Flink HiveCatalog
Hive Metastore作为一个元数据管理的标准在Hadoop生态系统中已经成为公认的事实,因此Flink也采用HiveCatalog作为表元数据持久化的介质。对于同时部署了Hive和Flink的公司来说,可以方便管理元数据,而对于只部署了Flink的公司来说,HiveCatalog也是Flink唯一支持的元数据持久化的介质。不将元数据持久化的时候,开发过程中的每个地方都需要使用DDL重新将Kafka等数据源的数据注册到临时的Catalog中,浪费了很多精力和时间。
1、使用Hive作为元数据存储介质,需要制定hive-site.xml配置文件的位置,里面制定了存储hive-metadata的MySQL或其他关系型数据库的连接信息。
2、sql-client配置访问HiveCatalog,修改flink安装目录下conf/sql-client-defaults.yaml文件,将catalogs模块的内容改为:
#==============================================================================
# Catalogs
#==============================================================================
# Define catalogs here.
catalogs:
# A typical catalog definition looks like:
- name: myhive
type: hive
hive-conf-dir: /apps/hive/conf
hive-version: 2.3.5
default-database: gmallexecutions模块也需要修改:
execution:
# select the implementation responsible for planning table programs
# possible values are 'blink' (used by default) or 'old'
planner: blink
# 'batch' or 'streaming' execution
type: streaming
# allow 'event-time' or only 'processing-time' in sources
time-characteristic: event-time
# interval in ms for emitting periodic watermarks
periodic-watermarks-interval: 200
# 'changelog' or 'table' presentation of results
result-mode: table
# maximum number of maintained rows in 'table' presentation of results
max-table-result-rows: 1000
# parallelism of the program
parallelism: 4
# maximum parallelism
max-parallelism: 128
# minimum idle state retention in ms
min-idle-state-retention: 0
# maximum idle state retention in ms
max-idle-state-retention: 0
# current catalog ('default_catalog' by default)
current-catalog: hive
# current database of the current catalog (default database of the catalog by default)
current-database: flink
# controls how table programs are restarted in case of a failures
restart-strategy:
# strategy type
# possible values are "fixed-delay", "failure-rate", "none", or "fallback" (default)
type: fallbackhive-conf-dir目录需要根据实际情况填写。
此时,通过sql-client.sh embedded启动sql-client:
Flink SQL> use catalog myhive; # 选择Catalog
Flink SQL> show databases;
default
gmall
test
Flink SQL> create database flink;
[INFO] Database has been created.
Flink SQL> use flink;
Flink SQL> CREATE TABLE log_user_cart (name STRING, logtime BIGINT, etime STRING, prod_url STRING) WITH (
> 'connector.type' = 'kafka',
> 'connector.version' = 'universal',
> 'connector.topic' = 'test_log_user_cart',
> 'connector.properties.zookeeper.connect' = 'm.hadoop.com:2181,s1.hadoop.com:2181,s2.hadoop.com:2181',
> 'connector.properties.bootstrap.servers' = 'm.hadoop.com:9092,s1.hadoop.com:9092,s2.hadoop.com:9092',
> 'format.type' = 'csv'
> );
[INFO] Table has been created.
Flink SQL> 切换到别的窗口打开hive的终端,即可看到该数据库:
hive (flink)> show databases;
OK
database_name
default
flink
gmall
test
Time taken: 0.019 seconds, Fetched: 4 row(s)
hive (flink)> use flink;
OK
Time taken: 0.025 seconds
hive (flink)> show tables;
OK
tab_name
log_user_cart
Time taken: 0.026 seconds, Fetched: 1 row(s)
hive (flink)> select * from log_user_cart;
FAILED: SemanticException Line 0:-1 Invalid column reference 'TOK_ALLCOLREF'
hive (flink)> 在Hive中可以看到sql-client中创建的数据库和表,但是无法查询该数据表。
在sql-client中查询该数据表:
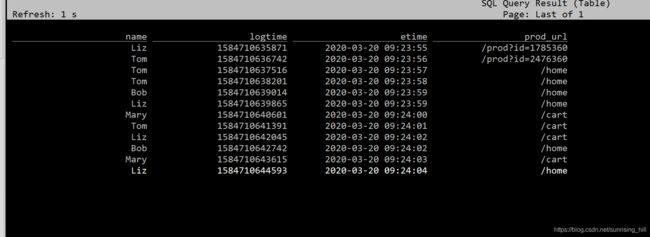
3、代码中访问HiveCatalog:
val settings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build()
val tableEnv = TableEnvironment.create(settings)
val name = "myhive"
val defaultDatabase = "gmall"
val hiveConfDir = "/apps/hive/conf" // a local path
val version = "2.3.5"
val hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version)
tableEnv.registerCatalog("myhive", hive)
注意:使用时,需要从hive安装目录的lib下拷贝jar包到flink的lib目录,需要拷贝的jar包包括:
167761 Mar 19 20:50 antlr-runtime-3.5.2.jar
366748 Mar 19 20:48 datanucleus-api-jdo-4.2.4.jar
2016766 Mar 19 20:48 datanucleus-core-4.1.17.jar
1908681 Mar 19 20:48 datanucleus-rdbms-4.1.19.jar
74416 Mar 20 20:57 flink-avro-1.10.0.jar
357555 Mar 19 20:33 flink-connector-hive_2.11-1.10.0.jar
81579 Mar 20 20:54 flink-connector-kafka_2.11-1.10.0.jar
107027 Mar 20 21:01 flink-connector-kafka-base_2.11-1.10.0.jar
37311 Mar 20 20:55 flink-csv-1.10.0.jar
110055308 Feb 8 02:54 flink-dist_2.11-1.10.0.jar
37966 Mar 20 20:56 flink-hadoop-fs-1.10.0.jar
43007 Mar 18 23:45 flink-json-1.10.0.jar
43317025 Mar 18 23:45 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
19301237 Feb 8 02:54 flink-table_2.11-1.10.0.jar
55339 Mar 19 20:34 flink-table-api-scala-bridge_2.11-1.10.0.jar
22520058 Feb 8 02:54 flink-table-blink_2.11-1.10.0.jar
241622 Mar 19 00:28 gson-2.8.5.jar
34271938 Mar 19 20:32 hive-exec-2.3.5.jar
348625 Mar 19 22:27 jackson-core-2.10.1.jar
249790 Mar 19 20:50 javax.jdo-3.2.0-m3.jar
2736313 Mar 18 23:45 kafka-clients-2.3.0.jar
489884 Sep 2 2019 log4j-1.2.17.jar
1007502 Mar 19 20:49 mysql-connector-java-5.1.47.jar
9931 Sep 2 2019 slf4j-log4j12-1.7.15.jar有些jar包需要手动去maven官网下载,如gson-2.8.5.jar,只需在百度输入maven gson搜索即可