etcd简介
etcd是基于go语言实现,主要用于共享配置和服务发现的组件,最初用于解决集群管理系统中 os 升级时的分布式并发控制、配置文件的存储与分发等问题。因此,etcd是在分布式系统中提供强一致性、高可用性的组件,用来存储少量重要的数据。
安装就不说了,需要从github上clone代码,具体操作较为复杂,如果编译过程中保存,根据具体问题来处理即可。
主要有两种应用场景
注册发现
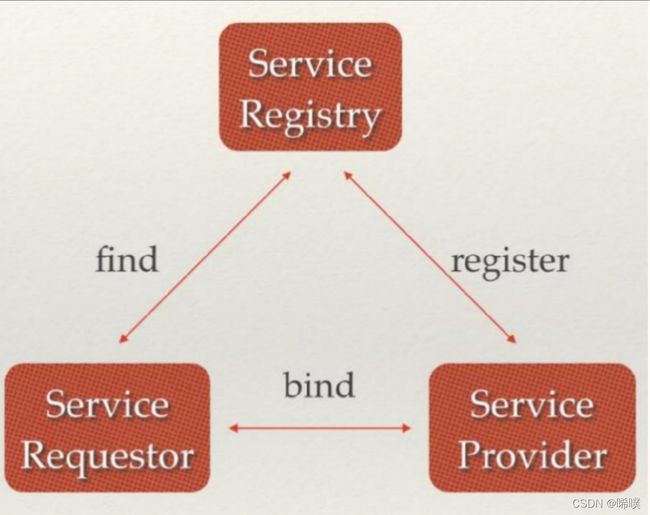
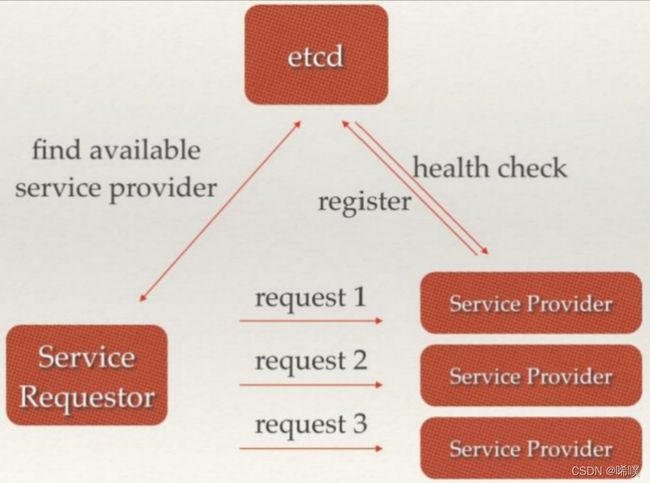
负载均衡
etcd v2与v3版本
这里对比一下两个版本的一些区别,也可以看出v3版本做出了哪些优化:
- v3版本使用 gRPC + protobuf 取代 v2版本的http + json 通信,提高通信效率。gRPC 只需要一条连接,http是每个请求建立一条连接,建立连接会耗费大量时间;protobuf 加解密比json加解密速度得到数量级的提升,包体也更小。
- v3 使用 lease (租约)替换v2中key ttl自动过期机制,后面会介绍。
- v3 是支持事务和多版本并发控制mvcc(解决一致性非锁定读的问题)的磁盘数据库,而 v2 是简单的kv内存数据库
- v3 是扁平的kv结构,v2是类型文件系统的存储结构,类似zookeeper的存储结构。v3版本使用__prefix前缀索引的方式实现了以往v2版本实现的文件系统的存储结构。
etcd 架构
先给个架构图
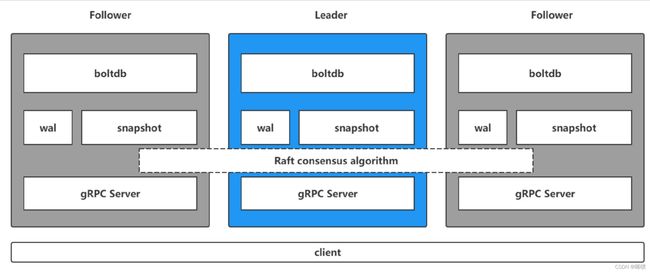
etcd通常采用集群的方式来提供服务:
- gRPC server: 用来处理客户端的连接,也用来处理集群其他节点之间的通信,都是采用protobuf来传输数据。
- raft共识算法:用来保证集群一致性
- wal(write ahead log):预写式日志实现事务日志的标准方法,两段式提交。执行写操作前先写日志,跟 mysql中 redo_log 类似,wal 实现的是顺序写,而若按照 B+ 树写,则涉及到多次 io 以及 随机写。
- snapshot 快照数据:用于其他节点(新加入节点或从节点数据落后太多)同步主节点数据从而达到一致性地状态,类似 redis 中主从复制中 rdb 数据恢复。流程:leader生成 snapshot,leader向follower发送snapshot,follower接收并应用snapshot。
- boltdb是一个单机的支持事务的 kv 存储,etcd 的事务是基于 boltdb 的事务实现的。boltdb 为每一个 key 都创建一个索引(B+树),该 B+ 树存储了 key 所对应的版本数据,所以可以通过这个B+树索引出历史信息。
etcd操作
etcd的基本操作比较简单,那就简单介绍一下。注意是key-val型数据就可以了,可以理解为和redis差不多。注意在命令前面要加etcdctl来执行,如果是windows,前加etcdctl.exe。
增删改查
增加或者修改key
PUT key val
查找key
GET key
# 范围查找,范围是左闭右开区间,key按字典序查找
GET keyfrom keyend
# 前缀索引
GET --prefix key
删除key
DEL key
监听
用来实现监听和推送服务
WATCH key
WATCH --prefix key
当监听的key发生变化(增删改)时,终端会输出这个变化的操作,注意不响应查找操作。
事务
用于分布式锁以及leader选举,保证多个操作的原子性,确保多个节点数据读写的一致性。
# -i表示交互式操作
txn -i
执行命令后,根据提示输入的三段指令
- compare:相当于if
- success requests:相当于then,上面的条件判断为真,则执行这里
- failure request:相当于else,上面的条件为假时执行
租约
是对expire的优化。在etcd中,大量的key设置expire的话,效率会很低。在实际使用过程中发现,很多key的过期时间相等,也就是说,同时过期。针对这种情况,v3版本做了一个优化,设置一个对象,挂接多个key共享一个过期实体,这个实体就被称为租约(lease)。租约过期后,挂接在上面的所有key都会被删除。这样一来,把相同过期时间的key挂接到同一租约上,不同过期时间的key挂接到不同租约上,就把对key的过期管理转变为了对租约的管理。
lease grant 60 # 创建一个租约,这里参数60表示60秒后租约过期
lease keep-alive # 续约,刷新当前租约的时间,重新计时
lease list # 枚举所有的租约
lease revoke # 销毁租约
lease timetolive # 获取租约信息
具体怎么使用呢,创建租约后,将key挂到租约上
# 等号后面是创建这个租约使返回的id值
put hello world --lease=694d7d17eaab280f
此外可以通过续约和监听(watch)实现服务注册发现。前提是客户端对etcd中的某个key进行操作,这个key是挂接在某个租约上的。具体做法:
- 启动一个服务,监听这个key
- 客户端发送心跳包,会续约,不会删除这个key
- 如果超过指定时间未收到心跳包,续约过期,这个key就删除了
- watch服务监听到了delete操作,发现节点删除。此外,如果有新服务注册进来,监听服务也能感知到。
版本号
etcd内部维护了一个版本号,每个key也有相应的版本号,可以通过get key -w命令来查看。
etcd中全局的版本号
- term:leader任期,leader切换时term加一。全局单调递增,64bits
- revision:etcd 键空间版本号,任一key发生变更,则revision加一。全局单调递增,64bits;用来支持MVCC;
单个key中的版本号:
- create_revision:创建数据时,对应的版本号revision
- mod_revision:数据最后一次修改时,对应的版本号revision
- version:当前key自己维护的版本号,标识该val被修改了多少次,注意与revision区分,
这是扯远一点,做个对比。mysql的mvcc是采用undo_log来实现,那为什么etcd却是用B+树呢?
一是因为用途不同。mysql的mvcc主要是为了实现事务的不同隔离级别,而etcd的mvcc主要是为了回滚数据,这是需要持久化的。
二是索引方式不同。etcd是需要范围查找的,例如watch --prev_kv命令需要列举出所有老的key的事件。
存储原理
v3版本的存储结构
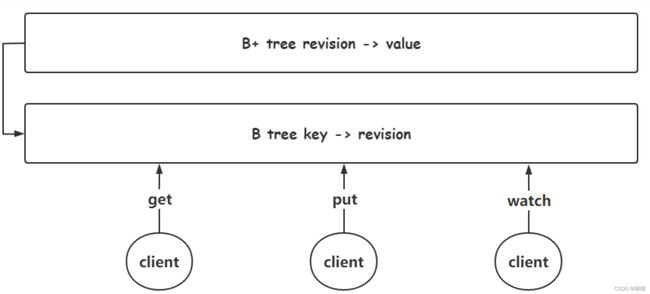
etcd 为每个key创建一个索引,一个索引对应着一个B+树。B+树中,key为 revision,节点存储的值为value。B+ 树存储着 key 的各个版本的信息,从而实现了 etcd 的 mvcc。etcd 不会任由版本信息膨胀,通过定期的 compaction 来清理历史数据。由于B+树中映射的磁盘数据,etcd为了加速索引数据,在内存中维持着一个 B 树,B 树key为 key,value 为该 key 的 revision。一般的操作在B树中进行。这里也对比一下,mysql 为了加快索引数据,采用自适应hash来加速索引。
我们可以使用etcd实现公平锁,因为key的每次修改都会记录revision值,所以可以按照revision值进行排队,这里就不详细说了,不然又扯远了。
读写机制
etcd 是串行写,并发读。
事务开启的时候,读数据读的是B+树中,通过mmap映射的磁盘数据,因为事务开启期间的数据还未落盘,所以读取的是事务开启之前的数据。如果不采用这种方式,读数据就可能出现脏读的问题。
为什么写是串行的而不是并发的呢?如果写是并发的,事务就很难实现了。目前boltdb就是这种做法,写是先写内存,读却是读的磁盘映射到内存中的数据,这就不会涉及到加锁问题。事务提交之后,数据会刷盘。
如果没有开启事务,读写都是走的B树。
raft算法
raft算法是分布式共识算法,用于在分布式系统中保证数据一致性的,主要包含 leader 选举以及日志复制。
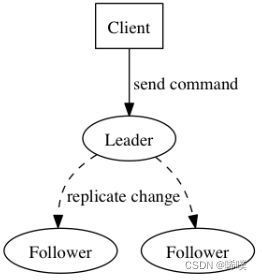
三个角色
- follower :服务刚启动时,每个节点都是follower当选举超时时间过期,则自动成为 candidate。
- candidate候选者: follower称为candidate时,会主动给自己投票,转而向其他节点发送拉票广播,当自身获得选票数超过半数将成为leader。需要选票超过半数的原因,是因为只能选举出一个 leader。
- leader 会定时向其他节点同步自身的变化信息,如果 leader 发现有比自身更高的选举任期,则自己马上下台成为 follower,并接收新的 leader 的数据变更同步。
解释几个概念。
选举超时:leader会给follower节点定期(时间是心跳超时)发送心跳包保持联系,follower收到心跳包后会重置选举超时定时器并回复leader。如果follower在选举超时内未收到心跳包,则会主动成为candidate。这个值是150ms~300ms的一个随机值。选举超时要大于心跳超时,否则会一直都在选举。
选举超时重新生成时机:一是服务器启动时,每个节点会随机生成一个选举超时。二是成为候选者时,这是用来避免多个候选者同时发生选举,获得选票不到一半产生僵持的情况。
选举任期:每发生一次选举会加1,就是上面介绍的term。
投票规则:每个人只有一张选票,只有成为 candidate 才能给自己投票;如果自己是 follower 并且收到其他candidate 的拉票,那么会给第一个给自己拉票的候选者投票,此时会重置自身的选举超时。
日志复制
当我们的集群leader 选举之后。leader 接收所有客户端请求,然后转化为 log 复制命令,发送通知其他节点完成日志复制请求。状态机命令表示客户端请求的数据操作指令,任期号表示 leader 的当前任期。
具体过程:
- Leader 与 Followers 之间保持着心跳联系(heart beat),随心跳 Leader 将追加的 Entry(AppendEntries)并行地发送给其它的 Follower,并让它们复制这条日志条目,这一过程称为复制(Replicate)。注意此时写在日志中,并未真正写盘,是为了回滚。
- Followers 接收到 Leader 发来的复制请求后,会进行一致性检查,检查成功后,写入本地日志中,返回 Success。需要注意的是,此时该 Entry 的状态也是未提交(Uncommitted)。
- 完成上述步骤后,Followers 会向 Leader 发出 Success 的回应,当 Leader 收到大多数 Followers 的回应后,会将第一阶段写入的 Entry 标记为提交状态(Committed),并把这条日志条目写盘。
- Leader会向客户端回应 OK,表示写操作成功,注意此时也会给客户端回复。
- Leader 回应客户端后,将随着下一个心跳通知 Followers,Followers 收到通知后也会将 Entry 标记为提交状态,并把他也应用到状态机上。
后加入节点怎么进行数据同步呢?每个日志复制请求包括状态机命令和任期号,同时还有前一个日志的任期号和日志索引。当follower 收到日志复制命令,执行一致性检查:follower 会使用前一个日志的任期号和日志索引来对比自己的数据。上面讲了检查成功的情况。如果检查失败,follower会回拒绝复制当前日志,回复 error。leader 收到拒绝复制的回复后,继续发送节点日志复制请求,不过这次会带上更前面的一个日志任期号和索引。如此循环往复,直到找到一个共同的任期号&日志索引。此时 follower 从这个索引值开始复制,最终和 leader 节点日志保持一致。
这里只是非常简单地介绍了一下raft算法,只是说明了选举和日志复制的基本流程,对于过程中可能出现的异常情况没有介绍。raft算法不算复杂,但是也没有讲得这么简单,还有关于raft的论文,由于网上相关介绍很多,这里只是作为etcd中的一部分来介绍,不是专门研究这个算法,所以就不再细说了。