GPU设备架构全面解析(持续更新ing)
作为一个7年的GPU开发者,随着加速算法应用的普及以及应用GPU设备的增多,各种设备结构(比如Kepler Maxwell Pascal)和GPU系列混入脑中,经常记不住,希望用这篇博客记录下各个设备架构的特性和最新功能,当然这并不是包含所有的GPU设备,只是笔者经常接触到的或者买不起的又想用的(终究是贫穷)。
目录
一、GPU设备架构和系列产品
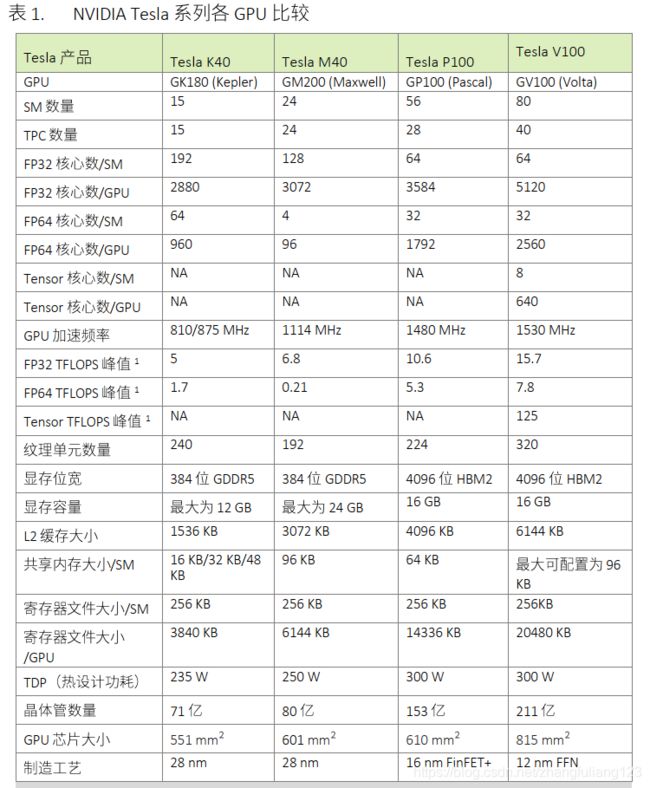
二、几个卡相关对比(总览)
三、K80计算卡架构及特性
四、P100计算卡架构及特性
五、V100计算卡架构及特性
六、A100计算卡架构及特性
一、GPU设备架构和系列产品
设备架构:
| 架构 | Tesla | Fermi | Kepler | Maxcell | Pascall | Volta | Turing | Ampere |
| GPU时代 | 1.0 | 2.0 | 3.0 | 5.0 | 6.0 | 7.0 | 7.5 | 8.0 |
| 时间 | 2008 | 2010 | 2012 | 2014 | 2016 | 2017 | 2018 | 2020 |
NVIDIA 算力与卡对照表:
NVIDIA GPU 算力对照表 - 知乎
其中Tesla既是架构又是英伟达系列产品中的一个,比如Tesla K20 Teska K40 Tesla K80,所有架构可谓是一代更比一代强,
系列产品:英伟达GPU产品根据应用场景主要分了3个产品系列:GeForce系列(桌面电脑应用)、Tesla系列(专业计算,数据中心)和Quadro系列(专用一体机);
详细可参考官方文档配图:
图:GPU计算应用(GPU被设计成为支持不同语言和应用程序的接口)- (From Pascal-architecture-white-paper)
二、几个卡相关对比(总览)
下表是几个常用卡参数对比:
| Name | K80 | P100 | V100 | RTX2080Ti | A100 80GB PCIE |
| 架构 | Kepler | Pascal | Volta | Turing | Ampere |
| GPU | GK110 | GP100 | GV100 | TU102 | GA100 |
| 计算能力 | 3.7 | 6.0 | 7.0 | 7.5 | 8.0 |
| 内存接口 | GDDR5 | HBM2 | HBM2 | HBM2e | |
| 显存 | 11520M | 16265M | 16225M | 11264M | 80GB |
| GPU最大时钟频率 | 0.82GHz | 1.33GHz | 1.38GHz | 1.545GHz | 1.410GHz |
| L2缓存 | 1536KB | 4096KB | 6144KB | 40MB | |
| 常量内存 | 64KB | 64KB | 64KB | 64KB | 64KB |
| SM 数量 | 13 | 56 | 80 | 68 | 128 |
| 总core / SM内 Cores | 2496(192) | 3584(64) | 5120(64) | 4352(64) | 8192(64) full_GPU |
| 共享内存 Per Block | 48KB | 48KB | 96KB | 64KB | 163KB |
| 共享内存Per SM | 112KB | 64KB | configurable up to 96KB |
64KB | configurable up to 164KB |
| SM最大线程 | 2048 | 2048 | 2048 | 1024 | 2048 |
| Block最大线程 | 1024 | 1024 | 1024 | 1024 | 1024 |
| Copy Engines | 2个 | 2个2 | 7个 | ||
NVIDIA A100 PCIe 40 GB Specs | TechPowerUp GPU Database
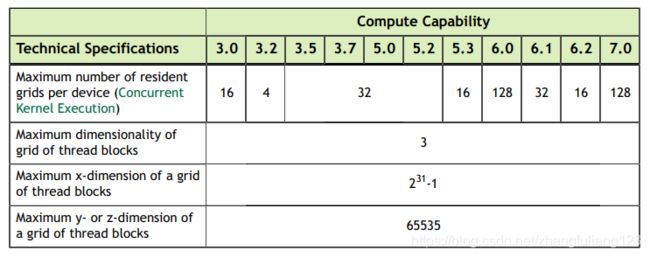
注意:每个设备最大驻留Grids数量即是CUDA并发kernel执行的数量

图来自CUDA_C_Progrmming_Guide.pdf
其中对一些参数做部分说明:
Maximum number of threads per block: 每个Block内最大线程数量为1024(这个参数所有架构下都一样,到目前)
Warp Size: 线程束数量为32
Maximum number of resident blocks per multiprecessor : 每个SM下最大驻留的线程块数量(3.7及以前是16个,5.0开始是32个)
Maximum number of resident threass per multiprecessor:每个SM下最大驻留的线程数量.都是2048个
Maximum number of resident warps per multiprecessor:每个SM下最大驻留的Warp数量(都是64),因为最大驻留线程数2048/32 =64
Number of 32-bit registers per multiprocessor:每个SM下32寄存器的数量:基本都是64K,只有3.7是128K
Number of shared memory banks:共享内存最大Bank数, 均为32个
Amount of local memory per thread:每个线程的最大局部内存,均为512KB(局部内存实际存在于Global memory)
Constant memory size:常量内存,均是64KB
Maximum amount of shared memory per thread Block: 每个线程块拥有的最大共享内存是48KB(除了7.0是最大可设置为96KB)
Maximum number of 32-bit registers per thread: 每个线程拥有的最大寄存器数量,3.0是63个,3.0之后都是255个
三、K80计算卡架构及特性
四、P100计算卡架构及特性
FMA: Fused Multiply-Add (参考nvidia docs: Floating Point and IEEE 754 :: CUDA Toolkit Documentation https://docs.nvidia.com/cuda/floating-point/index.html#fused-multiply-add-fma)
https://docs.nvidia.com/cuda/floating-point/index.html#fused-multiply-add-fma)
GPU一般一个时钟周期可以操作64bit的数据,1个核心实现1个FMA。
这个GPU的计算能力的单元是:64bit*1FMA*2M/A/64bit=2FLOPs/Cycle
The FMA operation computes rn(X×Y+Z) with only one rounding step

浮点数计算能力公式:
理论峰值 FLOPS = GPU芯片数量 * GPU Boost主频 * FP32 cores * 单个时钟周期内能处理的浮点计算次数
注意: 是FLOPS, 不是FLOPs,参考: NVIDIA A100 PCIe 40 GB Specs | TechPowerUp GPU Database
FP32 cores = SM * coresPerSM = 56个 SM *64 = 3584
SM: 对应clinfo里面的Max Compute Units
P100理论峰值 = 1* 1.48GHz * 3584 * 2 = 10.608 TFLOPS
双精度(FP64)计算能力 5.3 TFLOPS)
单精度(FP32)计算能力 10.6 TFLOPS)
半精度(FP16)计算能力 21.2 TFLOPS)
GP100架构核心内建3840个CUDA核心、240个纹理单元、最高32GB HBM2显存、位宽4096bit,L2缓存也从3MB提升到了4MB,据Nvidia官方所说,Nvidia Tesla P100采用的则是“阉割版”的GP100,因此只采用了3584个CUDA核心,而且显存也缩水成了16GB HBM2显存。
GP100架构新特性:
1)Extreme performance(For HPC, DeepLearning,MoreComptuting Areas)
2) NVLink技术(高速高带宽连接)
3) HBM2(快速高容量CoWos Chip-on-Wafer-on-Substrate stacked memory architecture)
4) Unified Memory ,Compute Preemption,and New AI Algorithms
5)16nm FinFET(支持更多的功能、更高的性能和更高的功率效率)
如图:
(From Pascal-architecture-white-paper)
GP100 GPU 的60个SM (P100 只拥有阉割版的56个SM) (From Pascal-architecture-white-paper)
同之前的Tesla系列产品一样,GP100由多个GPU处理集群(GPCs :Graphics Processing Clusters)、纹理处理集群(TPCs:Texture Processing Clusters)、流多处理器(SMs:Streaming Multiprocessors )以及内存控制器(Memory controllers )组成.
如图,一个完整的GP100GPU包含6个GPC(每个GPC包含10个SM),30个TPC(每个TPC包含两个SM), 60个SM, 8个512位的内存控制器(共4096bits)

Pascal GP100 SM Unit (From Pascal-architecture-white-paper) DP Units(Double Precision Units)
GP100 SM 被分为两个处理块(图中左右两部分),每个块都有16个FP64 CUDA Cores(图中黄色块), 32个FP32 CUDA Cores(图中绿色块),一个指令缓冲区 Instuction Buffer,一个warp调度器 Warp Scheduler和两个分派器单位 Dispatch Unit, 以及一些寄存器,Texture, L1 Cache ,和Shared Memory;(一个完整GP100含有1920个FP64 )
五、V100计算卡架构及特性
新特性:
1)专为深度学习优化的全新流多处理器(SM)架构(Tensor cores)
2)第二代 NVIDIA NVLink (能够提供更高带宽与更多链路,GV100 最多支持六条NVLink链路,总带宽为300GB/s , 而GP100 只支持四条NVLink链路)
3)HBM2内存:高速、高效
4)Volta 多进程服务MPS(volta架构新功能,为共享GPU的多个计算应用提高性能实现隔离兵改进服务质量)
5)统一内存寻址和地址转换服务质量提升(GV100统一内存寻址技术包含新的存取计数器)
6)协作组合新的协作启动API
7)针对Volta优化的软件(Volta优化版的GPU加速库 如cuDNN cuBLAS TensorRT)

(Tesla V100 中的新技术)
双精度(FP64)计算能力 7.8 TFLOPS)(比P100提升一大截啊)
单精度(FP32)计算能力 15.7TFLOPS)
Tensor 125 TFLOPS

图:包含84个SM的完整Volta GV100 GPU (V100 只是阉割版的80个SM)
同之前的Tesla系列产品一样,GV100由多个GPU处理集群(GPCs :Graphics Processing Clusters)、纹理处理集群(TPCs:Texture Processing Clusters)、流多处理器(SMs:Streaming Multiprocessors )以及内存控制器(Memory controllers )组成.
如图,一个完整的GV100GPU包含6个GPC(每个GPC包含14个SM, 7个TPC),42个TPC(每个TPC包含两个SM)
84个SM, 每个SM拥有64个FP32 核心、64个INT32核心、32个FP64核心、8个Tensor核心、4个纹理单元
8个512位的内存控制器(共4096bits)

图: Volta GV100流多处理器(SM)
每个SM分为四个处理块,每个处理块拥有16个FP32 核心、16个INT32核心、8个FP64核心、2个Tensor核心、一个L0指令缓存、一个线程束调度器、一个分配单元、一个64KB的寄存器文件;
GV100 中共享内存和L1资源的合并使每个Volta SM 的共享内存容量增加至96KB, 而GP100仅有64 KB的共享内存。
Tensor Core 恐怖之处:V100GPU含有640个 Tensor Cores ,每个Tensor Core每个时钟执行64次浮点FMA运算,一个SM中的8个Tensor Core每时钟总共执行512次FMA运算,毕竟Tensor Core可为训练和推理应用提供高达125Tensor TFLOPS ;