij} aij的加权和。
以机器翻译为例(将中文翻译成英文):

输入的序列是“我爱中国”,因此,Encoder中的h1、h2、h3、h4就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。
在翻译成英语时,第一个上下文c1应该和“我”这个字最相关,因此对应的就比较大,而相应的就比较小。
c2应该和“爱”最相关,因此对应的就比较大。最后的c3和h3、h4最相关,因此 的值就比较大。
至此,关于Attention模型,我们就只剩最后一个问题了,那就是:这些权重是怎么来的?
事实上,同样是从模型中学出的,它实际和Decoder的第i-1阶段的隐状态、Encoder第j个阶段的隐状态有关。
同样还是拿上面的机器翻译举例,的计算(此时箭头就表示对h’和![]() 同时做变换):
同时做变换):
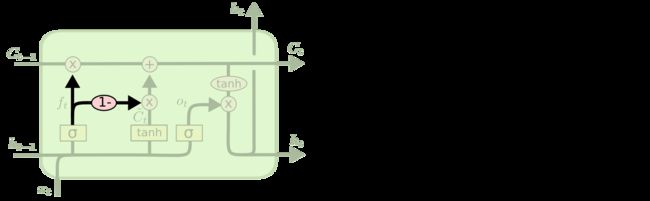
LSTM
Long Short Term Memory networks ------一般就叫做 LSTM ,是一种 RNN 特殊的类型,可以学习长期依赖信息
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
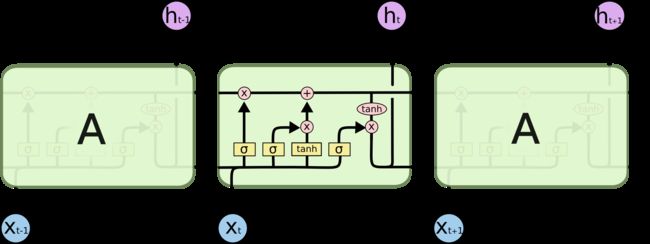

在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置
1、LSTM 的核心思想
LSTM 的关键就是cell状态(c状态),水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
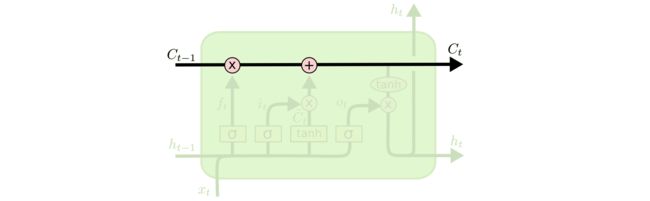
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。

Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”
一个LSTM有三个这样的门,以保护和控制细胞状态
2、逐步理解 LSTM
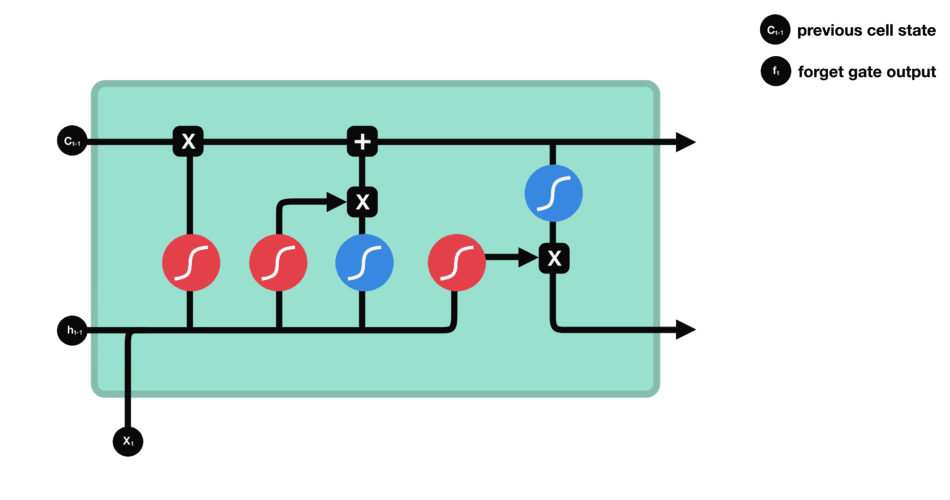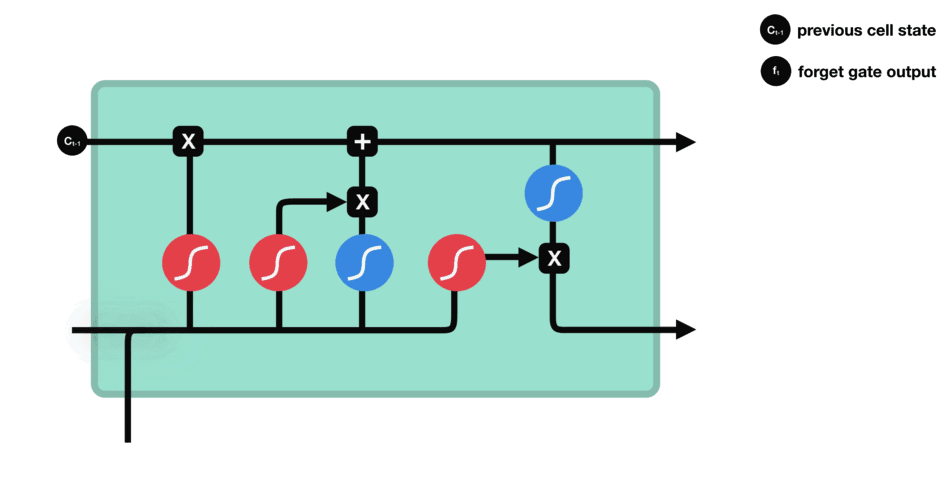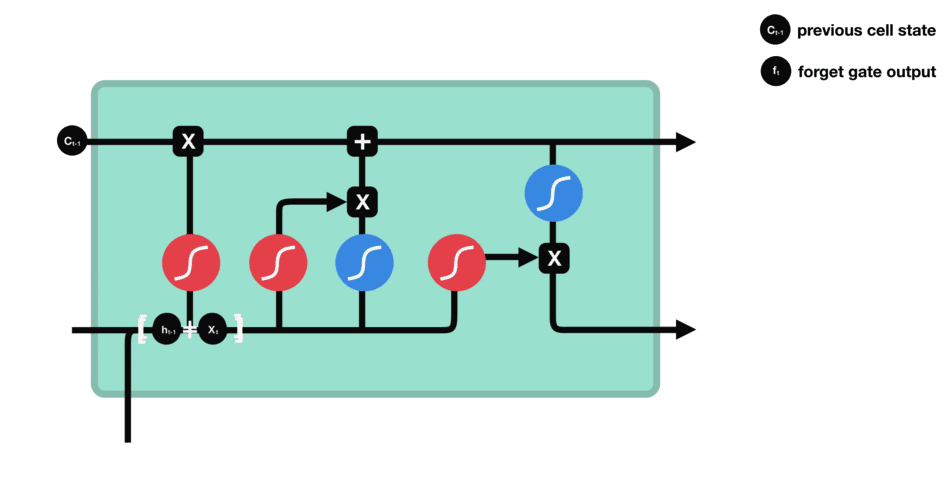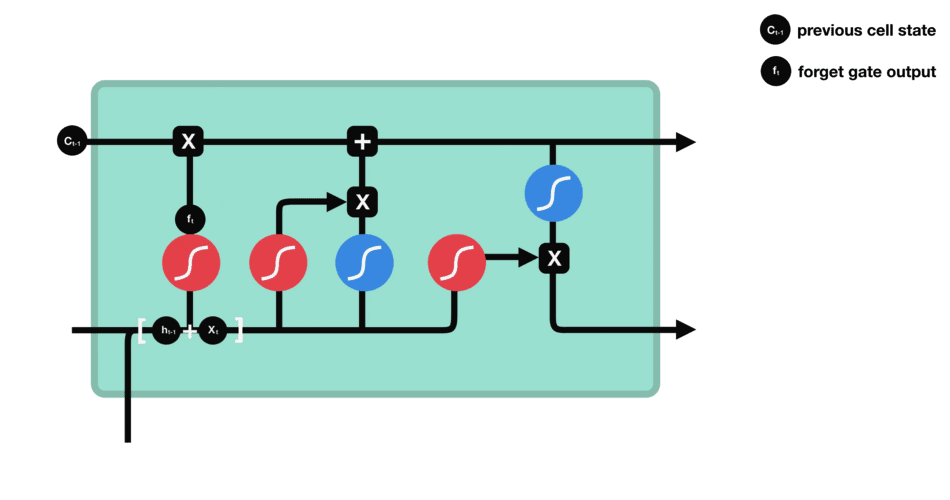
2.1 忘记门
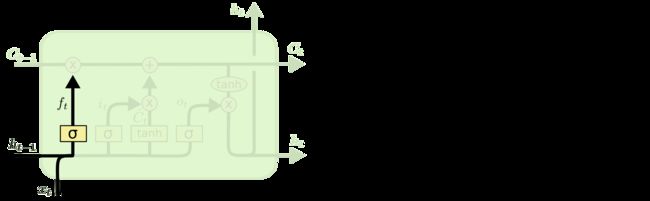
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取 h t − 1 h_{t-1} ht−1和 x t x_t xt,输出一个在 0 到 1 之间的数值给每个在细胞状态 C t − 1 C_{t-1} Ct−1中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
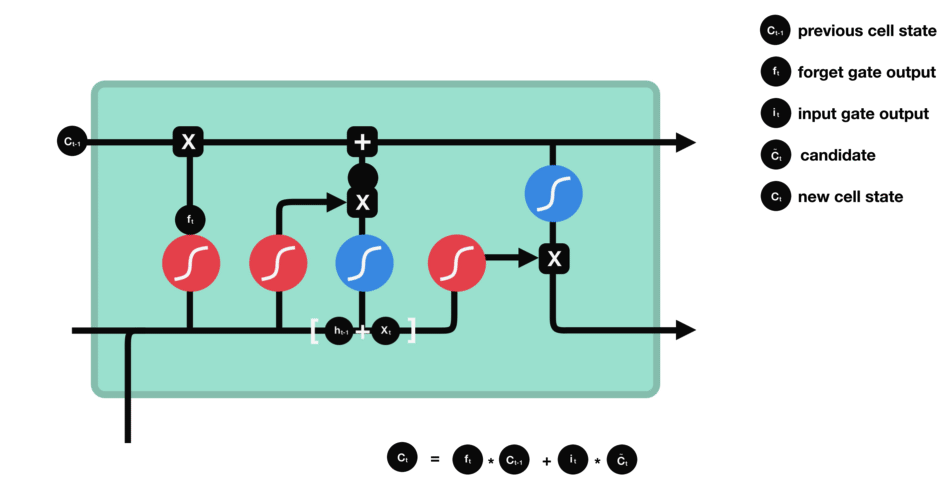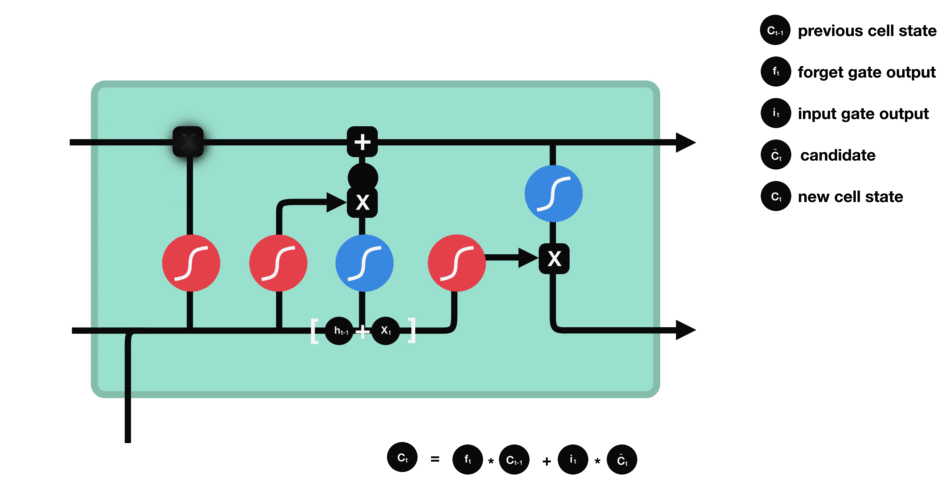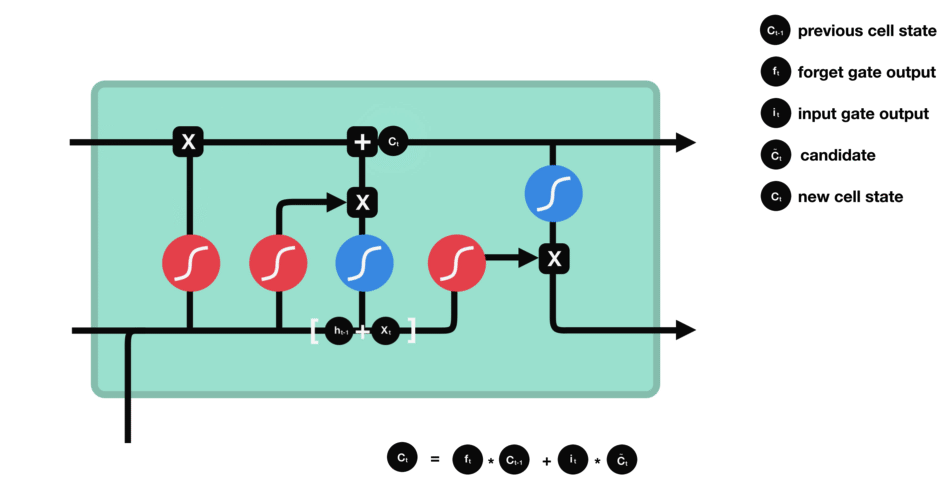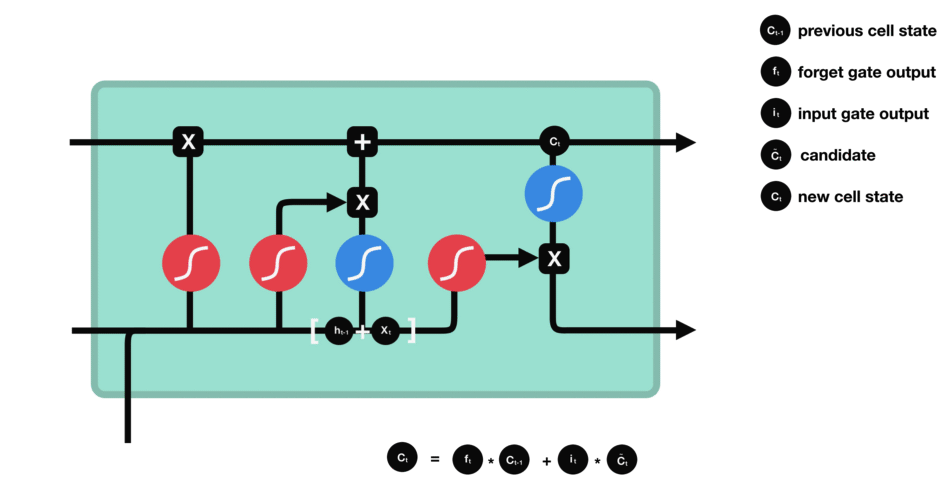
2.2 输入门

下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 输入门层,决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量, C ~ t \tilde{C}_t C~t,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。

2.3 细胞状态

现在是更新旧细胞状态的时间了, C t − 1 C_{t-1} Ct−1更新为 C t C_t Ct。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。我们把旧状态与 f t f_t ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上 i t ∗ C ~ t i_t * \tilde{C}_t it∗C~t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。
2.4 输出门

最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定 h t − 1 h_{t-1} ht−1和 x t x_t xt的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 层的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。

LSTM 的变体
我们到目前为止都还在介绍正常的 LSTM。但是不是所有的 LSTM 都长成一个样子的。实际上,几乎所有包含 LSTM 的论文都采用了微小的变体。差异非常小,但是也值得拿出来讲一下。
GRU
其中一个流行的 LSTM 变体是 Gated Recurrent Unit (GRU),这是由 Cho, et al. (2014) 提出。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。

为了便于理解,我把上图右侧中的前三个公式展开一下
- z t = σ ( W z h h t − 1 + W z x x t ) z_{t} = \sigma (W_{zh}h_{t-1} + W_{zx}x_{t}) zt=σ(Wzhht−1+Wzxxt)
- r t = σ ( W r h h t − 1 + W r x x t ) r_{t} = \sigma (W_{rh}h_{t-1} + W_{rx}x_{t}) rt=σ(Wrhht−1+Wrxxt)
- h ~ = t a n h ( W r h ( r t h t − 1 ) + W x x t ) \tilde{h} = tanh(W_{rh}(r_{t}h_{t-1}) + W_{x}x_{t}) h~=tanh(Wrh(rtht−1)+Wxxt)
z t z_{t} zt和 r t r_{t} rt都是对 h t − 1 h_{t-1} ht−1 , x t x_{t} xt做的Sigmoid非线性映射,那区别在哪呢?原因在于GRU把忘记门和输入门合二为一了,而 z t z_{t} zt是属于要记住的,反过来 1 − z t 1- z_{t} 1−zt则是属于忘记的。图中的 z t z_t zt和 r t r_t rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 h t ~ \tilde{h_t} ht~ 上,重置门越小,前一状态的信息被写入的越少。
其他变体
另一个变体就是由 Gers & Schmidhuber (2000) 提出的,增加了 “peephole connection”。是说,我们让 门层 也会接受细胞状态的输入。

上面的图例中,我们增加了 peephole 到每个门上,但是许多论文会加入部分的 peephole 而非所有都加。
另一个变体是通过使用 coupled 忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。我们仅仅会当我们将要输入在当前位置时忘记。我们仅仅输入新的值到那些我们已经忘记旧的信息的那些状态 。