【操作系统】xv6文档及源码阅读1 Operating system interfaces
现在前面的
嘻嘻几百年没写文了确实没时间,等搞完毕设可以一起重温重温。最近学os,读源码发现还挺多东西得整理的,尤其途中有必要找资料整理的时候,内容有点多有点乱,写在源码已经显得不现实了。用的vscode,听大佬介绍选的老师相当巴适,没那么叠bug叠难度,适合我的水平,有时间有也想手写啊啊啊啊感觉很好玩的样子。不管了,先按部就班完成实验阅读要求吧,也十分幸运今年2门课都强强组队了呜呜呜求大佬带起飞。(emmmm即使毕设悬于头上但小组小作业还是不太能随便拉胯,尽力而为吧)。那么就没来写博客居然换版了,舒适很多了感觉,希望不要出现1年前我撤销一下万字就没了emmmm,那会就很佛系对待当复习没了就没了吧,也不重写了。
之前搞的并发实验
前几天老师是尝试让我们自己先阅读kernel/main.c proc.h proc.c,讲真多少有点一知半解,尤其到proc我甚至没意识到这个是进程间。后面的也很多没进去看定义大概罢了。不过这里可以解释下昨天听老师解释的main里其实那个判断是在决定是否是主核(cpuid==0),其他核是需要等等待它开启的。还在题目不难也有队友帮忙,比较方便解决。具体这方面的详解等我搞完毕设再说吧呵呵,到时候看有时间就好好整理理顺os,说不定等毕业在接触这么纯粹的计算机知识的机会也不多了,我纯粹爱好呀。
简介
这个系列是对仿unix基本接口和内部设计的简化教学操作系统xv6的源码阅读理解,仅个人学习笔记理解,有误见谅哈哈。本文是阅读xv6中文文档里“Chapter 1 Operating system interfaces ”,理解对应的xv6源代码,且只做必要源码备注。
一些个小预备
安装wsl操作系统
wsl操作系统问题解决 安装过程代码 wsl --install -d Ubuntu-20.04 sudo apt-get update && sudo apt-get upgrade sudo apt-get install git build-essential gdb-multiarch qemu-system-misc gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu 将riscv放⼊系统中(⽅法在⽂件管理器,输⼊“\\wsl$\” 就可以访问虚拟机⽂件夹。) 下次再进⼊Ubuntu,使⽤wsl命令即可 1. 使⽤su进⾏root,再进⾏即可 2. su命令时,提⽰su: Authentication failur sudo passwd root过⼀次之后,下次再su的时候只要输⼊密码就可以成功登录了。 https://blog.csdn.net/jxaucm/article/details/80194372 3. Windows直接访问WSL2路径(\\wsl$\)并直接进⾏读写操作,权限不⾜的问题 https://blog.csdn.net/qq_33412312/article/details/119720052 4. WslRegisterDistribution failed with error_ 0x8007019e、0x800701bc、0x80370102 https://blog.csdn.net/qq_37085158/article/details/125172803 5. wsl --install -d Ubuntu ⽆法解析服务器的名称或地址-window11 https://blog.csdn.net/qq_51219814/article/details/127546848 6. 如果没有⾃动启⽤,需要在控制⾯板的程序中设置
用Visual Studio Code连接WSL使用GDB
我们用Visual Studio Code连接WSL使用GDB进行源码调试(其实单纯阅读源码也不用emmm,但为了大作业呵呵)折腾两节课终于在师哥帮忙搞定wsl远程连接了,具体借用良心是个的指南,笔芯:
1. 安装remote
https://blog.csdn.net/qq_39297053/article/details/126875313
2.Visual Studio Code连接WSL使⽤GDB 教程 http://hitsz-cslab.gitee.io/os-labs/remote_env_gdb/ 3. 系统找不到make命令,但是其他linux命令⽐如ls等都是可⽤的 https://blog.csdn.net/qingtu11/article/details/124073708 4. 使⽤过程 会弹出新的窗⼝,左下⻆的会显⽰是否连接上,打开终端,查看⾃⼰的xv6位置 打开⽂件夹,输⼊查询到的位置
不过就是发现连上甚至都找不到跳转标志emmmm,问了师哥帮忙最后是得在远程上重新装C/C++扩展,呜呜呜呜助教各格真的太给力了
VSCode 无法跳转C语言函数定义和变量定义的解决方案(本地端+远程服务器端)_vscode函数无法跳转_YJer的博客-CSDN博客
相关文档
MIT 6.S081的xv6课程用书:
https://pdos.csail.mit.edu/6.S081/2022/xv6/book-riscv-rev3.pdf
网上对应的中文翻译,是阅读代码过程中非常好的参考资料(目前都基于rev1)。
https://github.com/FrankZn/xv6-riscv-book-Chinese
https://github.com/shzhxh/xv6-riscv-book-CN
文档阅读:shell源码理解
看了第一章最开始是有提shell源码在user/sh.c。好说这不先观摩观摩。我直接丢上来这500行代码了,感兴趣的可以先瞄一眼。
// Shell.
#include "kernel/types.h"
#include "user/user.h"
#include "kernel/fcntl.h"
// Parsed command representation解析后的命令表示
#define EXEC 1
#define REDIR 2
#define PIPE 3
#define LIST 4
#define BACK 5
#define MAXARGS 10
struct cmd {
int type;
};
struct execcmd {
int type;
char *argv[MAXARGS];
char *eargv[MAXARGS];
};
struct redircmd {
int type;
struct cmd *cmd;
char *file;
char *efile;
int mode;
int fd;
};
struct pipecmd {
int type;
struct cmd *left;
struct cmd *right;
};
struct listcmd {
int type;
struct cmd *left;
struct cmd *right;
};
struct backcmd {
int type;
struct cmd *cmd;
};
int fork1(void); // Fork but panics on failure.
void panic(char*);
struct cmd *parsecmd(char*);
void runcmd(struct cmd*) __attribute__((noreturn));
// Execute cmd. Never returns.执行
void
runcmd(struct cmd *cmd)
{
int p[2];
struct backcmd *bcmd;
struct execcmd *ecmd; //struct execcmd {int type;char *argv[MAXARGS];char *eargv[MAXARGS];};
struct listcmd *lcmd;
struct pipecmd *pcmd;
struct redircmd *rcmd;
if(cmd == 0)
exit(1);
switch(cmd->type){
default:
panic("runcmd"); //【非法命令警告】
case EXEC:
ecmd = (struct execcmd*)cmd;
if(ecmd->argv[0] == 0)
exit(1); //【参数非法则退出】
exec(ecmd->argv[0], ecmd->argv);
fprintf(2, "exec %s failed\n", ecmd->argv[0]);
break;
case REDIR:
rcmd = (struct redircmd*)cmd;
close(rcmd->fd);
if(open(rcmd->file, rcmd->mode) < 0){
fprintf(2, "open %s failed\n", rcmd->file);
exit(1);
}
runcmd(rcmd->cmd);
break;
case LIST:
lcmd = (struct listcmd*)cmd;
if(fork1() == 0)
runcmd(lcmd->left);
wait(0);
runcmd(lcmd->right);
break;
case PIPE:
pcmd = (struct pipecmd*)cmd;
if(pipe(p) < 0)
panic("pipe");
if(fork1() == 0){
close(1);
dup(p[1]);
close(p[0]);
close(p[1]);
runcmd(pcmd->left);
}
if(fork1() == 0){
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
runcmd(pcmd->right);
}
close(p[0]);
close(p[1]);
wait(0);
wait(0);
break;
case BACK:
bcmd = (struct backcmd*)cmd;
if(fork1() == 0)
runcmd(bcmd->cmd);
break;
}
exit(0);
}
int
getcmd(char *buf, int nbuf)
{
write(2, "$ ", 2);
memset(buf, 0, nbuf);
gets(buf, nbuf);
if(buf[0] == 0) // EOF
return -1;
return 0;
}
int
main(void)
{
static char buf[100];
int fd; //文件描述符总数
// Ensure that three file descriptors are open.确保自己总是有三个文件描述符打开
while((fd = open("console", O_RDWR)) >= 0){
if(fd >= 3){
close(fd);
break;
}
}
// Read and run input commands.
while(getcmd(buf, sizeof(buf)) >= 0){
if(buf[0] == 'c' && buf[1] == 'd' && buf[2] == ' '){
// Chdir must be called by the parent, not the child.
buf[strlen(buf)-1] = 0; // chop \n
if(chdir(buf+3) < 0)
fprintf(2, "cannot cd %s\n", buf+3);
continue;
}
if(fork1() == 0)
runcmd(parsecmd(buf));
wait(0);
}
exit(0);
}
void
panic(char *s)
{
fprintf(2, "%s\n", s);
exit(1);
}
int
fork1(void)
{
int pid;
pid = fork();
if(pid == -1)
panic("fork");
return pid;
}
//PAGEBREAK!
// Constructors
struct cmd*
execcmd(void)
{
struct execcmd *cmd;
cmd = malloc(sizeof(*cmd));
memset(cmd, 0, sizeof(*cmd));
cmd->type = EXEC;
return (struct cmd*)cmd;
}
struct cmd*
redircmd(struct cmd *subcmd, char *file, char *efile, int mode, int fd)
{
struct redircmd *cmd;
cmd = malloc(sizeof(*cmd));
memset(cmd, 0, sizeof(*cmd));
cmd->type = REDIR;
cmd->cmd = subcmd;
cmd->file = file;
cmd->efile = efile;
cmd->mode = mode;
cmd->fd = fd;
return (struct cmd*)cmd;
}
struct cmd*
pipecmd(struct cmd *left, struct cmd *right)
{
struct pipecmd *cmd;
cmd = malloc(sizeof(*cmd));
memset(cmd, 0, sizeof(*cmd));
cmd->type = PIPE;
cmd->left = left;
cmd->right = right;
return (struct cmd*)cmd;
}
struct cmd*
listcmd(struct cmd *left, struct cmd *right)
{
struct listcmd *cmd;
cmd = malloc(sizeof(*cmd));
memset(cmd, 0, sizeof(*cmd));
cmd->type = LIST;
cmd->left = left;
cmd->right = right;
return (struct cmd*)cmd;
}
struct cmd*
backcmd(struct cmd *subcmd)
{
struct backcmd *cmd;
cmd = malloc(sizeof(*cmd));
memset(cmd, 0, sizeof(*cmd));
cmd->type = BACK;
cmd->cmd = subcmd;
return (struct cmd*)cmd;
}
//PAGEBREAK!
// Parsing
char whitespace[] = " \t\r\n\v";
char symbols[] = "<|>&;()";
int
gettoken(char **ps, char *es, char **q, char **eq)
{
char *s;
int ret;
s = *ps;
while(s < es && strchr(whitespace, *s))
s++;
if(q)
*q = s;
ret = *s;
switch(*s){
case 0:
break;
case '|':
case '(':
case ')':
case ';':
case '&':
case '<':
s++;
break;
case '>':
s++;
if(*s == '>'){
ret = '+';
s++;
}
break;
default:
ret = 'a';
while(s < es && !strchr(whitespace, *s) && !strchr(symbols, *s))
s++;
break;
}
if(eq)
*eq = s;
while(s < es && strchr(whitespace, *s))
s++;
*ps = s;
return ret;
}
int
peek(char **ps, char *es, char *toks)
{
char *s;
s = *ps;
while(s < es && strchr(whitespace, *s))
s++;
*ps = s;
return *s && strchr(toks, *s);
}
struct cmd *parseline(char**, char*);
struct cmd *parsepipe(char**, char*);
struct cmd *parseexec(char**, char*);
struct cmd *nulterminate(struct cmd*);
struct cmd*
parsecmd(char *s)
{
char *es;
struct cmd *cmd;
es = s + strlen(s);
cmd = parseline(&s, es);
peek(&s, es, "");
if(s != es){
fprintf(2, "leftovers: %s\n", s);
panic("syntax");
}
nulterminate(cmd);
return cmd;
}
struct cmd*
parseline(char **ps, char *es)
{
struct cmd *cmd;
cmd = parsepipe(ps, es);
while(peek(ps, es, "&")){
gettoken(ps, es, 0, 0);
cmd = backcmd(cmd);
}
if(peek(ps, es, ";")){
gettoken(ps, es, 0, 0);
cmd = listcmd(cmd, parseline(ps, es));
}
return cmd;
}
struct cmd*
parsepipe(char **ps, char *es)
{
struct cmd *cmd;
cmd = parseexec(ps, es);
if(peek(ps, es, "|")){
gettoken(ps, es, 0, 0);
cmd = pipecmd(cmd, parsepipe(ps, es));
}
return cmd;
}
struct cmd*
parseredirs(struct cmd *cmd, char **ps, char *es)
{
int tok;
char *q, *eq;
while(peek(ps, es, "<>")){
tok = gettoken(ps, es, 0, 0);
if(gettoken(ps, es, &q, &eq) != 'a')
panic("missing file for redirection");
switch(tok){
case '<':
cmd = redircmd(cmd, q, eq, O_RDONLY, 0);
break;
case '>':
cmd = redircmd(cmd, q, eq, O_WRONLY|O_CREATE|O_TRUNC, 1);
break;
case '+': // >>
cmd = redircmd(cmd, q, eq, O_WRONLY|O_CREATE, 1);
break;
}
}
return cmd;
}
struct cmd*
parseblock(char **ps, char *es)
{
struct cmd *cmd;
if(!peek(ps, es, "("))
panic("parseblock");
gettoken(ps, es, 0, 0);
cmd = parseline(ps, es);
if(!peek(ps, es, ")"))
panic("syntax - missing )");
gettoken(ps, es, 0, 0);
cmd = parseredirs(cmd, ps, es);
return cmd;
}
struct cmd*
parseexec(char **ps, char *es)
{
char *q, *eq;
int tok, argc;
struct execcmd *cmd;
struct cmd *ret;
if(peek(ps, es, "("))
return parseblock(ps, es);
ret = execcmd();
cmd = (struct execcmd*)ret;
argc = 0;
ret = parseredirs(ret, ps, es);
while(!peek(ps, es, "|)&;")){
if((tok=gettoken(ps, es, &q, &eq)) == 0)
break;
if(tok != 'a')
panic("syntax");
cmd->argv[argc] = q;
cmd->eargv[argc] = eq;
argc++;
if(argc >= MAXARGS)
panic("too many args");
ret = parseredirs(ret, ps, es);
}
cmd->argv[argc] = 0;
cmd->eargv[argc] = 0;
return ret;
}
// NUL-terminate all the counted strings.
struct cmd*
nulterminate(struct cmd *cmd)
{
int i;
struct backcmd *bcmd;
struct execcmd *ecmd;
struct listcmd *lcmd;
struct pipecmd *pcmd;
struct redircmd *rcmd;
if(cmd == 0)
return 0;
switch(cmd->type){
case EXEC:
ecmd = (struct execcmd*)cmd;
for(i=0; ecmd->argv[i]; i++)
*ecmd->eargv[i] = 0;
break;
case REDIR:
rcmd = (struct redircmd*)cmd;
nulterminate(rcmd->cmd);
*rcmd->efile = 0;
break;
case PIPE:
pcmd = (struct pipecmd*)cmd;
nulterminate(pcmd->left);
nulterminate(pcmd->right);
break;
case LIST:
lcmd = (struct listcmd*)cmd;
nulterminate(lcmd->left);
nulterminate(lcmd->right);
break;
case BACK:
bcmd = (struct backcmd*)cmd;
nulterminate(bcmd->cmd);
break;
}
return cmd;
}嘿嘿区区500还好还好,就是展开说说是另外一个事了,不管怎么说先干就对了。说真的瞄了一眼发现没法细说,很多不确定,建议还是跟着文档来。代码瞄一瞄就是先是写命令相关的类型宏定义和结构体,然后有执行命令函数。我不是很想搞自己打算跟文档学,剩余的再自己看。文档好像都是代码段我就研究这些简化的。后续时候有需要细读这500行在问老师和助教。
先贴一张我认为很重要的图,建议初学者学的时候截图贴在旁边,可能比较不乱。
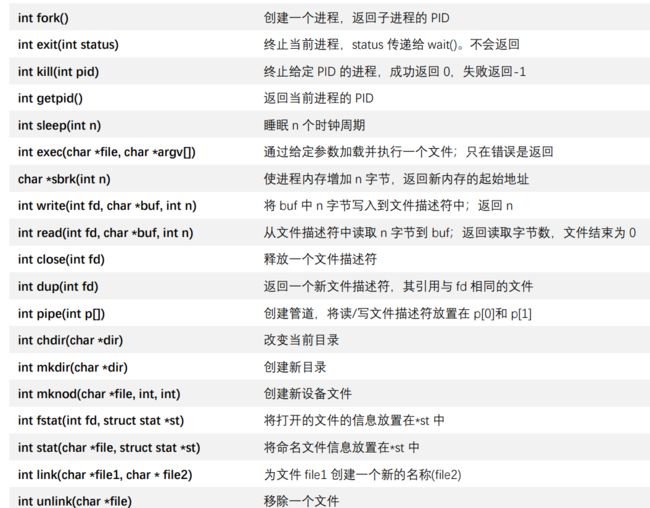
1.1 Processes and memory
fork()
先引入一个概念,内核为每个进程关联一个 PID(进程标识符)。 在父进程中,fork 返回子进程的 PID;在子进程中,fork 返回 0。
int pid = fork();
if (pid > 0)
{
//父进程
printf("parent: child=%d\n", pid);
//子进程退出状态码会复制到参数地址;参数为0表示不存(数据类型为指针)
//等待当前进程的一个子进程退出或被杀死,并返回该子进程的 PID
pid = wait((int *)0);
printf("child %d is done\n", pid);
}
else if (pid == 0)
{
//子进程
printf("child: exiting\n");
exit(0); // 0 表示成功,1 表示失败;并释放资源,如内存和打开的文件
}
else
{
printf("fork error\n");
}
由于父子进程的打印不确定谁先谁后,所以会有2种顺序(child %d is done一定最后)
//情况1
parent: child=3884
child: exiting
child 3884 is done
//情况2
child: exiting
parent: child=3884
child 3884 is done对于fork几节课听下来觉得他的作用是多复制几个克隆体来并行,那么肯定指向一样的地方。但其实一旦各自开始执行,势必可能会出现不同时改变变量的情况,同一时间父子进程各自的变量可能不同。所以很纯粹的指向同一片物理内存是不合理的。但父子进程打印的内存地址(虚拟地址)相同,主要还是父子进程的同一虚拟地址其实指向不同的物理地址。子进程执行时是会把父进程的物理内存块复制一份的。具体可参考【进程管理】fork之后子进程到底复制了父进程什么? - 知乎 (zhihu.com),下面引用其中代码段及结果
#include
#include
#include
#include
void main()
{
char str[6]="hello";
pid_t pid=fork();
if(pid==0)
{
str[0]='b';
printf("子进程中str=%s\n",str);
printf("子进程中str指向的首地址:%x\n",(unsigned int)str);
}
else
{
sleep(1);
printf("父进程中str=%s\n",str);
printf("父进程中str指向的首地址:%x\n",(unsigned int)str);
}
} 子进程中str=bello
子进程中str指向的首地址:bfdbfc06
父进程中str=hello
父进程中str指向的首地址:bfdbfc06
exec()
exec的作用是根据指定的文件名找到可执行文件,并用它来取代调用进程的内容,即使用新内存映像来替换进程的内存, 新内存映像从文件系统中的文件中进行读取,换句话说,就是在调用进程内部执行一个可执行文件。这里的可执行文件既可以是二进制文件,也可以是任何Linux下可执行的脚本文件。这个文件必须有特定的格式,它指定了文件中哪部分存放指令,哪部分是数据, 在哪条指令开始,等等。xv6 使用 ELF 格式,第 3 章将详细讨论。
与一般情况不同,当 exec 成功时,它并不返回到调用程序;相反,从文件中加载的指令在 ELF 头声明的入口点开始执行。因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代,只留下进程ID等一些表面上的信息仍保持原样,颇有些神似"三十六计"中的"金蝉脱壳"。看上去还是旧的躯壳,却已经注入了新的灵魂。只有调用失败了,它们才会返回一个-1,从原程序的调用点接着往下执行。
exec 需要 两个参数:包含可执行文件的文件名和一个字符串参数数组。
char *argv[3];
argv[0] = "echo"; //大多数程序都会忽略参数数组的第一个元素,也就是程序名称。
argv[1] = "hello";
argv[2] = 0;
exec("/bin/echo", argv);
printf("exec error\n");shell主函数
即上面代码145(user/sh.c/main()),我粘到下面了,用到的runcmd()相关部分节(user/sh.c:58 )也有。
int
main(void)
{
static char buf[100];
int fd;
// Ensure that three file descriptors are open.
while((fd = open("console", O_RDWR)) >= 0){
if(fd >= 3){
close(fd);
break;
}
}
// Read and run input commands. getcmd 读取用户的一行输入
while(getcmd(buf, sizeof(buf)) >= 0){
if(buf[0] == 'c' && buf[1] == 'd' && buf[2] == ' '){
// Chdir must be called by the parent, not the child.【cd指令】
buf[strlen(buf)-1] = 0; // chop \n
if(chdir(buf+3) < 0) //改变当前地址
fprintf(2, "cannot cd %s\n", buf+3);
continue;
}
//调用 fork,创建 shell 副本
if(fork1() == 0) //子进程去运行
runcmd(parsecmd(buf)); //parsecmd解析
wait(0); //父进程等待子进程运行完毕;echo 会调用 exit,这将使父程序从wait 返回。
}
exit(0);
}//user/sh.c:58
void
runcmd(struct cmd *cmd)
{
//参数为命令解析后结构体
struct execcmd *ecmd; //struct execcmd {int type;char *argv[MAXARGS];char *eargv[MAXARGS];};
if(cmd == 0)
exit(1);
switch(cmd->type){
//根据解析命令获得的结构体信息分命令执行
default:
panic("runcmd"); //【非法命令警告】
case EXEC: //对于echo hello,它会调用 exec,将执行 echo 程序
ecmd = (struct execcmd*)cmd;
if(ecmd->argv[0] == 0)
exit(1); //【参数非法则退出】
exec(ecmd->argv[0], ecmd->argv);
fprintf(2, "exec %s failed\n", ecmd->argv[0]);
break;
exit(0);
}copy-on-write
具体可参考【进程管理】fork之后子进程到底复制了父进程什么? - 知乎 (zhihu.com),也就文中下面这部分引用:
fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制“技术,也就是只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
fork时子进程获得父进程数据空间、堆和栈的复制,所以变量的地址(当然是虚拟地址)也是一样的。
每个进程都有自己的虚拟地址空间,不同进程的相同的虚拟地址显然可以对应不同的物理地址。因此地址相同(虚拟地址)而值不同没什么奇怪。
具体过程是这样的:
fork子进程完全复制父进程的栈空间,也复制了页表,但没有复制物理页面,所以这时虚拟地址相同,物理地址也相同,但是会把父子共享的页面标记为“只读”(类似mmap的private的方式),如果父子进程一直对这个页面是同一个页面,知道其中任何一个进程要对共享的页面“写操作”,这时内核会复制一个物理页面给这个进程使用,同时修改页表。而把原来的只读页面标记为“可写”,留给另外一个进程使用。
这就是所谓的“写时复制”。正因为fork采用了这种写时复制的机制,所以fork出来子进程之后,父子进程哪个先调度呢?内核一般会先调度子进程,因为很多情况下子进程是要马上执行exec,会清空栈、堆。。这些和父进程共享的空间,加载新的代码段。。。,这就避免了“写时复制”拷贝共享页面的机会。如果父进程先调度很可能写共享页面,会产生“写时复制”的无用功。所以,一般是子进程先调度滴。
假定父进程malloc的指针指向0x12345678, fork 后,子进程中的指针也是指向0x12345678,但是这两个地址都是虚拟内存地址 (virtual memory),经过内存地址转换后所对应的 物理地址是不一样的。所以两个进城中的这两个地址相互之间没有任何关系。
(注1:在理解时,你可以认为fork后,这两个相同的虚拟地址指向的是不同的物理地址,这样方便理解父子进程之间的独立性)
(注2:但实际上,linux为了提高 fork 的效率,采用了 copy-on-write 技术,fork后,这两个虚拟地址实际上指向相同的物理地址(内存页),只有任何一个进程试图修改这个虚拟地址里的内容前,两个虚拟地址才会指向不同的物理地址(新的物理地址的内容从原物理地址中复制得到))
一个进程如果在运行时需要更多的内存(可能是为了 malloc), 可以调用 sbrk(n)将其数据内存增长 n 个字节;sbrk 返回新内存的位置。
1.2 I/O and File descriptors
这部分因为文档也没展开和多细节,我一开始看得有点迷糊。这里找到一篇文帮助理解:I/O重定向的原理和实现 - Todd Wei - 博客园 (cnblogs.com),才弄清楚进程各自的文件描述符索引是怎么回事。看的时候考虑一个问题,write可以写入标准输入0吗?找到以下答案:
write(0)可以的。在Linux下试验过了,两者均会在终端上打印出buf的内容。
char buf[]="aaaaaa";
write(1,buf,7);
write(0,buf,7);
二者最终呈现的效果是一样的,均在终端上打印“aaaaaa”
那么常说0是stdin的fd,1是stdout的fd,这二者是否在底层就是形式上完全相同的file description描述符,只是在宏观用法上做了些许约定呢?
read(1,buf,7);发现Ubuntu18下有的时候会出现段错误,而有的时候不出现段错误却会夹杂乱码,不过不论在哪一种情况下,gdb调试中发现buf确实被读入了用户从终端上输入的内容。
答:为了一些老系统兼容性,如果stdin连接的是一个terminal,那么stdin仍然是可以写入的。写入的结果是将写入的内容回显。但是stdin连接的并不总是terminal,完全可以是一个pipe或者文件。这种情况下,再往stdin里写入,就有可能出错了。所以写入stdin并不是什么好主意。
cat(英文全拼:concatenate)命令用于连接文件并打印到标准输出设备上。
文档关于fork和io重定向的合作没看明白,他强调了前面出fork和exec分开的好处。其实刚开始想觉得分开也是对的,因为是两个东西。但是或许有时候考虑说一般分支就是为了执行,所以可以考虑把它们合起来。但是不这么做的原因是,在执行之前,子进程可能是需要单独做一下自己的io重定向。这样子如果fork和exec两个是合起来的, 这个子进程的单独io重定向修改就没法实现了。
打开同一个文件的文件描述符也是不一样的,除非你是通过fork dup获取的文件描述符。
我可以理解为标准输入就是写入到缓存区。
1.3 Pipes
Linux进程间通信——管道 - 知乎 (zhihu.com)
传完数据是需要关闭写端的,不然就会一直等待写,然后被阻塞。
读端和写端的重定向分别是两个子进程实现的。
linux中管道符的作用是什么
case PIPE:
pcmd = (struct pipecmd*)cmd;
if(pipe(p) < 0)
panic("pipe"); //创建管道失败警告
if(fork1() == 0){
//写段子进程
close(1); //关闭标准输出1.使其后面能引用管道写段p[1],即标准输出连到管道写端
dup(p[1]); //标准输出连到管道写端
close(p[0]); //管道一般就被放到文件描述符3 4,这里不需要用了关闭
close(p[1]);
runcmd(pcmd->left); //左端即写段,递归调用;管道端可能是一个命令
}
if(fork1() == 0){
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
runcmd(pcmd->right); //也可以是包含管道的多个命令(例如,a | b | c)
}
close(p[0]);
close(p[1]);
wait(0);
wait(0);
break;当管道的右端读端可能有多个命令(用管道符|,a | b | c)的时候会形成进程树。比如a b c都是指令,执行a | b | c的话,a到左端子进程,b|c到右端进程;右端进程又分为b左端进程和c右端进程,我理解的进程树如下:
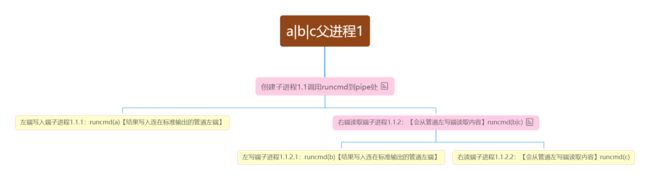
f粉红色节点为内部(非叶子)节点是等待左右子 进程完成的进程
我突然想起一个问题,为什么要弄一个子进程,然后让父进程来等待他执行,这不是多此一举,脱裤子放屁吗,本来还以为后面可能跟并行的有点关系,但目前是不清楚的。后面看到命令递归的问题,突然意识到,弄子进程的话可以形成进程树,比较清晰。如果把它改成递归的话,因为代码里面针对子进程思想runcmd也有一个退出exit(是子进程控制每一条指令的话一切都好说,确实是执行完就能退出了,反正父进程还在),所以肯定会提前结束掉。要么就得判断非叶子节点才能exit,这肯定变复杂的。
我来骂骂,这里卡得好久就是那个进程树莫名其妙,他没怎么说细节,后面找了管道符及其管道运行原理、源码fork引用分析、源码runcmd前的命令解析步骤,才摸了几个小时出来,md
管道是一个小的内核缓冲区。
1.4 File system
当一个进程打开设备文件后,内 核会将系统的读写调用转移到内核设备实现上,而不是将它们传递给文件系统。 每个 inode 都有一个唯一的 inode 号来标识 。
但文件名字可以有多个。
1.5 Real world
我们先想一下刚才都是干了些啥?我们发现就是一直在探讨进程、文件管理相关信息。想一下在这些都没诞生出来之前,是什么样的人为实现这样一个完整的功能系统而仔细地为每个细节设计出绝妙的解决方案?确实牛逼。
死磕代码部分
能看的也都看了,是时候解决老师留的问题,这里直接丢上来但因为我也得交作业就没放具体答案了嘿嘿。等到期末后(毕业)我那会时间多就丢上来。我会记录一下为了这些问题被源码搞到的一些过程。
user/sh.c (L168-169).
1.if(fork1() == 0)
为什么fork1()返回值为0时才进入if语句内部?
2.runcmd(parsecmd(buf));
阅读runcmd的代码,其中:
$echo README对应的cmd->type是哪个?
相应的,$ls; echo “hello world“ 对应的cmd->type是哪个?
而ls | wc 对应的cmd->type是哪个?给出你的答案,并从代码中给出解释。
没啥好说的前面都研究过了,看过文档的和我一起走到这里八成没啥问题。
问题:阅读user/sh.c (L83)对应的switch分支及相关代码,请说明这个输出重定向命令
$ls > test.txt
如何确保test.txt接收ls命令的输出呢?
这部分是我整理的part,所以我得详细研究。一开始还以为是LIST分支,但后面发现redir居然是重定向的意思!!!但不管怎么说,结合前面管道那部分的折磨,可以推出在命令解析时是做了很多预备工作的,所以要搞细节的话这部分就没法忽略。但是,但是,好混乱啊啊啊爷被绕进去了,网上也没这部分的详解,尤其我看到有个函数是在找命令开头是不是'<''>'我就开始自我怀疑了。。。are you sure是不是我那里理解错。
为此,我决定采取另外一条路径曲线救国,先试试之前安的gdb看能摸透吗。注意,这里用户态代码调试是没法直接跳到断点的,需要一点技巧。前面提到的安装文档远程实验平台环境图形化调试指南 - 操作系统后面是有相应的调试教程的,在4.4.4
用户态程序调试
4.4.4 用户态程序调试 ¶
xv6的内核态和用户态并不共享页表,调试符号也完全不同。调试用户程序需要加载对应的用户程序调试符号,我们将通过调试控制台完成这一项操作。我们以调试自带的用户程序“ls"为例。
Step1: 先在终端输入“make qemu-gdb”。
接着,按下F5, 或者 点击左侧按钮运行与调试,并点击左上角绿色三角(Attach to gdb)。
再点击“运行”,让xv6正常运行,直到出现“$”,表示已经进入shell中。
Step2: 在调试控制台,输入“interrupt”。
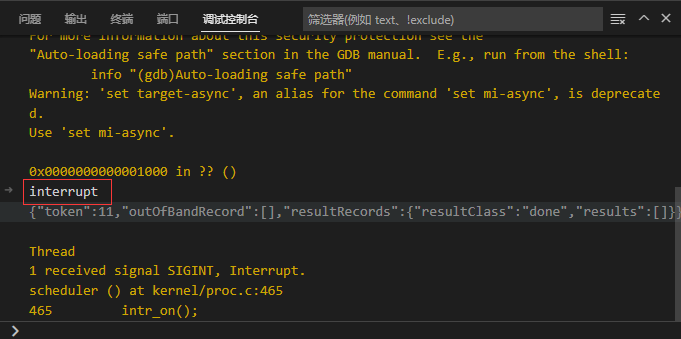
Step3: 我们知道,在进入Trampoline切换前最后一行C代码位于 kernel/trap.c:128处,我们将断点打在此处,继续点击“运行”。
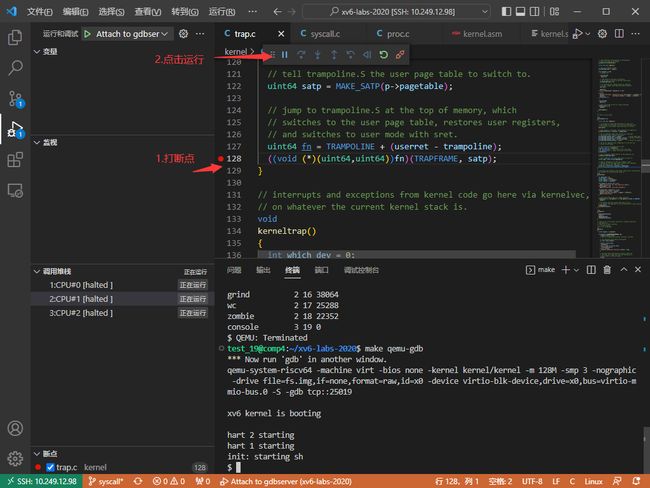
Step4: 在xv6的shell中输入 ls,以启动 ls程序;程序停留在 kernel/trap.c:128处。
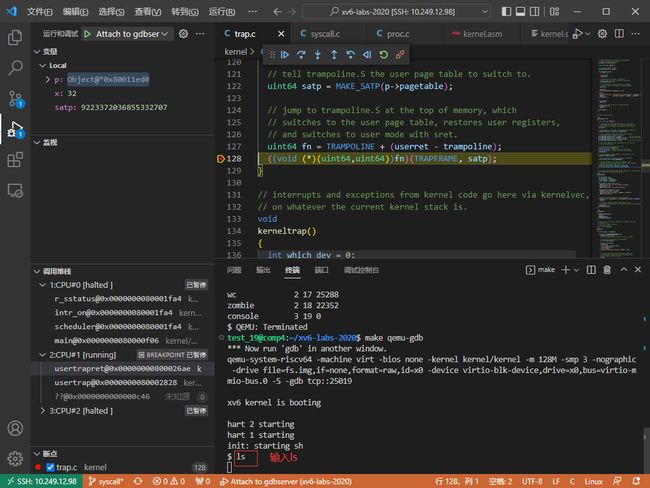
Step5: 接下来,我们需要确认对应xv6的用户程序入口点,我们有两种方法可以确认应用程序的入口点:
通过readelf确认应用程序入口点。
在VSCode上直接打开该应用程序的源代码,找打main()函数,并在main()函数里打上断点。
以下分别介绍两种方法:
方法一: 通过readelf确认应用程序入口点
ls的elf文件位于 user/_ls:
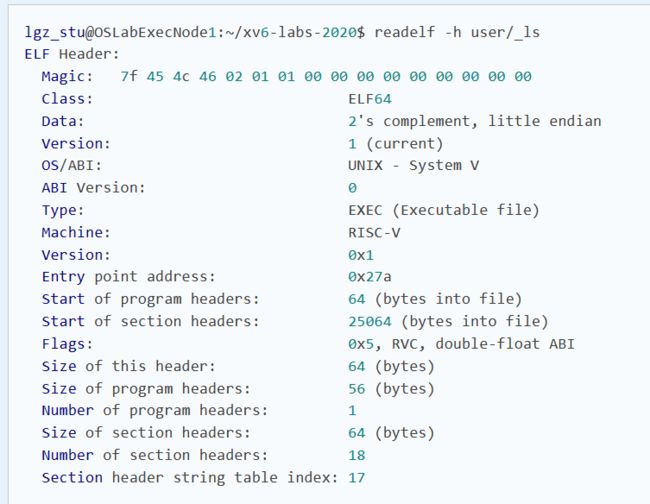
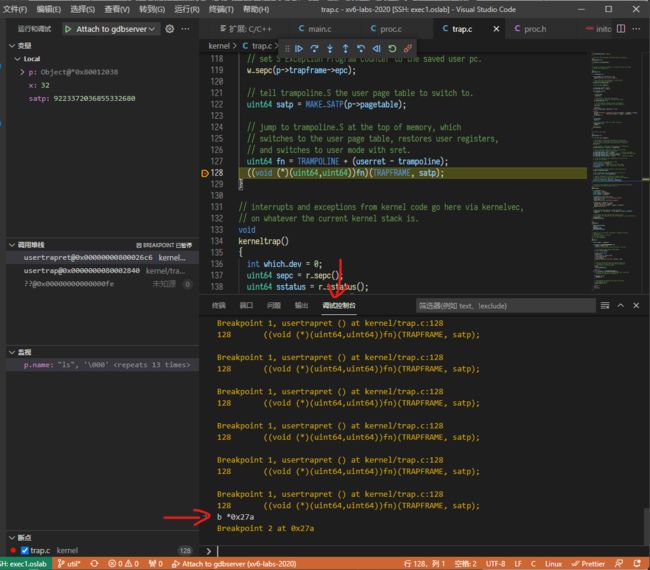
可见其中显示 Entry point address: 0x27a,应用程序入口点位于 0x27a处。随后,我们用上面的方法开始调试,并将断点打在即将返回用户态处。
我们前往调试控制台,在其中输入 b *0x27a,即将断点置于 ls程序入口处:
方法二: 在应用程序的源代码main()函数打断点
在VSCode中,打开user/ls.c文件,找到main()函数,在第78行打上断点。
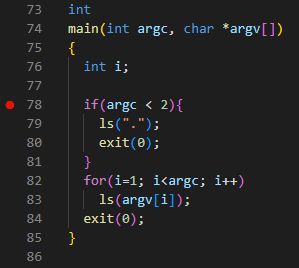
通过上述两个方法都可以确认应用程序的入口点,将断点打在应用程序的main()上。
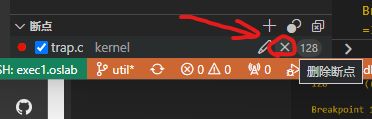
Step6: 接下来,我们需要在调试窗口左下角删除原有的内核态断点,并通过调试控制台,加载 ls的调试符号。在其中输入 file user/_ls:

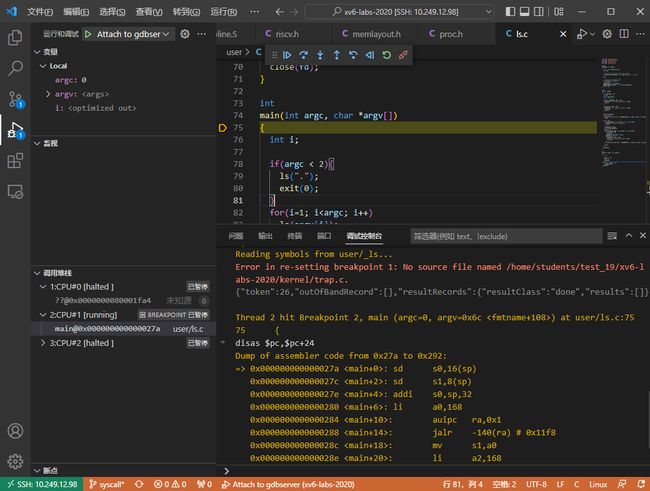
Step7: 点击“运行”。可以看到已经进入了ls.c的main函数中。
Step8: 此时,可以在user/ls.c文件中直接打上断点,下图是在user/ls.c中的第78行打断点。如果已经在78行打过断点,可以忽略这一步。
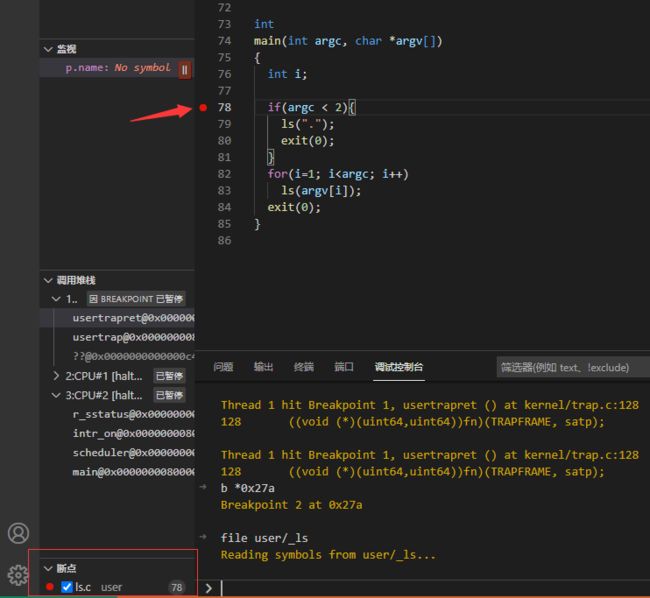
Step9: 接下来,继续执行。qemu将停止在 ls程序的第78行。
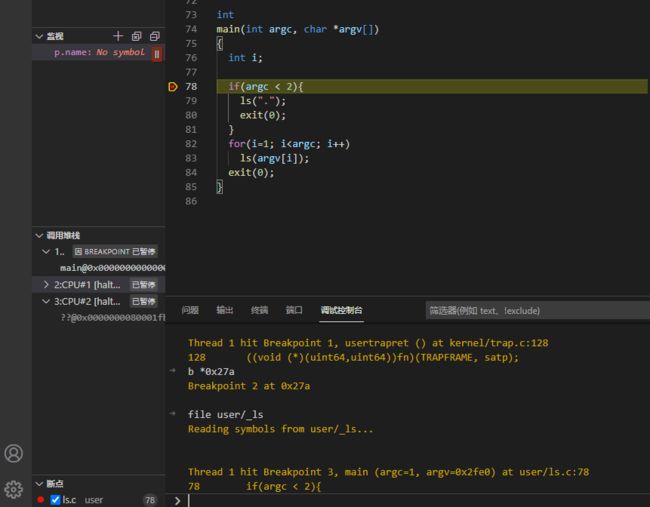
点击上方的单步调试按钮,我们发现vscode的GUI调试工具现也以可以正常工作。

不知道什么原因是调试不了sh.c的(没权限?),后面又找到关于shell代码分析的
xv6 shell实现源代码分析
文摘加碎碎念
纯纯宝藏啊!!!直接帮忙让我把题解出来。不过我还是想通过该文好好了解下那些很乱的代码。文摘和笔记如下
shell对每一次输入的命令都会派生一个子进程来执行,因此必须在父进程里先处理cd。因为每个进程的工作目录都不同,如果把cd放到子进程中,由外部用户程序来实现,那么只会修改子进程的工作目录,shell本身的工作目录还是得不到改变。
execcmd,代表最基本的命令,包括命令名与参数,例如cat y.sh这样的命令。argv是参数列表,每个项都是一个字符指针,代表相应的字符串开始的内存位置。eargv的每个项也是一个字符指针,不过与argv相反,它代表的是每个字符串结束的内存位置,主要是作为字符串结束的标志。
backcmd,代表后台命令。在命令的最后面加上&,代表放到后台执行。也包含一个实际要执行的cmd命令。
LIST就是echo hello; echo world类。
ls < y; ls | sort; who如下(;高于|)
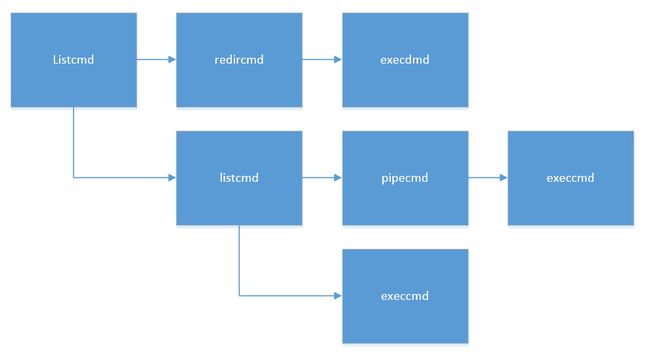
来骂一骂骂一骂,代码逻辑就下面那么绕我不看乱才怪
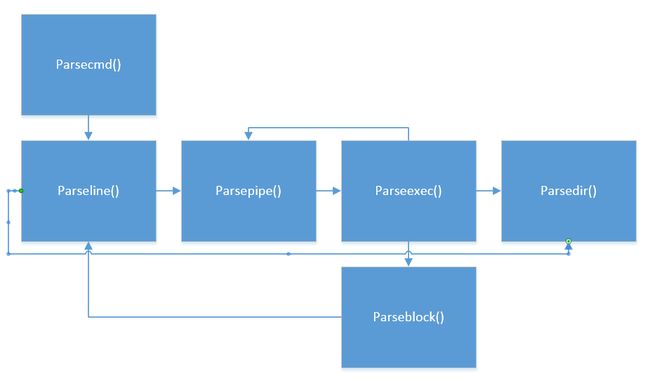
然后大大的文实在太牛逼了通俗易懂,只能继续放了
parsecmd()是命令构造函数,它简单地把工作转交给parseline()函数。
parseline顾名思义就是处理一行的输入字符串,把它转化成命令。这一行的概念有点抽象,实际上应该是可以视作一个命令整体的一行字符串,在这行字符串里可以包含各种命令,也就是|&<>();这些字符都可以处理。所有需要处理全部类型字符的工作都可以交给parseline()完成。parseline()里还可以递归地调用parseline()。
parsepipe()用于处理管道命令,由于可能存在多个管道命令,因此parsepipe()可以递归调用自身。
parseblock()处理()内的命令,把()内的命令作为一个整体命令来处理,而忽略从左到右的执行优先级。
parseredirs()用于处理重定向命令,把子命令包裹成redircmd类型。
这些函数通过一连串的互相调用、递归调用,构建起链式的命令串。
gettoken()函数独立分析
来,就是这个该死gettoken()函数,我当时就是看到这里放弃的,知道处理字符串当越看越不对劲,没整明白。但有个问题,它返回的结果有'a’(表示解析出命令)、'+'(>>)以及其他命令符(<|>&;()),那为什么是返回int类型呢?不是应该返回char更合理吗?这又是有什么讲究吗?
gettoken()分析如下,其作用就是对1整行的复杂命令(可能包含多个<|>&;()及多条子命令),我们需要把子命令提取出来(子命令始止放在参数q和eq;当设定q和eq为0时即无需保存)。也可能获取失败,即读到<|>&;()或>>,那就直接返回该字符,>>返回'+’。不管返回什么,该函数都会将命令行起始位置移到下一次开始位置。
int
gettoken(char **ps, char *es, char **q, char **eq) //q为提取命令起始,eq终止(传0时忽略);该函数的作用就是获取命令(命令头尾保存在q eq)/获取失败,命令头也后移到下一次命令开始
{
char *s;
int ret; //读取到命令时返回'a',读到>>返回'+',其他间隔符号返回该字符
s = *ps; //命令行副本
while(s < es && strchr(whitespace, *s))
s++; //去前边空格等
if(q)
*q = s; //保存命令起始(q为0时忽略)
ret = *s; //保留起始字符
switch(*s){
case 0:
break;
case '|':
case '(':
case ')':
case ';':
case '&':
case '<':
s++; //符号跳过
break;
case '>':
s++;
if(*s == '>'){
ret = '+'; //读到符号为>>时用ret='+'表示
s++;
}
break;
default:
ret = 'a'; //其他情况就是读到命令了,返回结果设置为'a'表示读到命令
while(s < es && !strchr(whitespace, *s) && !strchr(symbols, *s))
s++; //获取命令尾
break;
}
if(eq)
*eq = s; //需要保存命令尾时进行存储
while(s < es && strchr(whitespace, *s))
s++; //更新下一条命令头(前去空)
*ps = s; //保存新的命令头
return ret;
}看完文,我觉得我懂了个大概;拿起笔,我发现一些细节莫名其妙。。。啊啊啊啊还是不能跳步只能每个细节有研究一遍,要不总会卡在路上。
我发现代码里一个很牛逼的思想,当然也差点没把我绕住折磨老久了:其实刚开始创建cmd是复杂的redircmd,但回传时只简化成cmd,但数据还存在随时可以复原。
后话
emmm折磨好几天,源码就是神奇。作业搞定赶快肝毕设~~~