快速理解Raft之日志复制(肝了两千五百字)
一、日志复制背景
当raft集群选出领导者的时候,集群就开始提供服务了。这个时候,会有客户端向raft集群发出请求。请求里面会包含一个可以被raft状态机执行的命令。leader会把这个命令作为一个entry(理解成raft中的一小段日记就可以)首先添加到自己的日志中,然后并发的向followeri节点发送请求,让他们复制这一小段日志。当日志安全复制成功后,leader将这段日志applied到自己的状态及,然后把命令的执行结果返回给客户端。如果在日志的复制过程中,有节点因为网络原因或者什么七七八八的原因,导致日志没有复制成功。leader会一直给这个节点发送append请求,直到复制成功。
下面这张图就描述了raft集群中日志的组成结构。每一个小方框就是entry,小方框里面的数字就是entry创建时对应的任期。每一个小方框自己对应的位置就是logIndex。
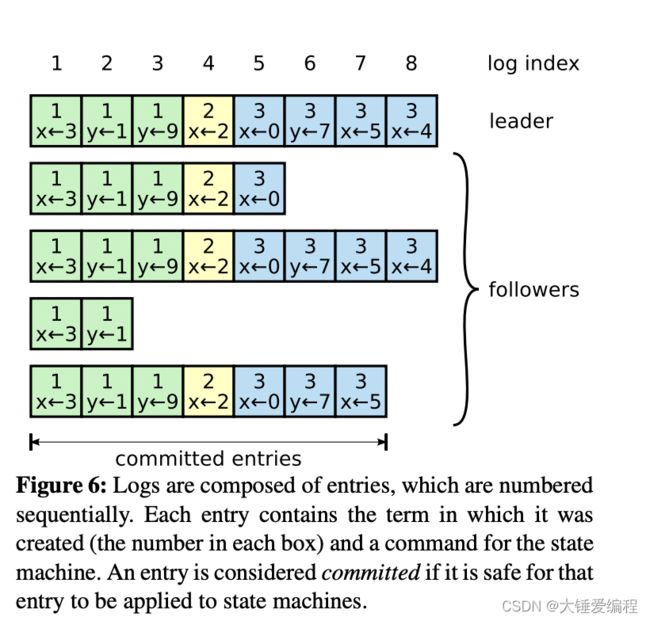
leader会对收到的entry进行判断,判断什么时候是安全的,是可以把这个entry应用到状态机上。可以被应用到状态机上的entry被称为committed。raft算法保证提交的entry都是持久化存储的,并且保证所有可用的状态机都会执行这个entry。
二、什么是entry的committed状态
entry的committed的状态是由entry在raft集群中有多少个副本而决定的。如果该entry有多数副本,则判断这个entry是committed状态。从figure6中可以看到index为5、6、7的entry都是committed的,因为这几个entry在raft集群中都有三个副本以上,占大多数。也就是说如果index为7的entry是committed状态的,那么index在7前面的entry都是committed状态,即便这个entry是其他leader创建的。
于此同时,leader会通过AppendEntries RPCs向其他节点通知,他目前提交的entry。如果其他节点发现自己的entry滞后于leader的entry,那么其他会按照log index顺序拉取entry,保证自己的log和leader是一致的。
三、raft 关于日志的两个特性
1、两个entry的index和term相同的话,那么他们包含的command一定是相同的
2、两个entry的index和term相同的话,那么他们在他们之前的entry一定都是相同的。
第一个特性:leader在给定的term和index上只能创建一个entry,而且entry不被允许修改位置。
第二个特性:通过AppendEntries执行的简单一致性来保证。
简单介绍一下通过这个AppendEntries来保证一致性。
首先从leader发出的AppendEntries中有两个比较重要的参数:
prevLogIndex :新entry对应的前一个entry对应的LogIndex(也就是leader当前日志中最后一个entry对应的log index)
prevLogTerm : 新entry对应的前一个entry对应的term(也就是leader当前日志中最后一个entry对应的log term)
follower收到AppendEntries请求后,查看自己的log当中有没有prevLogIndex、prevLogTerm对应的entry。followed发现自己日志没有的话,就说明自己的日志滞后当前的leader,拒绝将entries添加到自己的log中。

这种一致性检查归纳起来说就是两点:
1、初始时刻,也就是没有日志空状态的时候,满足日志匹配的特性。
2、后续有日志添加时,通过AppendEntries实现的一致性机制来保证配日志匹配的特性。
最后达到的效果就是,只要AppendEntries返回success的时候,leader就知道这个follower和自己的日志是一致的。
四、raft日志冲突的原因以及常见场景
一般来说,follower和leader的日志总是一致的。说到这就有了但是,那就是leader和follower的突然宕机会让日志发生冲突,也就是follower的日志和leader的日志对不上了,follower上的日志相对于leader说有可能多也有可能少。而且这种对不上的情况可能会蔓延到多个周期。
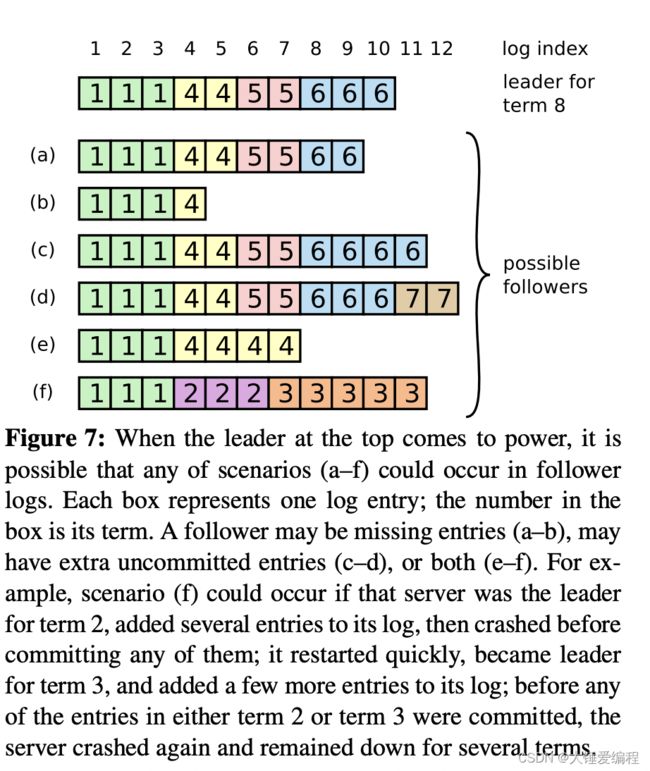
上面这张图就讲了raft日志冲突的场景,首先说明方框中的数字代表任期。下面介绍一下日志冲突的场景:
- a,b场景表示的意思是follower和leader日志相比缺失entries。
- c,d,e,f场景表示和leader日志保持同步的同时,还有额外的未提交的entries
- f场景比较特殊,就是在任期二、任期三的时候都成为了领导,都接收到了新的entries,但是这些entries还没有提交的时候,就下台了。f对应的follower因为打击太大,没有加入raft群聊,导致自身的log一致没有更新。
五、日志冲突的解决办法
整体来说就是leader的日志保持不动,然后强制更新follower上的日志和leader保持一致。主要的操作流程就以下两步:
1、通过AppendEntries 找到日志冲突点,就是follower从哪个位置开始和leader的日志不一致了
2、leader把follower日志冲突点以后的日志强行刷新成自己的。
具体细节就是leader会向follower不间断的发送AppendEntries请求,如果follower返回false的话,那就证明follower和leader不一致。那么leader发送的AppendEntries就会把 index减1再次发送,直至和follower匹配上。匹配成功以后,通过AppendEntries请求将leader上的entries同步至follower。
论文中有提到的一个优化手段就是AppendEntries请求返回失败同时,follower也返回冲突entry所在的任期和所在任期的第一个entry对应的logIndex。通过这两个信息,leader调整下次发送的prevLogIndex和prevLogTerm,可以减少rpc请求。