深度学习在视频多目标跟踪中的应用综述
文章目录
- 摘要
- 1、简介
- 2、MOT:算法、指标和数据集
-
- 2.1、MOT算法简介
- 2.2、指标
-
- 经典的指标
- 完整的MOT指标
- ID 分数
- 2.3、基准数据集
- 3、MOT中的深度学习
-
- 3.1、深度学习中的检测步骤
-
- 3.1.1、Faster R-CNN
- 3.1.2、SSD
- 3.1.3、Other detectors
- 3.1.4、cnn在检测步骤中的其他用途
- 3.2、深度学习在特征提取和运动预测中的应用
-
- 3.2.1、自动编码器:深度学习首次在MOT管道中使用
- 3.2.2、cnn作为视觉特征提取器
- 3.2.3、孪生网络
- 3.2.4、更复杂的视觉特征提取方法
- 3.2.5、用于运动预测的cnn:相关滤波器
- 3.2.6、其他方法
- 3.3、匹配计算中的深度学习
-
- 3.3.1、循环神经网络和lstm
- 3.3.2、孪生LSTMs
- 3.3.3、双向LSTMs
- 3.3.4 lstm在MHT框架中的使用
- 3.3.5 其他递归网络
- 3.3.6、用于匹配度计算的cnn
- 3.3.7、孪生cnn
- 3.4、DL在关联/跟踪步骤
-
- 3.4.1、循环神经网络
- 3.4.2、深度多层感知器
- 3.4.3、深度强化学习智能体
- 3.5、DL在MOT中的其他用途
- 4、分析与比较
-
- 4.1、设置和组织
- 4.2、结果的讨论
-
- 总体评论
- MOT四个步骤中的最佳方法
- 性能最好的算法的其他趋势
- 5、结论与未来发展方向
摘要
论文链接:https://arxiv.org/pdf/1907.12740.pdf
多目标跟踪(MOT)的问题包括在一个序列中跟踪不同物体的轨迹,通常是一个视频。近年来,随着深度学习的兴起,为这个问题提供解决方案的算法受益于深度模型的表示能力。本文对利用深度学习模型解决单摄像机视频的MOT任务的工作进行了全面的调查。确定了MOT算法的四个主要步骤,并深入回顾了深度学习如何在每个阶段中使用。还提供了对三个MOTChallenge数据集上所述工作的完整实验比较,确定了一些顶级性能方法之间的相似性,并提出了一些可能的未来研究方向。
关键词 多目标跟踪·深度学习·视频跟踪·计算机视觉·卷积神经网络·LSTM·强化学习
1、简介
多目标跟踪(MOT),也称为多目标跟踪(MTT),是一种计算机视觉任务,旨在分析视频,以识别和跟踪属于一个或多个类别的对象,如行人、汽车、动物和无生命物体,而不需要任何关于目标外观和数量的先验知识。与对象检测算法不同的是,对象检测算法的输出是由坐标、高度和宽度标识的矩形包围框的集合,MOT算法还将目标ID关联到每个框(称为检测),以区分类内对象。MOT算法输出的示例如图1所示。MOT任务在计算机视觉中扮演着重要的角色:从视频监控到自动驾驶汽车,从动作识别到人群行为分析,许多这些问题都将受益于高质量的跟踪算法。
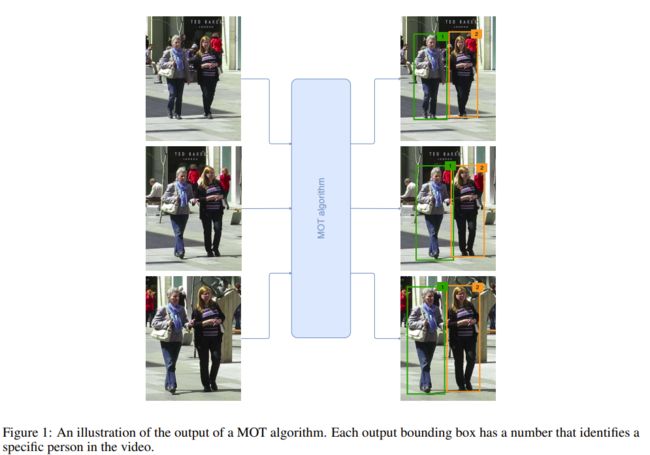
在单目标跟踪(SOT)中,目标的外观是先验已知的,而在MOT中,需要一个检测步骤来识别目标,这些目标可以离开或进入场景。同时跟踪多个目标的主要困难来自于物体之间的各种遮挡和相互作用,这些物体有时也具有相似的外观。因此,简单地应用SOT模型直接求解MOT会导致较差的结果,通常会导致目标漂移和大量ID切换错误,因为此类模型通常难以区分外观相似的类内对象。近年来开发了一系列专门针对多目标跟踪的算法来解决这些问题,以及一些基准数据集和竞赛,以简化不同方法之间的比较。
最近,越来越多这样的算法开始利用深度学习(DL)的表征能力。深度神经网络(DNN)的优势在于它们能够学习丰富的表示形式,并从输入中提取复杂和抽象的特征。卷积神经网络(CNN)目前是空间模式提取的最先进技术,用于图像分类[1,2,3]或物体检测[4,5,6]等任务,而长短期记忆(LSTM)等循环神经网络(RNN)用于处理顺序数据,如音频信号、时间序列和文本[7,8,9,10]。由于DL方法已经能够在许多这些任务中达到最佳性能,我们现在逐渐看到它们被用于大多数性能最佳的MOT算法中,帮助解决问题划分的一些子任务。
这项工作介绍了利用深度学习模型的功能来执行多对象跟踪的算法的调查,重点是用于MOT算法的各个组件的不同方法,并将它们放在每个提议的方法的上下文中。虽然MOT任务可以应用于2D和3D数据,也可以应用于单摄像头和多摄像头场景,但在本次调查中,我们主要关注从单摄像头记录的视频中提取的2D数据。
关于MOT的一些综述和调查已经发表。它们的主要贡献和局限性如下:
-
Luo等人[11]提出了第一个专门关注MOT的综合综述,特别是行人跟踪。他们提供了MOT问题的统一公式,并描述了在MOT系统的关键步骤中使用的主要技术。他们将深度学习作为未来的研究方向之一,因为当时只有极少数算法采用了深度学习。
-
Camplani等人[12]提出了一项关于多重行人跟踪的调查,但他们关注的是RGB- d数据,而我们的重点是2D RGB图像,没有额外的输入。此外,他们的综述没有涵盖基于深度学习的算法。
-
Emami等人[13]提出了一种将单传感器和多传感器跟踪任务作为多维分配问题(MDAP)的公式。他们还提出了一些在跟踪问题中使用深度学习的方法,但这不是他们论文的重点,他们也没有提供这些方法之间的任何实验比较。
-
Leal-Taixé等人。[14]对MOT15[15]和MOT16[16]数据集上的算法获得的结果进行了分析,提供了关于结果的研究趋势线和统计数据的摘要。他们发现,在2015年之后,方法已经从试图为关联问题找到更好的优化算法转变为专注于改进亲和模型,他们预测,更多的方法将通过使用深度学习来解决这一问题。然而,这项工作也没有关注深度学习,也没有涵盖最近几年发表的MOT算法。
在本文中,基于所讨论的局限性,我们的目的是提供一个调查,主要贡献如下:
-
我们提供了关于深度学习在多目标跟踪中的使用的第一次全面调查,重点是从单摄像头视频中提取的2D数据,包括过去调查和评论中没有涵盖的近期作品。DL在MOT中的应用实际上是最近的事情,许多方法在过去三年中已经发表。
-
我们确定了MOT算法中的四个常见步骤,并描述了每个步骤中采用的不同DL模型和方法,包括使用它们的算法上下文。每个被分析的作品所使用的技术也被总结在一个表中,以及可用源代码的链接,作为未来研究的快速参考。
-
我们收集了最常用的MOT数据集的实验结果,以在它们之间进行数值比较,也确定了表现最好的算法的主要趋势。
-
最后,我们讨论了未来可能的研究方向。
综述是按照这种方式进一步组织的。在第2节中,我们首先描述了MOT算法的一般结构和最常用的指标和数据集。第3节在MOT算法的四个确定步骤中探索了各种基于dl的模型和算法。第4节介绍了所提出的算法之间的数值比较,并确定了当前方法的共同趋势和模式,以及一些局限性和未来可能的研究方向。最后,第5节总结前几节的调研结果,并提出一些最后的评论。
2、MOT:算法、指标和数据集
在本节中,对MOT问题进行了一般描述。MOT算法的主要特征和常用步骤在2.1节中进行了识别和描述。通常用于评估模型性能的指标在2.2节中讨论,而最重要的基准数据集在2.3节中给出。
2.1、MOT算法简介
MOT算法中采用的标准方法是检测跟踪:从视频帧中提取一组检测(即识别图像中目标的边界框),并用于指导跟踪过程,通常通过将它们关联在一起,以便为包含相同目标的边界框分配相同的ID。由于这个原因,许多MOT算法将任务表述为分配问题。现代检测框架[4,17,18,5,6]确保了良好的检测质量,大多数MOT方法(如我们将看到的,有一些例外)一直专注于改善关联;事实上,许多MOT数据集提供了一个标准的检测集,可以由算法使用(因此可以跳过检测阶段),以便专门比较它们在关联算法质量上的性能,因为检测器性能会严重影响跟踪结果。
MOT算法也可分为批处理方法和在线方法。批处理跟踪算法允许使用未来信息(即来自未来帧),当试图确定某一帧中的对象身份时。它们经常利用全局信息,从而获得更好的跟踪质量。相反,在线跟踪算法只能使用现在和过去的信息来预测当前帧。这在某些场景下是必需的,比如自动驾驶和机器人导航。与批处理方法相比,在线方法往往表现更差,因为它们不能使用未来的信息修复过去的错误。需要注意的是,虽然实时算法需要以在线方式运行,但并不是每个在线方法都必须实时运行;事实上,除了极少数例外,在线算法在实时环境中仍然太慢,特别是在利用深度学习算法时,这通常是计算密集型的。
尽管文献中提出了各种各样的方法,但绝大多数MOT算法共享以下部分或全部步骤(如图2所示):
-
检测阶段:对象检测算法分析每个输入帧,使用包围框识别属于目标类的对象,在MOT上下文中也称为“检测”;
-
特征提取/运动预测阶段:一个或多个特征提取算法分析检测和/或轨迹,以提取外观、运动和/或交互特征。可选地,运动预测器预测每个跟踪目标的下一个位置;
-
相似匹配阶段:特征和运动预测用于计算检测对和/或轨迹之间的相似度/距离分数;
-
关联阶段:相似度/距离度量用于关联属于同一目标的检测和轨迹,通过为识别同一目标的检测分配相同的ID。

虽然这些阶段可以按照这里给出的顺序依次执行(对于在线方法,通常每帧执行一次,对于批处理方法,整个视频执行一次),但有许多算法将这些步骤中的一些合并在一起,或者将它们交织在一起,甚至使用不同的技术多次执行它们(例如,在两个阶段工作的算法中)。此外,一些方法不直接将检测联系在一起,但使用它们来改进轨迹预测和管理新轨迹的初始化和终止;尽管如此,正如我们将看到的,即使在这种情况下,许多提出的步骤通常仍然可以确定。
2.2、指标
为了提供一个可以公平地测试和比较算法的通用实验设置,一组度量标准实际上已经被建立起来,并且几乎在所有工作中都使用它们。最相关的是Wu和Nevatia定义的指标[19],所谓的CLEAR MOT指标[20],以及最近的ID指标[21]。这些度量集旨在反映测试模型的总体性能,并指出每个模型可能存在的缺陷。因此,这些指标的定义如下:
经典的指标
Wu和Nevatia[19]定义的这些度量指标强调了MOT算法可能犯的不同类型的错误。为了显示这些问题,计算以下值:
-
大部分跟踪(MT)轨迹:在至少80%的帧中被正确跟踪的地面真实轨迹的数量。
-
片段:轨迹假设,最多覆盖80%的真实轨迹。观察到一个真实的轨迹可以被多个碎片覆盖。
-
大部分丢失(ML)轨迹:在不到20%的帧内被正确跟踪的地面真实轨迹的数量。
-
虚假轨迹:与真实物体不对应的预测轨迹(即地面真实轨迹)。
-
ID切换:对象被正确跟踪,但对象的关联ID被错误更改的次数。
完整的MOT指标
CLEAR MOT指标是为2006[22]和2007[23]举行的事件、活动和关系分类(CLEAR)研讨会开发的。这些研讨会由欧洲CHIL项目、美国VACE项目和美国国家标准与技术研究所(NIST)联合组织。这些指标是MOTA(多目标跟踪精度)和MOTP(多目标跟踪精度)。它们是构成它们的其他简单指标的总结。我们将首先解释简单的度量标准,然后在此基础上构建复杂的度量标准。[20]中详细描述了如何将真实对象(ground truth)与跟踪器假设相匹配,因为如何考虑一个假设何时与一个对象相关并不简单,这取决于要评估的精确跟踪任务。在我们的例子中,当我们专注于单摄像机的2D跟踪时,最常用的度量来确定对象和预测是否相关的是包围框的交集除以联合(IoU),因为它是在MOT15数据集[15]的演示论文中建立的度量。具体而言,建立了ground truth与假设之间的映射关系:如果ground truth对象oi与假设hj在框架t−1中匹配,并且在框架t中 I o U ( o i , h j ) ≥ 0.5 IoU(o_i, h_j)≥0.5 IoU(oi,hj)≥0.5,则oi与hj在该框架中匹配,即使存在另一个假设hk,使得 I o U ( o i , h j ) < I o U ( o i , h k ) IoU(o_i, h_j)< IoU(o_i, h_k) IoU(oi,hj)<IoU(oi,hk),考虑连续性约束。在完成前一帧的匹配后,剩余的对象将尝试与剩余的假设匹配,仍然使用0.5的IoU阈值。不能与假设关联的ground truth边界框被视为假阴性(FN),不能与真实边界框关联的假设被标记为假阳性(FP)。另外,在跟踪期间,每次被跟踪的地面真相对象的ID被错误更改,每次被跟踪的地面真相对象的ID被错误更改,都被计算为一次ID切换。然后,计算出的简单指标如下:
- FP:整个视频的误报数;
- FN:整段视频的假阴性数;
- Fragm:碎片总数;
- IDSW: ID交换机总数。
MOTA评分定义如下:
M O T A = 1 − ( F N + F P + I D S W ) G T ∈ ( − ∞ , 1 ] M O T A=1-\frac{(F N+F P+I D S W)}{G T} \in(-\infty, 1] MOTA=1−GT(FN+FP+IDSW)∈(−∞,1]
GT是地面真值框的个数。需要注意的是,分数可以是负的,因为算法可能会犯比基本真理框数量更大的错误。通常,不报告MOTA,而是报告百分比MOTA,这只是前面的表达式表示为百分比。另一方面,MOTP的计算为:
MOTP = ∑ t , i d t , i ∑ t c t \operatorname{MOTP}=\frac{\sum_{t, i} d_{t, i}}{\sum_{t} c_{t}} MOTP=∑tct∑t,idt,i
其中 c t c_t ct表示在框架t中匹配的数量, d t , i d_{t,i} dt,i是假设i与其指定的ground truth对象之间的边界框重叠。需要注意的是,这个指标很少考虑跟踪信息,而是关注检测的质量。
ID 分数
MOTA评分的主要问题是,它考虑了跟踪器做出错误决定的次数,例如切换ID,但在某些情况下(例如机场安全),人们可能更感兴趣的是奖励能够尽可能长时间跟踪对象的跟踪器,以便不丢失其位置。正因为如此,在[21]中定义了两个可选的新指标,这应该是对CLEAR MOT指标所给出的信息的补充。映射不是逐帧匹配地面真相和检测,而是全局执行,分配给给定地面真相轨迹的轨迹假设是最大限度地为地面真相正确分类的帧数。为了解决该问题,构造了一个二部图,取该问题的最小代价解作为问题解。对于二部图,顶点集定义如下:第一个顶点集 V T V_T VT对于每一个真轨迹都有一个所谓的正则节点,对于每一个计算的轨迹都有一个假阳性节点。第二个集合 V C V_C VC,对于每个计算的轨迹都有一个常规节点,对于每个真实的轨迹都有一个假阴性。设置边缘的代价是为了在选择边缘的情况下计算假阴性和假阳性帧的数量(更多信息可以在[21]中找到)。在执行关联之后,根据所涉及节点的性质,有四种不同的可能对。如果 V T V_T VT中的正则节点与 V C V_C VC中的正则节点相匹配(即真实轨迹与计算轨迹相匹配),则计数为真正ID。 V T V_T VT中的每一个假阳性与VC中的一个常规节点匹配,都算作一个假阳性ID。 V T V_T VT中的每一个常规节点匹配 V C V_C VC中的一个假阴性都算一个假阴性ID,最后,每一个假阳性匹配 V C V_C VC中的一个假阴性ID都算一个真阴性ID。然后,计算三个分数。IDTP是选取为真正ID匹配的边的权值之和(它可以看作是在整个视频中正确分配的检测的百分比)。IDFN为所选假阴性ID边权值之和,IDFP为所选假阳性ID边权值之和。利用这三个基本指标,计算出另外三个指标:
- Identification precision: I D P = I D T P I D T P + I D F P I D P=\frac{I D T P}{I D T P+I D F P} IDP=IDTP+IDFPIDTP
- Identification recall: I D R = I D T P I D T P + I D F N I D R=\frac{I D T P}{I D T P+I D F N} IDR=IDTP+IDFNIDTP
- Identification F1: I D F 1 = 2 1 I D P + 1 I D R = 2 I D T P 2 I D T P + I D F P + I D F N IDF1 =\frac{2}{\frac{1}{I D P}+\frac{1}{I D R}}=\frac{2 I D T P}{2 I D T P+I D F P+I D F N} IDF1=IDP1+IDR12=2IDTP+IDFP+IDFN2IDTP
通常,几乎每一项工作中报告的指标都是CLEAR MOT指标,主要是跟踪轨迹(MT),主要是丢失轨迹(ML)和IDF1,因为这些指标是MOTChallenge排行榜中显示的指标(详见2.3节)。此外,跟踪器可以处理的每秒帧数(FPS)经常被报告,也包括在排行榜中。然而,我们发现这个度量很难在不同的算法之间进行比较,因为一些方法包括检测阶段,而另一些方法跳过了这个计算。此外,对所使用的硬件的依赖也与速度有关。
2.3、基准数据集
在过去的几年中,已经发表了大量的MOT数据集。在本节中,我们将介绍最重要的几个,从MOTChallenge基准测试的一般描述开始,然后重点介绍其数据集,最后介绍KITTI和其他不太常用的MOT数据集。
MOTChallenge。MOTChallenge(https://motchallenge.net/)是多对象跟踪最常用的基准测试。除其他外,它提供了目前公开的一些最大的行人跟踪数据集。对于每个数据集,提供了训练分割的基本真理,以及训练和测试分割的检测。MOTChallenge数据集经常提供检测(通常被称为公共检测,而不是算法作者通过使用自己的检测器获得的私有检测)的原因是检测质量对跟踪器的最终性能有很大影响,但算法的检测部分通常独立于跟踪部分,通常使用已经存在的模型;提供每个模型都可以使用的公共检测使得跟踪算法的比较更容易,因为检测质量从性能计算中剔除,跟踪器开始于一个共同的基础。算法在测试数据集上的评估是通过将结果提交给测试服务器来完成的。MOTChallenge网站包含每个数据集的排行榜,在单独的页面上显示使用公共提供的检测模型和使用私人检测的模型。在线方法也是这样标记的。MOTA是MOTA挑战赛的主要评估分数,但还有许多其他指标,包括2.2节中介绍的所有指标。正如我们将看到的,由于绝大多数使用深度学习的MOT算法都专注于行人,因此mott challenge数据集是使用最广泛的,因为它们是目前可用的最全面的数据集,提供了更多的数据来训练深度模型。
MOT15。第一个MOTChallenge数据集是2D MOT 2015(Dataset: https://motchallenge.net/data/2D_MOT_2015/, leaderboard: https://motchallenge.net/results/2D_
MOT_2015/)15。它包含一系列22个视频(11个用于训练,11个用于测试),从旧的数据集中收集,具有各种各样的特征(固定和移动的摄像机,不同的环境和照明条件,等等),因此模型需要更好地概括,以便在其上获得良好的结果。它总共包含11283个不同分辨率的帧,1221个不同的身份和101345个盒子。所提供的检测是使用ACF检测器[24]获得的。
MOT16/17。该数据集的新版本于2016年发布,名为MOT16(Dataset: https://motchallenge.net/data/MOT16/, leaderboard: https://motchallenge.net/results/MOT16/)[16]。这一次,基本真相是从头开始的,因此它在整个数据集是一致的。视频也更有挑战性,因为它们有更高的行人密度。集合中总共包含14个视频(7个用于训练,7个用于测试),其中使用基于变形部分的模型(DPM) v5[25,26]获得的公共检测,与其他模型相比,他们发现在检测数据集上的行人时获得了更好的性能。这次数据集包括11235帧,1342个身份和292733个盒子。MOT17数据集(Dataset: https://motchallenge.net/data/MOT17/, leaderboard: https://motchallenge.net/results/MOT17/)包括与MOT16相同的视频,但具有更准确的地面真相,每个视频有三组检测:一组来自Faster R-CNN[4],一组来自DPM,一组来自Scale-Dependent Pooling detector (SDP)[27]。然后,这些跟踪器必须被证明是多功能的,足够强大,才能在使用不同的检测质量时获得良好的性能。
MOT19。最近,CVPR 2019跟踪挑战赛(https://motchallenge.net/workshops/bmtt2019/tracking.html)发布了一个新版本的数据集,包含8个行人密度极高的视频(4个用于训练,4个用于测试),在最拥挤的视频中,平均每帧行人达245人。数据集包含13410帧,6869个轨道和2259143个盒子,远远超过之前的数据集。虽然该数据集只允许在有限的时间内提交,但该数据将成为2019年底发布MOT19[28]的基础。
KITTI。MOTChallenge数据集侧重于行人跟踪,KITTI跟踪基准(http://www.cvlibs.net/datasets/kitti/eval_tracking.php)[29,30]允许对人和车辆进行跟踪。该数据集是通过在城市周围驾驶汽车收集的,并于2012年发布。它由21个训练视频和29个测试视频组成,共计约19000帧(32分钟)。它包括使用DPM(The website says the detections were obtained using a model based on a latent SVM, or L-SVM. That model is now known as
Deformable Parts Model (DPM))和RegionLets(http://www.xiaoyumu.com/project/detection)[31]探测器获得的探测,以及立体声和激光信息;然而,如前所述,在本次调查中,我们将只关注使用2D图像的模型。CLEAR MOT指标、MT、ML、ID开关和碎片被用来评估这些方法。可以只提交行人的结果,也可以只提交汽车的结果,并且为这两个类别维护了两个不同的排行榜。
其他数据集。除了前面描述的数据集之外,还有一些较老的,现在不太常用的数据集。在这些数据中,我们可以找到UA-DETRAC跟踪基准(https://detrac-db.rit.albany.edu/Tracking)[32],它专注于交通摄像头跟踪的车辆,以及TUD(https://www.d2.mpi-inf.mpg.de/node/428)[33]和PETS2009(http://www.cvg.reading.ac.uk/PETS2009/a.html)[34]数据集,它们都专注于行人。他们的许多视频现在都是MOTChallenge数据集的一部分。
3、MOT中的深度学习
由于本次综述的重点是深度学习在MOT任务中的使用,我们将该部分分为五个子部分。前四个小节中的每一个小节都回顾了在前面定义的四个MOT阶段中如何利用深度学习。第3.4小节除了介绍深度学习在关联过程中的使用外,还将包括其在整个赛道管理过程中的使用(例如赛道的初始化/终止),因为它与关联步骤严格相关。第3.5小节将最后描述深度学习在MOT中的应用,这些应用不适合四步方案。
我们在附录A中收录了一个汇总表,显示了本次调查中每篇论文中四个步骤中每个步骤中使用的主要技术。说明了操作模式(批处理vs.在线),还包括到源代码或其他提供材料的链接(如果可用)。
3.1、深度学习中的检测步骤
虽然许多工作已将各种检测器生成的检测作为其算法数据集的输入(例如,聚合通道特征[24]用于MOT15[15]或可变形部件模型[25]用于MOT16[16]),也有算法集成了自定义检测步骤,通过提高检测质量通常有助于提高整体跟踪性能。
正如我们将看到的,大多数采用自定义检测的算法都使用了Faster R-CNN及其变体(3.1.1节)或SSD(3.1.2节),但也存在使用不同模型的方法(3.1.3节)。尽管绝大多数算法利用深度学习模型来提取矩形边界框,但少数工作在检测步骤中对深度网络进行了不同的使用:这些工作是3.1.4节的重点。

3.1.1、Faster R-CNN
简单的在线实时跟踪(SORT)算法[35]已经成为第一个利用卷积神经网络进行行人检测的MOT管道之一。Bewley等研究表明,将使用聚合通道特征(Aggregated Channel Features, ACF)[24]得到的检测替换为Faster R-CNN[4]计算得到的检测(如图3所示),可以将MOT15数据集[15]上的MOTA分数提高18.9%(绝对变化)。他们使用了一种相对简单的方法,即使用卡尔曼滤波器[36]预测目标运动,然后将检测与匈牙利算法[37]的帮助相关联,使用交并比(IoU)距离计算成本矩阵。在本文发表时,SORT被评为MOT15数据集上性能最好的开源算法。
Yu等人使用改进的Faster R-CNN在[38]中得出了相同的结论,其中包括跳跃池化[39]和多区域特征[40],并在多个行人检测数据集上进行了微调。使用这种架构,他们能够将他们提出的算法(参见3.2.2节)的性能提高30%以上(绝对变化,在MOTA中测量),在MOT16数据集[16]上达到了最先进的性能。他们还表明,具有更高质量的检测减少了对复杂跟踪算法的需求,同时仍然获得类似的结果:这是因为MOTA分数在很大程度上受到假阳性和假阴性数量的影响,使用准确的检测是减少两者的有效方法。[38]在MOT16数据集上计算的检测也已经公开,许多MOT算法已经利用了它们[41,42,43,44,45,46,47,48,49,50,51]。
在接下来的几年中,其他工作利用了Faster R-CNN的检测精度,已作为MOT算法的一部分应用于检测运动员[52]、细胞[53]和猪[54]。此外,Zhou等人还使用了一种添加了分割分支的Faster R-CNN的自适应方法Mask R-CNN[17]来检测和跟踪行人。
3.1.2、SSD
SSD[5]检测器是检测步骤中另一种常用的网络。Zhang et al.[54]将其与Faster R-CNN和R-FCN[18]在他们的pig跟踪管道中进行了比较,表明它在他们的数据集上工作得更好。他们采用了一种基于判别式相关滤波器(DCF)的在线跟踪方法[56],并使用HOG[57]和颜色名称[58]特征来预测所谓的标签框(tag-boxes)的位置,即每个动物中心周围的小区域。使用匈牙利算法进行跟踪标签框与检测之间的关联,在跟踪失败的情况下,使用DCF跟踪器的输出来细化边界框。Lu等人[59]也使用了SSD,但在这种情况下检测了各种要跟踪的对象类(人、动物、汽车等,参见3.2.4节)。
一些工作试图通过考虑跟踪算法其他步骤中获得的信息来改进SSD得到的检测结果。Kieritz等人[60]在他们的联合检测和跟踪框架中,使用轨迹和检测之间计算的亲和度分数来取代SSD网络中包含的标准非极大值抑制(NMS)步骤,并使用一个版本来根据它们与被跟踪目标的对应关系来细化检测置信度分数。
相反,Zhao等人[61]使用SSD检测器在场景中搜索行人和车辆,但他们使用基于cnn的相关滤波器(CCF)使SSD生成更准确的边界框。CCF利用PCA-compressed [62] CNN特征预测目标在后续帧中的位置;然后利用预测的位置裁剪它周围的ROI(感兴趣区域),并将其作为SSD的输入。通过这种方式,网络能够使用更深的层来计算小的检测,这些层提取了更有价值的语义信息,从而可以产生更准确的边界框和更少的假阴性。然后,该算法通过NMS步骤将这些检测与在全图像上获得的检测相结合,然后使用匈牙利算法进行轨迹和检测之间的关联,其代价矩阵考虑了几何(IoU)和外观(平均相关峰能量- APCE[63])线索。APCE还用于目标再识别(ReID)步骤,以从遮挡中恢复。作者表明,通过多尺度增强训练一个检测器可以带来更好的跟踪性能,该算法达到了与KITTI和MOT15上最先进的在线算法相当的精度。
3.1.3、Other detectors
在MOT中用作检测器的其他CNN模型中,我们可以提到YOLO系列检测器[64,6,65];特别是,Kim等人[66]也使用YOLOv2来检测行人。Sharma等人[67]使用循环滚动卷积(RRC) CNN[68]和SubCNN[69]在自动驾驶环境中检测运动摄像机记录的视频中的车辆(见第3.2.4节)。Pernici等人[70]在他们的人脸跟踪算法中使用了Tiny CNN检测器[71],与未使用深度学习技术的可变形部件模型检测器(DPM)[25]相比,获得了更好的性能。
3.1.4、cnn在检测步骤中的其他用途
有时cnn被用于MOT检测步骤,而不是直接计算对象边界框。
例如,cnn已被用于减少误报[72],其中车辆检测是通过修改版本的ViBe算法[73]获得的,该算法对输入执行背景减法。这些检测首先作为输入输入支持向量机[74],如果支持向量机没有足够的信心丢弃或确认它们,那么基于fast - cnn的网络[75]将被用于决定是否保留或丢弃它们。这样,CNN只需要分析少量的物体,使检测步骤更快。
Bullinger等人在[76]中探索了一种不同的方法,在检测步骤中,不是计算经典的边界框,而是采用多任务网络级联[77]来获得实例感知的语义分割图。作者认为,由于实例的2D形状不同于矩形边界框,不包含背景结构或其他对象的部分,因此基于光流的跟踪算法将表现得更好,特别是当图像中的目标位置除了对象自身的运动之外还受摄像机运动的影响时。在获得当前帧中存在的各种实例的分割图之后,应用光流方法([78,79,80])来预测下一帧中每个实例的位置和形状。然后计算预测实例和检测实例之间的相似度矩阵,并将其作为匈牙利算法的输入进行关联。虽然与SORT方法相比,该方法在整个MOT15数据集上获得的MOTA分数略低,但作者表明,它在具有移动摄像机的视频上的表现更好。
3.2、深度学习在特征提取和运动预测中的应用
特征提取阶段是深度学习模型使用的首选阶段,因为其强大的表示能力使其擅长提取有意义的高层特征。这方面最典型的方法是使用cnn提取视觉特征,如3.2.2节所述。与使用经典的CNN模型不同,另一个递归的想法是将它们训练为孪生CNN,使用对比损失函数,以便找到一组最能区分主题的特征。这些方法将在3.2.3节解释。此外,一些作者探索了cnn在基于相关滤波器的算法中预测物体运动的能力:这些在3.2.5节中注释。最后,使用其他类型的深度学习模型,通常将其包含在更复杂的系统中,将深度特征与经典特征相结合。它们将在3.2.4节(特别是视觉特性)和3.2.6节(不属于其他类别的方法)中进行解释。
3.2.1、自动编码器:深度学习首次在MOT管道中使用
据我们所知,Wang等人[81]在2014年提出了在MOT中使用深度学习的第一种方法。他们提出了一个堆叠在两层的自动编码器网络,用于细化从自然场景中提取的视觉特征[82]。在提取步骤之后,使用SVM进行亲和度计算,并将关联任务建模为最小生成树问题。他们表明,特征细化大大提高了模型的性能。然而,该算法所使用的数据集并不常用,其测试结果难以与其他方法进行比较。
3.2.2、cnn作为视觉特征提取器
最广泛使用的特征提取方法是基于对卷积神经网络的细微修改。这些模型的第一次使用可以在[83]中找到。在这里,Kim等人使用预训练的CNN从检测中提取4096个视觉特征,然后使用PCA将这些特征减少到256个,将视觉特征纳入到称为多假设跟踪的经典算法中。这一修改将MOTA在MOT15上的分数提高了3分以上。当论文提交时,它是该数据集上排名最高的算法。Yu等人。[38]使用了GoogLeNet[2]的修改版本,在自定义重识别数据集上进行了预训练,该数据集是通过结合经典行人识别数据集(PRW [84], Market-1501 [85], VIPeR [86], CUHK03[87])构建的。将视觉特征与空间特征相结合,利用卡尔曼滤波提取特征,计算相似度矩阵。
使用CNN进行特征提取的其他例子可以在[88]中找到,其中使用自定义CNN在多假设跟踪框架中提取外观特征,在[89]中,其跟踪器采用预训练的基于区域的CNN[90],或在[91]中,CNN从鱼头中提取视觉特征,后来与卡尔曼滤波器的运动预测相结合。
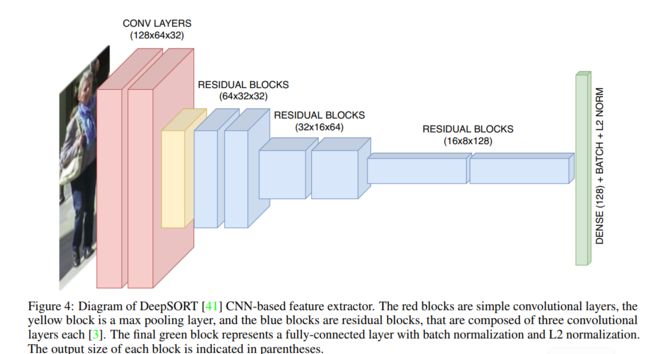
3.1.1节介绍的排序算法[35]后来使用深度特征对其进行了改进,这个新版本被称为DeepSORT[41]。该模型融合了由自定义残差CNN提取的视觉信息[92]。CNN提供了一个具有128个特征的归一化向量作为输出,这些向量之间的余弦距离被添加到用于排序的亲和度分数中。网络结构如图4所示。实验结果表明,该方法克服了排序算法的主要缺点,即需要大量的ID开关。
Mahmoudi et al.[42]也将CNN提取的视觉特征与动态和位置特征结合起来,然后通过匈牙利算法解决关联问题。在[93]中,使用在ImageNet上预训练的ResNet-50[3]作为视觉特征提取器。关于如何使用CNN来区分行人的详细解释可以在[94]中找到。在他们的模型中,Bae等人将CNN的输出与形状和运动模型结合起来,并计算出每对检测的聚合匹配得分;然后用匈牙利算法解决关联问题。Ullah等人[95]再次应用现成版本的GoogLeNet[2]进行特征提取。Fang等人[96]选择了一个Inception CNN[97]的隐藏卷积层的输出作为视觉特征。Fu等人[98]使用DeepSORT特征提取器,并使用判别相关滤波器测量特征的相关性。然后将匹配得分与时空关系得分相结合,并将最终得分作为高斯混合概率假设密度滤波器的似然值[99]。作者[100]在ILSVRC CLS-LOC[101]数据集上使用了一个经过微调的GoogLeNet来识别行人。在[70]中,作者重用了基于cnn的检测器提取的视觉特征,并使用反向最近邻技术进行关联[102]。Sheng等人[103]使用GoogLeNet的卷积部分来提取外观特征,使用它们之间的余弦距离来计算检测对之间的匹配分数,并将该信息与运动预测合并,以计算整体匹配度,作为图问题中的边缘成本。Chen等人[104]利用ResNet的卷积部分构建自定义模型,在卷积之上叠加LSTM单元,以便同时计算相似度评分和边界框回归。
在[53]中,该模型学习了区分快速移动的细胞和缓慢移动的细胞。分类计算完成后,慢速细胞几乎静止,仅使用运动特征进行关联,而快速细胞则使用基于VGG-16[1]的fast R-CNN提取的运动特征和视觉特征进行关联,特别针对细胞分类任务进行了微调。此外,所提出的模型包括跟踪优化步骤,通过合并错误中断的可能轨迹块来减少假阴性和假阳性。
Ran等人[52]提出了一种将经典CNN用于视觉特征提取和AlphaPose CNN用于姿态估计的组合。然后将这两个网络的输出与轨迹信息历史一起输入到LSTM模型中以计算相似度,如3.3.1节所述。
在[51]中可以发现一个有趣的使用cnn进行特征提取的方法。作者使用了一个名为DeepCut[105]的姿态检测器,它是Fast R-CNN的改进;它的输出由预测14个身体部位存在的得分图组成。这些图像与检测到的行人的裁剪图像相结合,并输入到CNN中。该算法的更详细解释见3.3.6节。
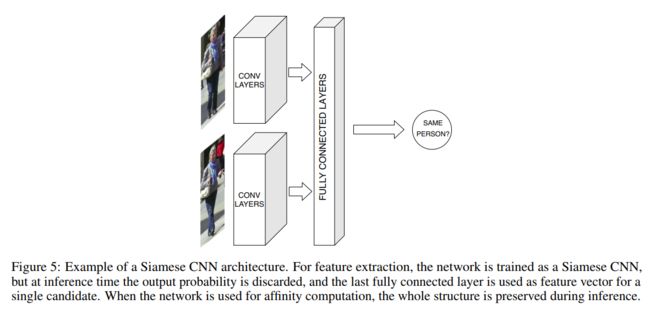
3.2.3、孪生网络
另一个递归的想法是使用结合不同图像信息的损失函数训练cnn,以便学习一组最能区分不同对象示例的特征。这些网络通常称为孪生网络(该架构的一个示例如图5所示)。Kim等人[106]提出了一种孪生网络[107],该网络使用对比损失进行训练。该网络将两张图像、它们的IoU分数和它们的面积比作为输入,并产生一个对比度损失作为输出。网络训练完成后,去掉计算对比度损失的层,将最后一层作为输入图像的特征向量。结合特征向量之间的欧氏距离、IoU得分和边界框之间的面积比计算相似度得分。关联步骤采用自定义贪心算法求解。Wang等人[108]也提出了一种孪生网络,该网络取两个图像块并计算它们之间的相似性得分。通过比较网络为两幅图像提取的视觉特征,包括时间约束信息,计算测试时的得分。作为相似度评分的距离是一个带权重矩阵的马氏距离,也是由模型学习得到的。
Zhang等[109]提出了一种称为SymTriplet loss的损失函数。根据他们的解释,在训练阶段使用了三个共享权重的cnn,损失函数结合了从属于同一目标的两幅图像(正对)和来自不同目标的图像(两幅负对)中提取的信息。正对特征向量之间的距离越小,共三元组损失越小;负对特征向量之间的距离越近,共三元组损失越大。对该函数的优化导致相同对象的图像的特征向量非常相似,同时为不同对象产生不同的向量,它们之间的距离更大。对跟踪算法进行测试的数据集由电视剧的章节和YouTube的音乐视频组成。由于视频包含不同的镜头,将问题分为两个阶段。首先,对同一镜头中的帧进行数据关联;在这种情况下,亲和性得分是检测到的特征向量的欧氏距离、时间和运动学信息的组合。然后,使用分层凝聚聚类算法对外观特征进行工作,在镜头之间连接轨迹片。
Leal-Taixé等人[110]提出了一种孪生CNN,它接收两个堆叠的图像作为输入,并输出两个图像属于同一个人的概率。他们用这个输出训练网络,以便它学习到最具代表性的特征来区分受试者。然后,去除输出层,将最后一层隐藏层提取的特征与上下文信息一起作为梯度提升模型的输入,以获得检测目标之间的亲和度得分;然后,利用线性规划求解关联步骤[111]。
Son等人[112]提出了一种新的CNN架构,称为Quad-CNN。该模型接收了4个图像块作为输入,其中前3个图像块来自同一个人,但按时间顺序递增,最后一个图像块来自另一个人。该网络使用自定义损失函数进行训练,结合了检测之间的时间距离信息、提取的视觉特征和边界框位置。在测试阶段,网络进行两次检测,并使用学习到的嵌入预测两次检测属于同一个人的概率。
在[55]中构建基于Mask R-CNN的孪生网络[17];在Mask R-CNN生成每个检测的掩码后,将三个示例输入浅层孪生网络,两个来自同一对象(正对),一个来自另一个对象(负对),再次使用三元组损失进行训练。在训练阶段结束后,去掉输出层,从最后一个隐含层中提取一个128维的向量。然后利用余弦距离计算图像的外观相似度;这种相似性进一步与运动一致性相结合,运动一致性是基于对象的预测位置的分数,假设是线性运动,并具有空间潜力,这是一个更复杂的运动模型。然后,通过在计算出的相似度的三维张量上进行幂迭代来解决关联问题。
Maksai等人[113]直接使用[114]中提出的ReID三元组CNN提取的128-d特征向量,并将其与其他基于外观的特征相结合(作为该算法的无外观版本的替代)。利用双向LSTM对这些特征进行进一步处理。在[115]中,采用了类似的方法,即所谓的空间注意力网络(SAN)。SAN是一个孪生CNN,它使用预训练的ResNet-50作为基础模型。该网络被截断,以便只使用卷积层。然后,从模型的最后一层卷积层中提取空间注意力图:它表示包围盒中不同部分重要性的度量,以便从提取的特征中排除背景和其他目标。这些特征实际上是由这个地图加权的,起到了掩码的作用。然后将来自两个检测的被屏蔽特征合并到一个全连接层中,计算它们之间的相似性。在训练过程中,网络也被设置为输出一个分类分数,因为作者观察到联合优化分类和亲和度计算任务可以在后者中获得更好的性能。如前面的例子所示,亲和性信息被进一步输入到双向LSTM中。这两个问题将在3.3节进一步讨论。Ma等[116]还训练了一个Siamese CNN,以便在他们的模型中从被跟踪的行人中提取视觉特征,详情见3.4.1节。
在[117]中,Zhou等人提出了一种视觉位移CNN,它学习根据物体之前的位置以及物体对场景中其他物体的影响来预测物体的下一个位置。然后使用该CNN预测下一帧中物体的位置,将其过去的轨迹作为输入。该网络还能够从预测位置和实际检测中提取视觉信息,以便计算相似性得分,如3.3.6节所述。
Chen等[118]提出了一种两步算法,该算法使用三元组损失训练的GoogLeNet进行特征提取。在第一步中,模型使用R-FCN利用现有轨迹的信息来预测可能的检测候选。然后,将这些检测结果与实际检测结果相结合并执行NMS;然后,他们使用自定义训练的GoogLeNet模型从检测中提取视觉特征,并使用分层关联算法解决关联问题。当他们的论文发表时,该算法在MOT16数据集的在线方法中排名第一。
Lee等人[119]最近探索了一种有趣的方法,将金字塔和孪生网络结合在一起。他们的模型称为特征金字塔孪生网络,采用了一个骨干网络(他们使用SqueezeNet[120]和GoogLeNet[2]研究性能,但骨干网络是可以改变的),该网络使用相同的参数从两个不同的图像中提取视觉特征。然后,提取网络中的部分隐藏特征图并将其输入到特征金字塔孪生网络中;然后,网络采用上采样和合并策略为金字塔的每个阶段创建特征向量。将较深的特征层与较浅的特征层合并,以丰富较简单的特征与较复杂的特征。之后,进行亲和度分数计算,如3.3.7节所述。
3.2.4、更复杂的视觉特征提取方法
也有人提出了更复杂的方法。Lu等人[59]将SSD在检测阶段预测的类别作为特征,并与RoI池化提取的图像描述子相结合进行每次检测。然后,将提取到的特征作为LSTM网络的输入,该网络学习计算关联特征以进行检测。这些特征稍后用于亲和性计算,使用它们之间的余弦距离。

在[121]中,使用GoogLeNet的较浅层来学习被跟踪对象的特征字典。为了学习字典,该算法在视频的前100帧中随机选择对象。该模型提取了网络前7层的特征图。然后利用正交匹配追踪(OPM)[122]对从对象中提取的特征进行降维,并将学习到的表示作为字典;在测试阶段,计算场景中每个检测到的目标的OPM表示,并与字典进行比较,结合卡尔曼滤波器提取的视觉和运动信息构建代价矩阵。最后,利用匈牙利算法进行关联。
lstm有时用于运动预测,以便从数据中学习更复杂的非线性运动模型。图6显示了典型的使用LSTMs进行运动预测的方案。Sadeghian等人[123]展示了使用递归网络的一个例子,他提出了一个模型,该模型使用三个不同的rnn来计算每种检测的各种类型的特征,而不仅仅是运动特征。使用第一个循环神经网络提取外观特征;该RNN的输入是由VGG CNN[1]提取的视觉特征向量,该特征向量是专门为行人再识别进行预训练的。第二个RNN是一个训练的LSTM,用于预测每个被跟踪对象的运动模型。在这种情况下,LSTM的输出是每个对象的速度向量。由于某些物体的位置会受到周围物体行为的影响,训练最后一个RNN来学习场景中不同物体之间的相互作用。然后,另一个LSTM将其他rnn的信息作为输入,进行亲和度计算。
文献[124]提出了一种堆叠式cnn模型。模型的第一部分由预训练的共享CNN组成,该CNN提取场景中每个目标的公共特征;CNN没有在线更新。然后,对每个候选区域进行RoI池化,提取RoI特征;然后,为每个被跟踪的候选人实例化一个新的特定CNN并在线训练。这些cnn同时为其候选对象提取了可见性图和空间注意力图。最后,提取精细特征后,计算每幅新图像属于每个已跟踪目标的概率,并使用贪心算法进行关联。
Sharma等人[67]设计了一组成本函数来计算车辆检测之间的相似性。这些成本结合了由CNN提取的外观特征,以及假设有移动摄像机的环境中的3D形状和位置特征。定义的成本是3D-2D成本,是将前一帧上的边界框估计的3D投影与新一帧上的2D边界框的3D投影进行比较,3D-3D成本,是前一边界框的3D投影与当前边界框的3D投影重叠,外观成本,是提取的视觉特征的欧氏距离计算,形状和姿态成本。计算并比较物体在边界框中的粗略形状和位置。请注意,虽然推断出了3D投影,但输入仍然是2D图像。每次代价计算完成后,后续两帧检测结果之间的成对代价是前两帧代价的线性组合。利用匈牙利算法求解最终的关联问题。
Kim等[66]利用YOLOv2 CNN目标检测器提取的信息构建Random Ferns(随机蕨)分类器[125]。该算法分两步运行。第一步,训练所谓的teacher-RF,以区分行人和非行人。在对teacher-RF进行训练后,为每一个被跟踪目标构建一个Random Ferns(随机蕨)分类器。这些分类器称为student-RF,它们比teacher-RF更小。他们擅长将被跟踪的物体与场景中的其他物体区分开来。为每个目标建立一个小的Random Ferns(随机蕨)分类器,以降低整个模型的计算复杂度,使其能够实时工作。
在[126]中,通过使用隐马尔可夫模型首先估计后续帧中物体的位置,减少了模型必须计算的亲和力计算数量[127]。然后,使用预训练的CNN进行特征提取;提取视觉特征后,仅在可行对之间进行亲和度计算,即在与HMM预测足够接近的检测之间进行计算,将其视为同一个目标。利用视觉特征之间的互信息函数获得亲和力得分;在计算亲和度得分时,使用动态规划算法进行检测关联。
3.2.5、用于运动预测的cnn:相关滤波器
Wang等[128]研究了相关滤波器[129]的使用,其输出是被跟踪目标的响应图。该地图是下一帧中目标新位置的估计。这种匹配度进一步与光流匹配度相结合,光流匹配度使用Lucas-Kanade算法计算[130],运动匹配度使用卡尔曼滤波器计算,尺度匹配度由边界框的高度和宽度的比率表示。两个检测之间的亲和度计算为先前分数的线性组合。还有一个步骤是使用SVM分类器去除误检,并处理漏检,使用前面步骤中计算的响应图处理该任务。如果一个物体错误地丢失了,然后重新识别,该步骤可以修复错误并重新连接损坏的轨迹。
在[61]中,还使用相关滤波器来预测目标在后续帧中的位置。滤波器接收CNN提取的外观特征作为输入,之前使用PCA进行了减少,并产生下一帧中目标预测位置的响应图作为输出。预测位置稍后用于计算相似性得分,结合预测和检测之间的IoU以及响应图的APCE得分。在构造代价矩阵后,计算帧间每对检测的得分,利用匈牙利算法解决分配问题。
3.2.6、其他方法
Rosello等人[131]探索了一种完全不同的方法,使用强化学习框架来训练一组智能体,帮助特征提取步骤。该算法仅基于运动特征,不使用任何视觉信息。运动模型使用卡尔曼滤波器学习,其行为由一个智能体管理,每个被跟踪对象使用一个智能体。智能体学会了决定卡尔曼滤波器应该采取哪种行动,在一组行动之间,包括忽略预测,忽略新测度,使用两种信息片段,启动或停止跟踪。作者声称,他们的算法即使在非视觉场景中也可以解决跟踪任务,而经典算法的性能深受视觉特征的影响。然而,由于模型是在训练集上进行测试的,因此在MOT15上的实验结果不可靠,无法与其他模型进行比较。
3.3、匹配计算中的深度学习
虽然许多工作通过对CNN提取的特征使用某种距离度量来计算轨迹块和检测(或轨迹块和其他轨迹块)之间的匹配度,但也有算法使用深度学习模型直接输出匹配度分数,而不必指定特征之间的显式距离度量。本节将重点介绍这些工作。
特别是,我们首先将描述使用递归神经网络的算法,从标准LSTMs(第3.3.1节)开始,然后描述孪生LSTMs(第3.3.2节)和双向LSTMs(第3.3.3节)的使用。在多假设跟踪(MHT)框架的背景下,对lstm计算的匹配度的特殊使用见第3.3.4节;最后,在3.3.5节中介绍了一些使用不同类型的循环网络进行亲和度计算的工作。
在本节的第二部分,我们将探索在匹配度计算中使用cnn(3.3.6节),包括直接使用孪生cnn的输出作为匹配度分数的算法(3.3.7节),而不是像3.2.3节那样依赖特征向量的距离度量。
3.3.1、循环神经网络和lstm
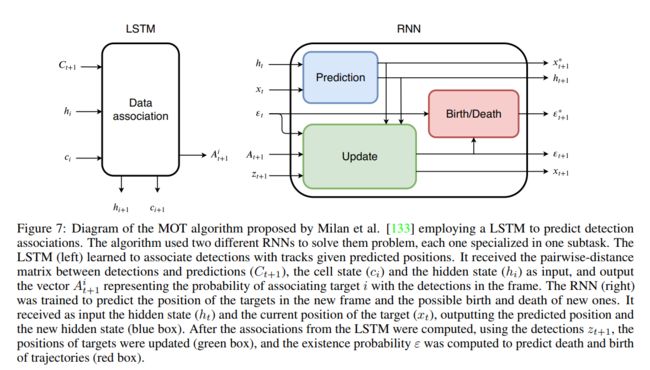
最早使用深度网络直接计算匹配度的工作之一是[133],Milan等人提出了一种用于在线MOT的端到端学习方法,总结在图7中。采用基于循环神经网络(RNN)的模型作为主要跟踪器,模拟贝叶斯滤波算法,由三个块组成:第一个是运动预测块,该块学习一个运动模型,该运动模型将过去帧中目标的状态(即旧的边界框位置和大小)作为输入,并预测下一帧的目标状态,而不考虑检测;第二个块使用新帧中的检测和包含将目标与所有此类检测关联的概率的关联向量来细化状态预测(很明显,这可以被视为亲和力分数);第三个区块管理航迹的产生和消失,因为它使用之前收集的信息来预测新帧中航迹存在的概率14。使用基于LSTM的网络计算关联向量,该网络使用目标的预测状态和新帧中检测到的状态之间的欧氏距离作为输入特征(除了隐藏状态和单元状态,作为任何标准LSTM)。使用100K个20帧长的合成序列对网络进行单独训练。虽然该算法的表现优于其他技术,如卡尔曼滤波器与匈牙利算法的结合,但在MOT15测试集上的结果并没有达到最高精度;然而,该算法能够比其他算法运行得快得多(~ 165 FPS),并且没有使用任何类型的外观特征,为未来的改进留下了空间
在后来使用LSTM的其他工作中[123],使用具有全连接(FC)层的LSTM来融合由其他3个LSTM提取的特征(如第3.2.4节中已经解释的),并输出匹配度得分。整个算法类似于[134]中提出的基于马尔可夫决策过程(MDP)的框架:使用单个目标跟踪器(SOT)独立跟踪目标;当目标发生遮挡时,停止SOT,并将LSTM计算的匹配度作为边代价构建二分图,然后借助匈牙利算法求解关联问题。作者表明,使用所有3个特征提取器和LSTM的组合,而不是简单的FC层,可以在MOT15验证集上持续获得更好的性能。截至本文发表时,该算法在MOT15和MOT16测试集上也取得了最先进的MOTA分数,证实了该方法的有效性。
另一种使用多个lstm的方法是[52],Ran等人提出了一种基于姿态的三流网络,它结合3个lstm输出的3个其他匹配度计算匹配度:一个用于外观相似性,使用AlphaPose[135]提取的CNN特征和姿态信息;一个用于运动相似性,使用姿态关节速度;一个用于交互相似性,使用交互网格。然后使用自定义跟踪算法将检测关联起来。在其专有的排球数据集上与其他最先进的MOT算法进行了比较,取得了良好的效果。
3.3.2、孪生LSTMs
Liang等人[136]也使用多个lstm对各种特征进行建模,但他们以不同的方式进行。由于用cnn提取外观特征的计算成本很高,他们进行了所谓的预关联步骤,该步骤使用SVM来预测轨迹块和检测之间的关联概率。SVM将位置和速度相似性得分作为输入,使用两个LSTMs进行位置和速度预测。预关联步骤包括丢弃具有低SVM匹配度分数的检测。在这一步之后,通过将VGG-16特征作为孪生LSTM的输入来执行实际的关联步骤,该特征预测轨迹波和检测之间的匹配度分数。以贪心的方式进行关联,将得分最高的检测与轨迹相关联。在MOT17数据集上进行测试,结果与表现最好的算法一致。
Wan等[43]在他们的算法中也使用了Siamese LSTM,该算法也由两个步骤组成。首先,利用匈牙利算法构建可靠的短轨迹子带,并利用Kalman滤波或Lucas-Kanade光流法计算目标检测结果与预测目标位置之间的IoU作为匹配度量;第二步也使用了匈牙利算法来加入轨迹小块,但这一次匹配度是使用孪生LSTM框架计算的,该框架将运动特征连接到CNN提取的外观特征(如[137]),在CUHK03 Re-ID数据集上进行了预训练。
3.3.3、双向LSTMs
Zhu等人[115]提出了lstm在匹配度计算阶段的另一种用法。他们使用所谓的时间注意力网络(TAN)来计算注意力系数,以对空间注意力网络(SAN)提取的特征进行加权(参见第3.2.3节),以降低噪声观测的重要性。为此,采用双向LSTM。当改进的高效卷积算子跟踪器(ECO)[56]基于困难样本挖掘训练,检测到目标失败时,整个网络(称为双匹配注意力网络)用于从遮挡中恢复。该算法在MOT16和MOT17数据集上的实验结果(MOTA、IDF1、ID开关数)与当前最先进的在线方法相当。
Yoon等人[138]还使用双向LSTM来计算匹配度,在一些编码非外观特征(仅边界框坐标和检测置信度)的FC层上。使用匈牙利算法进行关联求解。他们在斯坦福无人机数据集(SDD)[139]上训练网络,并在SDD和MOT15上进行评估。他们与不使用视觉线索的顶级算法取得了相当的结果,但性能仍然比基于外观的方法差。
3.3.4 lstm在MHT框架中的使用
在多假设跟踪方法中,首先为每个候选目标建立潜在航迹假设树;然后计算每个航迹的似然度,并选择具有最高似然度的航迹组合作为解。各种深度学习算法也被用于增强基于MHT的方法。
Kim等人[93]提出使用所谓的双线性LSTM网络作为MHT-DAM[83]算法的门级步骤,即使用LSTM计算的匹配度分数来决定是否修剪假设树的某个分支。LSTM单元有一个修改的前向传递(受[83]中提出的在线递归最小二乘估计器的启发),并将用ResNet-50 CNN提取的过去帧轨迹波的外观特征作为输入。LSTM单元的输出是一个表示轨迹波历史外观的特征矩阵,然后将该矩阵乘以需要与轨迹波进行比较的检测的外观特征向量。在其之上的FC层最终计算轨迹波和检测之间的匹配度分数。作者声称,这种改进的LSTM比经典的LSTM能够存储更长期的外观模型。他们还建议添加一个运动建模经典的LSTM来计算历史运动特征(使用归一化的边界框坐标和大小),然后将其连接到外观特征,然后继续进行FC层和最终的softmax输出匹配度分数。两个lstm首先分别训练,然后联合微调。训练数据也被增强,包括定位误差和缺失检测,以更接近真实世界的数据。他们使用MOT15, MOT17, ETH, KITTI和其他小数据集进行训练,并在MOT16和MOT17上对模型进行评估。他们表明,他们的模型对检测质量很敏感,因为他们在使用公开的Faster R-CNN和SDP检测时提高了MHT-DAM的MOTA性能,而在公开的DPM检测上的表现比它差。无论如何,无论使用什么检测,他们似乎都获得了更高的IDF1分数,他们的总体结果也反映了这一点,因为他们在使用基于mht的算法的所有方法中获得了最高的IDF1。然而,在MOTA和IDF1中测量的跟踪质量仍然低于其他最先进的算法。
Maksai等人最近提出了一种类似的使用RNN的方法[113],他们还使用LSTM来计算MHT算法的一种变体中的轨迹小波分数,该算法迭代地增长和修剪轨迹小波,然后尝试选择一组能够最大化该分数的轨迹小波他们工作的目标是解决多目标跟踪中训练循环网络的两个常见问题:损失评估不匹配,当通过优化与推理时使用的评估指标不一致的损失来训练网络时,会出现损失评估不匹配(例如,分类分数与MOTA);曝光偏差,当模型在训练过程中没有暴露于自身的误差时就存在。为了解决第一个问题,他们引入了一种新颖的方法来对tracklets进行评分(使用RNN),这是IDF1指标的直接代理,并且不使用真实值;然后可以训练网络以优化这种度量。解决第二个问题的方法是将使用当前版本的网络计算的轨迹块添加到网络的训练集,并在训练过程中进行困难的示例挖掘和随机轨迹块合并;这样,训练集分布应该更类似于推理时的输入数据分布。使用的网络是双向LSTM,在嵌入层之上,将各种特征作为输入。作者提出了一种只使用几何特征的算法版本,以及一种使用基于外观的特征的算法版本,其性能更好。进行了大量的消融研究,并测试了各种替代方法。最终的算法在考虑IDF1指标时,在各种MOT数据集(MOT15, MOT17, DukeMTMC[21])上都取得了最好的性能,尽管它在MOTA上并不出色。
在使用rnn的MHT家族的其他方法中,我们还可以找到[104],Chen等人在他们的批量多假设跟踪策略中使用所谓的递归度量网络(RMNet)来计算轨迹假设和检测之间的外观匹配度(以及基于运动的匹配度)。RMNet是一种LSTM,它将所考虑的检测序列的外观特征作为输入,用ResNet CNN提取,并输出相似度分数和包围盒回归参数。采用门控和形成假设的双阈值方法,并采用重新发现奖励来鼓励从遮挡中恢复。通过将问题转换为二元线性规划问题来选择假设,并使用lpsolve进行求解。最后利用卡尔曼滤波对轨迹进行平滑处理。在MOT15, PETS2009 [34], TUD[140]和KITTI上进行了评估,在IDF1指标上取得了比MOTA更好的结果,该指标给予行人再识别更多的权重。
3.3.5 其他递归网络
Fang等人[96]在他们的循环自回归网络(RAN)框架中使用门控循环单元(gru)[141]来进行行人跟踪。gru用于估计每个被跟踪目标的自回归模型参数,其中一个用于运动,另一个用于外观,根据轨迹块过去的运动/外观特征计算观察到给定检测运动/外观的概率。这两种概率(可以很容易地视为一种匹配度度量)然后相乘以获得最终的关联概率,用于解决[134]中的跟踪块和检测之间关联的二分匹配问题。RAN训练步骤被建模为一个最大似然估计问题。
Kieritz等人[60]使用两个隐藏层的循环多层感知器(MLP)来计算检测和轨迹波之间的外观匹配度分数。然后将这种匹配度连同跟踪和检测置信度分数作为另一个MLP的输入,以预测总的匹配度分数(称为关联度量)。匈牙利算法最终使用这个分数来进行关联。该方法在UA-DETRAC数据集[32]上取得了最好的性能,但在MOT16上与其他使用隐私检测的算法相比,性能不是很好。
3.3.6、用于匹配度计算的cnn
其他算法使用cnn来计算某种相似性得分。Tang等人[51]测试了使用4种不同的cnn来计算图中节点之间的匹配度分数,关联任务被定义为最小成本提升的多分支问题[142]:它可以被视为图聚类问题,其中每个输出聚类表示单个被跟踪对象。与边缘相关的成本解释了两次检测之间的相似性。这种相似性是行人重识别置信度、深度对应匹配和时空关系的结合。为了计算行人重识别匹配度,测试了各种架构(在从MOT15, MOT16, CUHK03, Market-1501数据集提取2511个身份后进行训练),但表现最好的是新的StackNetPose。它融合了DeepCut人体部位检测器[105]提取的人体部位信息(见第3.2.2节)。两个图像的身体部位的14个得分图与两个图像本身堆叠在一起,以产生20个通道的输入。该网络遵循VGG-16架构,并输出两个输入身份之间的匹配度分数。与孪生cnn不同的是,这对图像能够在网络的早期阶段"交流"。作者表明,StackNetPose网络在行人再识别任务中表现更好,因此他们使用它来计算ReID匹配度。通过将一个权重向量(通过逻辑回归学习,并依赖于两次检测之间的时间间隔)与一个包含ReID匹配度、基于深度匹配的匹配度[143]、一个时空匹配度得分、两个检测置信度的最小值以及与上述项的所有成对组合的二次项相乘来计算组合匹配度得分。作者表明,将所有这些特征结合起来产生了更好的结果,再加上将问题框架化为最小成本提升的多切问题(使用[144]中提出的算法启发式解决)的改进,他们在发表论文时成功地在MOT16数据集上达到了最先进的性能(以MOTA分数衡量)。
另一种使用cnn的方法在[145]中提出,Chen等人使用粒子滤波器[146]来预测目标运动,使用改进的更快的R-CNN网络来加权每个粒子的重要性。该模型通过训练来预测包围盒中包含一个物体的概率,但它也通过一个目标特定分支来增强,该分支从CNN的下层提取输入特征,并将其与目标历史特征合并,以预测两个物体相同的概率。与之前的方法不同的是,这里计算的是采样粒子与跟踪目标之间的匹配度,而不是目标与检测之间的匹配度。与被跟踪对象不重叠的检测被用来初始化新的跟踪或检索丢失的对象。尽管它是一种在线跟踪算法,但在发布时,无论是使用公共检测还是使用私人检测(从[147]中获得),它都能够在MOT15上达到最佳性能。
Zhou等人[117]使用了视觉相似性CNN,类似于第3.2.3节中介绍的基于ResNet-101的视觉位移CNN,该CNN输出检测与深度连续条件随机场预测的tracklet盒之间的匹配度得分。利用IoU将视觉匹配度得分与空间相似性得分合并,然后将得分最高的检测与每个轨迹关联;在冲突的情况下,采用匈牙利算法。在MOTA评分方面,该方法在MOT15和MOT16上达到了与最先进的在线MOT算法相媲美的结果。
3.3.7、孪生cnn
孪生cnn也是匹配度计算中常用的方法。图5显示了Siamese CNN的一个示例。这里提出的方法决定直接使用孪生CNN的输出作为匹配度,而不是像3.2.3节中介绍的算法那样,使用从网络的倒数第二层提取的特征向量之间的经典距离。例如,Ma等人[148]在一个两步算法中使用一个来计算轨迹块之间的匹配度。他们选择应用层次相关性聚类,解决两个连续的提升多切线问题:局部数据关联和全局数据关联。在本地数据关联步骤中,通过使用[149]提出的鲁棒相似性度量将时间上紧密的检测连接在一起,该度量使用深度匹配和检测置信度来计算检测之间的匹配度得分。在这一步中,仅将相近检测点之间的边插入到图中。多ut问题用文献[144]提出的启发式算法来解决。在全局数据关联步骤中,将被长期遮挡分割的局部轨迹连接在一起,构建包含所有轨迹片的全连接图。Siamese CNN用于计算匹配度,这些匹配度将作为图中的边成本。该架构基于GoogLeNet[2],并在ImageNet上进行预训练。然后,网络在Market-1501 ReID数据集上进行训练,然后在MOT15和MOT16训练序列上进行微调。除了输出两幅图像之间的相似度分数的验证层外,仅在训练期间向网络中添加两个分类层,以对每幅训练图像的身份进行分类;这被证明可以提高计算匹配度分数的网络性能。这个所谓的"通用" ReID网络还以无监督的方式对每个测试序列进行了微调,而没有使用任何地面真实值信息,以使网络适应每个特定序列的光照条件、分辨率、相机角度等。这是通过观察本地数据关联步骤中构建的轨迹来采样阳性和阴性检测对来实现的。在MOT16上获得的结果证明了该算法的有效性,在撰写论文时,MOTA得分为49.3,是表现最好的方法。
如3.2.3节所述,Lee等人[119]使用特征金字塔孪生网络来提取外观特征。将这种网络应用于MOT问题时,将一个运动特征向量连接到外观特征,并在其上添加3个全连接层来预测轨迹和检测之间的匹配度分数;网络是端到端的训练。然后迭代地关联检测,从匹配度分数最高的对开始,当分数低于阈值时停止。该方法在MOT17数据集上取得了在线算法中最好的性能结果。
3.4、DL在关联/跟踪步骤
一些工作,尽管没有其他步骤那么多,已经使用深度学习模型来改进由经典算法执行的关联过程,如匈牙利算法,或管理轨迹状态(例如,决定开始或结束一个轨迹)。我们将在本节中介绍它们,包括rnn(第3.4.1节)、深度多层感知器(第3.4.2节)和深度强化学习智能体(第3.4.3节)的使用。
3.4.1、循环神经网络
Milan等人在[133]中提出的使用深度学习管理航迹状态的算法的第一个例子(已在第3.3.1节中描述),该算法使用RNN预测每帧中存在航迹的概率,从而帮助决定何时启动或终止航迹。
Ma等人[116]使用双向GRU RNN来决定在哪里分割轨迹。该算法主要分为3个阶段:首先是轨迹生成阶段,包括去除冗余检测的NMS阶段,然后结合具有外观和运动匹配的匈牙利算法生成置信度高的轨迹;然后,对轨迹子块进行分割:由于轨迹子块可能因遮挡而发生ID切换错误,该步骤旨在在ID切换发生的位置对轨迹子块进行分割,以获得两个包含相同ID的轨迹子块;最后,利用孪生双向门控循环单元提取的特征,采用自定义关联算法进行轨迹重连。然后用多项式曲线拟合填充新形成的轨迹片内的缝隙;切割步骤由双向GRU RNN执行,该RNN使用宽残差网络CNN提取的特征[92]。GRU为每一帧输出一对特征向量(GRU的每个方向一个);然后计算特征向量对之间的距离,得到一个距离向量;如果分数高于阈值,则该向量中的最大值表示在何处分割轨迹波。重连GRU类似,但它在GRU之上有一个额外的FC层和一个时间池化层,以提取代表整个轨迹的特征向量;然后,根据两个轨迹子块特征之间的距离来决定重新连接哪些轨迹子块。该算法在MOT16数据集上取得了与最新技术相当的结果。
3.4.2、深度多层感知器
尽管不是一种非常常见的方法,但深度多层感知器(MLP)也被用于指导跟踪过程。例如,Kieritz等人[60]使用具有两个隐藏层的MLP来计算轨迹置信度分数,将上一步的轨迹分数和最后一次关联检测的各种信息(如关联分数和检测置信度)作为输入。然后使用置信度分数来管理轨迹的终止:他们实际上决定随着时间的推移保持固定数量的目标,用置信度分数最低的旧轨迹替换为新轨迹。算法的其余部分将在3.3.5节解释。
3.4.3、深度强化学习智能体
一些工作使用深度强化学习(RL)智能体在跟踪过程中进行决策。Rosello等人[131],如第3.2.6节所述,使用多个深度强化学习智能体来管理各种被跟踪的目标,决定何时启动和停止跟踪,并影响卡尔曼滤波器的运行。agent使用具有3个隐藏层的MLP进行建模。
Ren等人[150]也在协作环境中使用多个深度强化学习智能体来管理关联任务。该算法主要由预测网络和决策网络两部分组成。预测网络是一个CNN,它被学习来预测目标在新帧中观察目标和新图像的运动,也使用最近的轨迹轨迹。相反,决策网络是由多个智能体(每个智能体对应一个被跟踪的目标)和环境组成的协作系统。每个智能体根据自己、邻居和环境的信息做出决策;智能体与环境之间的交互是通过最大化共享效用函数来实现的:因此,智能体不会相互独立地操作。每个智能体/对象由轨迹、其外观特征(使用MDNet提取[151])和当前位置表示。新帧中的检测结果表示环境。检测网络将每个目标在新帧中的预测位置(由预测网络输出)、最近的目标和最近的检测作为输入,并根据检测可靠性、目标遮挡状态等多种因素,在多种动作中采取一种:同时使用预测和检测更新航迹及其外观特征,忽略检测仅使用预测更新航迹,检测被跟踪目标的遮挡,删除航迹。在MDNet的特征提取部分上使用3个FC层对代理进行建模。消融研究表明,使用预测和检测网络分别代替线性运动模型和匈牙利算法是有效的,并且该方法在MOT15和MOT16数据集上取得了非常好的结果,达到了在线方法中最先进的性能,尽管存在相对较高的ID开关数量。
3.5、DL在MOT中的其他用途
在本节中,我们将介绍深度学习模型的其他有趣应用,这些应用并不完全符合多目标跟踪算法的四个常见步骤之一。因此,这些工作没有包含在表8中,而是总结在表1中。
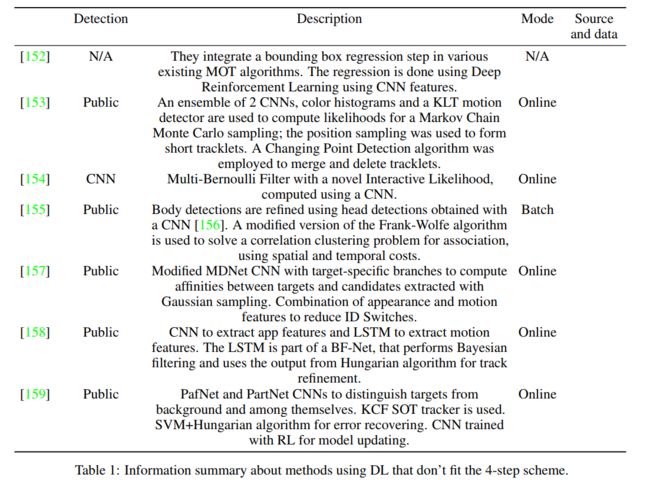
一个例子是[152],Jiang等人在使用许多MOT算法之一后,使用深度RL智能体来执行边界框回归。该过程实际上完全独立于所采用的跟踪算法,可以使用后验概率来提高模型的准确性。使用VGG-16 CNN从边界框包围的区域中提取外观特征,然后将这些特征连接到表示智能体最近10个动作历史的向量。最后,使用由3个全连接层组成的q网络[160]来预测13种可能动作中的一种,其中包括包围盒的运动和缩放以及终止动作,以标志回归的完成。在各种最先进的MOT算法上使用这种边界框回归技术,使MOT15数据集上的绝对MOTA点提高了2到7个点,在公共检测方法中达到了最高分数。作者还表明,他们的回归方法比使用传统方法(例如由更快的R-CNN模型计算的边界框回归)有更好的结果。
Lee等人[153]提出了一种多类多目标跟踪器,该跟踪器使用一组检测器,包括VGG-16和ResNet等CNN模型,来计算每个目标在下一帧中位于某个位置的可能性。利用马尔可夫链蒙特卡罗采样方法预测每个目标的下一位置,结合航迹诞生和死亡概率的估计,建立短航迹段。最后,采用变化点检测[161]算法在表示轨迹段的平稳时间序列中检测突变;这样做是为了检测航迹漂移,删除不稳定的航迹段,并将这些段合并在一起。该算法达到了与使用私有检测的最先进的MOT方法相当的结果。
Hoak等人[154]提出了一个5层的自定义CNN网络,该网络在Caltech行人检测数据集[162]上进行训练,以计算目标位于图像中某个位置的可能性。他们使用了多伯努利滤波器(使用[163]中提出的粒子滤波算法实现),并为每个粒子计算新的交互似然(ILH),以便根据它们与其他目标粒子的距离对它们进行加权;这样做是为了防止算法从属于不同对象的区域采样。该算法在VSPETS 2003 INMOVE soccer数据集(ftp://ftp.cs.rdg.ac.uk/pub/VS-PETS/)和AFL数据集[164]上取得了较好的效果。
Henschel等人[155]除了通常的人体检测外,还使用CNN提取的头部检测[156]来执行行人跟踪。头部的存在/不存在及其相对于边界框的位置,可以帮助确定边界框是真阳性还是假阳性。关联问题被建模为图上的相关性聚类问题,作者用修改版本的Frank-Wolfe算法解决了这个问题[165];将关联代价计算为空间代价和时间代价的组合:空间代价是探测到的头部位置与预测的头部位置之间的距离和角度;使用DeepMatching[79]获得的两帧之间的像素对应关系来计算时间代价。在本文发表时,该算法在MOT17上取得了最高的MOTA分数,在MOT16上取得了第二好的分数。
Gan等人[157]在他们的在线行人跟踪框架中使用了改进的MDNet[151]。每个目标除了共有3个卷积层外,还有3个特定的FC层,在线更新以捕捉目标的外观变化。一组候选框,包括与目标最后一个边界框相交的检测,以及一组从高斯分布中采样的框,这些框的参数使用线性运动模型估计,作为网络的输入,网络输出每个框的置信度分数。得分最高的候选目标被认为是最优估计目标位置。为了减少ID切换错误的数量,算法试图找到与估计框最相似的过去轨迹,使用对之间的另一种亲和性度量;使用外观和运动线索,以及轨迹置信分数和碰撞因子来计算这种亲和性。检测还用于初始化新的轨迹块,并修复发生遮挡时的运动预测错误。
Xiang等[158]使用MetricNet跟踪行人。该模型将亲和度模型与轨迹估计统一起来,使用贝叶斯滤波器进行估计。外观模型由在各种数据集上进行行人再识别训练的VGG-16 CNN组成,提取特征并进行边界框回归;相反,运动模型由两部分组成:基于LSTM的特征提取器,将轨迹的过去坐标作为输入,以及顶部由各种FC层组成的所谓BF-Net,它将LSTM提取的特征和检测框(由匈牙利算法选择)相结合,以执行贝叶斯过滤步骤并输出目标的新位置。与前几节介绍的其他模型类似,MetricNet使用三元组损失进行训练。该算法在MOT16和MOT15上分别取得了在线方法中最好和次好的结果。
最后,Chu等人[159]在他们的算法中使用了三种不同的cnn。第一个称为PafNet[166],用于区分背景和被跟踪对象。第二个被称为PartNet[167],用于区分不同的目标。使用由一个卷积层和一个FC层组成的第三个CNN来决定是否更新跟踪模型。整个算法的工作原理如下:对于每一个被跟踪的目标,在当前帧中使用PafNet和PartNet计算两个得分图。然后,使用核相关滤波跟踪器[168],预测目标的新位置。此外,在一定数量的帧后,执行所谓的检测验证步骤:通过解决图多切问题,将检测器输出的检测(在他们的实验中,他们选择使用数据集提供的公共检测)分配给被跟踪的目标。在一定帧数内与检测不相关的目标被终止。然后,使用第三个CNN检测关联检测框是否优于预测检测框;如果是,则更新KCF模型参数,以反映对象特征的变化。这种CNN使用PafNet提取的map,并使用强化学习进行训练。然后,使用SVM分类器和匈牙利算法进行非关联检测,从目标遮挡中恢复。最后,利用剩余的不关联检测来初始化新目标。该算法在MOT15和MOT16数据集上进行了测试,在第一个数据集上取得了最好的整体性能,在第二个数据集上取得了在线方法中最好的性能。
4、分析与比较
本节比较了在MOTChallenge数据集上测试他们算法的所有工作。我们将只关注MOTChallenge数据集,因为对于其他数据集,没有足够多的相关论文使用深度学习来进行有意义的分析。
我们首先描述实验分析的设置,包括4.1节中考虑的指标和表的组织。第4.2节将介绍从分析中得出的实际结果和考虑因素。
4.1、设置和组织
为了公平比较,我们只显示了在整个测试集上报告的结果。讨论的一些论文报告了他们的结果,使用测试集的子集,或从MOTChallenge数据集的训练分割中提取的验证数据集。这些结果由于无法与其他结果进行比较而被丢弃。此外,由于检测质量的不同会对性能产生很大的影响,因此报告的结果被分为使用公共检测的算法和使用私有检测的算法。由于在线方法的缺点是只能访问当前和过去的信息来分配每帧中的id,因此可以将结果进一步分为在线方法和批处理方法。
对于每个算法,我们指出了参考论文发表的年份、它们的操作模式(批量vs.在线);MOTA, MOTP, IDF1,主要跟踪(MT)和主要丢失(ML)指标,以百分比表示;假阳性(FP)、假阴性(FN)、ID开关(IDS)和片段(Frag)的绝对数量;算法的速度以每秒帧数(Hz)表示。对于每个指标,向上的箭头(")表示得分越高越好,而向下的箭头 ( ↓ ) (\downarrow) (↓)表示相反。这里显示的指标与MOTChallenge网站上的公共排行榜相同。参考工作中给出的数值结果已与MOTChallenge排行榜的数据集成。
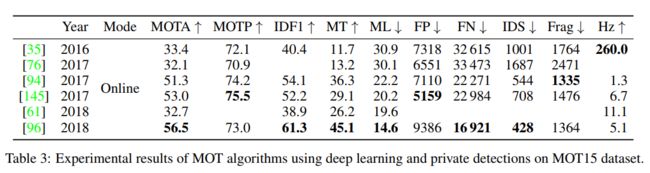
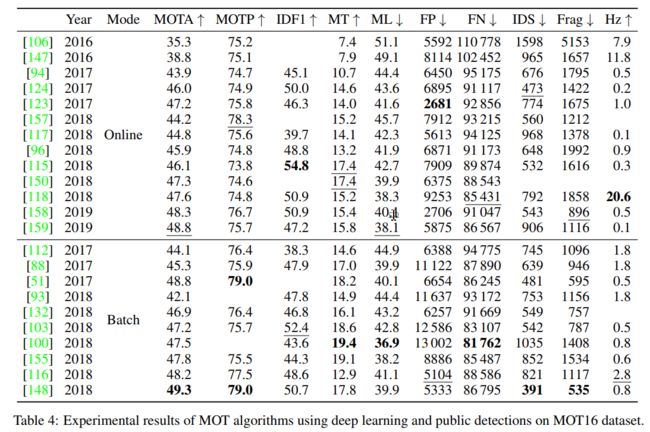
根据前面给出的分类,显示了每个组合数据集/检测源的表。表2和表3分别显示了使用公共检测和私人检测对MOT15的结果;表4和表5对MOT16做了同样的处理。最后,表6显示了在MOT17上的结果,该组织目前只发布了使用公共检测的算法。每个表分别对在线和批处理方法进行分组,对于每个组,论文按年份进行排序,如果论文来自同一年,则按MOTA分数升序排序,因为它是MOTChallenge数据集中考虑的主要指标。如果一个工作在相同的数据集上使用相同的检测集和相同的操作模式显示多个结果,我们只显示具有最高MOTA的结果。每个指标的最佳性能以粗体突出显示,而在相同模式(批处理/在线)下运行的论文中的最佳性能以下划线显示。值得注意的是,Hz指标的比较可能不可靠,因为通常只报告算法的跟踪部分的性能,没有检测步骤,有时不包括深度学习模型的运行时间,而深度学习模型通常是本综述中提出的算法中计算最密集的部分;此外,这些算法运行在各种不同的硬件上。

4.2、结果的讨论
总体评论
正如预期的那样,在每个数据集上表现最好的算法都使用了私有检测,这证实了检测质量主导了跟踪器的整体性能:MOTA 56.5%, MOT15 42.3%, MOT16 71.0%, 49.3%。此外,在MOT16和MOT17上,尽管在线算法的性能逐渐接近于批量算法,但批量算法的性能略优于在线算法。事实上,在MOT15上,使用深度学习的最佳算法以在线方式运行。然而,这可能是更关注开发在线方法的影响,这是MOT深度学习研究社区的一种趋势。在线方法的一个常见问题是碎片数量较多,这在MOTA得分中没有反映出来,如表7所示。这是因为,当发生遮挡或检测丢失时,在线算法无法在视频中向前看,重新识别丢失的目标并插值轨迹的缺失部分[124,89,94]。在图8中,我们可以看到一个被在线方法MOTDT[118]分割的轨迹示例,而它被批量方法eHAF16[103]正确跟踪。


另一个值得注意的有趣的事情是,由于MOTA分数基本上是FPs、FNs和ID开关的归一化和,并且由于FNs的数量通常比FPs至少高一个数量级,比ID开关高两个数量级,因此设法强烈减少FNs数量的方法是获得最佳性能的方法。我们实际上可以观察到MOTA与FNs数量之间存在很强的相关性,这与[14]中发现的一致:MOTA与FN值在MOT15上的Pearson相关系数为−0.95,在MOT16上为−0.98,在MOT17上为−0.95。因此,虽然使用公共检测在减少FNs方面有有限的改进,但最有效的方法仍然是构建和训练自定义检测器;FNs数量减半实际上是私有检测器能够带来更好的跟踪性能的主要原因,能够识别以前未发现的目标。在图9中,我们可以看到对漏检特别敏感的SORT算法,如何在相对检测漏检时无法检测到目标。

为了避免这个问题,许多新算法都包含了解决这个问题的新策略。事实上,虽然执行插值的基本方法能够在遮挡期间恢复缺失的框,但这仍然不足以检测到甚至一次检测都没有覆盖的目标,在MOT15和MOT16[14]上已被证明占总目标的18%。例如,Sheng等人[103]提出的eHAF16算法采用超像素提取算法对公开提供的检测进行补充,实际上能够显著减少MOT17上的假阴性数量,在数据集上达到MOTA得分最高。而MOTDT算法[118]则使用R-FCN将丢失的检测结果与新的候选结果进行整合,在MOT17上能够达到在线算法中最好的MOTA和最低的假阴性数量。AP-RCNN算法[145]采用粒子滤波算法,仅依靠检测来初始化新目标和恢复丢失的目标,避免了漏检带来的问题。文献[150]中提出的算法也通过设计一个深度预测网络来减少FNs,其目的是学习对象的运动模型。在测试时,网络能够预测它们在后续帧中的位置,从而减少因漏检产生的假阴性数量。事实上,它是MOT16中关于这个指标的第二好的在线方法。
必须对匹配网络的训练策略进行重要观察。如[93]所指出的,使用真实轨迹训练网络来预测匹配度可能会产生次优的结果,因为在测试时,这些网络将暴露于不同的数据分布,这些数据分布由噪声轨迹组成,可能包括漏检/错误检测。事实上,许多算法已经选择使用实际检测[96]或通过手动向真实轨迹[93,115]中添加噪声和错误来训练网络,尽管这有时可能会减慢训练过程,并且并不总是可行的[60]。
MOT四个步骤中的最佳方法
说到私人检测,这些表表明,目前性能最好的检测器是Faster R-CNN及其变体。事实上,[38]中提出的算法,使用改进的Faster R-CNN,已经在MOT16上的在线方法中保持了三年的排名第一,而许多其他表现最好的MOT16算法也采用了相同的检测。相比之下,采用SSD检测器的算法,如[60]和[61]中提出的算法,往往性能更差。然而,SSD的一个很大优势是它的速度更快:由于Kieritz等人的算法,[60]能够达到接近实时的性能(4.5 FPS),包括检测步骤。尽管有大量的在线方法,但在MOT管道中使用深度学习技术的一个主要问题仍然是难以获得实时预测,这使得此类算法在大多数实际的在线场景中不可用。
关于特征提取,在三个考虑的数据集上所有表现最好的方法都使用CNN来提取外观特征,其中GoogLeNet是最常见的。不利用外观的方法(无论是用深度方法还是经典方法提取的)往往性能更差。然而,视觉特征是不够的:许多最好的算法还使用其他类型的特征来计算亲和力,特别是运动特征。事实上,像lstm和卡尔曼滤波器这样的算法经常被用于预测目标在下一帧中的位置,这通常有助于提高关联的质量。各种贝叶斯滤波算法,如粒子滤波和假设密度滤波,也被用于预测目标运动,它们从深度模型的使用中受益[158,145,98]。尽管如此,即使与非视觉特征一起使用,外观仍然在提高算法的整体性能[123,158]方面发挥着主要作用,特别是在避免ID开关[83]或在长时间遮挡[41]后重新识别目标方面。在后一种情况下,简单的运动预测器不起作用,因为线性运动假设很容易被打破,如Zhou等人所指出的[55]。
虽然深度学习在检测和特征提取中发挥着重要作用,但使用深度网络来学习亲和函数的情况并不普遍,而且尚未被证明是一个好的MOT算法的必要条件。事实上,许多算法依赖于对各种深度特征和非深度特征的手工距离度量的组合。然而,一些工作已经证明了使用亲和网络可以产生性能最好的算法[148,145,51,96],方法从使用孪生cnn到递归神经网络。特别是,Ma等人[148]提出的自适应孪生网络能够产生可靠的相似性度量,有助于遮挡后的行人再识别,并使算法在MOT16上达到最高的MOTA分数。对于Tang等人提出的StackNetPose CNN来说,身体部位信息的融合也至关重要。[51]:它作为一种注意力机制,允许网络专注于输入图像的相关部位,从而产生更准确的相似性度量。使用私有检测,该算法能够在MOT16上达到最佳性能。
很少有工作探索使用深度学习模型来指导关联过程,这可能是未来方法的一个有趣的研究方向。
性能最好的算法的其他趋势

在目前排名靠前的方法中,还可以发现一些其他趋势。例如,在线方法中一个成功的方法是使用单目标跟踪算法,适当修改以解决MOT任务。事实上,这3个数据集上表现最好的一些在线算法采用了深度学习技术增强的SOT跟踪器,以从遮挡中恢复或刷新目标模型[159,115,123]。有趣的是,据我们所知,没有经过调整的SOT算法被用于执行带有私人检测的跟踪。正如我们已经观察到的,私有检测的使用减少了完全未被发现的目标的数量;由于SOT跟踪器在目标被识别后通常不需要检测来继续跟踪目标,因此未发现目标的减少可能会导致丢失跟踪的数量大大减少,这反过来会提高跟踪器的整体性能。因此,将SOT跟踪器应用于私人检测可能是一个很好的研究方向,可以尝试进一步提高在MOTChallenge数据集上的结果。批处理方法还可以利用SOT跟踪器查看过去的帧,以便在检测器首次识别目标之前恢复漏检。然而,基于sot的MOT跟踪器有时仍然容易发生跟踪漂移,并产生更多的ID开关。例如KCF16算法[159],虽然在MOT16上取得了在线方法中MOTA得分最高的公开检测结果,但由于跟踪器漂移,仍然产生了比较高的开关数量,如图10所示。此外,基于sot的MOT算法必须小心不要继续跟踪虚假轨迹,这是由高质量检测器预测的不可避免的更高假阳性检测数量造成的,因为这可能会抵消FNs数量的减少。目前的方法[159,115]仍然倾向于使用检测重叠(例如,检测覆盖了最近的多少帧)来了解轨迹在长期内是真还是假阳性,但应该研究更好的解决方案以避免对检测的完全依赖。
虽然许多方法通过将任务制定为图优化问题来执行关联,但批处理方法尤其受益于此,因为它们可以对它们执行全局优化。例如,在cnn计算的亲和度[148,51]的帮助下,最小成本提升的多分支问题在MOT16上达到了最佳性能,而在MOT17的两种顶级方法[103,155]上使用了异构关联图融合和相关性聚类。
最后,可以注意到边界框的准确性从根本上影响算法的最终性能。事实上,在MOT15[89]上排名靠前的跟踪器仅通过使用深度强化学习智能体对之前最先进的算法[89]的输出执行边界框回归步骤就获得了相对较高的MOTA分数。开发一个有效的边界框回归器,以纳入未来的MOT算法中,这可能是一个有趣的研究方向,但尚未被彻底探索。此外,不依赖于单一帧来固定框,这可能会使它们在遮挡的情况下包含错误的目标,批量方法还可以尝试利用未来和过去的目标外观来更准确地回归正确目标周围的边界框。
5、结论与未来发展方向
本文全面描述了所有采用深度学习技术的MOT算法,重点是单摄像头视频和2D数据。四个主要步骤可以表征一个通用的MOT流水线:检测,特征提取,匹配度计算,关联。已经探索了深度学习在这四个步骤中的每个步骤的使用。虽然大多数方法都集中在前两个方面,但也有一些应用深度学习来学习亲和函数的方法,但只有很少的方法使用深度学习来直接指导关联算法。在MOTChallenge数据集上对结果进行了数值比较,结果表明,尽管方法种类繁多,但在这些方法中可以发现一些共同点:
-
检测质量很重要:假阴性的数量仍然主导着MOTA得分。虽然深度学习已经允许使用公共检测的算法在这方面进行一些改进,但使用更高质量的检测仍然是减少假阴性的最有效方法。因此,在检测步骤中仔细使用深度学习可以大大提高跟踪算法的性能;
-
cnn在特征提取中至关重要:外观特征的使用也是一个好的跟踪器的基础,cnn在提取它们方面特别有效。此外,强跟踪器倾向于将它们与运动特征结合使用,可以使用lstm、卡尔曼滤波器或其他贝叶斯滤波器进行计算;
-
SOT跟踪器和全局图优化工作:在深度学习的帮助下,SOT跟踪器适应MOT任务,最近产生了性能良好的在线跟踪器;批处理方法反而受益于深度模型在全局图优化算法中的集成。
由于深度学习是最近才在MOT领域引入的,因此也确定了一些有希望的未来研究方向:
- 研究更多的策略来减少检测错误:尽管现代检测器不断达到越来越好的性能,但在密集行人跟踪等复杂场景中,它们仍然容易产生大量的误报和漏报。一些算法通过将检测与从其他来源提取的信息(如超像素[103]、R-FCN[118]、粒子滤波[145]等)整合,提供了减少对检测的独家依赖的解决方案,但还应研究进一步的策略;
- 应用深度学习跟踪不同的目标:大多数基于深度学习的MOT算法都专注于行人跟踪。由于不同类型的目标带来了不同的挑战,因此应该研究使用深度网络在跟踪车辆、动物或其他目标方面可能的改进;
- 研究当前算法的鲁棒性:当前方法在不同相机条件下的表现如何?不同的对比度、光照、噪声/缺失帧如何影响当前算法的结果?现有的深度学习网络能够泛化到不同的跟踪上下文吗?例如,绝大多数人跟踪框架都是为了跟踪行人或运动员而训练的,但跟踪在其他场景中也可能有用。一种可能的新应用程序可以帮助在不同的背景下理解场景:在电影中,为了生成文本描述,以提供在电影中搜索场景的粗略方式;或者在社交网络上,以为盲人用户生成描述,或者检测应该从平台上删除的不适当视频。这些不同的场景可能需要改变当前的检测和跟踪算法,因为人们可能以不同寻常的姿势和行为出现,这些姿势和行为在现有的MOT数据集中是不存在的;
- 应用深度学习来指导关联:使用深度学习来指导关联算法并直接执行跟踪仍处于起步阶段:在这个方向上需要更多的研究来了解深度算法是否在这一步中也有用;
- 将目标跟踪器与私有检测相结合:将目标跟踪器与私有检测相结合,可以减少丢失的跟踪数,从而减少假阴性,特别是在批量设置中,可以恢复以前遗漏的检测;
- 研究边界框回归:使用边界框回归已被证明是获得更高MOTA分数的一个有希望的步骤,但这尚未被详细探索,应该进行进一步的改进,例如使用过去和未来的信息来指导回归;
- 研究后跟踪处理:在批处理环境中,可以对跟踪器的输出应用校正算法以提高其性能。Babaee等人[132]已经证明了这一点,他们在现有算法的基础上应用遮挡处理,Jiang等人[152]使用前述的边界框回归步骤。可以对跟踪器的结果进行更复杂的处理,以进一步改善结果。
最后,由于所提出的算法中很少有提供源代码的公开访问,我们希望鼓励未来的研究人员公布他们的代码,以便更好地重现其结果,并惠及整个研究社区。