【NLP】第 6 章 :微调预训练模型
到目前为止,我们已经了解了如何使用包含预训练模型的huggingface API 来创建简单的应用程序。如果您可以从头开始并仅使用您自己的数据来训练您自己的模型,那不是很棒吗?
如果您没有大量空闲时间或计算资源可供使用,那么使用迁移学习 是最有效的策略。与在训练模型时从头开始相比,使用 Hugging Face 的迁移学习有两个主要优点。
正如我们在第4章中所述,像GPT3 这样的模型需要大量的基础设施资源来训练。这超出了我们大多数人的能力。那么我们如何以更灵活的方式使用这些模型,而不仅仅是通过下载预训练模型来使用它们呢?答案在于使用我们拥有的额外数据对这些模型进行微调。与从头开始训练完整的大型语言模型相比,这将需要很少的资源并且很容易实现。
要将基本模型转变为能够产生可靠结果的模型,需要投入大量时间和资源。由于迁移学习 ,您可以放弃费力的训练步骤,只需花费少量时间来根据您的特定要求调整数据集。
事实上,Hugging Face 的预训练模型能够在各种领域的任务中表现出色,甚至不需要额外的微调。人们很可能也可以在零样本学习 场景中使用这些模型,但是如果有一个特定的数据集,那么我们的好朋友 huggingface API 会为我们提供微调这些现有模型所需的抽象.
因此,我们基本上可以认为迁移学习 是训练的一种捷径。只需使用预训练的语言模型,您就可以在计算需求方面节省数万美元和数千小时。你应该坚持迁移学习,除非你正在处理的任务非常具体并且无法使用已经存在的模型来解决。
我们现在可以继续使用Hugging Face 进行微调指南 ,因为我们对迁移学习的应用和优势有了更好的理解。
微调的工作流程 如下所示:
从 huggingface 中选择适合您的用例需求的预训练模型。
额外的自定义数据集必须遵守 huggingface 数据集规范,因此我们需要预处理我们的数据,使其符合所需的格式。
将数据集上传到 Colab、S3 或任何其他存储。
使用 huggingface 的 Trainer API 微调现有模型。
在本地保存模型或将其上传到 huggingface 存储库。
有了一些基本的想法,让我们开始使用 Hugging Face 库进行一些迁移学习。
在微调阶段,大部分神经结构 被冻结。这意味着我们只调整输出层的权重。由于我们已经在前面的章节中介绍了分词器,因此我们将在此处简要概述 huggingface 数据集,这是本章最重要的结构。了解数据集 API 后,我们将继续通过迁移学习将自定义数据集用于预训练模型。
数据集
在本节中,我们描述了 huggingface 的基本数据集 构造及其一些基本功能。
您在任何机器学习项目的整个过程中使用的数据都将非常重要。真正的准确性不仅取决于数量,还取决于所使用数据的质量,无论您使用何种算法或模型,这一点都是正确的。
访问大型数据集有时可能是一项具有挑战性的工作。以适当的方式抓取、积累然后清理这些数据的过程可能会花费大量时间。Hugging Face 对于对 NLP 以及图像和音频处理感兴趣的人来说是幸运的,它带有一个已经准备好使用的数据集的中央存储库。在以下段落中,我们将简要介绍如何使用此数据集 模块来为您的项目选择和准备合适的数据集。
要安装数据集库,请使用以下命令:
!pip 安装数据集
在阅读数据集 存储库的文档时,我们发现有几种主要方法。第一种方法是我们能够用来调查现成的数据集列表的方法。您应该会看到处理近 6800 个不同数据集的选项,所有这些数据集当前都可用:
from datasets import list_datasets, load_dataset, list_metrics, load_metric
# 打印所有可用的数据集
print(len(list_datasets()))DatasetDict({ train: Dataset({ features: ['text', 'label'], num_rows: 25000 }) test: Dataset({ features: ['text', 'label'], num_rows: 25000 }) unsupervised: 数据集({ features: ['text', 'label'], num_rows: 50000 }) })
它构成了一个包含训练、测试和无监督数据集的字典 ,每个数据集都具有特征和 num_rows 作为值。这里,示例取自 IMDB 数据集,因此我们将对其进行情感分析的文本也取自 IMDB。
让我们访问火车数据集:
dataset['train'][2]dataset['train'][2]
{'label': 0, 'text': "If only to avoid making this type of film in the future. This film is interesting as an experiment but tells no cogent story.
One might feel virtuous for sitting thru it because it touches on so many IMPORTANT issues but it does so without any discernable motive. The viewer comes away with no new perspectives (unless one comes up with one while one's mind wanders, as it will invariably do during this pointless film).
One might better spend one's time staring out a window at a tree growing.
"}
描述数据集:
dataset['train'].description我们得到以下 输出:
Large Movie Review Dataset.\nThis is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing. There is additional unlabeled data for use as well.
列出数据集的特征:
dataset['train'].features我们可以看到有两个特点:
{'label': ClassLabel(num_classes=2, names=['neg', 'pos'], id=None), 'text': Value(dtype='string', id=None)}
在某些情况下,您可能不想处理使用 Hugging Face 数据集之一。除了其他类型的文件之外,此数据集对象仍然能够加载本地存储的CSV 文件。 例如,如果您想使用 CSV 文件,您可以轻松地将此信息连同本地计算机上 CSV 文件的路径传递到加载数据集方法。
微调预训练模型
现在既然我们了解了数据集构造,就该使用我们自己的数据集在预训练模型上应用一些迁移学习了。在下文中,我们将展示如何使用 IMDB 数据集微调预训练模型的示例。
我们将微调方面分为两部分。训练部分是我们将使用 huggingface 的Trainer API 微调模型并保存的地方。另一部分是推理部分,我们将在其中加载这个微调模型以实现推理。
微调训练
首先,使用以下命令安装转换 器和数据集:
!pip install datasets transformers接下来,加载 IMDB 数据集:
from datasets import load_dataset
dataset = load_dataset("imdb")
dataset["train"][100]以下是评论范例:
{'label': 0, 'text': "Terrible movie. Nuff Said.
These Lines are Just Filler. The movie was bad. Why I have to expand on that I don't know. This is already a waste of my time. I just wanted to warn others. Avoid this movie. The acting sucks and the writing is just moronic. Bad in every way. Even that was ruined though by a terrible and unneeded rape scene. The movie is a poorly contrived and totally unbelievable piece of garbage.
OK now I am just going to rag on IMDb for this stupid rule of 10 lines of text minimum. First I waste my time watching this offal. Then feeling compelled to warn others I create an account with IMDb only to discover that I have to write a friggen essay on the film just to express how bad I think it is. Totally unnecessary."}
接下来,我们需要使用 BERT 分词器对加载的数据集进行分词。 第一步是在Google Colab 中新建一个 Jupyter notebook,逐行复制以下代码:
from transformers import AutoTokenizer
brt_tkn = AutoTokenizer.from_pretrained("bert-base-cased")
def generate_tokens_for_imdb(examples):
return brt_tkn(examples["text"], padding="max_length", truncation=True)
tkn_datasets = dataset.map(generate_tokens_for_imdb, batched=True)上述代码产生 以下输出:
loading configuration file https://huggingface.co/bert-base-cased/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/a803e0468a8fe090683bdc453f4fac622804f49de86d7cecaee92365d4a0f829.a64a22196690e0e82ead56f388a3ef3a50de93335926ccfa20610217db589307
Model config BertConfig {
"_name_or_path": "bert-base-cased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.20.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 28996
}
loading file https://huggingface.co/bert-base-cased/resolve/main/vocab.txt from cache at /root/.cache/huggingface/transformers/6508e60ab3c1200bffa26c95f4b58ac6b6d95fba4db1f195f632fa3cd7bc64cc.437aa611e89f6fc6675a049d2b5545390adbc617e7d655286421c191d2be2791
loading file https://huggingface.co/bert-base-cased/resolve/main/tokenizer.json from cache at /root/.cache/huggingface/transformers/226a307193a9f4344264cdc76a12988448a25345ba172f2c7421f3b6810fddad.3dab63143af66769bbb35e3811f75f7e16b2320e12b7935e216bd6159ce6d9a6
loading file https://huggingface.co/bert-base-cased/resolve/main/added_tokens.json from cache at None
loading file https://huggingface.co/bert-base-cased/resolve/main/special_tokens_map.json from cache at None
loading file https://huggingface.co/bert-base-cased/resolve/main/tokenizer_config.json from cache at /root/.cache/huggingface/transformers/ec84e86ee39bfe112543192cf981deebf7e6cbe8c91b8f7f8f63c9be44366158.ec5c189f89475aac7d8cbd243960a0655cfadc3d0474da8ff2ed0bf1699c2a5f
loading configuration file https://huggingface.co/bert-base-cased/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/a803e0468a8fe090683bdc453f4fac622804f49de86d7cecaee92365d4a0f829.a64a22196690e0e82ead56f388a3ef3a50de93335926ccfa20610217db589307
Model config BertConfig {
"_name_or_path": "bert-base-cased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.20.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 28996
}
一旦我们标记 了数据集,我们将只对 200 个样本进行微调,以便我们可以为了简单起见更快地调整模型。我们鼓励您尝试更多样本:
training_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(200))
evaluation_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(200))加载基于 BERT 的序列分类模型:
from transformers import AutoModelForSequenceClassification
mdl = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2)Transformers 库 包含一个Trainer 类 ,专门用于训练 huggingface transformer 模型。此类使开始训练变得更加简单,而无需手动编写自己的代码。Trainer API 提供日志记录、监控等功能。
在这里,我们通过实例化一个名为 TrainingArguments 的类来提供训练参数 ,该类具有可以试验的所有超参数 。在这种情况下,我们将只使用默认值:
from transformers import TrainingArguments
training_args = TrainingArguments(output_dir="imdb")在训练期间,Trainer 不会自动评估模型的执行情况。如果您希望 Trainer 能够计算和报告指标,则需要向其传递 一个函数。这就是我们将在以下代码段中执行的操作:
import numpy as np
from datasets import load_metric
mdl_metrics = load_metric("accuracy")
def calculate_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return mdl_metrics.compute(predictions=predictions, references=labels)
from transformers import TrainingArguments, Trainer
trng_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch", num_train_epochs=3)实例化一个 Trainer 对象,其中包含您的模型、训练参数、用于训练和测试的数据集 以及评估函数:
Mdl_trainer = Trainer(
model=model,
args=trng_args,
train_dataset=training_dataset,
eval_dataset=evaluation_dataset,
compute_metrics=calculate_metrics,
)训练模型:
trainer.train()图6-1显示了我们用于微调现有预训练模型的 IMDB 数据集的训练 运行。
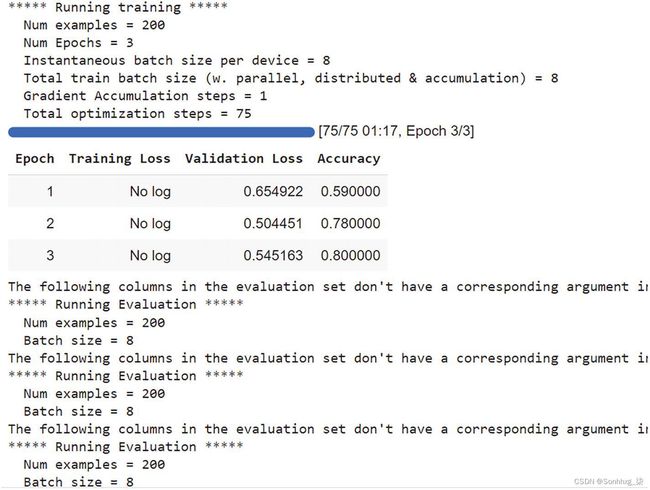
图 6-1 IMDB 数据集 的训练运行以进行微调
保存经过微调的训练模型:
trainer.save_model()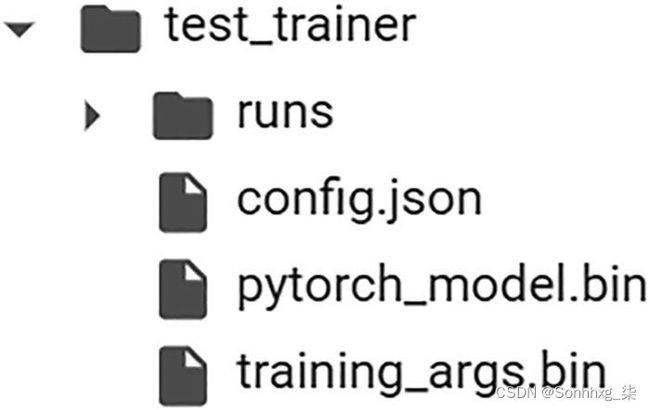
图 6-2 在本地保存模型(我们有一个基于 PyTorch 的模型,扩展名为 .bin)
我们可以看到微调后的模型以名称pytorch_model.bin 保存。
我们可以使用以下代码检查模型的准确性 :
metrics = mdl_trainer.evaluate(evaluation_dataset)
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
图 6-3 根据精度评估 微调模型
推理
一旦我们微调 了模型并保存了它,就可以对训练数据集之外的数据进行推理了。
我们将从路径加载微调模型并使用它进行分类,在本例中是对 IMDB 电影评论的情感分类 :
PATH = 'test_trainer/'
md = AutoModelForSequenceClassification.from_pretrained(PATH, local_files_only=True)
def make_classification(text):
# 分词
inps = brt_tkn(text, padding=True, truncation=True, max_length=512, return_tensors="pt").to("cuda")
# 获取输出
outputs = model(**inps)
# 用于生成概率的 softmax
probablities = outputs[0].softmax(1)
# 获得最佳匹配。
return probablities .argmax()
Here is the first inference:
text = """
This is the show that puts a smile on your face as you watch it. You get in love with each and every character of the show. At the end, I felt eight episode were not enough. Will wait for season 2.
"""
print(make_classification(text))这会产生以下输出:
tensor(1, device='cuda:0')
Output of 1 is positive review
这是第二个推论:
text = """
It was fun to watch but It did not impress that much I think i waste my money popcorn time pizza burgers everything.
Akshay should make only comedy movies these King type movies suits on king like personality of actors Total waste.
"""
print(make_classification(text))这会产生以下 输出:
tensor(0, device='cuda:0')
Output of zero is negative review
概括
在本章中,我们了解了huggingface 数据集 及其不同的功能。我们还学习了如何使用huggingface API 对现有的预训练模型与其他数据集进行微调。