憨批的语义分割重制版8——Keras 搭建自己的DeeplabV3+语义分割平台
憨批的语义分割重制版8——Keras 搭建自己的DeeplabV3+语义分割平台
- 注意事项
- 学习前言
- 什么是DeeplabV3+模型
- 代码下载
- DeeplabV3+实现思路
-
- 一、预测部分
-
- 1、主干网络介绍
- 2、加强特征提取结构
- 3、利用特征获得预测结果
- 二、训练部分
-
- 1、训练文件详解
- 2、LOSS解析
- 训练自己的DeeplabV3+模型
-
- 一、数据集的准备
- 二、数据集的处理
- 三、开始网络训练
- 四、训练结果预测
注意事项
这是重新构建了的DeeplabV3+语义分割网络,主要是文件框架上的构建,还有代码的实现,和之前的语义分割网络相比,更加完整也更清晰一些。建议还是学习这个版本的DeeplabV3+。
学习前言
DeeplabV3+也需要重构!

什么是DeeplabV3+模型
DeeplabV3+被认为是语义分割的新高峰,因为这个模型的效果非常好。
DeepLabv3+主要在模型的架构上作文章,引入了可任意控制编码器提取特征的分辨率,通过空洞卷积平衡精度和耗时。
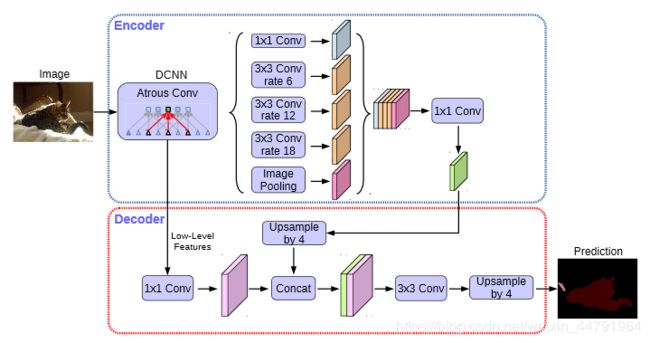
DeeplabV3+在Encoder部分引入了大量的空洞卷积,在不损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。如下就是空洞卷积的一个示意图,所谓空洞就是特征点提取的时候会跨像素。
代码下载
Github源码下载地址为:
https://github.com/bubbliiiing/deeplabv3-plus-keras
复制该路径到地址栏跳转。
DeeplabV3+实现思路
一、预测部分
1、主干网络介绍
DeeplabV3+在论文中采用的是Xception系列作为主干特征提取网络,本博客会给大家提供两个主干网络,分别是Xception和mobilenetv2。
但是由于算力限制(我没有什么卡),为了方便博客的进行,本文以mobilenetv2为例,给大家进行解析。
MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络。
MobileNetV2是MobileNet的升级版,它具有一个非常重要的特点就是使用了Inverted resblock,整个mobilenetv2都由Inverted resblock组成。
Inverted resblock可以分为两个部分:
左边是主干部分,首先利用1x1卷积进行升维,然后利用3x3深度可分离卷积进行特征提取,然后再利用1x1卷积降维。
右边是残差边部分,输入和输出直接相接。

需要注意的是,在DeeplabV3当中,一般不会5次下采样,可选的有3次下采样和4次下采样,本文使用的4次下采样。这里所提到的下采样指的是不会进行五次长和宽的压缩,通常选用三次或者四次长和宽的压缩。
在完成MobilenetV2的特征提取后,我们可以获得两个有效特征层,一个有效特征层是输入图片高和宽压缩两次的结果,一个有效特征层是输入图片高和宽压缩四次的结果。
from keras import layers
from keras.activations import relu
from keras.layers import (Activation, Add, BatchNormalization, Concatenate,
Conv2D, DepthwiseConv2D, Dropout,
GlobalAveragePooling2D, Input, Lambda, ZeroPadding2D)
from keras.models import Model
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
def relu6(x):
return relu(x, max_value=6)
def _inverted_res_block(inputs, expansion, stride, alpha, filters, block_id, skip_connection, rate=1):
in_channels = inputs.shape[-1].value # inputs._keras_shape[-1]
pointwise_conv_filters = int(filters * alpha)
pointwise_filters = _make_divisible(pointwise_conv_filters, 8)
x = inputs
prefix = 'expanded_conv_{}_'.format(block_id)
if block_id:
# Expand
x = Conv2D(expansion * in_channels, kernel_size=1, padding='same',
use_bias=False, activation=None,
name=prefix + 'expand')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999,
name=prefix + 'expand_BN')(x)
x = Activation(relu6, name=prefix + 'expand_relu')(x)
else:
prefix = 'expanded_conv_'
# Depthwise
x = DepthwiseConv2D(kernel_size=3, strides=stride, activation=None,
use_bias=False, padding='same', dilation_rate=(rate, rate),
name=prefix + 'depthwise')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999,
name=prefix + 'depthwise_BN')(x)
x = Activation(relu6, name=prefix + 'depthwise_relu')(x)
# Project
x = Conv2D(pointwise_filters,
kernel_size=1, padding='same', use_bias=False, activation=None,
name=prefix + 'project')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999,
name=prefix + 'project_BN')(x)
if skip_connection:
return Add(name=prefix + 'add')([inputs, x])
# if in_channels == pointwise_filters and stride == 1:
# return Add(name='res_connect_' + str(block_id))([inputs, x])
return x
def mobilenetV2(inputs, alpha=1, downsample_factor=8):
if downsample_factor == 8:
block4_dilation = 2
block5_dilation = 4
block4_stride = 1
atrous_rates = (12, 24, 36)
elif downsample_factor == 16:
block4_dilation = 1
block5_dilation = 2
block4_stride = 2
atrous_rates = (6, 12, 18)
else:
raise ValueError('Unsupported factor - `{}`, Use 8 or 16.'.format(downsample_factor))
first_block_filters = _make_divisible(32 * alpha, 8)
# 512,512,3 -> 256,256,32
x = Conv2D(first_block_filters,
kernel_size=3,
strides=(2, 2), padding='same',
use_bias=False, name='Conv')(inputs)
x = BatchNormalization(
epsilon=1e-3, momentum=0.999, name='Conv_BN')(x)
x = Activation(relu6, name='Conv_Relu6')(x)
x = _inverted_res_block(x, filters=16, alpha=alpha, stride=1,
expansion=1, block_id=0, skip_connection=False)
#---------------------------------------------------------------#
# 256,256,16 -> 128,128,24
x = _inverted_res_block(x, filters=24, alpha=alpha, stride=2,
expansion=6, block_id=1, skip_connection=False)
x = _inverted_res_block(x, filters=24, alpha=alpha, stride=1,
expansion=6, block_id=2, skip_connection=True)
skip1 = x
#---------------------------------------------------------------#
# 128,128,24 -> 64,64.32
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=2,
expansion=6, block_id=3, skip_connection=False)
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=1,
expansion=6, block_id=4, skip_connection=True)
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=1,
expansion=6, block_id=5, skip_connection=True)
#---------------------------------------------------------------#
# 64,64,32 -> 32,32.64
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=block4_stride,
expansion=6, block_id=6, skip_connection=False)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=7, skip_connection=True)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=8, skip_connection=True)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=9, skip_connection=True)
# 32,32.64 -> 32,32.96
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=10, skip_connection=False)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=11, skip_connection=True)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=12, skip_connection=True)
#---------------------------------------------------------------#
# 32,32.96 -> 32,32,160 -> 32,32,320
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block4_dilation, # 1!
expansion=6, block_id=13, skip_connection=False)
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=14, skip_connection=True)
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=15, skip_connection=True)
x = _inverted_res_block(x, filters=320, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=16, skip_connection=False)
return x,atrous_rates,skip1
2、加强特征提取结构
在DeeplabV3+中,加强特征提取网络可以分为两部分:
在Encoder中,我们会对压缩四次的初步有效特征层利用并行的Atrous Convolution,分别用不同rate的Atrous Convolution进行特征提取,再进行合并,再进行1x1卷积压缩特征。
在Decoder中,我们会对压缩两次的初步有效特征层利用1x1卷积调整通道数,再和空洞卷积后的有效特征层上采样的结果进行堆叠,在完成堆叠后,进行两次深度可分离卷积块。
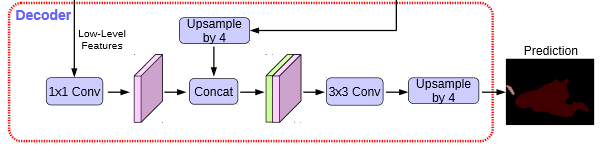
这个时候,我们就获得了一个最终的有效特征层,它是整张图片的特征浓缩。
def Deeplabv3(n_classes, inputs_size, alpha=1., backbone="mobilenet", downsample_factor=16):
img_input = Input(shape=inputs_size)
if backbone=="xception":
x,atrous_rates,skip1 = Xception(img_input,alpha, downsample_factor=downsample_factor)
elif backbone=="mobilenet":
x,atrous_rates,skip1 = mobilenetV2(img_input,alpha, downsample_factor=downsample_factor)
else:
raise ValueError('Unsupported backbone - `{}`, Use mobilenet, xception.'.format(backbone))
size_before = tf.keras.backend.int_shape(x)
# 调整通道
b0 = Conv2D(256, (1, 1), padding='same', use_bias=False, name='aspp0')(x)
b0 = BatchNormalization(name='aspp0_BN', epsilon=1e-5)(b0)
b0 = Activation('relu', name='aspp0_activation')(b0)
# rate = 6 (12)
b1 = SepConv_BN(x, 256, 'aspp1',
rate=atrous_rates[0], depth_activation=True, epsilon=1e-5)
# rate = 12 (24)
b2 = SepConv_BN(x, 256, 'aspp2',
rate=atrous_rates[1], depth_activation=True, epsilon=1e-5)
# rate = 18 (36)
b3 = SepConv_BN(x, 256, 'aspp3',
rate=atrous_rates[2], depth_activation=True, epsilon=1e-5)
# 全部求平均后,再利用expand_dims扩充维度,1x1
# shape = 320
b4 = GlobalAveragePooling2D()(x)
b4 = Lambda(lambda x: K.expand_dims(x, 1))(b4)
b4 = Lambda(lambda x: K.expand_dims(x, 1))(b4)
# 压缩filter
b4 = Conv2D(256, (1, 1), padding='same', use_bias=False, name='image_pooling')(b4)
b4 = BatchNormalization(name='image_pooling_BN', epsilon=1e-5)(b4)
b4 = Activation('relu')(b4)
# 直接利用resize_images扩充hw
b4 = Lambda(lambda x: tf.image.resize_images(x, size_before[1:3], align_corners=True))(b4)
x = Concatenate()([b4, b0, b1, b2, b3])
# 利用conv2d压缩
# 32,32,256
x = Conv2D(256, (1, 1), padding='same',
use_bias=False, name='concat_projection')(x)
x = BatchNormalization(name='concat_projection_BN', epsilon=1e-5)(x)
x = Activation('relu')(x)
x = Dropout(0.1)(x)
# x4 (x2) block
skip_size = tf.keras.backend.int_shape(skip1)
x = Lambda(lambda xx: tf.image.resize_images(xx, skip_size[1:3], align_corners=True))(x)
dec_skip1 = Conv2D(48, (1, 1), padding='same',use_bias=False, name='feature_projection0')(skip1)
dec_skip1 = BatchNormalization(name='feature_projection0_BN', epsilon=1e-5)(dec_skip1)
dec_skip1 = Activation(tf.nn.relu)(dec_skip1)
x = Concatenate()([x, dec_skip1])
x = SepConv_BN(x, 256, 'decoder_conv0',
depth_activation=True, epsilon=1e-5)
x = SepConv_BN(x, 256, 'decoder_conv1',
depth_activation=True, epsilon=1e-5)
3、利用特征获得预测结果
利用1、2步,我们可以获取输入进来的图片的特征,此时,我们需要利用特征获得预测结果。
利用特征获得预测结果的过程可以分为2步:
1、利用一个1x1卷积进行通道调整,调整成Num_Classes。
2、利用resize进行上采样使得最终输出层,宽高和输入图片一样。
#-----------------------------------------#
# 获得每个像素点的分类
#-----------------------------------------#
# 512,512
size_before3 = tf.keras.backend.int_shape(img_input)
# 512,512,21
x = Conv2D(n_classes, (1, 1), padding='same')(x)
x = Lambda(lambda xx:tf.image.resize_images(xx,size_before3[1:3], align_corners=True))(x)
x = Softmax()(x)
model = Model(img_input, x, name='deeplabv3plus')
return model
二、训练部分
1、训练文件详解
我们使用的训练文件采用VOC的格式。
语义分割模型训练的文件分为两部分。
第一部分是原图,像这样:

第二部分标签,像这样:

原图就是普通的RGB图像,标签就是灰度图或者8位彩色图。
原图的shape为[height, width, 3],标签的shape就是[height, width],对于标签而言,每个像素点的内容是一个数字,比如0、1、2、3、4、5……,代表这个像素点所属的类别。
语义分割的工作就是对原始的图片的每一个像素点进行分类,所以通过预测结果中每个像素点属于每个类别的概率与标签对比,可以对网络进行训练。
2、LOSS解析
本文所使用的LOSS由两部分组成:
1、Cross Entropy Loss。
2、Dice Loss。
Cross Entropy Loss就是普通的交叉熵损失,当语义分割平台利用Softmax对像素点进行分类的时候,进行使用。
Dice loss将语义分割的评价指标作为Loss,Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]。
计算公式如下:

就是预测结果和真实结果的交乘上2,除上预测结果加上真实结果。其值在0-1之间。越大表示预测结果和真实结果重合度越大。所以Dice系数是越大越好。
如果作为LOSS的话是越小越好,所以使得Dice loss = 1 - Dice,就可以将Loss作为语义分割的损失了。
实现代码如下:
def dice_loss_with_CE(beta=1, smooth = 1e-5):
def _dice_loss_with_CE(y_true, y_pred):
y_pred = K.clip(y_pred, K.epsilon(), 1.0 - K.epsilon())
CE_loss = - y_true[...,:-1] * K.log(y_pred)
CE_loss = K.mean(K.sum(CE_loss, axis = -1))
tp = K.sum(y_true[...,:-1] * y_pred, axis=[0,1,2])
fp = K.sum(y_pred , axis=[0,1,2]) - tp
fn = K.sum(y_true[...,:-1], axis=[0,1,2]) - tp
score = ((1 + beta ** 2) * tp + smooth) / ((1 + beta ** 2) * tp + beta ** 2 * fn + fp + smooth)
score = tf.reduce_mean(score)
dice_loss = 1 - score
# dice_loss = tf.Print(dice_loss, [dice_loss, CE_loss])
return CE_loss + dice_loss
return _dice_loss_with_CE
训练自己的DeeplabV3+模型
首先前往Github下载对应的仓库,下载完后利用解压软件解压,之后用编程软件打开文件夹。
注意打开的根目录必须正确,否则相对目录不正确的情况下,代码将无法运行。
一定要注意打开后的根目录是文件存放的目录。

一、数据集的准备
本文使用VOC格式进行训练,训练前需要自己制作好数据集,如果没有自己的数据集,可以通过Github连接下载VOC12+07的数据集尝试下。
训练前将图片文件放在VOCdevkit文件夹下的VOC2007文件夹下的JPEGImages中。
训练前将标签文件放在VOCdevkit文件夹下的VOC2007文件夹下的SegmentationClass中。

二、数据集的处理
在完成数据集的摆放之后,我们需要对数据集进行下一步的处理,目的是获得训练用的train.txt以及val.txt,需要用到根目录下的voc_annotation.py。
如果下载的是我上传的voc数据集,那么就不需要运行根目录下的voc_annotation.py。
如果是自己制作的数据集,那么需要运行根目录下的voc_annotation.py,从而生成train.txt和val.txt。

三、开始网络训练
通过voc_annotation.py我们已经生成了train.txt以及val.txt,此时我们可以开始训练了。训练的参数较多,大家可以在下载库后仔细看注释,其中最重要的部分依然是train.py里的num_classes。
num_classes用于指向检测类别的个数+1!训练自己的数据集必须要修改!
除此之外在train.py文件夹下面,选择自己要使用的主干模型backbone、预训练权重model_path和下采样因子downsample_factor。预训练模型需要和主干模型相对应。下采样因子可以在8和16中选择。

之后就可以开始训练了。
四、训练结果预测
训练结果预测需要用到两个文件,分别是deeplab.py和predict.py。
我们首先需要去deeplab.py里面修改model_path以及num_classes,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
num_classes指向检测类别的个数+1。

完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。