吴恩达机器学习笔记(一)
文章目录
- 引言
-
- 1.1 Welcome
- 1.2 What is machine learning?
- 1.3 Supervised learning
- 1.4 Unsupervised learning
引言
1.1 Welcome
参考视频:P1 Welcome
总结:第一个视频主要讲述了什么是机器学习以及机器学习的一些应用,比如垃圾邮件识别、网页排序、产品推荐等等。
1.2 What is machine learning?
参考视频:P2 What is machine learning
总结:第二个视频主要讲述了机器学习的定义。
Arthur Samuel:在进行特定编程的情况下,给予计算机学习能力的领域。西洋棋程序可以通过观察棋盘的布局哪种会赢,哪种会输,从而通过学习,西洋棋程序了解了什么是好的布局,什么是坏的布局。
Tom Mitchell:一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。比如在西洋棋程序中,经验E 就是程序上万次的自我练习的经验而任务T 就是下棋,而性能度量值P呢,就是它在与一些新的对手比赛时赢得比赛的概率。
西瓜书:机器学习所研究的主要内容,是关于在计算机上从数据中产生"模型" 的算法,即"学习算法"。有了学习算法,把经验数据提供给它,它就能基于这些数据产生模型; 在面对新的情况时(例如看到一个没剖开的西瓜),模型会给我们提供相应的判断(例如好瓜) 。如果说计算机科学是研究关于"算法"的学问,那么类似,可以说机器学习是研究关于"学习算法"的学问。
1.3 Supervised learning
参考视频:P3 Supervised learning
总结:第三个视频主要讲述了什么是监督学习。
监督学习:利用带有标签的训练样本训练一个模型,再用训练好的模型对新样本进行预测,其本质为,构建一个模型来表示输入到输出的映射。主要有分类问题和回归问题。
回归问题:预测连续值的输出,比如房价预测,西瓜的成熟度等等。
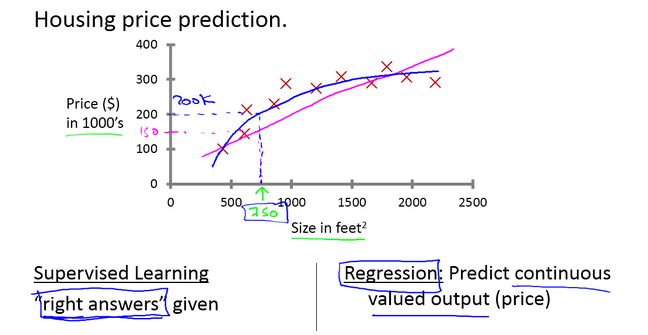
分类问题:预测离散值的输出,比如判断肿瘤是良性还是恶性,判断西瓜是好瓜还是坏瓜等等。

1.4 Unsupervised learning
参考视频:P4 Unsupervised learning
总结:第四个视频主要讲述了什么是无监督学习。
无监督学习:利用无标签或少量标签的数据,构建一个模型算法来学习数据之间的分布和关系,从而挖掘出数据之间隐藏的模式信息。常用场景为聚类和降维。
聚类:将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇,通过这样的划分,每个簇可能对应于一些潜在的概念。比如客户群划分,西瓜品种划分等等。
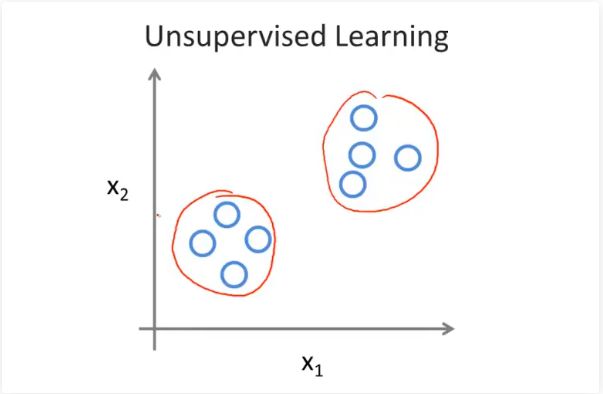
降维:通过某种数学变换将原始的高维属性空间转变为一个低纬的子空间,使得样本密度大幅提高,能够缓解维数灾难问题,即在高维情形下出现的数据样本稀疏、距离计算困难的问题,其依据为在很多时候,人们观测或收集到的数据样本虽然是高维的,但与学习任务密切相关的也许仅是某个低维分布,即高维空间中的一个低维嵌入,比如PCA(主成分分析,无监督)和LDA(线性判别分析,有监督)算法等。

参考引用
- 吴恩达机器学习视频
- 周志华 《机器学习》