【论文阅读】Dynamic Convolution: Attention over Convolution Kernels(CVPR2020)
论文题目:Dynamic Convolution: Attention over Convolution Kernels(CVPR2020)
论文地址:https://arxiv.org/abs/1912.03458
代码地址:https://github.com/kaijieshi7/Dynamic-convolution-Pytorch
https://github.com/prstrive/CondConv-tensorflow
2种代码均为非官方实现,其中pytorch代码讲解见[1]。
文章贡献:
1. 提出了一个动态卷积结构,相比于静态卷积,提高了网络的性能,额外的计算成本可以忽略;
2. 该结构可以容易的集成到现有的CNN架构中,在图像分类和关键点检测任务中取得了精度的提升。
1 背景和动机
轻量级的神经网络可以应用到移动设备上,而一些提升网络精度的方法往往计算量很大。当计算约束变得非常低时,性能会显著下降。
该文方法主要针对于轻量级神经网络,研究当计算成本受到限制时,如何尽可能的提升网络精度。
论文提出了一种动态卷积,它在同一层使用K个并行的卷积![]() 进行计算,而不是每一层使用不同的卷积:
进行计算,而不是每一层使用不同的卷积:
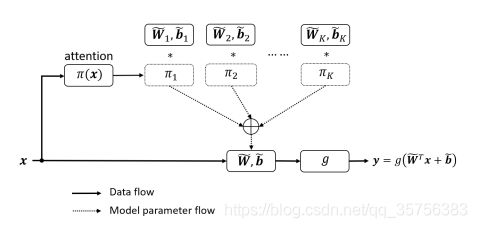
输入x经过attention产生一组权重Πk,有![]() ,每个权重对应相应的并行的卷积操作,最终由下述公式聚合:
,每个权重对应相应的并行的卷积操作,最终由下述公式聚合:
![]()
![]()
因此它不会增加网络的深度或宽度,但是增加了网络的复杂性,提升了网络的性能。
2 相关工作
(1)Effificient CNNs:
SqueezeNet使用1x1卷积减少参数量;MobileNetV1使用depthwise convolution替换3x3卷积,V2采用bottlenecks结构,V3采用SE模块,利用NAS搜索找到最优网络结构;ShufflfleNet通过channel shufflfle操作进一步减少1x1卷积的MAdds[2].
该论文提出的动态卷积可以替换上述任何卷积,并与SE结构互补。
(2)模型压缩和量化:帮助减少动态卷积的模型尺寸。
(3)动态深度神经网络:
以往的方法关注于基于输入图像跳过现有模型的一部分,该论文主要有2个区别:
- 卷积核是动态的,但网络是静态的,而以往的方法一般是动态的网络静态的卷积核;
- 不需要额外的控制器,可以实现端到端的训练。
(4)神经网络架构搜索NAS:
该论文提出的动态卷积可以应用于由NAS发现的架构中,提升其性能,只增加很低的FLOPs[2].
3 动态卷积结构
(1)动态感知器
传统静态感知器:![]() ,W和b是权重和偏置,g是激活函数。
,W和b是权重和偏置,g是激活函数。
动态感知器:聚合k个线性感知器,是非线性的,有

Πk是第k个线性感知器的注意权重,它随输入的不同而变化。相比静态感知器,动态感知器有更强的特征表达能力。
动态感知器引入了2个额外的计算:注意权重的计算和聚合操作的计算,有如下约束:

即增加的额外计算相比于原本感知器的计算量来说,是可以忽略的。
(2)动态卷积

通过SE模块来计算分配给每个并行卷积的权重。首先将输入特征在通道上进行平均池化,变为HxWxCin大小,之后经过两层全连接层(中间包括一个relu层),第1个全连接层将大小变为原来的1/4,FC2将输出长度为k的值,由softmax获取权重。
不同于SE将权重加在通道上,改论文将权重加在并行的卷积上。
注意模块多出的计算量Atten = (H*W*Cin) + (Cin*Cin/4) + (Cin/4 * k),聚合操作多出的计算量K = (k*Cin*Cout*Dk*Dk) + (k*Cout),都远小于卷积的计算量:H*W*Cin*Cout*Dk*Dk(Dk是卷积核的大小)。
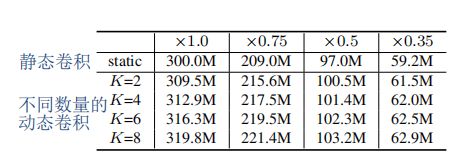
在MobileNetV2上静态卷积和动态卷积计算成本的对比:
4 训练策略
(1)限制注意力的取值将简化注意力模型的学习
注意力取值的限制将缩小多个卷积的叠加核的取值空间。论文不同于SE的sigmoid,而是使用了softmax,除了将注意力取值限制在0与1之间外,还使得所有注意力的和为1。

如上图所示,使用3个卷积核W1W2W3(可以看成是空间坐标中的3个向量),将注意力取值限制在0与1之间会将叠加核的取值限制在整个三棱锥中,而限制其和为1将进一步将叠加核的取值限制在图中的三角形中。因此,选择softmax比选择sigmoid更好。
(2)限制注意力接近均匀分布有利于多个卷积核在训练初期同时学习
Temperature annealing
对于inputs输入数据:
![]()
使用sigmoid的结果和softmax的结果对比:


可以看到softmax的注意力比较稀疏。因此论文提出了一个temperature参数,在第2个全连接层和softmax之间让输出除以t,以实现更均匀的注意结果:

![]()
论文指出,使用Temperature annealing策略更有助于网络精度的提升,即在最开始训练的10个epoch中,t的取值由30到1线性递减。对比下图的蓝线(未使用t)和红线(t=30)。
动态卷积层数
使用softmax来计算注意力时,收敛缓慢,这种情况与动态卷积层的数量有关。
在MobileNetV2*0.5上的实验,左图蓝线为每个bottlenecks的每个卷积均使用动态卷积,右图蓝线为只在每个bottlenecks的最后一个1x1卷积使用:

(3)与CondConv的对比
CondConv使用sigmoid来计算注意力,论文使用带有t的softmax来计算。由(1)可知CondConv的核空间明显大于DY-CNNs,因此学习注意模型更加困难,
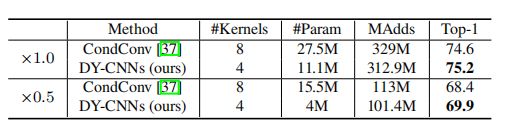
上图是两者的对比,DY-CNNs使用更少的kernel,更小的计算量,可以获得更高的精度。
5 实验结果
图像分类任务
使用ImageNet数据集,在ResNet浅网络、MobileNetV2、MobileNetV3上进行了实验对比。设置K=4,t=30。
(1)动态卷积性质证明
- 每一层的卷积核是不同的;
- 注意力依赖于输入。
论文使用反证法来证明以上性质,说明其提出的DY-CNNs属于动态卷积范畴。
- 假设1:如果卷积核不变,使用不同的注意力会获得稳定的性能;
- 假设2:对输入不使用其自己的注意力不会影响结果。
根据以上假设,设计了4种变换来实验对比:

- 不使用注意力,对个卷积的结果取平均;
- 只使用注意力最大的那一个卷积;
- 将每个卷积块和它们对应的权重随机打乱;
- 在a图片上应用由b图片算出来的动态卷积。
与使用原始的DY-CNNs相比,4种变换的性能均大幅降低,显著的不稳定性证实了卷积核的多样性,即假设1和2均错误。
具体来说,注意力在low levels是均匀分布的,在high levels是稀疏的。因此如果在low levels取最大的注意力(第2种)或者在high levels取平均结果(第1种)都是有问题的。第3、4种变换表明注意力依赖于输入,每个输入需使用它们自己的注意力。
下表表明了注意力如何影响跨层的性能:

√表示在该level使用注意力,-表示对卷积结果取平均(第1种)。可以看到,当每层都使用注意力时,效果最好。而在high levels不使用注意力(红框)效果很差,在low levels(蓝框)不使用注意力虽然效果不是最好的,但是因为注意力分布均匀,所以即使取平均也没有太大影响。
(2)消融实验
卷积核的数目
3种不同Depth的DY-MobileNetV2对比:

即使K设置的很小(K=2),动态卷积也明显优于静态卷积;当K>4后,对性能的提升不明显。
使用动态卷积的层
对比在每个bottleneck块的3个不同卷积层(1x1卷积,3x3深度可分离卷积,1x1卷积)使用动态卷积的结果:
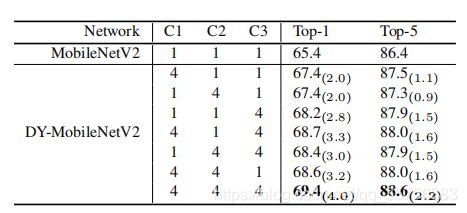
对3种卷积层均使用k=4的动态卷积效果最好,如果只能在某一层使用,那么在C3使用效果最好。
Softmax的Temperature参数

T=30时效果最好,且使用annealing策略时有进一步的改进。
动态卷积和SE的对比
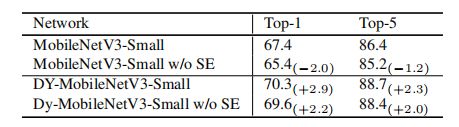
MobileNetV3中只使用动态卷积比只使用SE可以获得2.2%的提升,如果同时使用两者,比只使用其一效果更好,说明对kernel的注意力和对chanel的注意力可以协同作用。
动态卷积和静态卷积的对比

在各种网络中动态卷积都由于静态卷积,且计算量相差不大。
人体位姿估计
使用COCO 2017数据集,各种网络中参数量等和性能的对比:
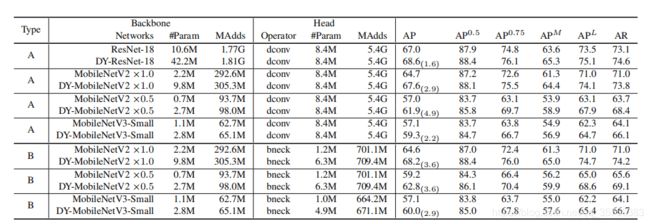
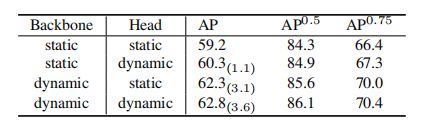
backbone和head中动态卷积的影响:(主要来源于backbone)
6 相关文献
[1] 通过分组卷积的思想,巧妙的代码实现动态卷积(Dynamic Convolution)
[2] FLOPS、MAdds、MACC指标
[3] 动态滤波器卷积|DynamicConv
[4] 动态取值_动态卷积:自适应调整卷积参数,显著提升模型表达能力 CVPR 2020