数据仓库基础与Apache Hive入门
文章目录
- 数据仓库基本概念
-
- 案例:中国人寿保险公司(chinalife)发展
- 数据仓库的主要特征
-
- 面向主题 Subject-Oriented
- 集成性 Integrated
- 非易失性 Non-Volatile
- 时变性 Time-Variant
- Apache Hive入门
-
- 场景设计:如何模拟实现Hive功能
-
- 案例 如何模拟实现Apache Hive的功能
- Apache Hive架构、组件
-
- Hive架构图
- Hive组件
- Apache Hive安装部署
-
- Apache Hive元数据
-
- Hive Metastore
数据仓库基本概念
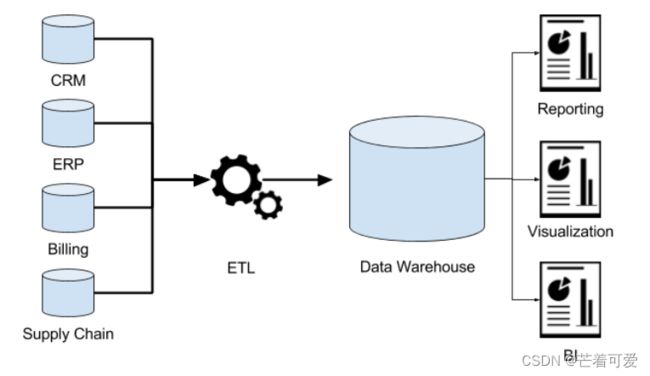
数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)。
数仓专注分析
- 数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统;
- 同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用;
- 这也是为什么叫“仓库”,而不叫“工厂”的原因。
案例:中国人寿保险公司(chinalife)发展
数据仓库为何而来,解决什么问题的?
先下结论:为了分析数据而来,分析结果给企业决策提供支撑。
- 业务数据的存储问题
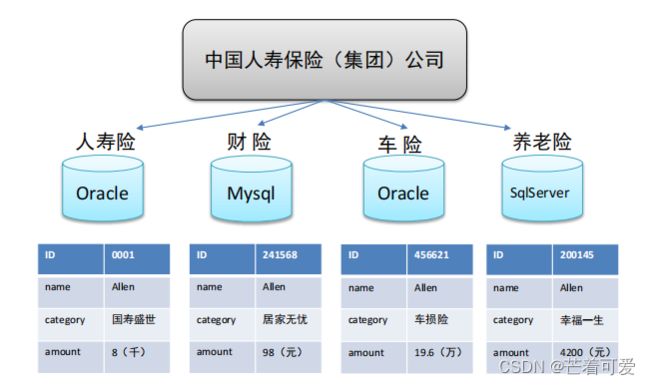
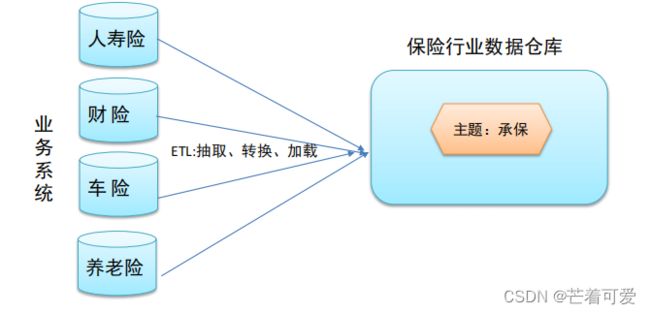
中国人寿保险(集团)公司下辖多条业务线,包括:人寿险、财险、车险,养老险等。各业务线的业务正常运营需要记录维护包括客户、保单、收付费、核保、理赔等信息。
这么多业务数据存储在哪里呢?
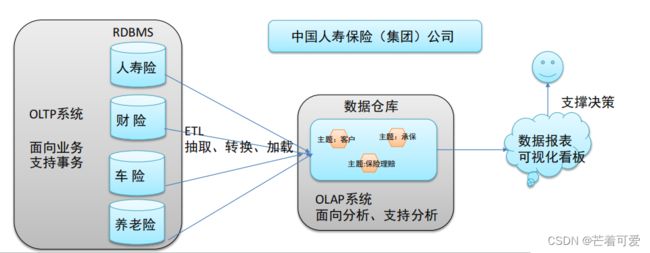
联机事务处理系统(OLTP)正好可以满足上述业务需求开展, 其主要任务是执行联机事务处理。其基本特征是前台接收的用户数据可以立即传送到后台进行处理,并在很短的时间内给出处理结果。
关系型数据库(RDBMS)是OLTP典型应用,比如:Oracle、MySQL、SQL Server等。
-
分析型决策的制定
随着集团业务的持续运营,业务数据将会越来越多。由此也产生出许多运营相关的困惑:
能够确定哪些险种正在恶化或已成为不良险种?
能够用有效的方式制定新增和续保的政策吗?
理赔过程有欺诈的可能吗?
现在得到的报表是否只是某条业务线的?集团整体层面数据如何?
为了能够正确认识这些问题,制定相关的解决措施,最稳妥办法就是:基于业务数据开展数据分析,基于分析的结果给决策提供支撑。也就是所谓的数据驱动决策的制
定。
OLTP环境开展分析可行吗?
可以,但是没必要
OLTP系统的核心是面向业务,支持业务,支持事务。所有的业务操作可以分为读、写两种操作,一般来说读的压力明显大于写的压力。如果在OLTP环境直接开展各种分析,有以下问题需要考虑:
数据分析也是对数据进行读取操作,会让读取压力倍增;
OLTP 仅存储数周或数月的数据;
数据分散在不同系统不同表中,字段类型属性不统一;
数据仓库的构建
数据仓库的主要特征
- 面向主题 Subject-Oriented
- 集成性 Integrated
- 非易失性 Non-Volatile
- 时变性 Time-Variant
面向主题 Subject-Oriented
主题是一个抽象的概念,是较高层次上数据综合、归类并进行分析利用的抽象。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象
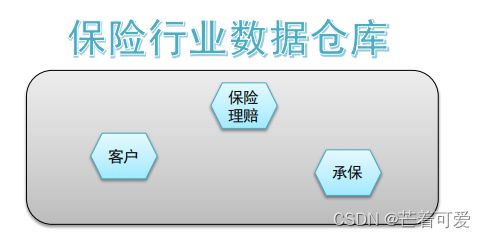
集成性 Integrated
主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。需要集成到数仓主题下。
因此在数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库建设中最关键、最复杂的一步,所要完成的工作有:
- 要统一源数据中所有矛盾之处;
如字段的同名异义、异名同义、单位不统一、字长不一致等等。 - 进行数据综合和计算。
数据仓库中的数据综合工作可以在从原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。
非易失性 Non-Volatile
也叫非易变性。数据仓库是分析数据的平台,而不是创造数据的平台。
数据仓库的数据反映的是一段相当长的时间内历史数据的内容
数据仓库中一般有大量的查询操作,但修改和删除操作很少。
时变性 Time-Variant
数据仓库包含各种粒度的历史数据,数据可能与某个特定日期、星期、月份、季度或者年份有关
当业务变化后会失去时效性。因此数据仓库的数据需要随着时间更新,以适应决策的需要。
从这个角度讲,数据仓库建设是一个项目,更是一个过程 。
Apache Hive入门
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。
Hive由Facebook实现并开源。
为什么使用Hive?
-
使用Hadoop MapReduce直接处理数据所面临的问题
人员学习成本太高 需要掌握java语言
MapReduce实现复杂查询逻辑开发难度太大 -
使用Hive处理数据的好处
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
避免直接写MapReduce,减少开发人员的学习成本
支持自定义函数,功能扩展很方便
背靠Hadoop,擅长存储分析海量数据集
Hive和Hadoop关系
- 从功能来说,数据仓库软件,至少需要具备下述两种能力:
存储数据的能力、分析数据的能力 - Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述
两种能力,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。 - 这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,
Hive帮您转换成为MapReduce程序完成对数据的分析。

场景设计:如何模拟实现Hive功能
案例 如何模拟实现Apache Hive的功能
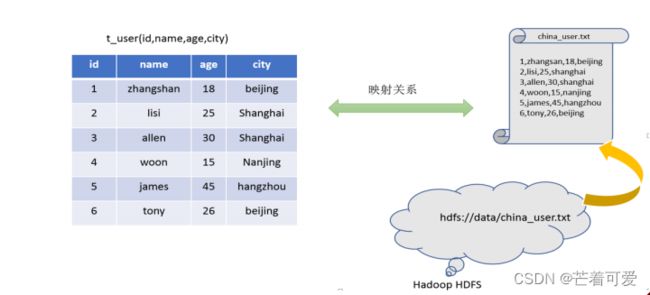
在HDFS文件系统上有一个文件,路径为/data/china_user.txt;
需求:统计来自于上海年龄大于25岁的用户有多少个?

重点理解下面两点:
Hive能将数据文件映射成为一张表,这个映射是指什么?
文件和表之间的对应关系
Hive软件本身到底承担了什么功能职责?
SQL语法解析编译成为MapReduce
映射信息记录
- 映射在数学上称之为一种对应关系,比如y=x+1,对于每一个x的值都有与之对应的y的值。 * 在hive中能够写sql处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚。
映射信息专业的叫法称之为元数据信息(元数据是指用来描述数据的数据 metadata)。 - 具体来看,要记录的元数据信息包括:
表对应着哪个文件(位置信息)
表的列对应着文件哪一个字段(顺序信息)
文件字段之间的分隔符是什么
SQL语法解析、编译
- 用户写完sql之后,hive需要针对sql进行语法校验,并且根据记录的元数据信息解读sql背后的含义,制定执行计划
- 并且把执行计划转换成MapReduce程序来具体执行,把执行的结果封装返回给用户。
最终效果

Apache Hive架构、组件
Hive架构图
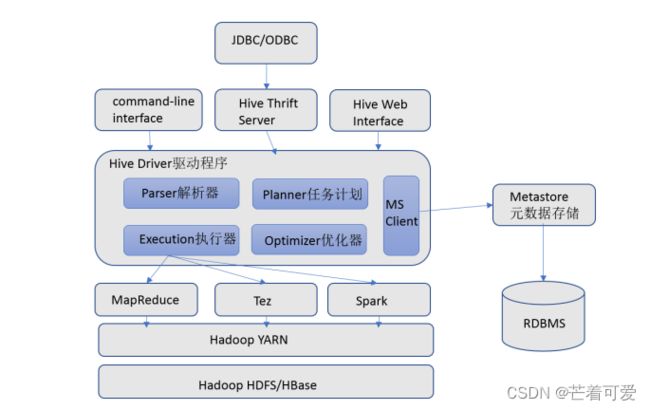
Hive组件
用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许
外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
Driver驱动程序
包括语法解析器、计划编译器、优化器、执行器
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在
随后有执行引擎调用执行。
执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
Apache Hive安装部署
Apache Hive元数据
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata
Hive Metadata即Hive的元数据。
包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息
元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
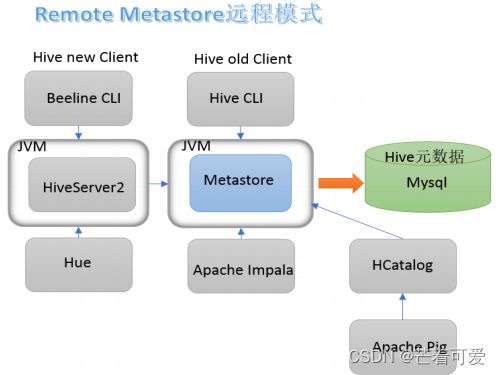
Hive Metastore
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。

metastore配置方式
metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。

- metastore远程模式
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。