详解车道线检测数据集和模型 VIL-100: A New Dataset and A Baseline Model for Video Instance Lane Detection

本文介绍一个新的车道线数据集 VIL-100 和检测模型 MMA-Net,论文已收录于 ICCV2021,重点是理解本文提出的 LGMA 模块,用于聚合局部和全局记忆特征。
论文链接:https://arxiv.org/abs/2108.08482
项目链接:https://github.com/yujun0-0/MMA-Net
1. Introduction
在自动驾驶中,最基本和最有挑战性的一个任务是车道线检测。然而在真实的场景中,会受到遮挡、恶劣天气、昏暗灯光或强光反射等影响,准确地进行车道线检测是很困难的。现有的车道线检测方法主要集中在图像上进行车道线检测,而在自动驾驶中汽车摄像头采集到的是视频。因此现在迫切需要将基于图像的车道线检测扩展到视频数据上进行车道线检测,因为基于视频的车道线检测可以利用时域一致性来解决图像检测存在的问题。针对以上问题,本文主要工作如下:
- 收集了一个新的视频实体车道线检测数据集(
VIL-100)。共包含100个视频,10000帧图像,涵盖10种车道线类型、各种驾驶场景、光照条件和多条车道线实体,同时对视频中的所有车道线提供了高质量的实体级标注。 - 开发了一个新的
baseline模型,即多层记忆聚合网络(MMA-Net)。具体来说,原始视频中历史帧为局部记忆,打乱顺序后的历史帧为全局记忆。局部和全局记忆(LGMA)模块以注意力机制分别对多层的局部和全局记忆特征进行聚合,并与当前帧的特征进行结合来得到当前帧的车道线实体分割结果。 - 最后,在
VIL-100数据集上将本文提出的方法和10个最先进的模型进行了比较。结果显示,本文设计的模型明显优于现有方法(单张图像车道线检测方法、视频实体分割方法)。
2. VIL-100 Dataset
2.1 Data Collection and Split
VIL-100 数据集的采样频率为10fps,是从30fps下采样而来。其中97个视频是通过单目前置摄像头采集的,3个视频是从互联网上获取而来。
整个数据集上包含10个场景:正常路况、拥挤路况、弯道路况、受损路况、阴影路况、含道路标志路况、强光路况、阴霾路况、夜晚路况、十字交叉路口。
数据集上按照8:2的比例将划分为训练集和测试集,在训练集和测试集上均包含10个场景。VIL-100 数据集与其它车道线数据集比较如下表所示。可以看到只有VIL-100数据集提供了视频实体车道线标注。

2.2 Annotation
标注时,将每个视频中每一帧的所有车道线中心位置坐标存储在json文件中。每一条车道线对应的中心位置存储为一组,从而提供了实体级车道线注释。然后用三阶多项式拟合成一条曲线,然后扩展为具有一定宽度的车道线区域。例如 1920 × 1080 1920 × 1080 1920×1080 的图片,宽度为30 pixels大小。对于低分辨率的图像,宽度等比例减小。
同时对每条车道线标注了车道线类型,总共由10种车道线类型,即:单条白色实线、单条白色虚线、单条黄色实线、单条黄色虚线、双条白色实线、双条黄色实线、双条黄色虚线、双条白色实虚线、双条白色虚实线、双条白色黄色实线。
最后对每一帧还标注了车道线与自身车辆的相对位置,即 2 i 2i 2i 表示车辆右侧的第 i i i 条车道线, 2 i − 1 2i-1 2i−1 表示车辆左侧的第 i i i 条车道线,在本数据集中 i = 1 , 2 , 3 , 4 i=1,2,3,4 i=1,2,3,4,因此每一帧最多可以标注8条车道线位置。
2.3 Dataset Features and Statistics
下面是对数据集的统计分析,有17%的视频中包含多个场景,图2(a)是不同场景同时出现的情况,图2(b)所示为每一个场景出现的数量。
图3(a)所示为标注的不同类型车道线数量,图3(b)所示为每帧中标注的车道线数量,可以看到3371帧中标注了5条车道线,13帧中标注了6条车道线。
 |
 |
3. Proposed Method
本文提出的检测模型MMA-Net如下图所示。为了检测目标帧 I t I_t It 的车道线区域,输入为原始视频有序历史帧 { I t − 5 , I t − 4 , … , I t − 1 } \left\{I_{t-5}, I_{t-4}, \ldots, I_{t-1}\right\} {It−5,It−4,…,It−1} 和 打乱顺序的历史帧 { I ^ t − 5 , I ^ t − 4 , … , I ^ t − 1 } \left\{\hat{I}_{t-5}, \hat{I}_{t-4}, \ldots, \hat{I}_{t-1}\right\} {I^t−5,I^t−4,…,I^t−1}。然后经过一个4层卷积网络的编码器得到高级特征图( H H H)和低级特征图 ( L L L)。这样就能得到局部记忆特征 M l \mathcal{M}_{l} Ml 和全局记忆特征 M l \mathcal{M}_{l} Ml。
然后使用局部全局记忆聚合模块(LGMA) 分别对低级特征图和高级特征图进行聚合。聚合后的低级特征 L m a L_{ma} Lma 和目标帧的底级特征 L t L_t Lt 一起输入到记忆读取模块(MR)增强目标帧的低级特征,同样也增强目标帧的高级特征。
最后,使用一个U-Net解码器来融合不同卷积层的特征,并预测目标帧 I t I_t It 的车道线检测图。

3.1 Local and Global Memory Aggregation Module
LGMA模块如下图(a)所示,输入为5个有序历史帧特征与乱序历史帧特征,首先使用两个 3 × 3 3\times3 3×3 卷积层在每一个输入特征图上提取 key maps 和 value maps。
然后使用注意力块(图(b)所示)对局部和全局key maps 和value maps集成记忆特征,得到新的map,最后局部与全局map相加得到kep map Z a t t k \mathbf{Z}_{att}^{\mathbf{k}} Zattk 和value map Z a t t v \mathbf{Z}_{att}^{\mathbf{v}} Zattv。数学表示为:
Z a t t k = f a t t ( k 1 L , k 2 L , … , k 5 L ) + f att ( k 1 G , k 2 G , … , k 5 G ) Z a t t v = f a t t ( v 1 L , v 2 L , … , v 5 L ) + f a t t ( v 1 G , v 2 G , … , v 5 G ) \begin{array}{l} \mathbf{Z}_{\mathbf{a t t}}^{\mathrm{k}}=f_{a t t}\left(\mathbf{k}_{\mathbf{1}}^{\mathbf{L}}, \mathbf{k}_{\mathbf{2}}^{\mathbf{L}}, \ldots, \mathbf{k}_{\mathbf{5}}^{\mathbf{L}}\right)+f_{\text {att }}\left(\mathbf{k}_{1}^{\mathbf{G}}, \mathbf{k}_{\mathbf{2}}^{\mathbf{G}}, \ldots, \mathbf{k}_{\mathbf{5}}^{\mathbf{G}}\right) \\ \mathbf{Z}_{\mathbf{a t t}}^{\mathrm{v}}=f_{a t t}\left(\mathbf{v}_{\mathbf{1}}^{\mathbf{L}}, \mathbf{v}_{\mathbf{2}}^{\mathbf{L}}, \ldots, \mathbf{v}_{\mathbf{5}}^{\mathbf{L}}\right)+f_{a t t}\left(\mathbf{v}_{\mathbf{1}}^{\mathbf{G}}, \mathbf{v}_{\mathbf{2}}^{\mathbf{G}}, \ldots, \mathbf{v}_{\mathbf{5}}^{\mathbf{G}}\right) \end{array} Zattk=fatt(k1L,k2L,…,k5L)+fatt (k1G,k2G,…,k5G)Zattv=fatt(v1L,v2L,…,v5L)+fatt(v1G,v2G,…,v5G)
其中, f a t t f_{att} fatt 为注意力块运算, ( k 1 L , k 2 L , … , k 5 L ) \left(\mathbf{k}_{\mathbf{1}}^{\mathbf{L}}, \mathbf{k}_{\mathbf{2}}^{\mathbf{L}}, \ldots, \mathbf{k}_{\mathbf{5}}^{\mathbf{L}}\right) (k1L,k2L,…,k5L) 为局部记忆key map, ( v 1 L , v 2 L , … , v 5 L ) \left(\mathbf{v}_{\mathbf{1}}^{\mathbf{L}}, \mathbf{v}_{\mathbf{2}}^{\mathbf{L}}, \ldots, \mathbf{v}_{\mathbf{5}}^{\mathbf{L}}\right) (v1L,v2L,…,v5L) 为局部记忆value map; ( k 1 G , k 2 G , … , k 5 G ) \left(\mathbf{k}_{\mathbf{1}}^{\mathbf{G}}, \mathbf{k}_{\mathbf{2}}^{\mathbf{G}}, \ldots, \mathbf{k}_{\mathbf{5}}^{\mathbf{G}}\right) (k1G,k2G,…,k5G) 为全局记忆key map, ( v 1 G , v 2 G , … , v 5 G ) \left(\mathbf{v}_{\mathbf{1}}^{\mathbf{G}}, \mathbf{v}_{\mathbf{2}}^{\mathbf{G}}, \ldots, \mathbf{v}_{\mathbf{5}}^{\mathbf{G}}\right) (v1G,v2G,…,v5G) 为全局记忆value map。

关于记忆读取模块(MR)、解码器、训练程序、训练参数这里就不一一介绍了,具体细节可以阅读代码。
4. Experiments
实验评价指标作者采用了image-leveli评价指标:mIoU、 F 1 0.5 , F 1 0.8 \mathbf{F1}^{0.5},\mathbf{F1}^{0.8} F10.5,F10.8,line-based评价指标:Accuracy、 F P \mathbf{FP} FP、 F N \mathbf{FN} FN,除此之外,作者还引入了video-level评价指标: M J , O J , M F , O F , M T \mathcal{M}_{\mathcal{J}}, \mathcal{O}_{\mathcal{J}}, \mathcal{M}_{\mathcal{F}}, \mathcal{O}_{\mathcal{F}} , \mathcal{M}_{\mathcal{T}} MJ,OJ,MF,OF,MT。
作者这里其它10中方法进行了比较,image-level检测方法:LaneNet、SCNN、ENet-SAD、UFSA、LSTR,instance-level video 检测方法:GAM、RVOS、STM、AFB-URR、TVOS。作者在VIL-100数据集上重新训练了上述方法。
下表是不同评价指标的对比。
| image-based metrics | video-based metrics |
|---|---|
 |
 |
下面是可视化比较:

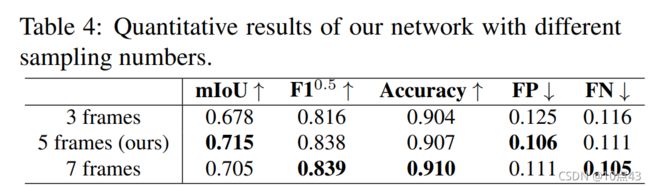
最后是不同采样帧数和对比实验,Basic为移除局部记忆注意力机制(LM)、全局记忆注意力机制(GM)、局部全局记忆注意力机制(LGM),多层融合机制,相当于检测方法STM。
 |
 |