网格结构对比分析
网络结构对比分析----LeNet-5 AlexNet VGG Inception ResNet MobileNet
- 1 引言
-
- 2 LetNet
- 3 AlexNet
- 4 VGG
- 5 Google Inception
-
- 5.1 InceptionV1
- 5.2 inception V2
- 6 ResNet
-
- 6.1 ResNetV1
- 6.2 ResNetV2
- 7 MobileNet
-
- 7.1 mobileNet depthwise
- 7.2 网络结构
- 8 总结
- 参考文献
1 引言
深度学习的发展,尤其在图像处理中的应用,网络结构也变得越来越丰富。从正常的分类网络到重建网络,网络的架构变得非常有技巧性,其对于学习结果有较大的影响,下面主要讨论一下几个成熟的网络结构。LeNet、AlexNet、VGG、Inception、ResNet 和mobilenet。主要参考和转载自文章见文末。
2 LetNet
手写数字的鼻祖,CNN较为成功的较早的尝试

LeNet-5输入为32x32的二维像素矩阵,由于是灰度图,输入通道为1,其正向传播步骤为
- 先经过一层5x5的卷积,featuremap为6,也就是输出通道为6。由于没有在图片四周加padding,像素矩阵大小变为了28x28。这一层参数量为(5x5+1)x6 = 156。
- 然后经过一层2x2的平均值池化层进行下采样。像素矩阵大小变为了14x14 再经过一层5x5的卷积,featuremap为16。像素矩阵大小变为了10x10。这一层参数量为(5x5x6+1)x16 = 2416
- 然后经过一层2x2的最大值池化层。像素矩阵大小变为了5x5 在经过一层5x5的卷积,feature map为120。像素矩阵大小变为了1x1。这一层参数量为(5x5x16+1)x120 = 48120
- 然后经过一层全连接层, 输出为84.故这一层参数量为84x120 = 10080 最后一层为Gaussian Connections输出层,输出0~9共10个分类。目前主流输出层已经由softmax来代替
LeNet-5的特点如下
- 使用了卷积来提取特征,结构单元一般为卷积 - 池化 -非线性激活
- 已经加入了非线性激活,激活函数采用了tanh和sigmoid,目前大多数情况下我们使用的是relu
- 池化层使用的是平均值池化,目前大多数情况下我们使用最大值池化 分类器使用了Gaussian Connections,目前已经被softmax替代
3 AlexNet
第一次采用relu,dropout和GPU加速等技巧,参数为6000万,模型大小240M左右,结构如下:

AlexNet输入图片为224x224, 输入为RGB三通道。正向传播共5个卷积层和3个全连接层,步骤为
- conv1-relu1-pool1-lrn1: 11x11的卷积,步长为4, 输出通道96,也就是96个特征图。分为两组,每组48个通道。然后通过一层relu的非线性激活。在经过一层最大值池化,池化核大小3x3, 步长为2。最后再经过一层LRN,局部响应归一化。第一层运算后图片大小为27x27x96
- conv2-relu2-pool2-lrn2: 第二层的输入即为第一层的输出,也就是27x27x96的像素矩阵。96个feature map分成两组,分别在两个GPU中进行运算。卷积核大小为5x5, 步长为1,输出通道为128. 然后进过一层relu非线性激活。再经过一层最大值池化,池化核大小仍然为3x3, 步长为2. 最后再经过一层LRN。第二层运算后为两组13x13x128的图片
- conv3-relu3: 第三层的输入为第二层的输出,也就是13x13x128的像素矩阵。先经过卷积核大小为3x3x192的卷积运算,步长为1。然后就是relu非线性激活。注意这一层没有max-pooling和LRN。第三层运算后为两组13x13x192
- conv4-relu4: 第四层先经过卷积核大小为3x3, 步长为1的卷积运算,然后经过relu非线性激活。第四层运算后尺寸仍然为两组13x13x192的图片
- conv5-relu5-pool5:第五层先经过卷积核大小为3x3, 输出通道128,步长为1的卷积运算,然后经过relu非线性激活。最后经过一层大小为3x3, 步长为2的max-pooling, 第五层运算后为两组6x6x128的图片
- fc6-relu6-dropout6: 第六层为全连接层,输入为两组6x6x128, 组合在一起也就是6x6x256。输出通道为4096。经过relu和dropout后输出。输出为4096的一维向量
- fc7-relu7-dropout7: 第七层为全连接层,输入为4096的一维向量,输出也为4096的一维向量,也就是4096x4096的全连接。然后通过relu和dropout输出。输出为4096的一维向量。
- fc8: 第八层为全连接层,输入为4096的一维向量,输出为1000的一维向量,对应1000个分类的输出。也就是4096x1000的全连接。输出为1000的一维向量。经过这一层后就可以通过softmax得到1000个分类的分类结果了。
AlexNet的结构特点为 - 采用relu替代了tanh和sigmoid激活函数。relu具有计算简单,不产生梯度弥散等优点,现在已经基本替代了tanh和sigmoid全连接层使用了dropout来防止过拟合。dropout可以理解为是一种下采样方式,可以有效降低过拟合问题。
- 卷积-激活-池化后,采用了一层LRN,也就是局部响应归一化。将一个卷积核在(x,y)空间像素点的输出,和它前后的几个卷积核上的输出做权重归一化。
- 使用了重叠的最大值池化层。3x3的池化核,步长为2,因此产生了重叠池化效应,使得一个像素点在多个池化结果中均有输出,提高了特征提取的丰富性
- 使用CUDA GPU硬件加速。训练中使用了两块GPU进行并行加速,使得模型训练速度大大提高。
- 数据增强。随机的从256x256的原始图片中,裁剪得到224x224的图片,从而使一张图片变为了(256-224)^2张图片。并对图片进行镜像,旋转,随机噪声等数据增强操作,大大降低了过拟合现象。
4 VGG
VGG为ILSVRC 2014年第二名,它探索了卷积网络深度和性能,准确率之间的关系。通过反复堆叠3x3卷积和2x2的池化,得到了最大19层的深度。VGG19模型大概508M,错误率降低到7.3%。VGG模型不复杂,只有3x3这一种卷积核,卷积层基本就是卷积-relu-池化的结构,没有使用LRN,结构如下图。

VGG特点如下:
- 采用了较深的网络,最多达到19层,证明了网络越深,高阶特征提取越多,从而准确率得到提升。
- 串联多个小卷积,相当于一个大卷积。VGG中使用两个串联的3x3卷积,达到了一个5x5卷积的效果,但参数量却只有之前的9/25。同时串联多个小卷积,也增加了使用relu非线性激活的概率,从而增加了模型的非线性特征。
- VGG-16中使用了1x1的卷积。1x1的卷积是性价比最高的卷积,可以用来实现线性变化,输出通道变换等功能,而且还可以多一次relu非线性激活。
- VGG有11层,13层,16层,19层等多种不同复杂度的结构。使用复杂度低的模型的训练结果,来初始化复杂度高模型的权重等参数,这样可以加快收敛速度。
5 Google Inception
Google Inception是一个大家族,包括inceptionV1 inceptionV2 inceptionV3 inceptionV4等结构。它主要不是对网络深度的探索,而是进行了网络结构的改进。inceptionV1击败了VGG,夺得2014年ILSVRC冠军。之后Google又对其网络结构进行了诸多改进,从而形成了一个大家族。
5.1 InceptionV1
inceptionV1是一个设计十分精巧的网络,它有22层深,只有500万左右的参数量,模型大小仅为20M左右,但错误率却只有6.7%。它的网络结构特点如下
5. 去除了最后的全连接层,而使用全局平均池化来代替。这是模型之所以小的原因。AlexNet和VGG中全连接几乎占据了90%的参数量。而inceptionV1仅仅需要1000个参数,大大降低了参数量
6. inception module的使用。借鉴与Network in Network的思想,提出了inception module的概念,允许通道并联来组合特征。其结构如下
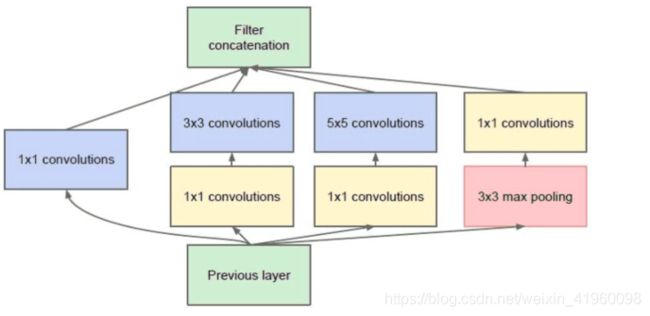
inception module分为并联的四路,分别为单独的1x1卷积,1x1并联3x3, 1x1并联5x5, 池化后1x1卷积。使用不同的卷积结构来提取不同特征,然后将他们组合在一起来输出。使用了1x1,3x3,5x5等不同尺寸的卷积,增加了提取特征面积的多样性,从而减小过拟合
5.2 inception V2
inceptionV2和V1网络结构大体相似,其模型大小为40M左右,错误率仅4.8%,低于人眼识别的错误率5.1%。主要改进如下
- 使用两个串联3x3卷积来代替5x5卷积,从而降低参数量,并增加relu非线性。这一点参考了VGG的设计
- 提出了Batch Normalization。在卷积池化后,增加了这一层正则化,将输出数据归一化到0~1之间,从而降低神经元分布的不一致性。这样训练时就可以使用相对较大的学习率,从而加快收敛速度。在达到之前的准确率之后还能继续训练,从而提高准确率。V2达到V1的准确率时,迭代次数仅为V1的1/14, 从而使训练时间大大减少。最终错误率仅4.8%
6 ResNet
6.1 ResNetV1
ResNet由微软提出,并夺得了2015年ILSVRC大赛的冠军。它以152层的网络深度,将错误率降低到只有3.57%,远远低于5.1%的人眼识别错误率。它同样利用全局平均池化来代替全连接层,使得152层网络的模型不至于太大。网络中使用了1x1 3x3 5x5 7x7等不同尺寸的卷积核,从而提高卷积的多样性。resNetV1_152模型大小为214M,不算太大。
ResNet提出了残差思想,将输入中的一部分数据不经过神经网络,而直接进入到输出中。这样来保留一部分原始信息,防止反向传播时的梯度弥散问题,从而使得网络深度一举达到152层。当前有很多人甚至训练了1000多层的网络,当然我们实际使用中100多层的就远远足够了。残差网络如下图

6.2 ResNetV2
ResNetV2相对于V1的最大变化,就是借鉴了inceptionV2的BN归一化思想,这样来减少模型训练时间。
7 MobileNet
为了能将模型部署在终端上,需要在保证准确率的前提下,减小模型体积,并降低预测时的计算时间,以提高实时性。为了能到达这一目的,Google提出了mobileNet框架。最终mobileNetV1_1.0_224模型以16M的大小,可以达到90%的top-5准确率。模型甚至可以压缩得更小,mobileNetV1_0.25_128只有10M左右,仍然能达到80%的准确率。
7.1 mobileNet depthwise
mobileNet模型的核心是,将一个普通的卷积拆分成了一个depthwise卷积和一个1x1的普通卷积(也叫pointwise卷积)。depthwise卷积层的每个卷积只和输入的某一个channel进行计算,而combining则由1x1的卷积来负责。如下图

对于卷积核dk*dk,输入通道为M,输出通道为N的普通卷积,每个输出通道都是由M个卷积分别和输入通道做计算,然后累加出来,所以需要的参数量为dk x dk x M x N。而对于depthwise卷积,每个卷积只和输入通道的某一个通道发生计算,并且不需要累加操作,其卷积后的输出通道和输入通道相等,仍然为M。然后再经过一层1x1的普通卷积。故其参数为dk x dk x M + 1 x 1 x M x N。
mobileNet参数量比原来减少了多少呢,我们由下面的计算可以得出
(dk x dk x M + 1 x 1 x M x N) / (dk x dk x M x N) = 1/N + 1/(dk^2)
由于输出通道一般都比较大,为48 96 甚至4096, 故一般取1/(dk^2), 对于最常见的3x3卷积,mobileNet参数量可以降低为原来的1/9.
7.2 网络结构
mobileNet一共包含28层,第一层的卷积为普通卷积,之后的卷积为分解的3x3 depthwise卷积和1x1 pointwise卷积。另外,最后有一个全局平均池化层和全连接层。并利用softmax得到分类结果。如下图所示

8 总结
CNN已经广泛应用在物体识别和分类领域,短短几年间就出现了AlexNet VGG inception ResNet等优秀的神经网络结构,并且每隔几个月就问世一种优秀网络结构,可以说是百花齐放。这要归功于TensorFlow等框架的成熟和GPU等硬件性能的提升,使得网络结构的设计和验证日趋平民化。各种网络结构,其实本质上也是在解决神经网络的几大痛点问题,如下
减少模型参数量,降低模型体积
加快训练收敛速度,减少训练耗时
加快模型预测计算时间,提高实时性。这主要还是通过减少参数量来达到
减少过拟合问题
减少网络层级过深时的梯度弥散问题
参考文献
转载: https://www.pianshen.com/article/309128672/