卷积神经网络与Pytorch实践(一)
卷积神经网络是一种以图像识别为中心,并且在多个领域得到广泛应用的深度学习方法,如目标检测、图像分割、文本分类等。
目录
1.卷积神经网络的基本单元
2.经典的卷积神经网络
1.LeNet-5
2.AlexNet
3.VGG
4.Inception
5.TextCNN
3.卷积神经网络示例——Fashion-MNIST图片分类
1.准备数据集、定义数据加载器
2.对测试集进行处理
3.定义网络结构
4.定义训练函数
5.定义优化器、损失函数
6.对模型进行训练,并可视化
7.该案例的完整代码
1.卷积神经网络的基本单元
之前已经介绍了图像的二维卷积,下面再来介绍一下空洞卷积、转置卷积以及应用于NLP任务的二维卷积运算过程。
空洞卷积:空洞卷积可以认为是基于普通的卷积操作的一种变形,主要用于图像分割。相对于普通卷积而言,空洞卷积通过在卷积核中添加空洞(0元素),从而增大感受野,获取更多的信息。感受野可以理解为在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小。通俗的解释就是特征映射( feature map)上的一个点对应输入图上的区域大小。空洞卷积的示意图如下图所示。

图( a)对应3×3的1-空洞卷积运算,卷积核和普通的卷积核一样(没有0元素)。图(b)对应3×3的2-空洞卷积运算,实际的卷积核大小还是3×3,但是空洞为1,这样卷积核就会扩充为一个7×7的图像块,但只有9个红色的点会有权重取值进行卷积操作,也可以理解为卷积核的大小为7×7,但只有图中的9个点的权重不为0,其余均为0。实际进行卷积操作的权重只有3×3=9个,但这个卷积核的感受野已经增大到了7×7。图(c)是4-空洞卷积操作,能够作用于15×15的感受野区域,即卷积核的大小为15×15,但只有图中的9个点的权重不为0,其余都为0。
转置卷积:转置卷积的主要作用是将特征图放大恢复到原来的尺寸,其与原有的卷积操作计算方法上并没有差别,而主要区别是在于,转置卷积是卷积的反向过程,即卷积操作的输入作为转置卷积的输出,卷积操作的输出作为转置卷积的输入。转置卷积可以保证在尺寸上做到卷积的反向过程,但是内容上并不能保证完全做到卷积的反向过程。针对二维转置卷积其工作示意图如下图所示。

上图展示的是针对一个2×3的输出,在使用2×2的卷积核时,使用转置卷积,获得3×4的特征映射。
NLP中的二维卷积:针对自然语言的词嵌入(Embedding)进行二维卷积,是利用卷积神经网络对自然语言进行分类的关键步骤。在NLP中,由于词嵌入层中每一行都表示一个词语,即每个词语都是由一个向量(词向量)表示的,当提取句子中有利于分类的特征时,需要从词语或字符级别提取,也就是说卷积核的宽度应该覆盖完全单个词向量,即二维卷积的卷积核宽度必须等于词向量的维度。其卷积操作方式如下图所示。

池化操作的一个重要的目的就是对卷积后得到的特征映射进行降维。常用的有最大值池化和平均值池化,全连接层通常会放在卷积神经网络的最后几层,在整个卷积神经网络中起到“分类器”的作用。在卷积层和全连接层相连接时,需要将卷积层的所有特征映射展开为一个向量,作为全连接网络的输入层,然后与全连接层进行连接。其连接方式如图所示。

图中,全连接层之前有4个2×2的特征映射,在特征映射与第一个全连接层连接之前,需要4个2×2的特征映射展开成一个16×1的列向量,使用该列向量作为输入与全连接层连接即可。
2.经典的卷积神经网络
1.LeNet-5
LeNet-5是最早提出的卷积神经网络,主要用于处理手写字体识别。其网络结构如图所示:
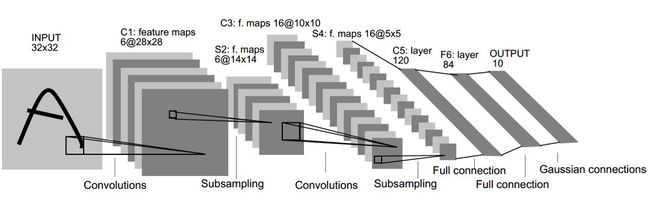
在LeNet-5中,输入的图像为32×32的灰度图像,经过两个卷积层、两个池化层和两个全连接层,最后连接一个输出层。LeNet-5网络的第一层使用了6个5×5的卷积核对图像进行卷积运算,且在卷积操作时不使用填补操作,这样针对一张32×32的灰度图像会输出6个28×28的特征映射。第二层为池化层,使用2×2的池化核,步长大小为2,从而将6个28×28的特征映射转化为6个14×14的特征映射,该层主要是对数据进行下采样。第三层为卷积层,有16个大小为5×5的卷积核,同样在卷积操作时不使用填补操作,将6个14×14的特征映射卷积运算后输出16个10×10的特征映射。第四层为池化层,使用大小为2×2的池化核,步长为2,从而将16个10x10的特征映射转化为16个5×5的特征映射。第五和第六层均为全连接层,且神经元的数量分别为120和84。最后一层为包含10个神经元的输出层。
2.AlexNet
AlexNet模型是一个只用8层的卷积神经网络,有5个卷积层、3个全连接层,在每一个卷积层中包含了一个激活函数ReLU(这也是ReLU激活函数的首次应用)以及局部响应归一化(LRN)处理,卷积计算后通过最大值池化层对特征映射进行降维处理。AlexNet网络结构如图所示:
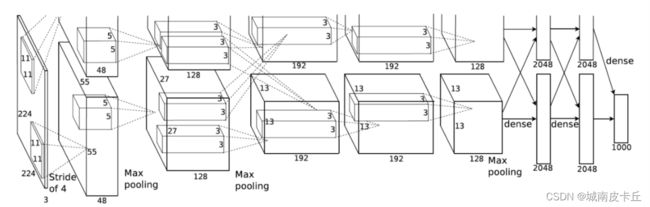
AlexNet网络中输入为RCB图像,卷积层使用的卷积核从11逐渐减小到3,最后三个卷积层使用的卷积核为3×3,而池化层则使用了大小为3×3,步长为2,有重叠的池化,两个全连接层分别包含4096个神经元,最后的输出层使用softmax分类器,包含1000个神经元。AlexNet网络在torchvision库的models模块中,已经包含了预训练好的模型,可以直接使用下面的程序进行调用:
import torchvision.models as models models.AlexNet()
3.VGG
论文Very Deep Convolutional Networks for Large-Scale Image Recognition中,一共提出了四种不同深度层次的卷积神经网络,分别是11、13、16、19层。这些网络的结构如下图所示。
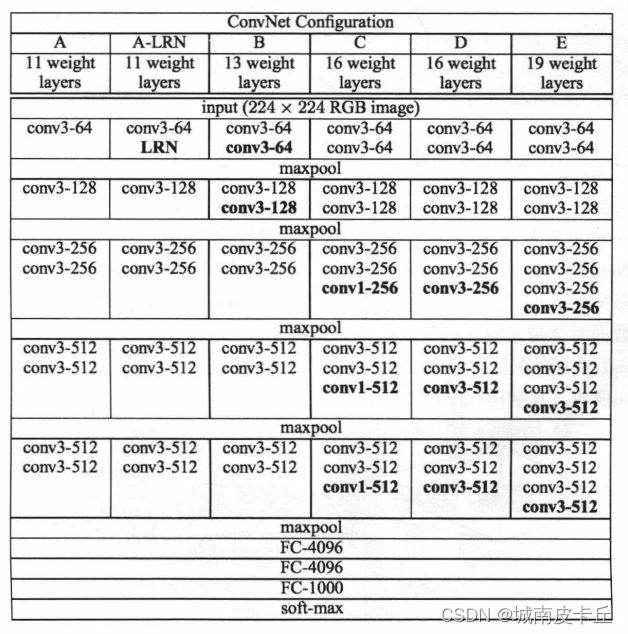
图中,conv3-64表示使用64个3×3的卷积核,maxpool表示使用2×2的最大值池化核,FC-4096表示具有4096个神经元的全连接层。在提到的多种VGG网络结构中,最常用的VGG网络有两种,分别是VGG16(图中的网络结构D)和VGG19(图中的网络结构E)。在多种VCG网络结构中,它们最大的差距就是网络深度的不同。在VGG网络中,通过使用多个较小卷积核(3×3)的卷积层,来代替一个卷积核较大的卷积层。小卷积核是VCG的一个重要特点,VGG的作者认为2个3×3的卷积堆叠获得的感受野大小相当于一个5×5的卷积;而3个3×3卷积的堆叠获取到的感受野相当于一个7×7的卷积。使用小卷积核一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以进一步增加网络的拟合能力。相比AlexNet使用3×3的池化核,在VGG网络中全部采用2×2的池化核。并且VGG网络中具有更多的特征映射,网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,随着通道数的增加,使得VGG网络能够从数据中提取更多的信息。并且VGG网络具有更深的层数,得到的特征映射更宽。常用的VGG16和VGG19网络,在torchvision库中的models模块中,已经包含了预训练好的模型,可以直接使用下面的程序进行调用:
import torchvision.models as models
VGG16=models.vgg16()
VGG19=models.vgg19()4.Inception
即GoogLeNet,是在2014年由Google DeepMind公司的研究员提出的一种全新的深度学习结构,并取得了ILSVRC2014比赛分类项目的第一名。GoogLeNet共有22层,并且没用全连接层,所以使用了更少的参数,在GoogLeNet前的AlexNet、VGG等结构,均通过增大网络的层数来获得更好的训练结果,但更深的层数同时会带来较多的负面效果,如过拟合、梯度消失、梯度爆炸等问题。GoogLeNet则在保证算力的情况下增大网络的宽度和深度,尤其是其提出的Inception模块。其结构如图所示:
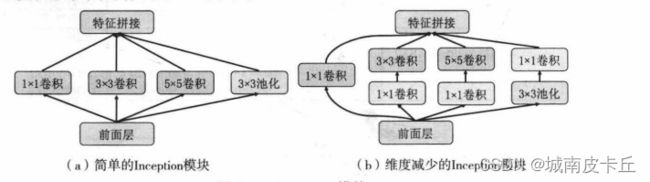
在GoogLeNet中前几层是正常的卷积层,后面则全部用Inception堆叠而成。在论文Going Deeper with Convolutions中给出了两种结构的Inception模块,分别是简单的Inception模块和维度减小的Inception模块。和简单的Inception模块相比,维度减小的Inception模块在3×3卷积的前面、5×5卷积前面和池化层后面添加1×1卷积进行降维,从而使维度变得可控并减少计算量。在GoogLeNet中不仅提出了Inception模块,还在网络中添加了两个辅助分类器,起到增加低层网络的分类能力、防止梯度消失、增加网络正则化的作用。在torchvision库的models模块中,已经包含了预训练好的GoogLeNet模型,可以直接使用下面的程序进行调用:
import torchvision.models as models
GoogLeNet=models.googlenet()5.TextCNN
CNN不仅可以用于图像数据的处理,还可以应用于自然语言分类任务。TextCNN网络是一种利用卷积神经网络进行自然语言处理的网络结构。这类网络常用的结构如图所示:

在网络结构中,针对一个句子的词嵌入使用一层卷积层进行文本信息的提取。在卷积操作时,使用高度为2、3、4的卷积核,每个卷积核有2个,共6个卷积核(注意卷积核的宽度等于词向量的维度,如在图示中卷积核为:2个2×5,2个3×5,2个4x5),6个卷积核对输入的句子进行卷积操作后,会得到6个向量,对此6个向量(卷积后的输出)各取一个最大值进行池化,然后将6个最大值拼接为一个列向量,该列向量即为通过一层卷积操作从句子中提取到的有用信息,并将其和分类器层连接后,即可组成TextCNN的网络结构。
3.卷积神经网络示例——Fashion-MNIST图片分类
下面使用PyTorch搭建一个类似LeNet-5的网络结构,用于Fashion-MNIST数据集的图像分类。针对该问题的分析可以分为数据准备、模型建立以及使用训练集进行训练与使用测试集测试模型的效果。针对卷积网络的建立,将会分别建立常用的卷积神经网络与基于空洞卷积的卷积神经网络。
1.准备数据集、定义数据加载器
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import copy
import time
import torch
import torch.nn as nn
from torch.optim import Adam
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
#准备Fashion-MNIST数据集
train_data=FashionMNIST(
root="./Dataset/FashionMNIST",#数据集的路径
train=True,#只使用训练数据集
transform=transforms.ToTensor(),
download=False
)
#定义一个数据加载器
train_loader=Data.DataLoader(
dataset=train_data,#使用的数据集
batch_size=64,#批处理样本的大小
shuffle=True,#每次迭代前打乱数据
num_workers=0
)2.对测试集进行处理
#对测试集数据进行处理
test_data=FashionMNIST(
root='./Dataset/FashionMNIST',
train=False,
download=False
)
test_data_x=test_data.data.type(torch.FloatTensor)/255.0
test_data_x=torch.unsqueeze(test_data_x,dim=1)
test_data_y=test_data.targets
在对训练集进行处理后,下面对测试数据集进行处理。导入测试数据集后,将所有的样本处理为一个整体,看作一个batch用于测试
3.定义网络结构
定义的卷积神经网络的结构:2个卷积层,分别包含16个和32个3×3卷积核,并且卷积后使用ReLU激活函数进行激活,两个池化层均为平均值池化,而两个全连接层分别有256和128个神经元,最后的分类器则包含了10个神经元。
class MyConvNet(nn.Module):
def __init__(self):
super(MyConvNet, self).__init__()
#定义第一个卷积层
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=1,#输入的feature map
out_channels=16,#输出的feature map
kernel_size=3,#卷积核尺寸
stride=1,#卷积核步长
padding=1,#卷积核步长
),#(1*28*28)->(16*28*28)
nn.ReLU(),#激活函数
nn.AvgPool2d(
kernel_size=2,#平均池化层,2*2
stride=2,#池化步长为2
),#池化后:(16*28*28)->(16*14*14)
)
# 定义第二个卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(16,32,3,1,0),#卷积操作:(16*14*14)->(32*12*12)
nn.ReLU(),#激活函数
nn.AvgPool2d(2,2)#最大值池化操作:(32*12*12)->(32*6*6)
)
self.classify=nn.Sequential(
nn.Linear(32*6*6,256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,10)
)
#定义网络的前向传播
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x)
x=x.view(x.size(0),-1)
output=self.classify(x)
return output
#输出我们的网络结构
MyConvNet=MyConvNet()4.定义训练函数
为了训练定义好的网络结构,还需要定义一个train_model()函数,该函数可以用训练数据集来训练。训练数据整体包含60000张图像,938个batch,可以使用80%的batch用于模型的训练,20%的batch用于模型的验证,所以在定义train_model()函数时,应该包含模型的训练和验证两个过程。train_model()函数的程序如下所示:
#定义网络的训练过程函数
def train_model(model,traindataloader,train_rate,criterion,optimizer,num_epochs=25):
#计算训练使用的batch数量
batch_num=len(traindataloader);
train_batch_num=round(batch_num*train_rate)
#复制模型参数
best_model_wts=copy.deepcopy(model.state_dict())
best_acc=0.0
train_loss_all=[]
train_acc_all=[]
val_loss_all=[]
val_acc_all=[]
since=time.time()
for epoch in range(num_epochs):
#每个epoch有两个训练阶段
train_loss=0.0
train_corrects=0
train_num=0
val_loss=0.0
val_corrects=0
val_num=0
for step,(b_x,b_y) in enumerate(traindataloader):
if step < train_batch_num:
model.train()#设置模型为训练模式
output=model(b_x)
pre_lab=torch.argmax(output,1)
loss=criterion(output,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss+=loss.item() * b_y.size(0)
train_corrects+=torch.sum(pre_lab==b_y.data)
train_num+=b_x.size(0)
else:
model.eval()#设置模型为评估形式
output=model(b_x)
pre_lab=torch.argmax(output,1)
loss=criterion(output,b_y)
val_loss+=loss.item() * b_x.size(0)
val_corrects +=torch.sum(pre_lab==b_y.data)
val_num+=b_x.size(0)
#计算一个epoch在训练集和测试集上的损失和精度
train_loss_all.append(train_loss / train_num)
train_acc_all.append(train_corrects.double().item()/train_num)
val_loss_all.append(val_loss/val_num)
val_acc_all.append(val_corrects /val_num)
#拷贝模型最高精度下的参数
if val_acc_all[-1] > best_acc:
best_acc=val_acc_all[-1]
best_model_wts=copy.deepcopy(model.state_dict())
time_use=time.time() -since
#使用最好模型的参数
model.load_state_dict(best_model_wts)
train_process=pd.DataFrame(
data={"epoch":range(num_epochs),
"train_loss_all":train_loss_all,
"val_loss_all":val_loss_all,
"train_acc_all":train_acc_all,
"val_acc_all":val_acc_all}
)
return model,train_processtrain_model()函数通过train_batch_num确定用于训练的batch数量,并且在每轮的迭代中,如果step < train_batch_num,则进入训练模式,否则进入验证模式。在模型的训练和验证过程中,分别输出当前的损失函数的大小和对应的识别精度,并将它们保存在列表汇总中,最后组成数据表格train_process输出。为了保存模型最高精度下的训练参数,使用copy.deepcopy()函数将模型最优的参数保存在best_model_wts中,最终将所有的训练结果使用model.load_state_dict(best_model_wts)将最优的参数赋值给最终的模型
5.定义优化器、损失函数
optimizer=torch.optim.Adam(MyConvNet.parameters(),lr=0.0003)
criterion=nn.CrossEntropyLoss()#损失函数
使用Adam优化器,损失函数为交叉嫡函数。
6.对模型进行训练,并可视化
train_model()将训练集train_loader的80%用于训练,20%用于测试,共训练25轮。训练结束之后,使用折线图将模型训练过程中的精度和损失函数进行可视化
MyConvNet,train_process=train_model(MyConvNet,train_loader,0.8,criterion,optimizer,num_epochs=25)
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(train_process.epoch,train_process.train_loss_all,"ro-",label="Train loss")
plt.plot(train_process.epoch,train_process.val_loss_all,"bs-",label="Val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1,2,2)
plt.plot(train_process.epoch,train_process.train_acc_all,"ro-",label="Train acc")
plt.plot(train_process.epoch,train_process.val_acc_all,"bs-",label="Val acc")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
从图中可以发现模型在训练过程中,损失函数在训练集上迅速减小,在验证集上先减小然后逐渐收敛到一个很小的区间,说明模型已经稳定。在训练集上的精度一直在增大,而在验证集上的精度收敛到一个小区间内。
从输出结果可以发现,模型在测试集上的预测精度为为90.64%。针对测试样本的预测结果,使用混淆矩阵表示,并将其可视化,观察其在每类数据上的预测情况。
MyConvNet.eval()
output=MyConvNet(test_data_x)
pre_lab=torch.argmax(output,1)
acc=accuracy_score(test_data_y,pre_lab)
print("在测试集上的预测精度为:",acc)
conf_mat=confusion_matrix(test_data_y,pre_lab)
df_cm=pd.DataFrame(conf_mat,index=class_label,columns=class_label)
heatmap=sns.heatmap(df_cm,annot=True,fmt="d",cmap="YlGnBu")
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(),rotation=0,ha="right")
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(),rotation=45,ha="right")
plt.xlabel('True label')
plt.ylabel('Predicted label')
plt.show()

从图中可以发现,最容易预测发生错误的是T-shirt和Shirt,相互预测出错的样本量超过了50个
7.该案例的完整代码
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import copy
import time
import torch
import torch.nn as nn
from torch.optim import Adam
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
#准备Fashion-MNIST数据集
train_data=FashionMNIST(
root="./Dataset/FashionMNIST",#数据集的路径
train=True,#只使用训练数据集
transform=transforms.ToTensor(),
download=False
)
#定义一个数据加载器
train_loader=Data.DataLoader(
dataset=train_data,#使用的数据集
batch_size=64,#批处理样本的大小
shuffle=True,#每次迭代前打乱数据
num_workers=0
)
class_label=train_data.classes
"""
#对数据集中每个图像进行可视化处理
for step,(b_x,b_y) in enumerate(train_loader):
if step>0:
break
batch_x=b_x.squeeze().numpy()
batch_y=b_y.numpy()
class_label=train_data.classes
class_label[0]="T-shirt"
plt.figure(figsize=(12,5))
for i in np.arange(len(batch_y)):
plt.subplot(4,16,i+1)
plt.imshow(batch_x[i,:,:],cmap=plt.cm.gray)
plt.title(class_label[batch_y[i]],size=9)
plt.axis("off")
plt.subplots_adjust(wspace=0.05)
"""
#对测试集数据进行处理
test_data=FashionMNIST(
root='./Dataset/FashionMNIST',
train=False,
download=False
)
test_data_x=test_data.data.type(torch.FloatTensor)/255.0
test_data_x=torch.unsqueeze(test_data_x,dim=1)
test_data_y=test_data.targets
#搭建卷积神经网络
"""
卷积神经网络结构:2个卷积层,分别包含16个和32个3×3卷积核,
并且卷积后使用ReLU激活函数进行激活,两个池化层均为平均值池化,
而两个全连接层分别有256和128个神经元,最后的分类器则包含了10个神经元。
"""
class MyConvNet(nn.Module):
def __init__(self):
super(MyConvNet, self).__init__()
#定义第一个卷积层
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=1,#输入的feature map
out_channels=16,#输出的feature map
kernel_size=3,#卷积核尺寸
stride=1,#卷积核步长
padding=1,#卷积核步长
),#(1*28*28)->(16*28*28)
nn.ReLU(),#激活函数
nn.AvgPool2d(
kernel_size=2,#平均池化层,2*2
stride=2,#池化步长为2
),#池化后:(16*28*28)->(16*14*14)
)
# 定义第二个卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(16,32,3,1,0),#卷积操作:(16*14*14)->(32*12*12)
nn.ReLU(),#激活函数
nn.AvgPool2d(2,2)#最大值池化操作:(32*12*12)->(32*6*6)
)
self.classify=nn.Sequential(
nn.Linear(32*6*6,256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,10)
)
#定义网络的前向传播
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x)
x=x.view(x.size(0),-1)
output=self.classify(x)
return output
#输出我们的网络结构
MyConvNet=MyConvNet()
#定义网络的训练过程函数
def train_model(model,traindataloader,train_rate,criterion,optimizer,num_epochs=25):
#计算训练使用的batch数量
batch_num=len(traindataloader);
train_batch_num=round(batch_num*train_rate)
#复制模型参数
best_model_wts=copy.deepcopy(model.state_dict())
best_acc=0.0
train_loss_all=[]
train_acc_all=[]
val_loss_all=[]
val_acc_all=[]
since=time.time()
for epoch in range(num_epochs):
#每个epoch有两个训练阶段
train_loss=0.0
train_corrects=0
train_num=0
val_loss=0.0
val_corrects=0
val_num=0
for step,(b_x,b_y) in enumerate(traindataloader):
if step < train_batch_num:
model.train()#设置模型为训练模式
output=model(b_x)
pre_lab=torch.argmax(output,1)
loss=criterion(output,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss+=loss.item() * b_y.size(0)
train_corrects+=torch.sum(pre_lab==b_y.data)
train_num+=b_x.size(0)
else:
model.eval()#设置模型为评估形式
output=model(b_x)
pre_lab=torch.argmax(output,1)
loss=criterion(output,b_y)
val_loss+=loss.item() * b_x.size(0)
val_corrects +=torch.sum(pre_lab==b_y.data)
val_num+=b_x.size(0)
#计算一个epoch在训练集和测试集上的损失和精度
train_loss_all.append(train_loss / train_num)
train_acc_all.append(train_corrects.double().item()/train_num)
val_loss_all.append(val_loss/val_num)
val_acc_all.append(val_corrects /val_num)
#拷贝模型最高精度下的参数
if val_acc_all[-1] > best_acc:
best_acc=val_acc_all[-1]
best_model_wts=copy.deepcopy(model.state_dict())
time_use=time.time() -since
#使用最好模型的参数
model.load_state_dict(best_model_wts)
train_process=pd.DataFrame(
data={"epoch":range(num_epochs),
"train_loss_all":train_loss_all,
"val_loss_all":val_loss_all,
"train_acc_all":train_acc_all,
"val_acc_all":val_acc_all}
)
return model,train_process
optimizer=torch.optim.Adam(MyConvNet.parameters(),lr=0.0003)
criterion=nn.CrossEntropyLoss()#损失函数
MyConvNet,train_process=train_model(MyConvNet,train_loader,0.8,criterion,optimizer,num_epochs=25)
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(train_process.epoch,train_process.train_loss_all,"ro-",label="Train loss")
plt.plot(train_process.epoch,train_process.val_loss_all,"bs-",label="Val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1,2,2)
plt.plot(train_process.epoch,train_process.train_acc_all,"ro-",label="Train acc")
plt.plot(train_process.epoch,train_process.val_acc_all,"bs-",label="Val acc")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
MyConvNet.eval()
output=MyConvNet(test_data_x)
pre_lab=torch.argmax(output,1)
acc=accuracy_score(test_data_y,pre_lab)
print("在测试集上的预测精度为:",acc)
conf_mat=confusion_matrix(test_data_y,pre_lab)
df_cm=pd.DataFrame(conf_mat,index=class_label,columns=class_label)
heatmap=sns.heatmap(df_cm,annot=True,fmt="d",cmap="YlGnBu")
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(),rotation=0,ha="right")
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(),rotation=45,ha="right")
plt.xlabel('True label')
plt.ylabel('Predicted label')
plt.show()由于本篇文章篇幅有限,下一篇文章我们继续用PyTorch搭建一个类似LeNet-5的网络结构,不过我们要使用空洞卷积核搭建一个空洞卷积神经网络。