图像分类网络模型框架解读
分类网络的基本结构
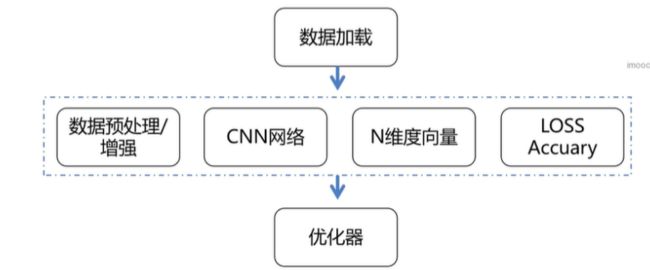
数据加载
RGB数据OR BGR数据
JPEG编码后的数据
torchvision.datasets中的数据集
torch.utils.data下的Dataset,DataLoader自定义数据集
数据增强
为什么需要数据增强?
在图像分类过程中,为了能够提高分类准确率,一般都需要对图像进行一定程度上增强。否则会导致出现模糊现象。
数据增强的时候需要注意什么?
首先,在进行数据增强过程中,一定要确保增强结果真实可靠,其次,在进行数据增强过程中,一定要保证合理性。还有,在进行数据增强过程中,一定要保证所选数据集与目标图像具有相似性。
torchvision.transforms
train_transforms=transforms.Compose([transforms.RandomResizedCrop((227,227)),
transforms.ToTensor(),])
网络结构

类别概率分布
N维度向量对应N个类别
将卷积输出的tensor转换成N维度向量
Softmax
softmax,其实就是一种概率运算方法,它主要作用,就是可以有效地处理图像中非线性特征。适用于分类问题。
LOSS
nn.CrossEntropyLoss
交叉熵损失函数,是一种在损失函数中,引入了噪声干扰因素,从而来提高系统预测准确率。一种衡量输入数据与目标数据相似程度函数。
label smoothing
label smoothing,对样本进行标准化处理方法,它主要作用,就是可以有效地提高样本泛化能力。或者说一种隐藏层提取特征方法,就是能够有效地帮助我们提取隐藏层特征
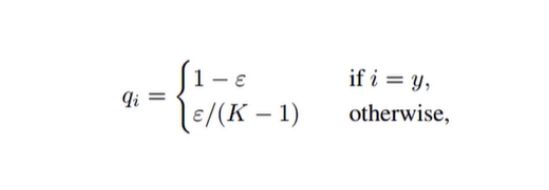
分类问题常用评价指标
正确率(accuracy):(TP+TN)/(P+N)
错误率(error rate):(FP+FN)/(P+N)
灵敏度(sensitive):sensitive=TP/P
特效度(specificity):TN/N
精度(precision):TP/(TP+FP)
召回率(recall):TP/(TP+FN)=TP/P=sensitive
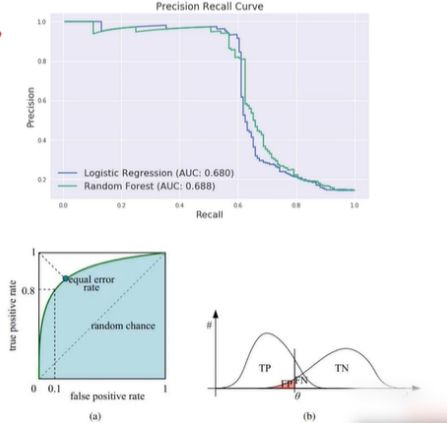
PR曲线、ROC曲线、AUC面积
预测值=1 |
预测值=0 |
|
真实值=1 |
TP |
FN |
真实值=0 |
FP |
TN |
PR曲线 VS ROC 曲线
PR曲线
ROC曲线、AUC 曲线
TPR=TP/(TP+FN)
FPR=FP/(FP+TN)
优化器选择
推荐使用:torch.optim.Adam
学习率初值:lr=0.001
学习率指数衰减:torch.optim.lr_scheduler.ExponentialLR
Cifar10/100
8000万个微小图像数据集的子集
由Alex Krizhevsky,Vinod Nair, Geoffrey Hinton收集

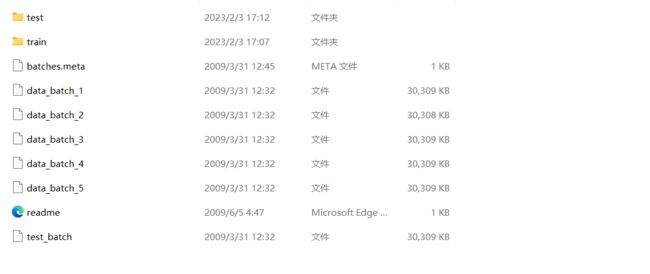
Cifar10数据读取及处理
从官网下载数据集,新建两个文件夹train、test
import pickle
import cv2
import numpy as np
import glob
import os
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
label_name = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
train_list = glob.glob("D:/Users/86187/Downloads/pycharm/pycharmprojects/cifar10/cifar-10-batches-py/data_batch_*")
print(train_list)
save_path = "D:/Users/86187/Downloads/pycharm/pycharmprojects/cifar10/cifar-10-batches-py/train"
for l in train_list:
print(l)
l_dict = unpickle(l)
# print(l_dict)
print(l_dict.keys())
for im_idx, im_data in enumerate(l_dict[b'data']):
# print(im_idx)
# print(im_data)
im_label = l_dict[b'labels'][im_idx]
im_name = l_dict[b'filenames'][im_idx]
print(im_label, im_name, im_data)
im_label_name = label_name[im_label]
im_data = np.reshape(im_data, [3, 32, 32])
im_data = np.transpose(im_data, (1, 2, 0))
# cv2.imshow("im_data", cv2.resize(im_data, (400, 400)))
# cv2.waitKey(0)
if not os.path.exists("{}/{}".format(save_path, im_label_name)):
os.mkdir("{}/{}".format(save_path, im_label_name))
cv2.imwrite("{}/{}/{}".format(save_path, im_label_name, im_name.decode("utf-8")), im_data)
import pickle
import cv2
import numpy as np
import glob
import os
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
label_name = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
train_list = glob.glob("D:/Users/86187/Downloads/pycharm/pycharmprojects/cifar10/cifar-10-batches-py/data_batch_*")
print(train_list)
save_path = "D:/Users/86187/Downloads/pycharm/pycharmprojects/cifar10/cifar-10-batches-py/test"
for l in train_list:
print(l)
l_dict = unpickle(l)
# print(l_dict)
print(l_dict.keys())
for im_idx, im_data in enumerate(l_dict[b'data']):
# print(im_idx)
# print(im_data)
im_label = l_dict[b'labels'][im_idx]
im_name = l_dict[b'filenames'][im_idx]
print(im_label, im_name, im_data)
im_label_name = label_name[im_label]
im_data = np.reshape(im_data, [3, 32, 32])
im_data = np.transpose(im_data, (1, 2, 0))
# cv2.imshow("im_data", cv2.resize(im_data, (400, 400)))
# cv2.waitKey(0)
if not os.path.exists("{}/{}".format(save_path, im_label_name)):
os.mkdir("{}/{}".format(save_path, im_label_name))
cv2.imwrite("{}/{}/{}".format(save_path, im_label_name, im_name.decode("utf-8")), im_data)