【知识点】卷积神经网络
文章目录
-
- 符号约定
- 过滤器
- Padding
- 卷积步长
- 三维卷积
- 单层卷积网络
- 简单卷积网络示例
- 池化层
- 迁移学习
- 数据扩充
- 目标定位
- 特征点检测
- 交并比
- 非极大值抑制
- YOLO
符号约定
n 原图像大小,比如6*6的图像,n=6
f 过滤器大小,比如3*3的过滤器,f=3
p padding填充多少像素,填充2像素,p=2
s 卷积步长
nc 通道数
nc’ 过滤器个数
图片左上角的坐标为(0,0),右下角标记为(1,1)。要确定边界框的具体位置,需要指定红色方框的中心点,这个点表示为(bx , by),边界框的高度为 bh,宽度为bw。
过滤器
如何在图像中检测边缘?
看一个例子,一个6×6的灰度图像。因为是灰度图像,所以它是6×6×1的矩阵,而不是6×6×3的,因为没有RGB三通道。为了检测图像中的垂直边缘,你可以构造一个3×3矩阵。在共用习惯中,在卷积神经网络的术语中,它被称为过滤器。也称卷积核。
更多过滤器:sobel、scharr
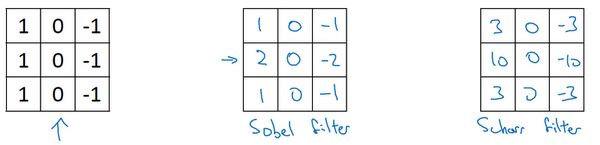
卷积运算

垂直边缘检测

什么过滤器更好?这就是卷积神经网络要做的事情,使用反向传播去让神经网络学习这9个数字
Padding
我们在之前视频中看到,如果你用一个3×3的过滤器卷积一个6×6的图像,你最后会得到一个4×4的输出,也就是一个4×4矩阵。那是因为你的3×3过滤器在6×6矩阵中,只可能有4×4种可能的位置。这背后的数学解释是,如果我们有一个 n ∗ n的图像,用 f ∗ f的过滤器做卷积,那么输出的维度就是 ( n − f + 1 ) ∗ ( n − f + 1 )。在这个例子里是 6 − 3 + 1 = 4,因此得到了一个4×4的输出。
这样的话会有两个缺点:
第一个缺点,每次做卷积操作,你的图像就会缩小,从6×6缩小到4×4,你可能做了几次之后,你的图像就会变得很小了,可能会缩小到只有1×1的大小。你可不想让你的图像在每次识别边缘或其他特征时都缩小。
第二个缺点,如果你注意角落边缘的像素,这个像素点(绿色阴影标记)只被一个输出所触碰或者使用,因为它位于这个3×3的区域的一角。但如果是在中间的像素点,比如这个(红色方框标记),就会有许多3×3的区域与之重叠。所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息。

为了解决这些问题,你可以在卷积操作之前填充这幅图像。在这个案例中,你可以沿着图像边缘再填充一层像素。如果你这样操作了,那么6×6的图像就被你填充成了一个8×8的图像。如果你用3×3的图像对这个8×8的图像卷积,你得到的输出就不是4×4的,而是6×6的图像,你就得到了一个尺寸和原始图像6×6的图像。习惯上,你可以用0去填充,如果是填充的数量,在这个案例中, p = 1,因为我们在周围都填充了一个像素点,输出也就变成了 ( n + 2 p − f + 1 ) ∗ ( n + 2 p − f + 1 ),所以就变成了 ( 6 + 2 ∗ 1 − 3 + 1 ) ∗ ( 6 + 2 ∗ 1 − 3 + 1 ) = 6 ∗ 6,和输入的图像一样大。这个涂绿的像素点(左边矩阵)影响了输出中的这些格子(右边矩阵)。这样一来,丢失信息或者更准确来说角落或图像边缘的信息发挥的作用较小的这一缺点就被削弱了。

至于选择填充多少像素,通常有两个选择,分别叫做Valid卷积和Same卷积。
Valid卷积意味着不填充,这样的话,如果你有一个 n ∗ n的图像,用一个 f ∗ f的过滤器卷积,它将会给你一个 ( n − f + 1 ) ∗ ( n − f + 1 ) 维的输出。这类似于我们在前面的视频中展示的例子,有一个6×6的图像,通过一个3×3的过滤器,得到一个4×4的输出。
Same卷积意味你填充后,你的输出大小和输入大小是一样的。根据这个公式 n − f + 1,当你填充 p个像素点, n就变成了 n + 2 p ,最后公式变为 n + 2 p − f + 1。因此如果你有一个 n ∗ n的图像,用 p个像素填充边缘,输出的大小就是这样的 ( n + 2 p − f + 1 ) ∗ ( n + 2 p − f + 1 )。如果你想让 n + 2 p − f + 1 = n的话,使得输出和输入大小相等,如果你用这个等式求解 p ,那么 p = ( f − 1 ) / 2。所以当 f 是一个奇数的时候,只要选择相应的填充尺寸,你就能确保得到和输入相同尺寸的输出。这也是为什么前面的例子,当过滤器是3×3时,和上一张幻灯片的例子一样,使得输出尺寸等于输入尺寸,所需要的填充是(3-1)/2,也就是1个像素。另一个例子,当你的过滤器是5×5,如果 f = 5,然后代入那个式子,你就会发现需要2层填充使得输出和输入一样大,这是过滤器5×5的情况。
习惯上,计算机视觉中, f 通常是奇数
卷积步长
如果你用一个 f ∗ f的过滤器卷积一个 n ∗ n的图像,你的padding为 p,步幅为 s,在这个例子中 s = 2,你会得到一个输出,因为现在你不是一次移动一个步子,而是一次移动 s个步子,输出于是变为
![]()
在我们的这个例子里, n = 7 , p = 0 , f = 3 , s = 2 , (7+0−3)/2 + 1 = 3,即3×3的输出。
如果商不是一个整数怎么办?在这种情况下,我们向下取整。 ⌊ ⌋这是向下取整的符号
总结一下维度情况,如果你有一个 n ∗ n的矩阵或者 n ∗ n的图像,与一个 f ∗ f的矩阵卷积,或者说 f ∗ f 的过滤器。Padding是 p,步幅为 s,输出尺寸就是这样:

三维卷积
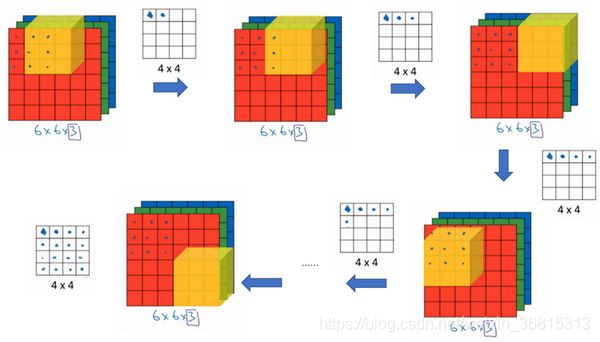
假设一张6*6*3的彩色图像,要准备一个3*3*3的过滤器,最后一个数字通道数必须和过滤器中的通道数相匹配。

为了计算这个卷积操作的输出,你要做的就是把这个3×3×3的过滤器先放到最左上角的位置,这个3×3×3的过滤器有27个数,27个参数就是3的立方。依次取这27个数,然后乘以相应的红绿蓝通道中的数字。先取红色通道的前9个数字,然后是绿色通道,然后再是蓝色通道,乘以左边黄色立方体覆盖的对应的27个数,然后把这些数都加起来,就得到了输出的第一个数字。
如果要计算下一个输出,你把这个立方体滑动一个单位,再与这27个数相乘,把它们都加起来,就得到了下一个输出,以此类推。
一个3×3×3的过滤器,如果你想检测图像红色通道的边缘,那么你可以将绿色通道全为0,蓝色也全为0。如果你把这三个堆叠在一起形成一个3×3×3的过滤器,那么这就是一个检测垂直边界的过滤器,但只对红色通道有用。
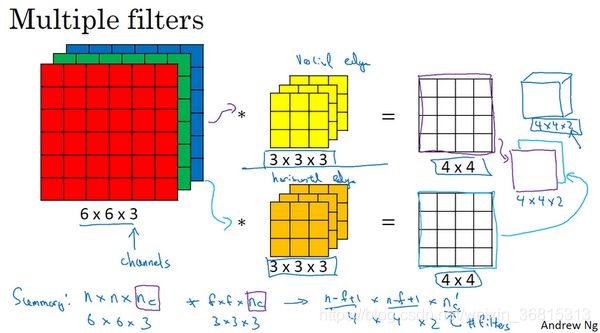
我们总结一下维度,如果你有一个 n ∗ n ∗ nc(通道数)的输入图像,在这个例子中就是6×6×3,这里的 nc就是通道数目,然后卷积上一个 f ∗ f ∗ nc,这个例子中是3×3×3,按照惯例,这个(前一个 nc)和这个(后一个 nc)必须数值相同。然后你就得到了( n − f + 1)∗ *∗( n − f + 1)∗ nc′,这里 nc′其实就是下一层的通道数,它就是你用的过滤器的个数,在我们的例子中,那就是4×4×2。我写下这个假设时,用的步幅为1,并且没有padding。如果你用了不同的步幅或者padding,那么这个 n − f + 1 数值会变化,正如前面的视频演示的那样。
单层卷积网络

假设你有10个过滤器,而不是2个,神经网络的一层是3×3×3,那么,这一层有多少个参数呢?我们来计算一下,每一层都是一个3×3×3的矩阵,因此每个过滤器有27个参数,也就是27个数。然后加上一个偏差,用参数 b表示,现在参数增加到28个。现在我们有10个,加在一起是28×10,也就是280个参数。
维度:

简单卷积网络示例

池化层
卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。池化层没有需要学习的参数。
最大池化(max pooling)
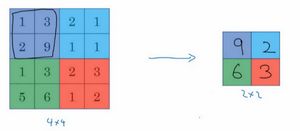
左上区域的最大值是9,右上区域的最大元素值是2,左下区域的最大值是6,右下区域的最大值是3。为了计算出右侧这4个元素值,我们需要对输入矩阵的2×2区域做最大值运算。这就像是应用了一个规模为2的过滤器,因为我们选用的是2×2区域,步幅是2,这些就是最大池化的超参数。
这是对最大池化功能的直观理解,你可以把这个4×4区域看作是某些特征的集合,也就是神经网络中某一层的非激活值集合。数字大意味着可能探测到了某些特定的特征,左上象限具有的特征可能是一个垂直边缘,一只眼睛,或是大家害怕遇到的CAP特征。显然左上象限中存在这个特征,这个特征可能是一只猫眼探测器。然而,右上象限并不存在这个特征。最大化操作的功能就是只要在任何一个象限内提取到某个特征,它都会保留在最大化的池化输出里。所以最大化运算的实际作用就是,如果在过滤器中提取到某个特征,那么保留其最大值。如果没有提取到这个特征,可能在右上象限中不存在这个特征,那么其中的最大值也还是很小,这就是最大池化的直观理解。
输入是一个5×5的矩阵。我们采用最大池化法,它的过滤器参数为3×3,即 f = 3,步幅为1, s = 1,输出矩阵是3×3.之前讲的计算卷积层输出大小的公式同样适用于最大池化,即 (n +2p−f)/s + 1,这个公式也可以计算最大池化的输出大小。
平均池化,不太常用
迁移学习
下载别人预训练好的权重,来初始化自己的权重。
数据扩充
图像:镜像对称、随机裁剪、色彩转换…
目标定位

为监督学习任务定义目标标签 y,有四个分类,神经网络输出的是这四个数字和一个分类标签,或分类标签出现的概率。目标标签y 的定义如下: y = [ P c b x b y b h b w c 1 c 2 c 3 ] y= \begin{bmatrix} {P_c}\\ {b_x}\\ {b_y}\\ {b_h}\\ {b_w}\\ {c_1}\\ {c_2}\\ {c_3}\\ \end{bmatrix} y=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡Pcbxbybhbwc1c2c3⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤ ,它是一个向量,第一个组件 p c p_c pc表示是否含有对象,如果对象属于前三类(行人、汽车、摩托车),则 p c p_c pc=1,如果是背景,则图片中没有要检测的对象,则 p c p_c pc=0 。我们可以这样理解 p c p_c pc,它表示被检测对象属于某一分类的概率,背景分类除外。
如果检测到对象,就输出被检测对象的边界框参数 b x b_x bx、 b y b_y by 、 b h b_h bh和 b w b_w bw。最后,如果存在某个对象,那么 p c p_c pc = 1,同时输出 c 1 c_1 c1、 c 2 c_2 c2和 c 3 c_3 c3,表示该对象属于1-3类中的哪一类,是行人,汽车还是摩托车。鉴于我们所要处理的问题,我们假设图片中只含有一个对象,所以针对这个分类定位问题,图片最多只会出现其中一个对象。
特征点检测
交并比

在对象检测任务中,你希望能够同时定位对象,所以如果实际边界框是这样的,你的算法给出这个紫色的边界框,那么这个结果是好还是坏?所以交并比(loU)函数做的是计算两个边界框交集和并集之比。两个边界框的并集是这个区域,就是属于包含两个边界框区域(绿色阴影表示区域),而交集就是这个比较小的区域(橙色阴影表示区域),那么交并比就是交集的大小,这个橙色阴影面积,然后除以绿色阴影的并集面积。
一般约定,在计算机检测任务中,如果IoU ≥ 0.5,就说检测正确,如果预测器和实际边界框完美重叠,loU就是1,因为交集就等于并集。但一般来说只要IoU ≥ 0.5,那么结果是可以接受的,看起来还可以。一般约定,0.5是阈值,用来判断预测的边界框是否正确。一般是这么约定,但如果你希望更严格一点,你可以将loU定得更高,比如说大于0.6或者更大的数字,但loU越高,边界框越精确。
所以这是衡量定位精确度的一种方式,你只需要统计算法正确检测和定位对象的次数,你就可以用这样的定义判断对象定位是否准确。再次,0.5是人为约定,没有特别深的理论依据,如果你想更严格一点,可以把阈值定为0.6。有时我看到更严格的标准,比如0.6甚至0.7,但很少见到有人将阈值降到0.5以下。
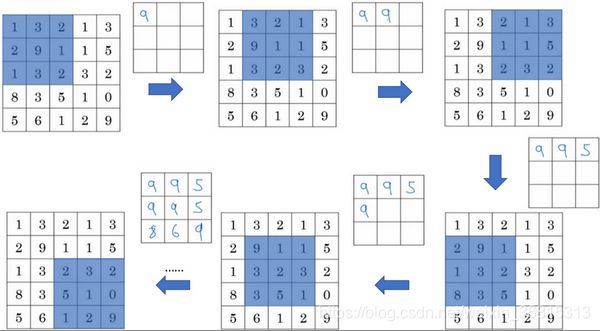
非极大值抑制
3.7 非极大值抑制-深度学习第四课《卷积神经网络》-Stanford吴恩达教授_赵继超的笔记-CSDN博客
YOLO
3.9 YOLO算法-深度学习第四课《卷积神经网络》-Stanford吴恩达教授_赵继超的笔记-CSDN博客_yolo卷积神经网络